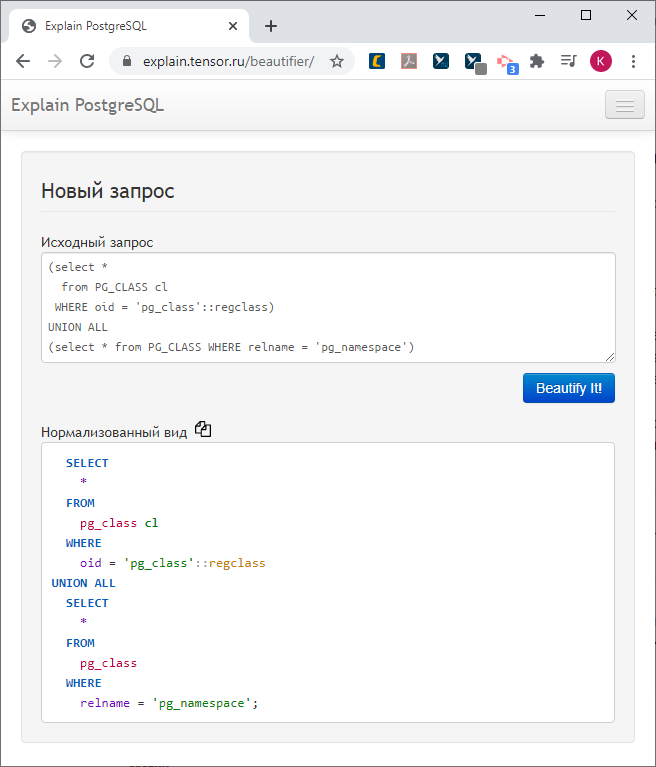
...対応するプランノードのコンテキストヒントを使用して、適切に設計されたクエリに変換します。

PGConf.Russia 2020 での私の講演の第2部のこのトランスクリプトでは、私たちがこれをどのように行ったかを説明します。
典型的なクエリパフォーマンスの問題とその解決策を扱っている最初の部分のトランスクリプトは、記事「SQLクエリを苦しめるためのレシピ」にあります。
最初に、私たちはペイントします-そして私たちはもはや計画をペイントしません、私たちはすでにそれをペイントしました、私たちはそれをすでに美しくそして理解できるようにしています、しかし要求。
フォーマットされていない「シート」を使用してログから取得されたクエリは非常に見苦しく、したがって不便であるように思われました。

特に、コード内の開発者がリクエストの本文を1行で「接着」する場合(これはもちろんアンチパターンですが、発生します)。ホラー!
なんとなくもっと美しく描きましょう。
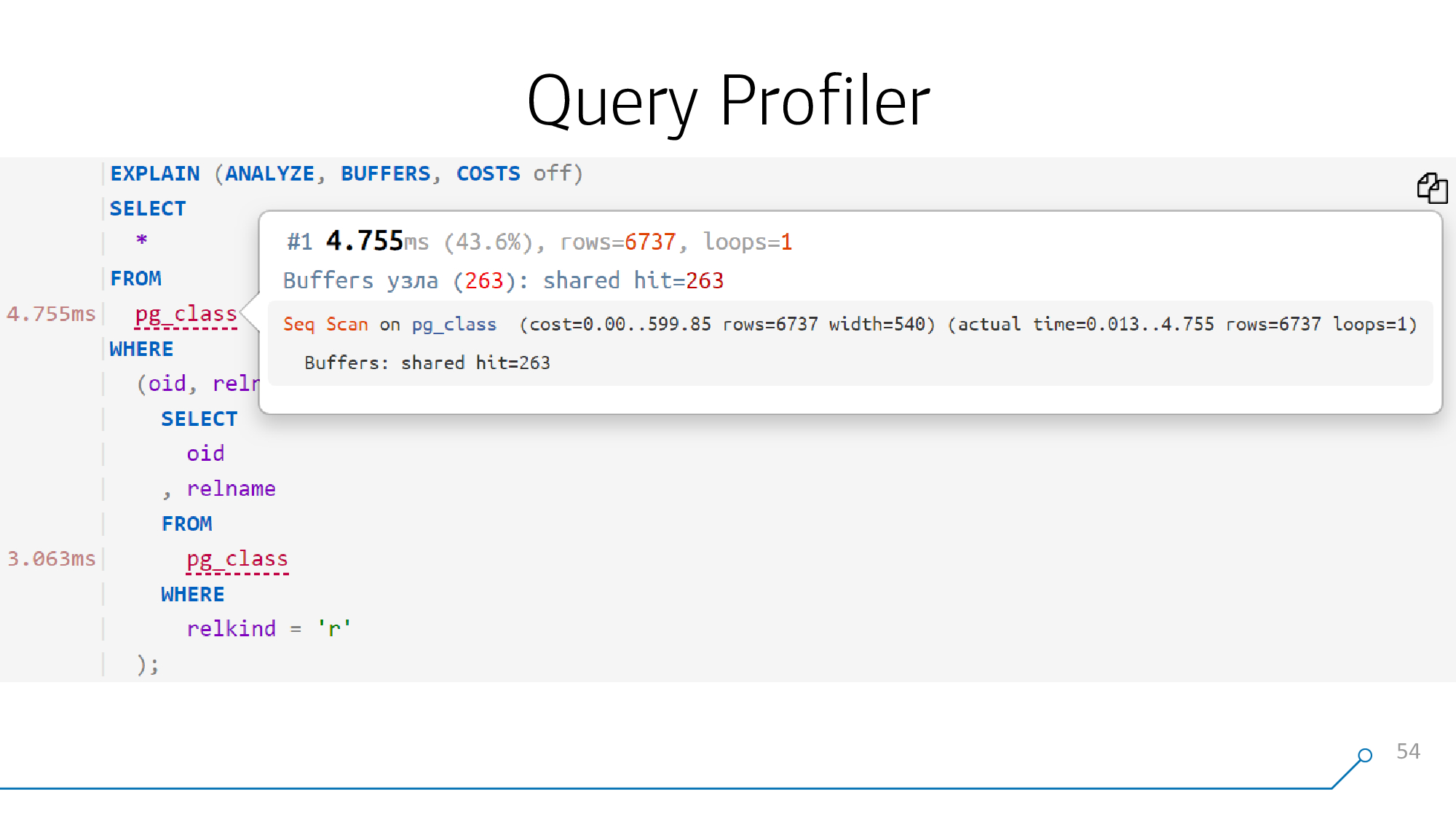
そして、それを美しく描くことができれば、つまり、リクエストの本文を分解して再アセンブルできれば、このリクエストの各オブジェクトにヒントを添付できます。これは、プランの対応するポイントで何が起こったかです。
構文クエリツリー
これを行うには、最初にリクエストを解析する必要があります。
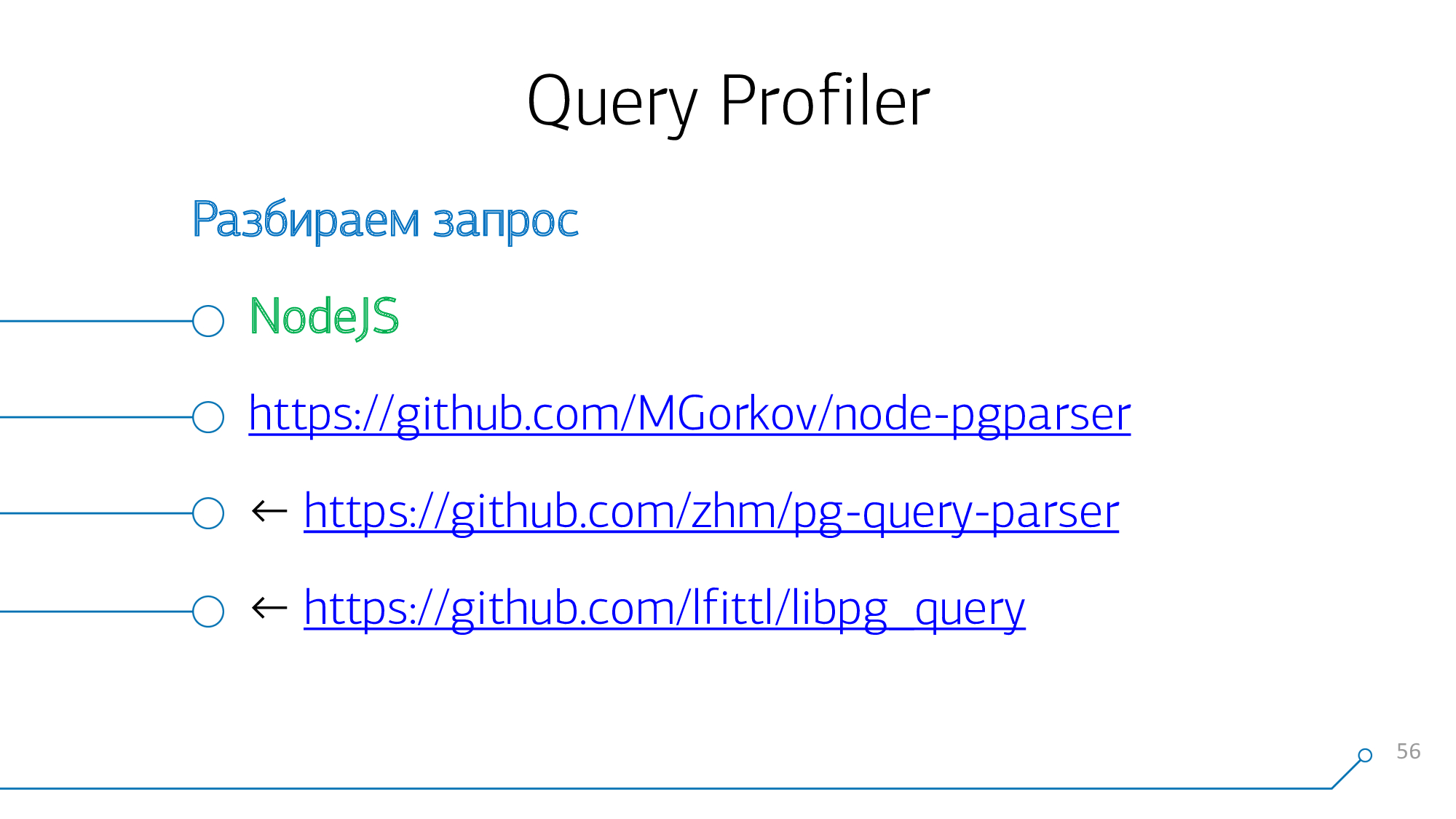
当社以来、システムのコアはNodeJS上で実行されている、我々はあなたがすることができ、それのためのモジュールを作ったGitHubの上でそれを見つけます。実際、これらはPostgreSQLパーサー自体の内部への拡張された「バインディング」です。つまり、文法は単純にバイナリにコンパイルされ、NodeJS側からバインディングが作成されます。私たちは他の人のモジュールを基礎として取りました-ここに大きな秘密はありません。
リクエストの本文を関数の入力にフィードします。出力では、JSONオブジェクトの形式で解析された構文ツリーを取得します。

これで、このツリーを反対方向に通過して、必要なインデント、色付け、フォーマットを使用してリクエストを収集できます。いいえ、構成できませんが、これは便利だと思われました。

クエリノードとプランノードのマッピング
ここで、最初のステップで分析したプランと2番目のステップで分析したクエリを組み合わせる方法を見てみましょう。
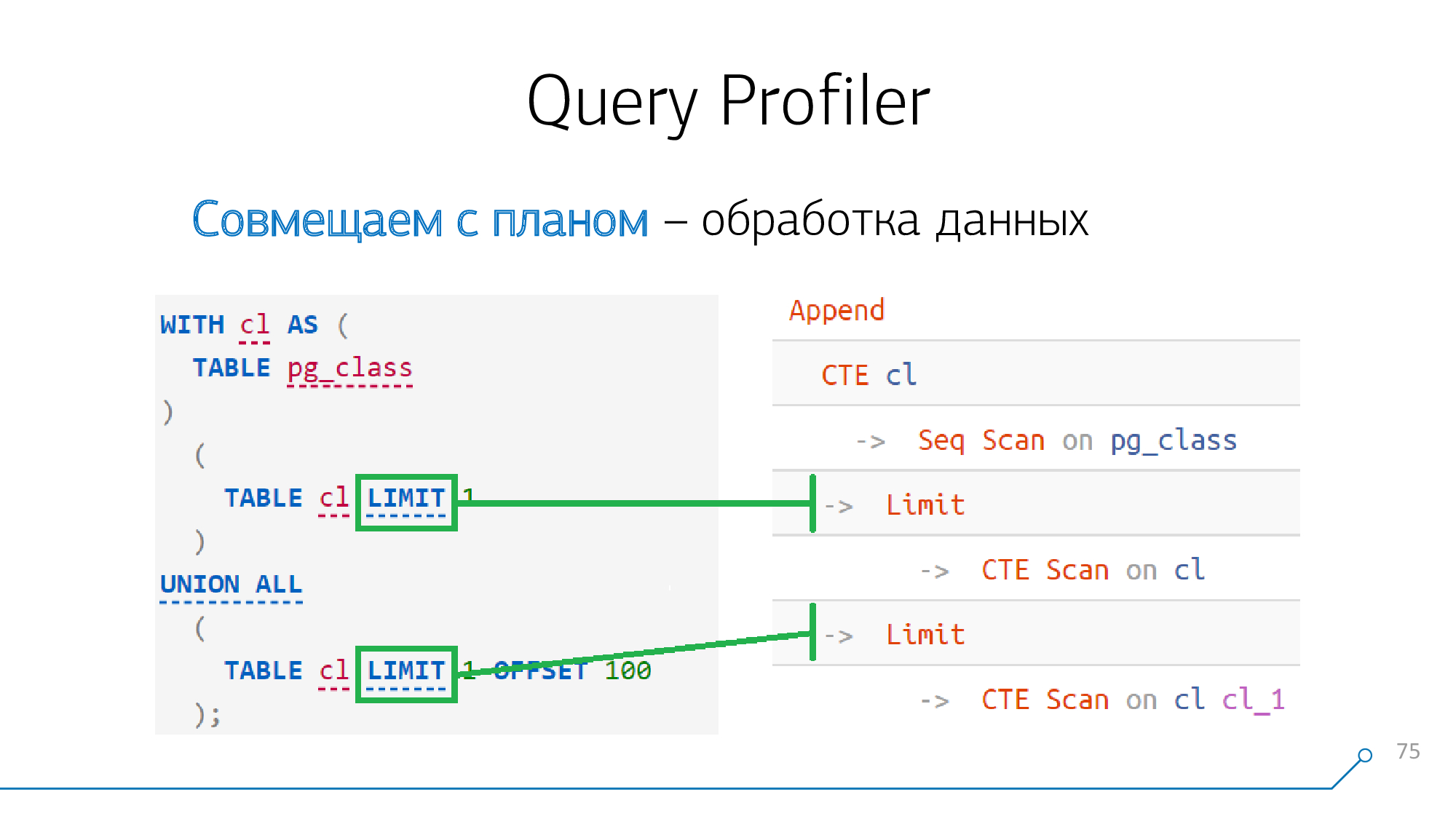
簡単な例を見てみましょう。CTEを生成して2回読み取るリクエストがあります。彼はそのような計画を立てます。

CTE
注意深く見ると、12番目のバージョンの前に(またはキーワードで開始して
MATERIALIZED)、CTEの形成はプランナーにとって絶対的な障壁です。
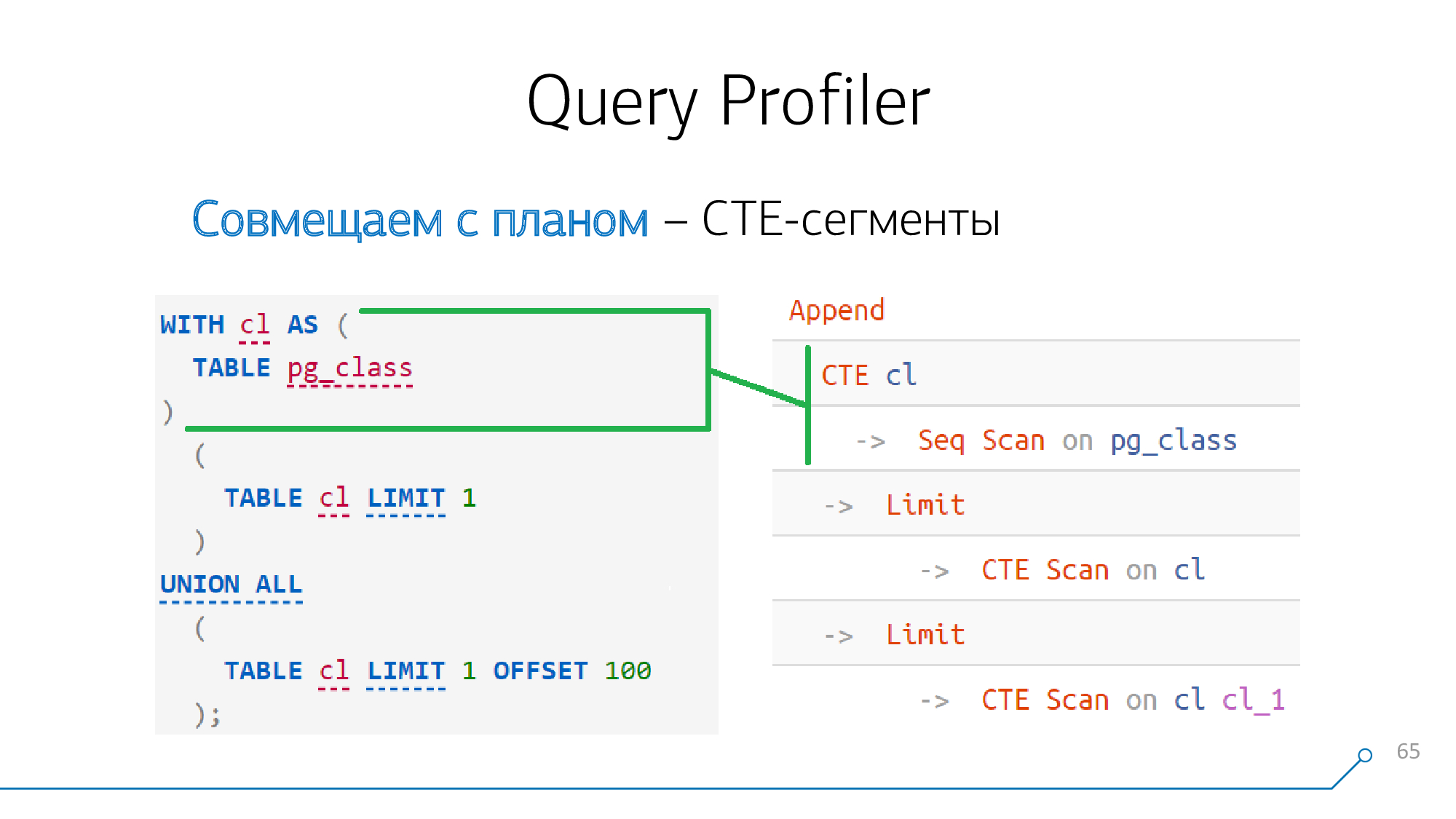
つまり、リクエストのどこかでCTEの生成が見られ、プランのどこかでノードが生成された場合
CTE、これらのノードは確実に相互に「競合」し、すぐに組み合わせることができます。
アスタリスクの問題:CTEはネストできます。

非常にひどくネストされており、同じ名前でさえあります。たとえば、内部で
CTE A実行し、内部CTE Xの同じレベルCTE Bで再度実行できますCTE X。
WITH A AS (
WITH X AS (...)
SELECT ...
)
, B AS (
WITH X AS (...)
SELECT ...
)
...比較するときはこれを理解する必要があります。これを「目」で理解することは非常に困難です。計画を見ても、リクエストの本文を見ても。CTEの生成が複雑で、ネストされていて、リクエストが大きい場合、それは完全に無意識です。
連合
クエリにキーワード
UNION [ALL](2つの選択を結合する演算子)がある場合、ノードAppendまたはいずれかのノードがプラン内のキーワードに対応しRecursive Unionます。

「上」にあるのは
UNIONノードの最初の子であり、「下」にあるのは2番目の子です。場合はUNION、いくつかのブロックが「糊付け」されて一度私たちは、Appendまだ一つだけ-nodeがあるでしょうが、それは2人の子供を持っていますが、多くはないだろう-ために、彼らが行くように、それぞれ:
(...) -- #1
UNION ALL
(...) -- #2
UNION ALL
(...) -- #3Append
-> ... #1
-> ... #2
-> ... #3
「アスタリスク付き」の問題:再帰的選択(
WITH RECURSIVE)の生成内には、複数のが存在する場合もありますUNION。ただし、最後のブロックの後の最後のブロックのみが常に再帰的UNIONです。上記のすべては1つですが、異なりUNIONます:
WITH RECURSIVE T AS(
(...) -- #1
UNION ALL
(...) -- #2,
UNION ALL
(...) -- #3, T
)
...また、そのような例を「貼り付ける」ことができる必要があります。この例では
UNION、リクエストに3つのセグメントがあったことがわかります。したがって、一方はUNION ノードに対応しAppend、もう一方はに対応しRecursive Unionます。

読み取り/書き込みデータ
これで、それを広げました。これで、リクエストのどの部分が計画のどの部分に対応するかがわかりました。そして、これらの作品では、「読み取り可能な」オブジェクトを簡単かつ自然に見つけることができます。
クエリの観点からは、これがテーブルなのかCTEなのかはわかりませんが、同じノードで示されます
RangeVar。そして、「読み取り可能」という点では、これもかなり限定されたノードのセットです。
Seq Scan on [tbl]Bitmap Heap Scan on [tbl]Index [Only] Scan [Backward] using [idx] on [tbl]CTE Scan on [cte]Insert/Update/Delete on [tbl]
計画とクエリの構造、ブロックの対応、オブジェクトの名前を知っています。明確な比較を行います。

繰り返しますが、アスタリスクの問題です。リクエストを受け取り、実行します。エイリアスはありません。1つのCTEから2回読み取るだけです。

私たちは計画を見ます-問題は何ですか?なぜエイリアスが出たのですか?注文しませんでした。なぜ彼はそんなに「番号が付けられている」のですか?
PostgreSQLはそれ自体を追加します。計画と比較するために、そのようなエイリアスだけでは意味がないことを理解する必要があります。ここに追加するだけです。彼に注意を払わないようにしましょう。
2番目のタスクは「アスタリスク付き」です。パーティション化されたテーブルから読み取る場合は、ノードを取得する
Appendか、Merge Append、これは多数の「子」で構成され、それぞれがScanテーブルのセクションの何とかして'番目になります:Seq Scan、、Bitmap Heap ScanまたはIndex Scan。ただし、いずれの場合も、これらの「子」は複雑なクエリではありません。これにより、これらのノードをAppendいつと区別できるかがわかりUNIONます。

また、そのようなノードを理解し、それらを「1つの山に」集めて、「メガテーブルから読み取ったものはすべて、こことツリーの下にあります」と言います。
データを受信するための「シンプルな」ノード

Values ScanプランVALUES内のリクエストで一致します。
Result-これはのFROMようなもののないリクエストSELECT 1です。または、-blockに故意に誤った式がある場合WHERE(その場合、属性が発生しますOne-Time Filter):
EXPLAIN ANALYZE
SELECT * FROM pg_class WHERE FALSE; -- 0 = 1Result (cost=0.00..0.00 rows=0 width=230) (actual time=0.000..0.000 rows=0 loops=1)
One-Time Filter: false
Function Scan同じ名前のSRFに「マップ」します。
しかし、ネストされたクエリでは、すべてがより複雑になります。残念ながら、必ずしも
InitPlan/に変わるとは限りませんSubPlan。時々、特にあなたがのようなものを書くとき、それらは... Joinまたはに変わり... Anti JoinますWHERE NOT EXISTS ...。また、そこで組み合わせることが常に可能であるとは限りません。プランのテキストには、プランノードに対応する演算子はありません。
繰り返しますが、タスクは「アスタリスク付き」です:
VALUESリクエストにいくつかあります。この場合と計画では、いくつかのノードを受け取りますValues Scan。

「番号付き」サフィックスは、それらを互いに区別するのに役立ちます。これは
VALUES、リクエストに沿って上から下に対応するブロックを見つける順序で正確に追加されます。
情報処理
私たちのリクエストのすべてが整理されたようです-残っているのは1つだけでした
Limit。
このようなノードとして-しかし、すべては簡単です
Limit、Sort、Aggregate、WindowAgg、Unique彼らが存在する場合、「mapyatsya」一対一のリクエストで対応するステートメントに、。「星」も困難もありません。

参加する
私たちが
JOIN互いに結合したいときに困難が生じます。これは常に行われるわけではありませんが、可能です。

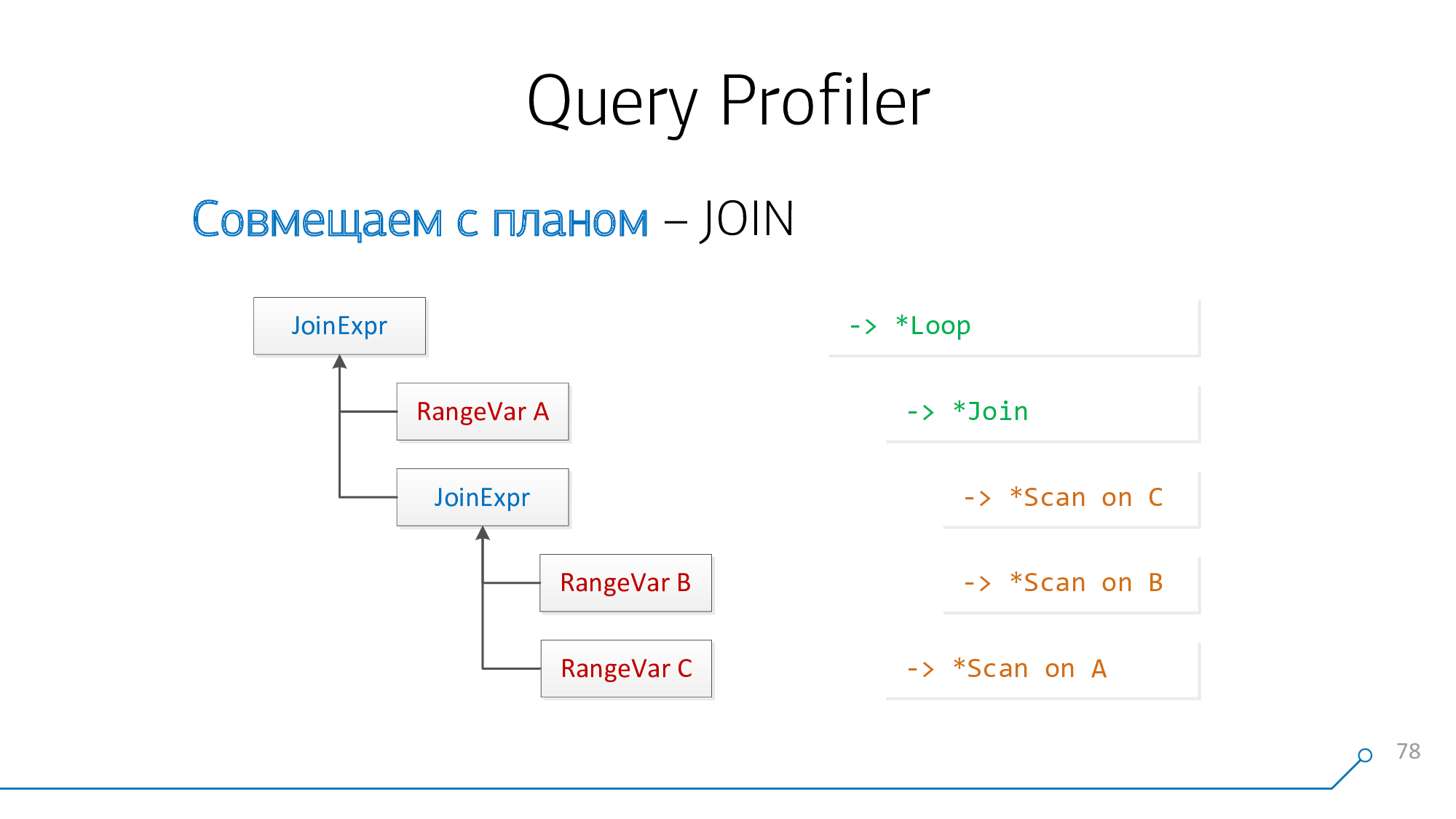
クエリパーサーの観点からは、
JoinExpr左と右の2つの子を持つノードがあります。これはそれぞれ、JOINの「上」にあるものであり、リクエストの「下」にあるものが書き込まれます。
そして、計画の観点から、これらはいくつかの
* Loop/* Joinノードの2つの子孫です。Nested Loop、Hash Anti Join...-それは何かです。
単純なロジックを使用してみましょう。プランで互いに「結合」するプレートAとBがある場合、リクエストでは、
A-JOIN-Bまたはのいずれかに配置できますB-JOIN-A。このように組み合わせてみたり、逆に組み合わせたりして、そのようなペアがなくなるまで続けてみましょう。
私たちの構文ツリーを取り、私たちのアウトラインを取り、それらを見てください...それはそれのようには見えません!
それをグラフの形で再描画しましょう-ああ、それはすでに何かのようなものになっています!
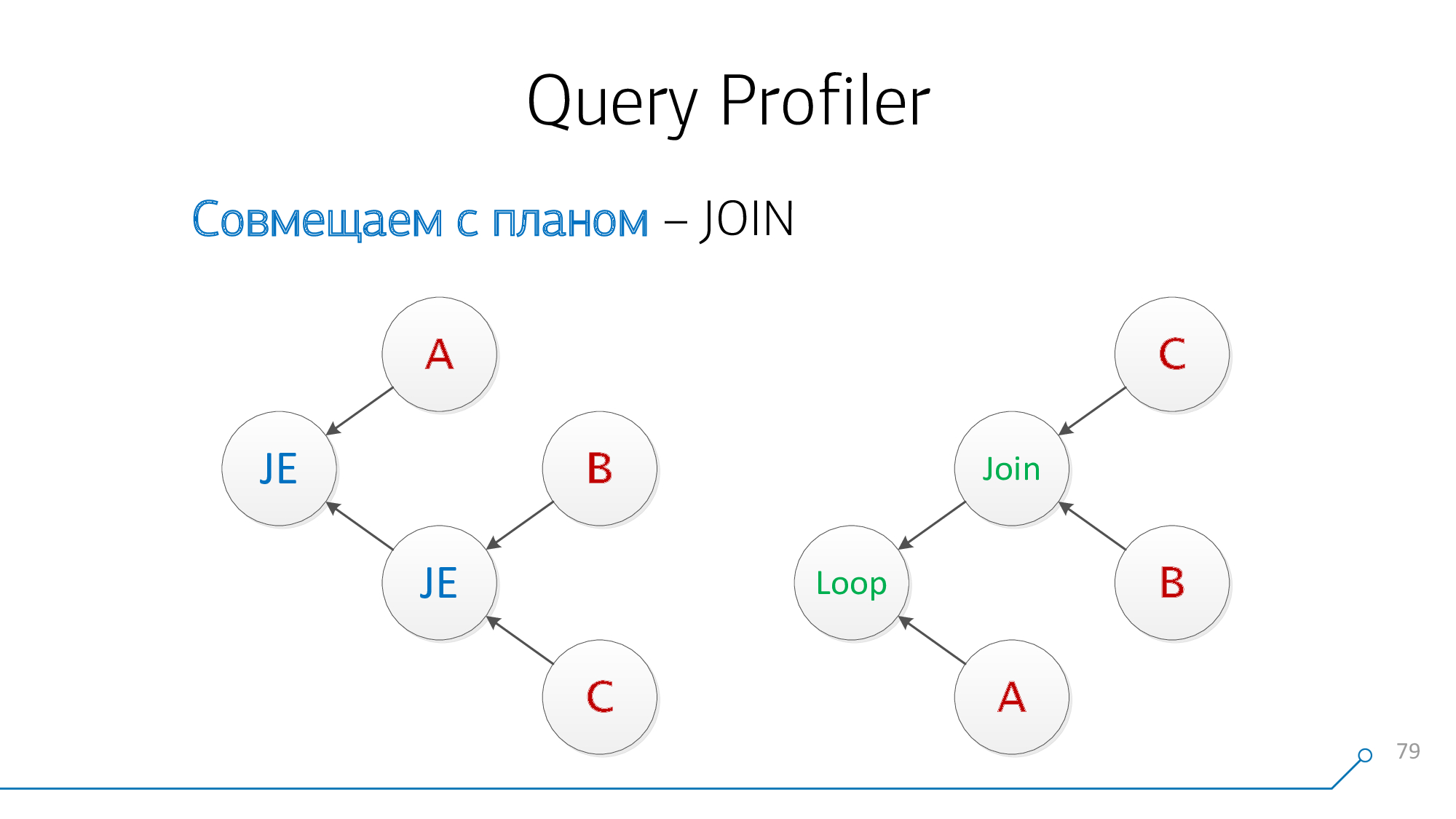
子Bと子Cが同時にあるノードがあることに注意してください。どちらの順序でもかまいません。それらを組み合わせて、結び目の絵を回してみましょう。

もう一度見てみましょう。これで、子Aとペア(B + C)を持つノードができました-それらとも互換性があります。
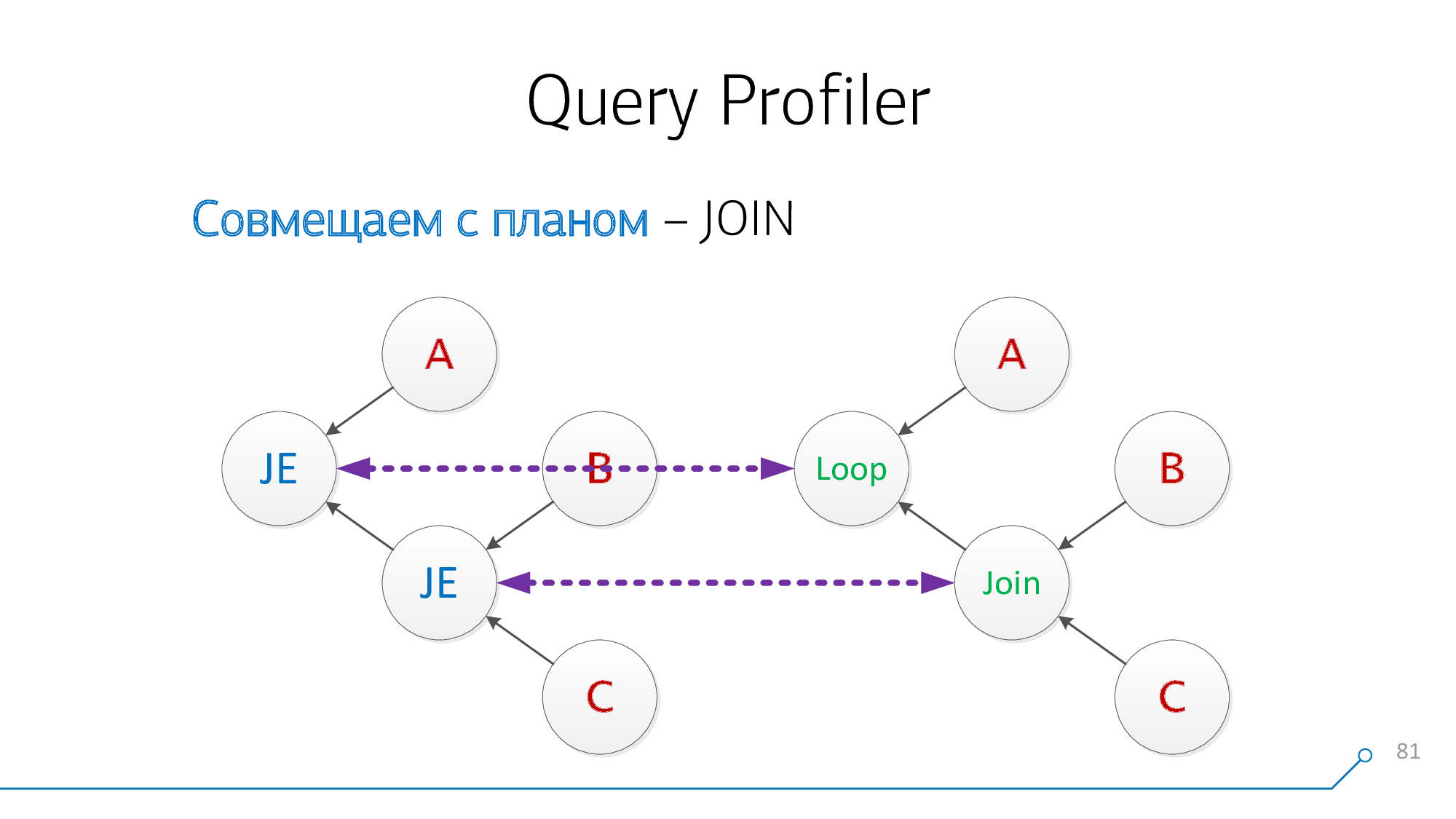
優れた!
JOINクエリからのこれら2つをプランノードと正常に組み合わせることができました。
残念ながら、このタスクは常に解決されるわけではありません。
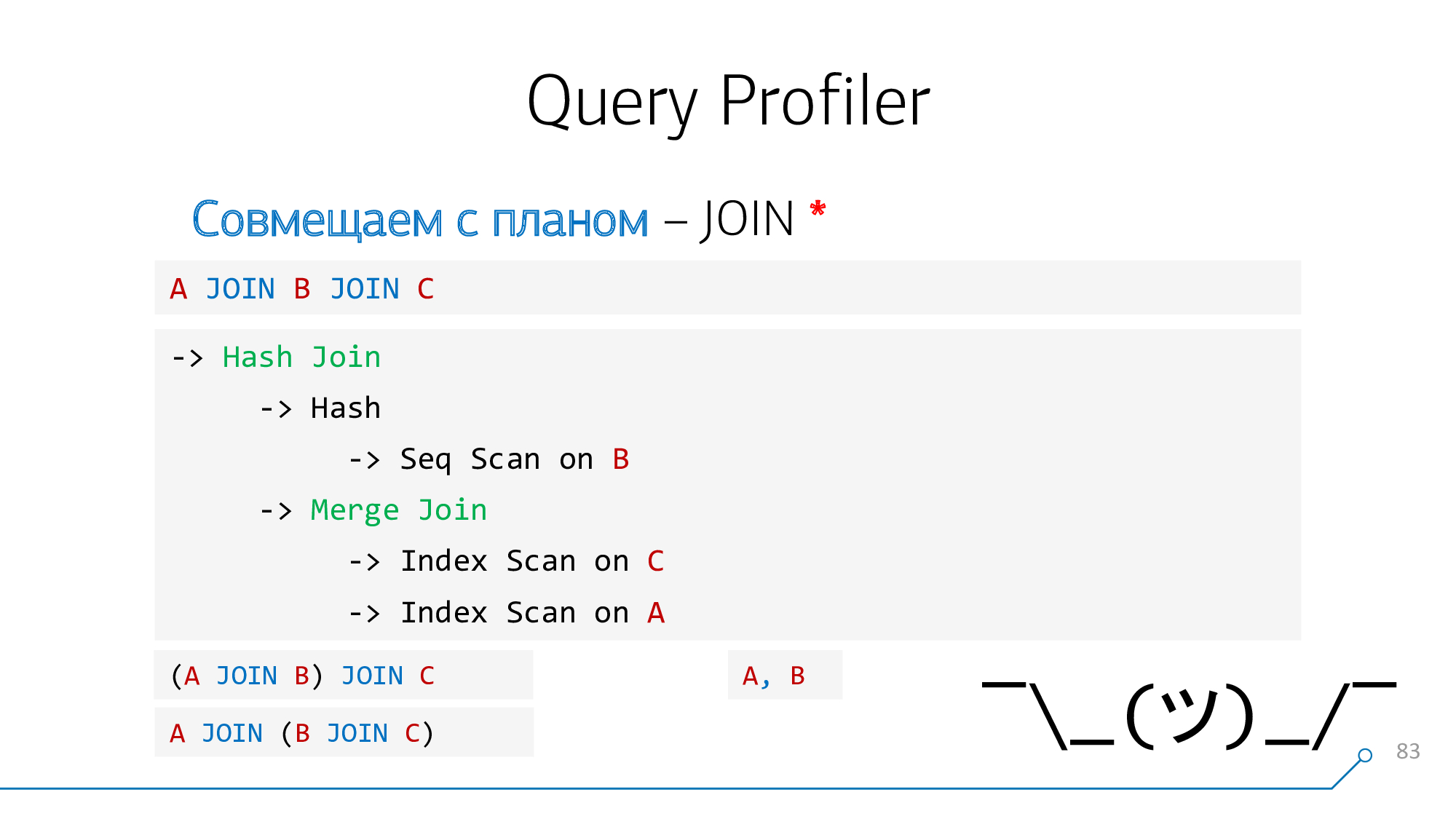
たとえば、クエリ
A JOIN B JOIN Cとプランで、「極端な」ノードAとCが最初に接続されている場合、クエリにはそのような演算子がなく、強調表示するものも、ヒントをバインドするものもありません。を書くときの「comma」も同じですA, B。
ただし、ほとんどの場合、ほとんどすべてのノードを「アンタイド」でき、JavaScriptコードを分析すると、文字通り、Google Chromeのように、この種のプロファイリングが時間の左側に表示されます。各行と各ステートメントが「実行」された期間を確認できます。

そして、これらすべてをより便利に使用できるように、アーカイブストレージを作成しました。このストレージでは、計画を保存して、関連するリクエストとともに検索したり、誰かとリンクを共有したりできます。
判読できないクエリを適切な形式にする必要がある場合は、「ノーマライザー」を使用してください。