CPU制限とスロットル
他の多くのKubernetesユーザーと同様に、GoogleはCPU制限を調整することを強くお勧めします。この構成がないと、ノード内のコンテナーがすべてのプロセッサー能力を消費する可能性があり、その結果、重要なKubernetesプロセス(たとえば
kubelet)が要求への応答を停止します。したがって、CPU制限を設定することは、ノードを保護するための良い方法です。
プロセッサ制限は、コンテナが特定の期間(デフォルトでは100ms)に使用できる最大プロセッサ時間を設定し、コンテナがこの制限を超えることはありません。 Kubernetesは、特別なツールCFS Quotaを使用してコンテナを抑制し、制限を超えないようにします。ただし、最終的には、このような人工プロセッサはパフォーマンスの低下を制限し、コンテナの応答時間を増加させます。
CPU制限を設定しないとどうなりますか?
残念ながら、私たち自身がこの問題に対処しなければなりませんでした。各ノードにはコンテナの管理を担当するプロセスがあり、
kubelet要求への応答を停止しています。これが発生すると、ノードは状態NotReadyになり、ノードからのコンテナは別の場所にリダイレクトされ、新しいノードですでに同じ問題が発生します。穏やかに言えば、理想的なシナリオではありません。
スロットルと応答性の問題の顕在化
コンテナを追跡するための重要な指標は
trottling、コンテナがスロットルされた回数です。プロセッサの負荷が最大であるかどうかに関係なく、一部のコンテナにスロットルが存在することに興味を持って気づきました。たとえば、主要なAPIの1つを見てみましょう:
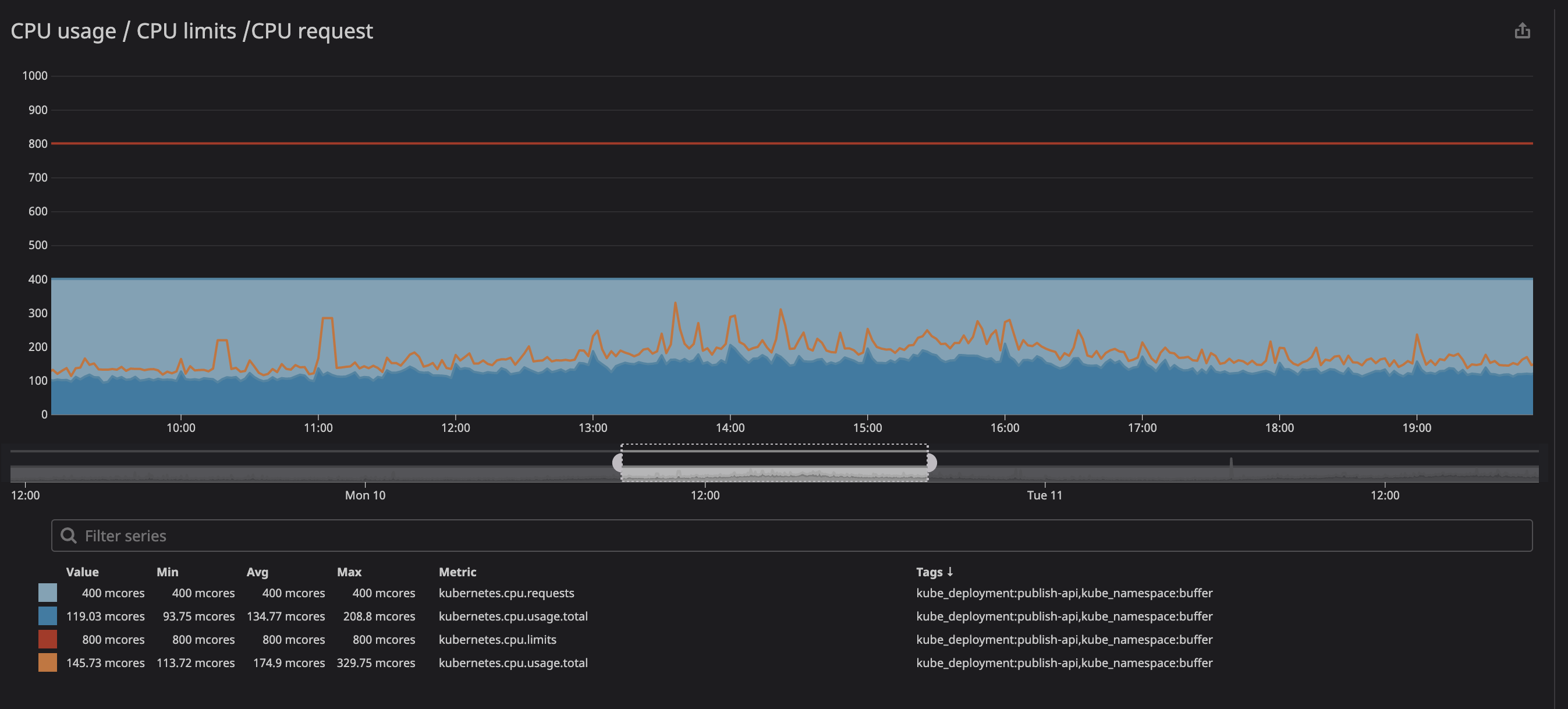
以下に示すように、制限を
800m(コアの0.8または80%)に設定し、ピーク値はせいぜい200m(コアの20%)です。ただし、サービスを制限する前に、まだ多くのプロセッサパワーがあるように見えます...
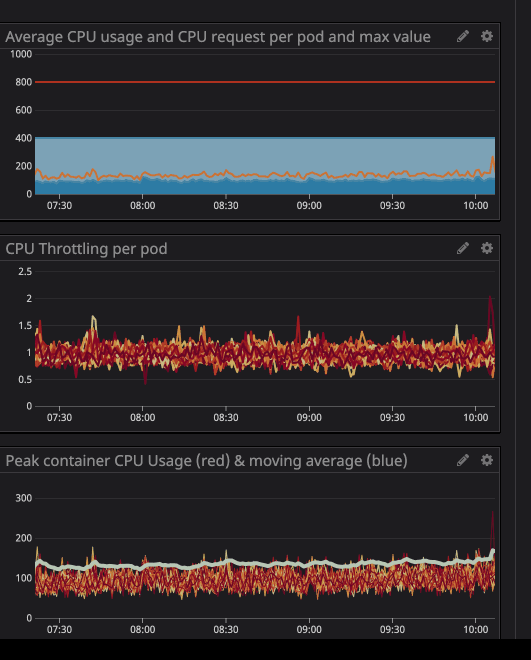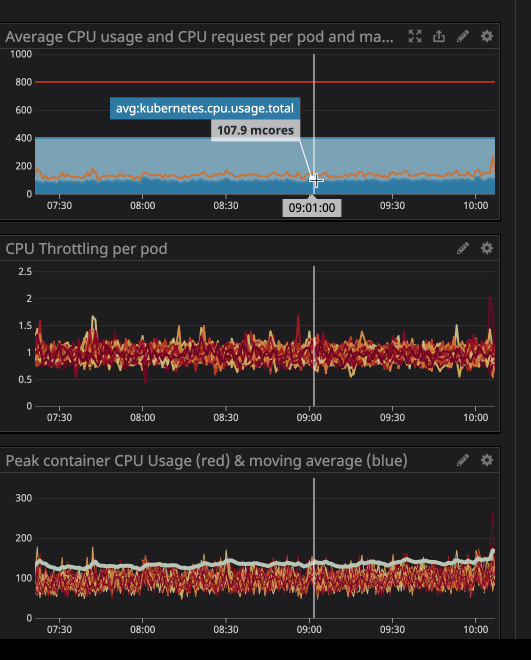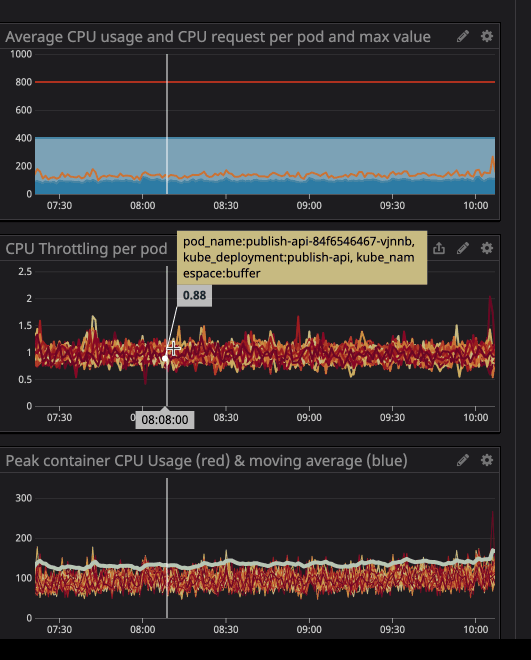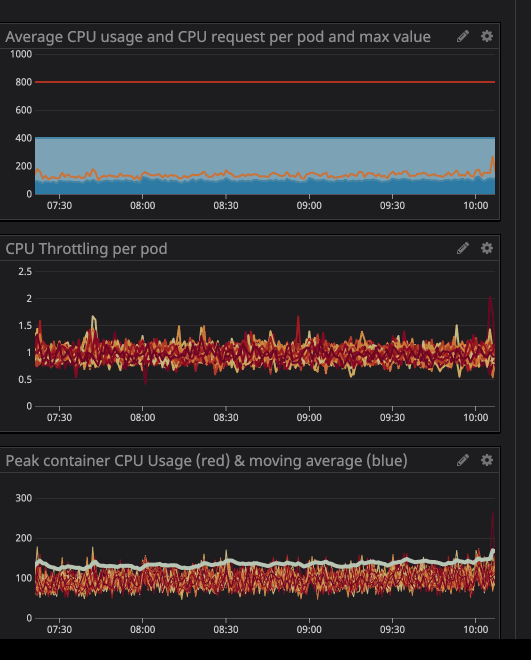
プロセッサの負荷が指定された制限を下回っている場合でも(はるかに低い)、スロットルが機能することに気付いたかもしれません。
このに直面し、我々はすぐにいくつかのリソース(発見githubの上の問題、zadanoに関するプレゼンテーション、omio上のポストを伴うスロットリングへのサービスのパフォーマンスと応答時間の低下について)。
CPU使用率が低いのになぜスロットルが発生するのですか?短いバージョンは次のようになります。「Linuxカーネルには、指定されたプロセッサ制限を持つコンテナの不要なスロットリングをトリガーするバグがあります。」問題の性質に興味がある場合は、プレゼンテーション(ビデオとテキスト)を読むことができます バリアント)DaveChilukによる。
プロセッサ制限の削除(細心の注意を払って)
長い議論の末、ユーザーの重要な機能に直接的または間接的に影響を与えるすべてのサービスからプロセッサの制限を削除することにしました。
クラスターの安定性を高く評価しているため、決定は難しいことが判明しました。過去に、クラスターの不安定性を実験してきましたが、サービスが大量のリソースを消費し、ノード全体の作業が遅くなりました。今ではすべてが少し異なりました。クラスターに何を期待するかを明確に理解し、計画された変更を実装するための優れた戦略を立てました。

差し迫った問題に関するビジネス通信。
制限を解除するときにノードを保護するにはどうすればよいですか?
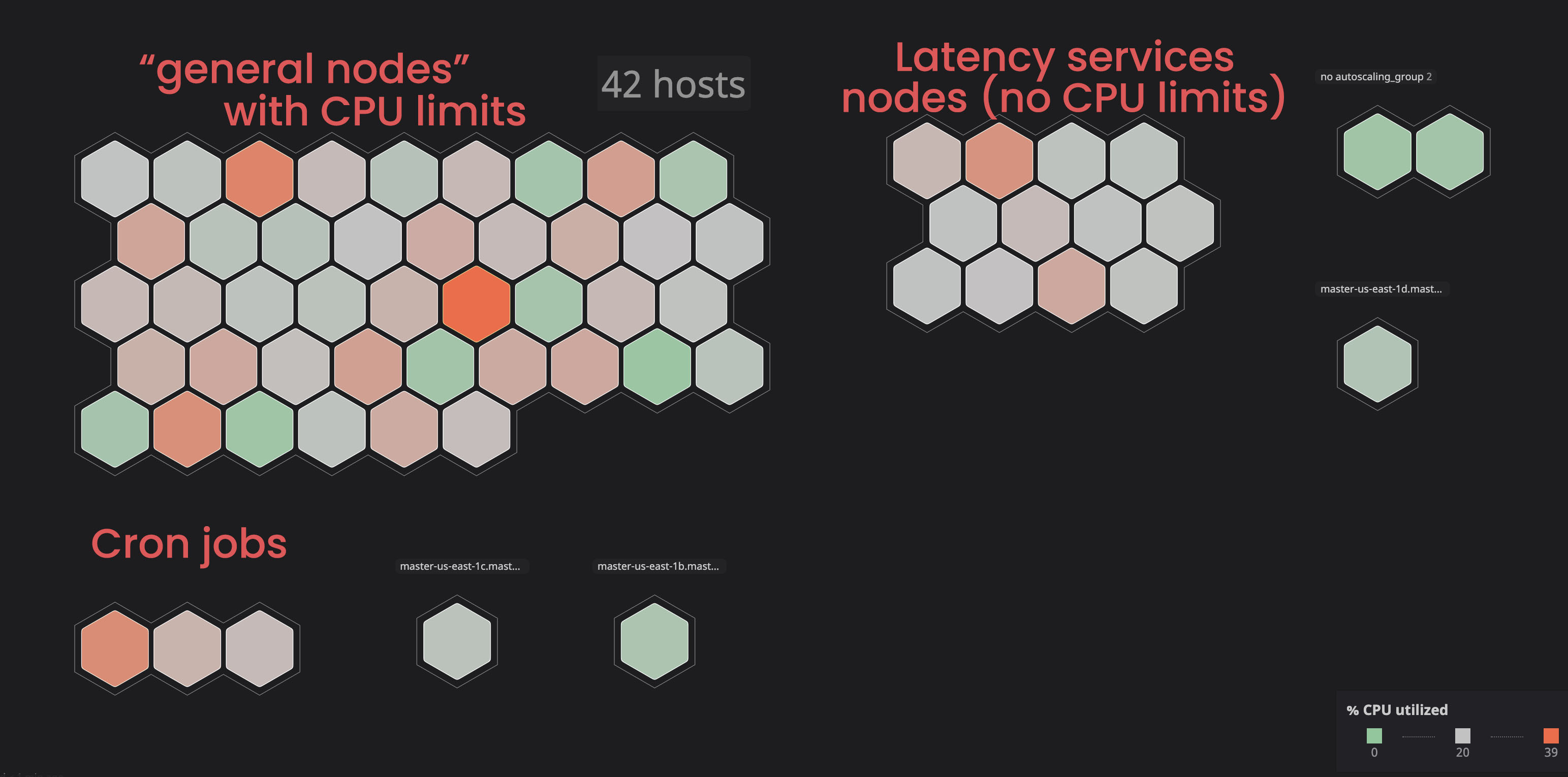
「無制限の」サービスの分離:
これまで
notReady、主にサービスが多くのリソースを消費していたために、一部のノードが状態になるのを確認しました。
このようなサービスは、「リンクされた」サービスに干渉しないように、別々の(「タグ付けされた」)ノードに配置することにしました。その結果、一部のノードにマークを付け、「無関係な」サービスに許容パラメータを追加することで、クラスターをより細かく制御できるようになり、ノードの問題を特定しやすくなりました。同様のプロセスを自分で実行するには、ドキュメントに精通している必要があります。
正しいプロセッサとメモリ要求の割り当て:
何よりも、プロセスが多くのリソースを消費し、ノードが要求への応答を停止することを恐れていました。これで(Datadogのおかげで)クラスター上のすべてのサービスを明確に観察できたので、「無関係」として指定する予定のサービスの数か月の運用を分析しました。最大CPU使用率を20%のマージンで設定するだけなので、k8sがノードに他のサービスを割り当てようとした場合に備えて、ノードにスペースを割り当てます。
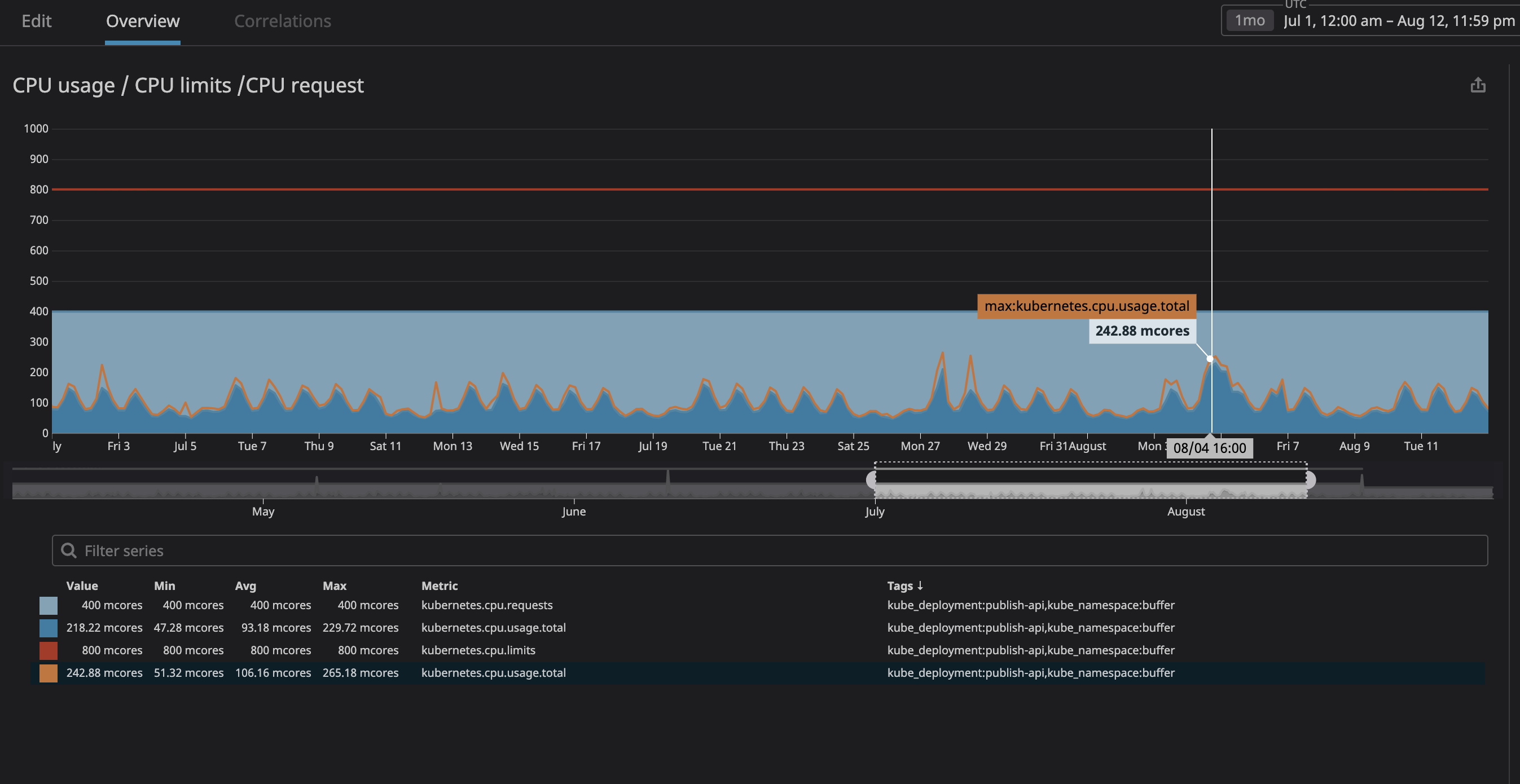
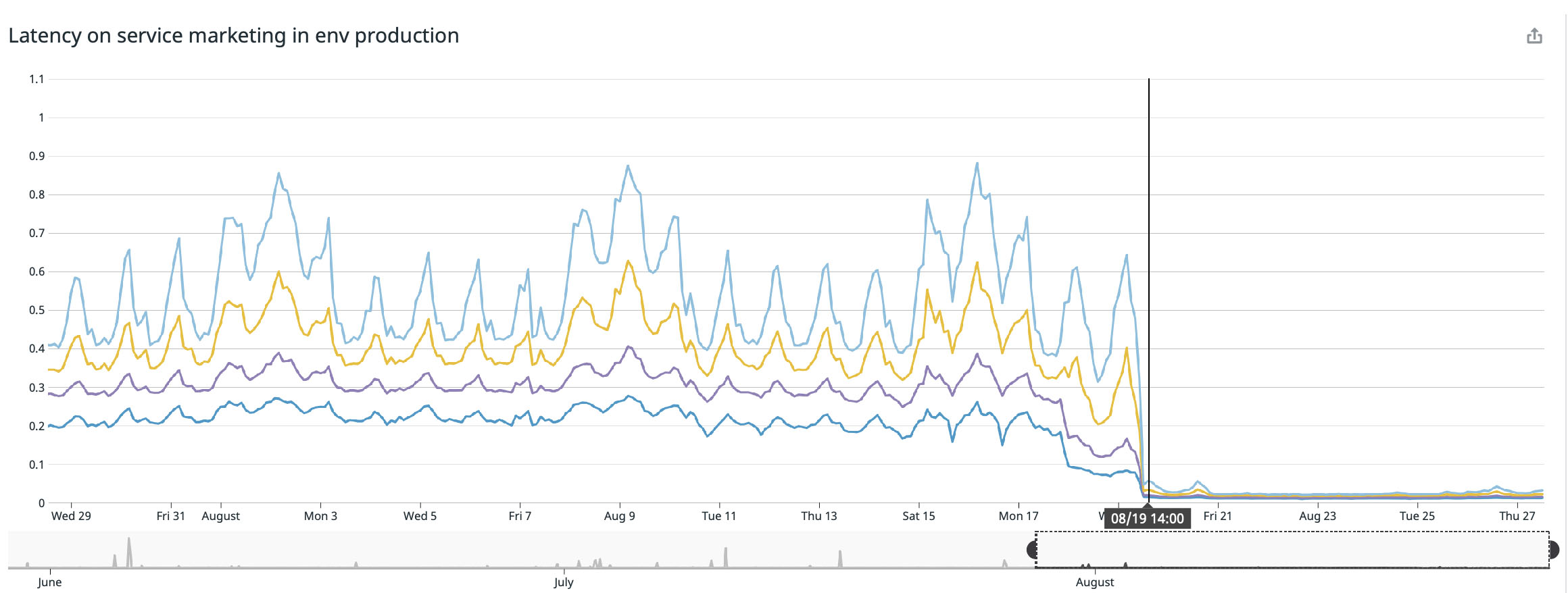
グラフからわかるように、最大プロセッサ負荷は
242mCPUコア(0.242プロセッサコア)に達しています。プロセッサ要求の場合、この値よりわずかに大きい数を取るだけで十分です。サービスはユーザー中心であるため、負荷のピークはトラフィックと一致することに注意してください。
メモリ使用量とクエリについても同じことを行います。これで準備は完了です。安全性を高めるために、ポッドの水平方向の自動スケーリングを追加できます。したがって、リソースの負荷が高くなるたびに、自動スケーリングによって新しいポッドが作成され、kubernetesはそれらを空き領域のあるノードに配布します。クラスタ自体にスペースが残っていない場合は、アラートを設定するか、自動スケーリングを使用して新しいノードの追加を構成できます。
マイナス点のうち、「コンテナの密度」が失われたことは注目に値します。1つのノードで動作するコンテナの数。また、トラフィック密度が低いと「贅沢」が多く発生する可能性があり、プロセッサの負荷が高くなる可能性もありますが、ノードの自動スケーリングは後者に役立つはずです。
結果
過去数週間のこれらの優れた実験結果を公開できることをうれしく思います。変更されたすべてのサービスの応答が大幅に改善されていることにすでに気づいています。
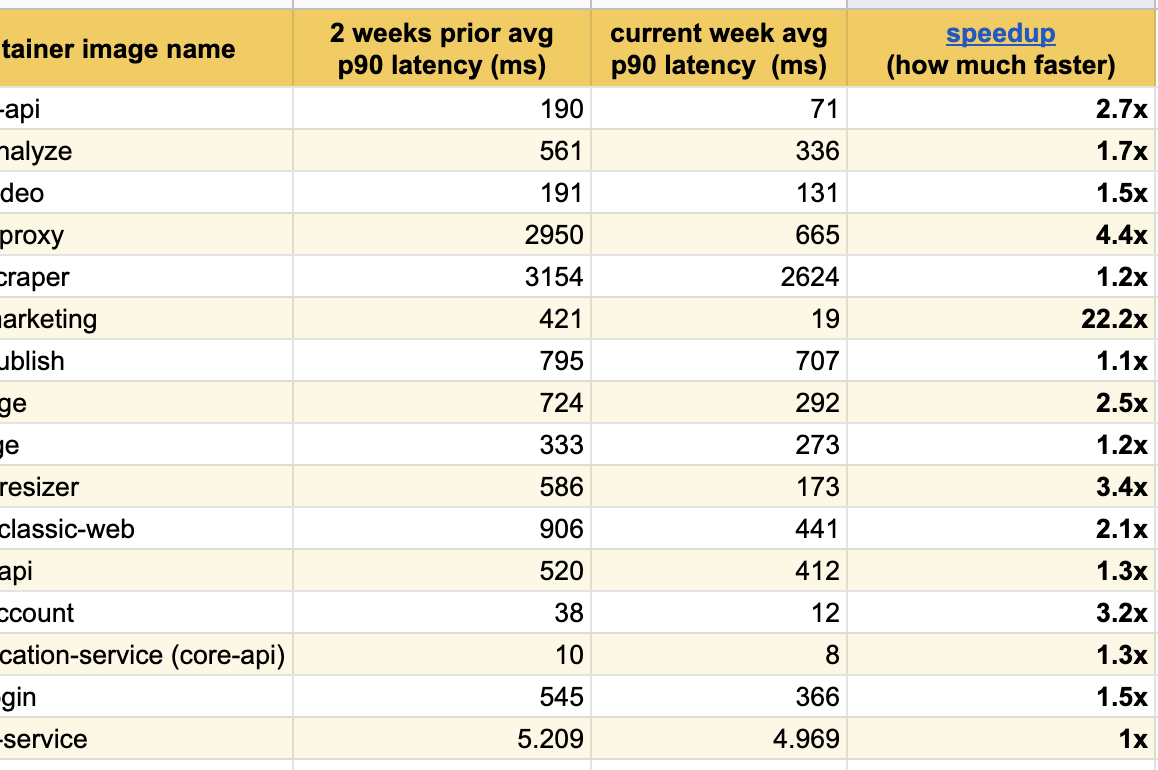
メインページ(buffer.com)で最高の結果を達成し、サービスは22倍高速でした。
Linuxカーネルのバグは修正されていますか?
はい、バグはすでに修正されており、ディストリビューションバージョン4.19以降のカーネルに修正が追加されています。
ただし、2020年9月2日のgithub でkubernetesの問題を読んでいると、同様のバグを持ついくつかのLinuxプロジェクトについての言及に出くわします。一部のLinuxディストリビューションにはまだこのバグがあり、現在修正に取り組んでいると思います。
ディストリビューションのバージョンが4.19未満の場合は、最新に更新することをお勧めしますが、とにかくプロセッサの制限を削除して、スロットルが続くかどうかを確認する必要があります。以下に、KubernetesサービスとLinuxディストリビューションの管理の不完全なリストを示します。
- Debian: , buster, ( 2020 ). .
- Ubuntu: Ubuntu Focal Fossa 20.04
- EKS 2019 . , AMI.
- kops: 2020
kops 1.18+Ubuntu 20.04. kops , , , . . - GKE (Google Cloud): 2020 , .
修正によってスロットルの問題が修正された場合はどうなりますか?
問題が完全に解決されたかどうかはわかりません。修正されたカーネルバージョンに到達したら、クラスターをテストして投稿を更新します。誰かがすでに更新している場合は、結果を確認したいと思います。
結論
- LinuxでDockerコンテナを使用している場合(Kubernetes、Mesos、Swarmなどは関係ありません)、スロットリングが原因でコンテナのパフォーマンスが低下する可能性があります。
- バグがすでに修正されていることを期待して、ディストリビューションの最新バージョンに更新してみてください。
- プロセッサの制限を削除すると問題は解決しますが、これは危険な手法であり、細心の注意を払って使用する必要があります(最初にカーネルを更新して結果を比較することをお勧めします)。
- プロセッサの制限を解除した場合は、プロセッサとメモリの使用量を注意深く監視し、プロセッサのリソースが消費量を超えていることを確認してください。
- 安全なオプションは、ハードウェアに高い負荷がかかった場合にポッドを自動スケーリングして新しいポッドを作成し、kubernetesがそれらを空きノードに割り当てることです。
この投稿が、コンテナシステムのパフォーマンスの向上に役立つことを願っています。
PSここで、著者は読者と解説者(英語)に対応しています。