1.1ディシジョンツリーとは何ですか?
1.1.1ディシジョンツリーの例
たとえば、次のデータセット(日付セット)があります:天気、温度、湿度、風、ゴルフ。天候やその他すべてに応じて、私たちはゴルフに行った(️)か、しなかった(×)。14の先入観があると仮定しましょう。

このデータから、ゴルフに行ったケースを示すデータ構造を作成できます。この構造は、その枝分かれした形状から、決定ツリーと呼ばれます。
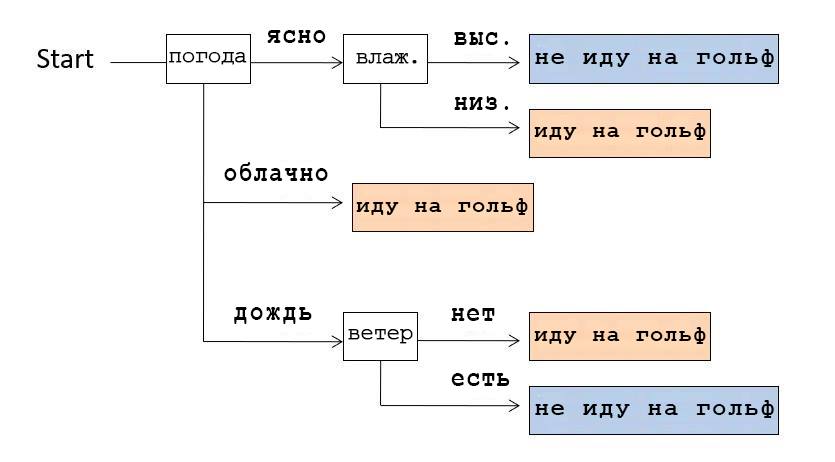
たとえば、上の写真に示されているデシジョンツリーを見ると、最初に天気をチェックしたことがわかります。澄んでいる場合は湿度をチェックしました。湿度が高い場合はゴルフに行きませんでした。低い場合は行きました。そして、天気が曇っていれば、他の条件に関係なく、彼らはゴルフをしに行きました。
1.1.2この記事について
利用可能なデータに基づいてそのような決定ツリーを自動的に作成するアルゴリズムがあります。この記事では、PythonでID3アルゴリズムを使用します。
この記事はシリーズの最初の記事です。次の記事:(
翻訳者のメモ:「続編に興味がある場合は、コメントでお知らせください。」)
- Pythonプログラミングの基礎
- Pandasデータ分析に不可欠なライブラリの基本
- データ構造の基本(ディシジョンツリーの場合)
- 情報エントロピーの基礎
- 意思決定ツリーを生成するためのアルゴリズムの学習
1.1.3ディシジョンツリーについて少し
ディシジョンツリーの生成は、監視対象のマシンの学習と分類に関連しています。機械学習における分類は、正解とそれにつながるデータを設定した日付のトレーニングに基づいて、正解につながるモデルを作成する方法です。近年、特に画像認識の分野で非常に人気のあるディープラーニングも、分類法に基づく機械学習の一部です。ディープラーニングとディシジョンツリーの違いは、最終結果が、最終的なデータ構造を生成する原理を人が理解できる形に縮小されるかどうかです。ディープラーニングの特徴は、最終結果が得られるが、その生成の原理を理解していないことです。ディープラーニングとは異なり、ディシジョンツリーは人間が理解しやすい機能です。これも重要な機能です。
ディシジョンツリーのこの機能は、機械学習だけでなく、データのユーザー理解も重要な日付マイニングにも適しています。
1.2ID3アルゴリズムについて
ID3は、1986年にRossQuinlanによって開発されたDecisionTree生成アルゴリズムです。これには2つの重要な機能があります。
- カテゴリデータ。このデータは、上記の例(ゴルフに行くかどうか)に似ており、特定のカテゴリラベルが付いています。ID3は数値データを使用できません。
- 情報エントロピーは、値のクラスのプロパティの変動が最小のデータのシーケンスを示す指標です。
1.2.1数値データの使用について
ID3のより高度なバージョンであるアルゴリズムC4.5は数値データを使用できますが、基本的な考え方はこのシリーズでも同じであるため、最初にID3を使用します。
1.3開発環境
以下で説明するプログラムは、次の条件でテストして実行しました。
- Jupyter Notebooks(Azure Notebooksを使用)
- Python 3.6
- ライブラリ:数学、パンダ、functools(scikit-learn、tensorflowなどを使用しませんでした)
1.4サンプルプログラム
1.4.1実際には、プログラム
まず、プログラムをJupyterNotebookにコピーして実行しましょう。
import math
import pandas as pd
from functools import reduce
#
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
# - , ,
# .
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],
}
df0 = pd.DataFrame(d)
# - , - pandas.Series,
# -
# s value_counts() ,
# , , items().
# , sorted,
#
# , , : (k) (v).
cstr = lambda s:[k+":"+str(v) for k,v in sorted(s.value_counts().items())]
# Decision Tree
tree = {
# name: ()
"name":"decision tree "+df0.columns[-1]+" "+str(cstr(df0.iloc[:,-1])),
# df: , ()
"df":df0,
# edges: (), ,
# , .
"edges":[],
}
# , , open
open = [tree]
# - .
# - pandas.Series、 -
entropy = lambda s:-reduce(lambda x,y:x+y,map(lambda x:(x/len(s))*math.log2(x/len(s)),s.value_counts()))
# , open
while(len(open)!=0):
# open ,
# ,
n = open.pop(0)
df_n = n["df"]
# , 0,
#
if 0==entropy(df_n.iloc[:,-1]):
continue
# ,
attrs = {}
# ,
for attr in df_n.columns[:-1]:
# , ,
# , .
attrs[attr] = {"entropy":0,"dfs":[],"values":[]}
# .
# , sorted ,
# , .
for value in sorted(set(df_n[attr])):
#
df_m = df_n.query(attr+"=='"+value+"'")
# ,
attrs[attr]["entropy"] += entropy(df_m.iloc[:,-1])*df_m.shape[0]/df_n.shape[0]
attrs[attr]["dfs"] += [df_m]
attrs[attr]["values"] += [value]
pass
pass
# , ,
# .
if len(attrs)==0:
continue
#
attr = min(attrs,key=lambda x:attrs[x]["entropy"])
#
# , , open.
for d,v in zip(attrs[attr]["dfs"],attrs[attr]["values"]):
m = {"name":attr+"="+v,"edges":[],"df":d.drop(columns=attr)}
n["edges"].append(m)
open.append(m)
pass
#
print(df0,"\n-------------")
# , - tree: ,
# indent: indent,
# - .
# .
def tstr(tree,indent=""):
# .
# ( 0),
# df, , .
s = indent+tree["name"]+str(cstr(tree["df"].iloc[:,-1]) if len(tree["edges"])==0 else "")+"\n"
# .
for e in tree["edges"]:
# .
# indent .
s += tstr(e,indent+" ")
pass
return s
# .
print(tstr(tree))1.4.2結果
上記のプログラムを実行すると、決定ツリーは次のようにシンボルテーブルとして表されます。
decision tree ['×:5', '○:9']
=
=['○:2']
=['×:3']
=['○:4']
=
=['×:2']
=['○:3']
1.4.3調査する属性(データ配列)を変更する
日付セットdの最後の配列は、クラス属性(分類するデータの配列)です。
d = {
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["","","","","","","","","","","","","",""],
"":["×","×","○","○","○","×","○","×","○","○","○","○","○","×"],}
# - , , .
"":["","","","","","","","","","","","","",""],
}たとえば、上記の例に示すように、配列「Golf」と「Wind」を交換すると、次の結果が得られます。
decision tree [':6', ':8']
=×
=
=
=[':1', ':1']
=[':1']
=[':2']
=○
=
=[':1']
=[':1']
=
=[':2']
=[':1']
=[':1']
=[':3']本質的には、風の有無とゴルフをするかどうかによって、最初に分岐するようにプログラムに指示するルールを作成します。
読んでくれてありがとう!
この記事が気に入ったら、翻訳は明確でしたか、役に立ちましたか?