
私たちは放送に戻り、データサイエンティストの一連のメモを続けています。今日は、機械学習モデルを選択するための完全に主観的なチェックリストを紹介します。
これらは、問題の上位10のプロパティであり、(順序なしで)単なるポイントであり、その観点から、モデルの選択と、一般に、データ分析タスクのモデリングを開始します。
あなたがそれを同じにする必要はまったくありません-ここではすべてが主観的ですが、私は人生からの私の経験を共有します。
一般的に私たちの目標は何ですか?解釈可能性と精度-スペクトル

ソース
おそらく、モデリングを開始する前にデータサイエンティストが直面する最も重要な質問は次の
とおりです。ビジネスタスクとは正確には何ですか。
または、アカデミーなどについて話している場合は、調査します。
たとえば、データモデルに基づく分析が必要であり、その逆の場合、電子メールがスパムである可能性の定性的な予測にのみ関心があります。
私が見た古典的なバランスは、メソッドの解釈可能性とその精度の間のスペクトルです(上のグラフのように)。
しかし実際には、Catboost / Xgboost / Random Forestを運転してモデルを選択するだけでなく、ビジネスが何を望んでいるか、どのようなデータがあり、どのように適用されるかを理解する必要があります。
私の練習では、これはすぐに解釈可能性と正確さの範囲にポイントを設定します(それがここで意味するものは何でも)。そしてこれに基づいて、問題をモデル化する方法についてすでに考えることができます。
タスク自体のタイプ
さらに、ビジネスが何を望んでいるのかを理解した後、たとえば、私たちが属する機械学習の問題の数学的タイプを理解する必要があります。
- 探索的分析-利用可能なデータの純粋な分析とスティックの貼り付け
- クラスタリング-いくつかの一般的な属性に従ってデータをグループに収集します
- 回帰-整数の結果を返す必要があります。そうでない場合、イベントの可能性があります。
- 分類-1つのクラスラベルを返す必要があります
- マルチラベル-エントリごとに1つ以上のクラスラベルを返す必要があります
データの例:2つのクラスとラベルのないレコードセットがあります。

そして、このデータそのものをマークアップするモデルを構築する必要があります。

または、オプションとして、ラベルがなく、グループを選択する必要があります。

ここのように:ここからの
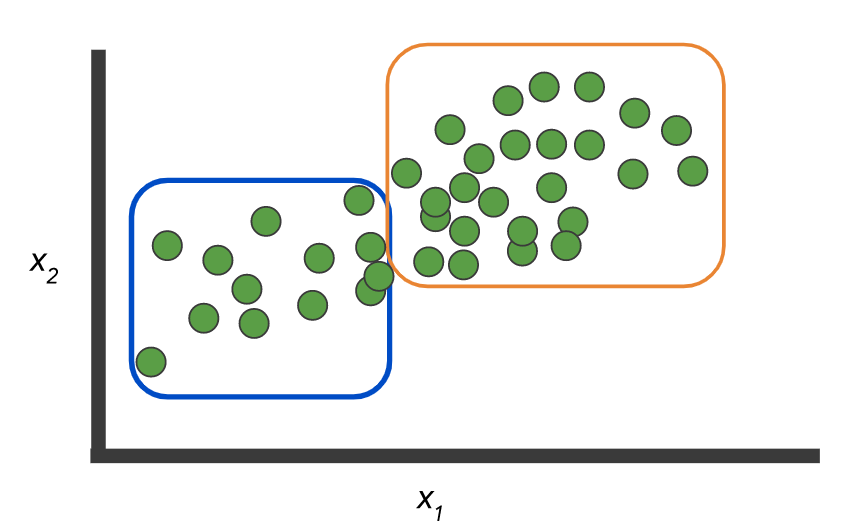
写真。 しかし、例自体は、2つの概念の違いを示しています。N> 2クラスの場合の分類-マルチクラスと。マルチレーベルここから 撮影 驚くかもしれませんが、この点はビジネスに直接話す価値があることもよくあります。これにより、時間と労力を大幅に節約できます。自由に絵を描いて簡単な例を挙げてください(ただし、過度に単純化しないでください)。
精度とその決定方法
簡単な例から始めましょう。あなたが銀行でローンを発行した場合、ローンが失敗すると、成功したローンの5倍の損失が発生します。
したがって、仕事の質を測定するという問題が第一です!または、データに重大な不均衡があり、クラスA = 10%、クラスB = 90%であると想像すると、単にBを返す分類子は常に90%正確です。これは、モデルをトレーニングするときに見たかったものではない可能性があります。
したがって、次のようなモデルスコアリングメトリックを定義することが重要です。
- ウェイトクラス-上記の例のように、不良クレジットは5、良好クレジットは1です。
- コストマトリックス-低リスクと中リスクを混同する可能性があります-これは問題ではありませんが、低リスクと高リスクはすでに問題になっています
- メトリックはバランスを反映する必要がありますか?ROCAUCなど
- 私たちは一般的に確率を数えますか、それともクラスラベルはまっすぐですか?
- あるいは、クラスは一般的に「1つ」であり、ゲームの精度/リコールおよびその他のルールがありますか?
一般に、メトリックの選択はタスクとその定式化によって決定されます。このタスクを設定する人(通常はビジネスマン)は、これらすべての詳細を明確にして明確にする必要があります。そうしないと、出力に継ぎ目があります。
モデル事後分析
多くの場合、モデル自体に基づいて分析を行う必要があります。たとえば、元の結果に対するさまざまな機能の寄与は何ですか。原則として、ほとんどのメソッドは次のようなものを生成できます。
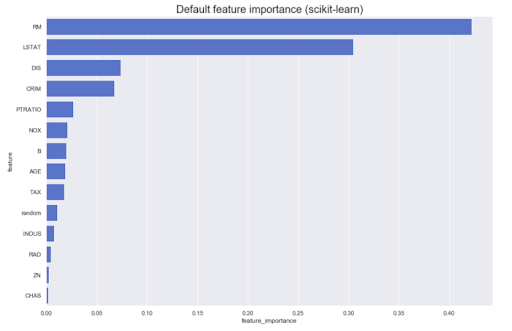
ただし、方向を知る必要がある場合はどうなりますか?属性Aの値が大きいと、クラスZに属するものが増えます、またはその逆の場合はどうなりますか?それらを有向機能の重要性と呼びましょう-たとえば、線形(正規化されたデータの係数を介して)など、いくつかのモデルから取得できます。
ツリーとブースティングに基づく多くのモデルには、たとえば、SHapley AdditiveexPlanationsメソッドが適しています。
形
これは、モデルの内部を確認できるモデル分析方法の1つです。
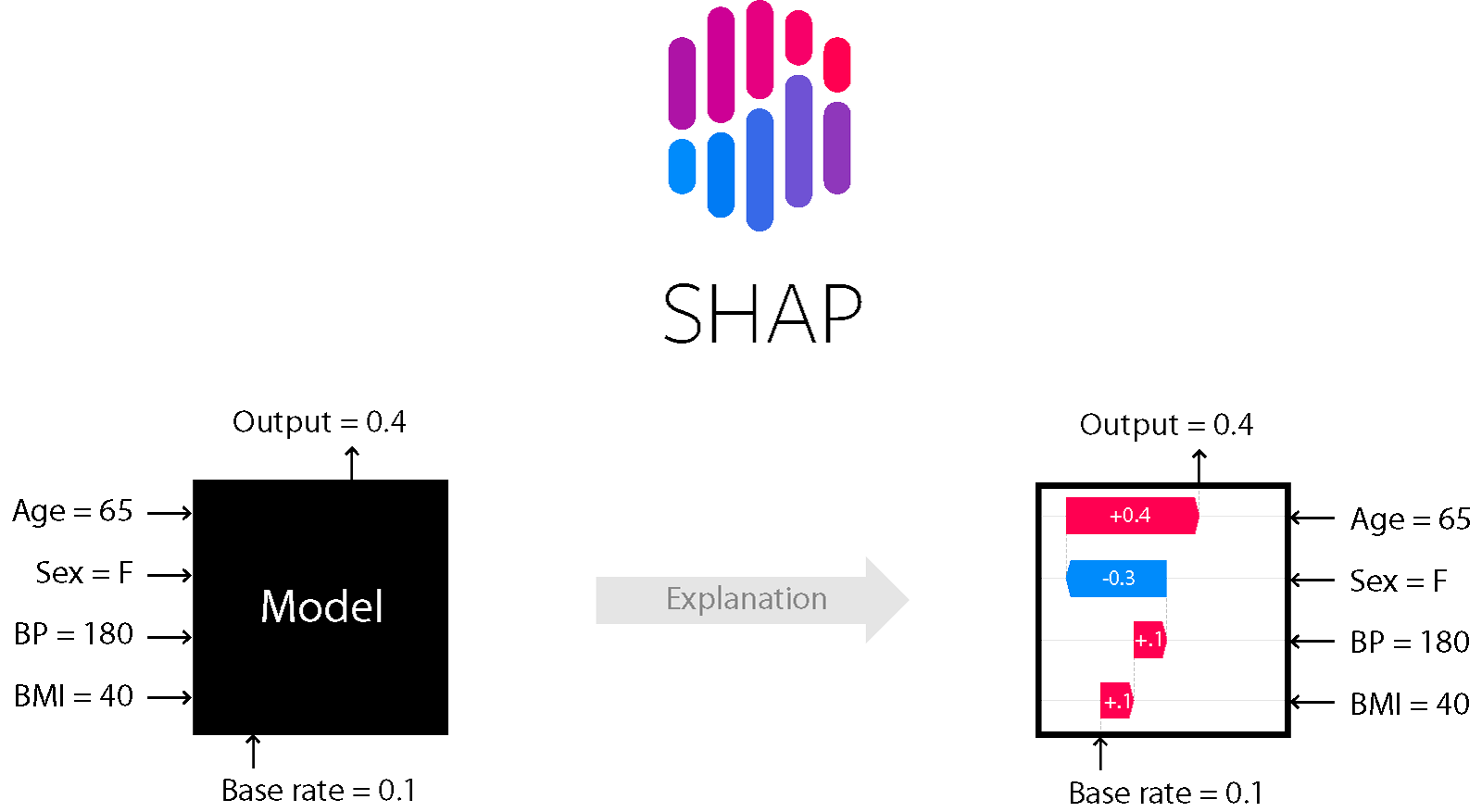
それはあなたが効果の方向を評価することを可能にします:

さらに、木(およびそれらに基づく方法)の場合、それは正確です。詳細については、こちらをご覧ください。
ノイズレベル-安定性、線形依存性、異常検出など。
ノイズへの耐性とこれらすべての人生の喜びは別のトピックであり、ノイズレベルを注意深く分析し、適切な方法を選択する必要があります。データに異常があることが確実な場合は、高品質でデータをクリーンアップし、ノイズに強い方法(高バイアス、正規化など)を適用する必要があります。
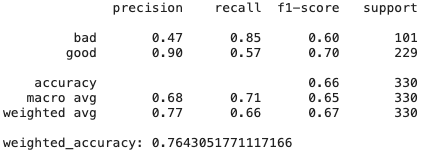
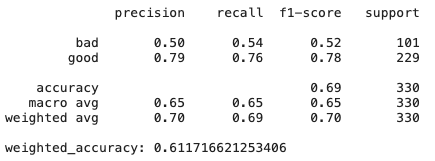
また、記号は同一直線上にあり、意味のない記号が存在する可能性があります。モデルが異なれば、これに対する反応も異なります。これは、古典的なドイツのクレジットデータ(UCI)データセットと3つの単純な(比較的)学習モデルの例です。
- リッジ回帰分類子:Tikhonovの正規化装置を使用した古典的な回帰
- 決定木
- YandexのCatBoost
リッジ回帰
# Create Ridge regression classifier
ridge_clf = RidgeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
ridge_model = ridge_clf.fit(X_train, y_train)
y_pred = ridge_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
デシジョンツリー
# Create Ridge regression classifier
dt_clf = DecisionTreeClassifier(class_weight=class_weight, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(pd.get_dummies(X), y, test_size=0.33, random_state=42)
# Train model
dt_model = dt_clf.fit(X_train, y_train)
y_pred = dt_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:", weighted_accuracy(y_test,y_pred))
CatBoost

# Create boosting classifier
catboost_clf = CatBoostClassifier(class_weights=class_weight, random_state=42, cat_features = X.select_dtypes(include=['category', object]).columns)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
# Train model
catboost_model = catboost_clf.fit(X_train, y_train, verbose=False)
y_pred = catboost_model.predict(X_test)
print(classification_report(y_test,y_pred))
print("weighted_accuracy:",weighted_accuracy(y_test,y_pred))
ご覧のとおり、バイアスと正規化が高いリッジ回帰モデルは、CatBoostよりも優れた結果を示しています。あまり有用ではなく同一直線上にない機能が多数あるため、それらに耐性のあるメソッドは良好な結果を示します。
DTの詳細-データセットを少し変更するとどうなりますか?意思決定ツリーは一般にデータのシャッフルに対しても機密性の高い方法であるため、機能の重要性はさまざまです。
結論:時には簡単な方がより良く、より効果的です。
スケーラビリティ
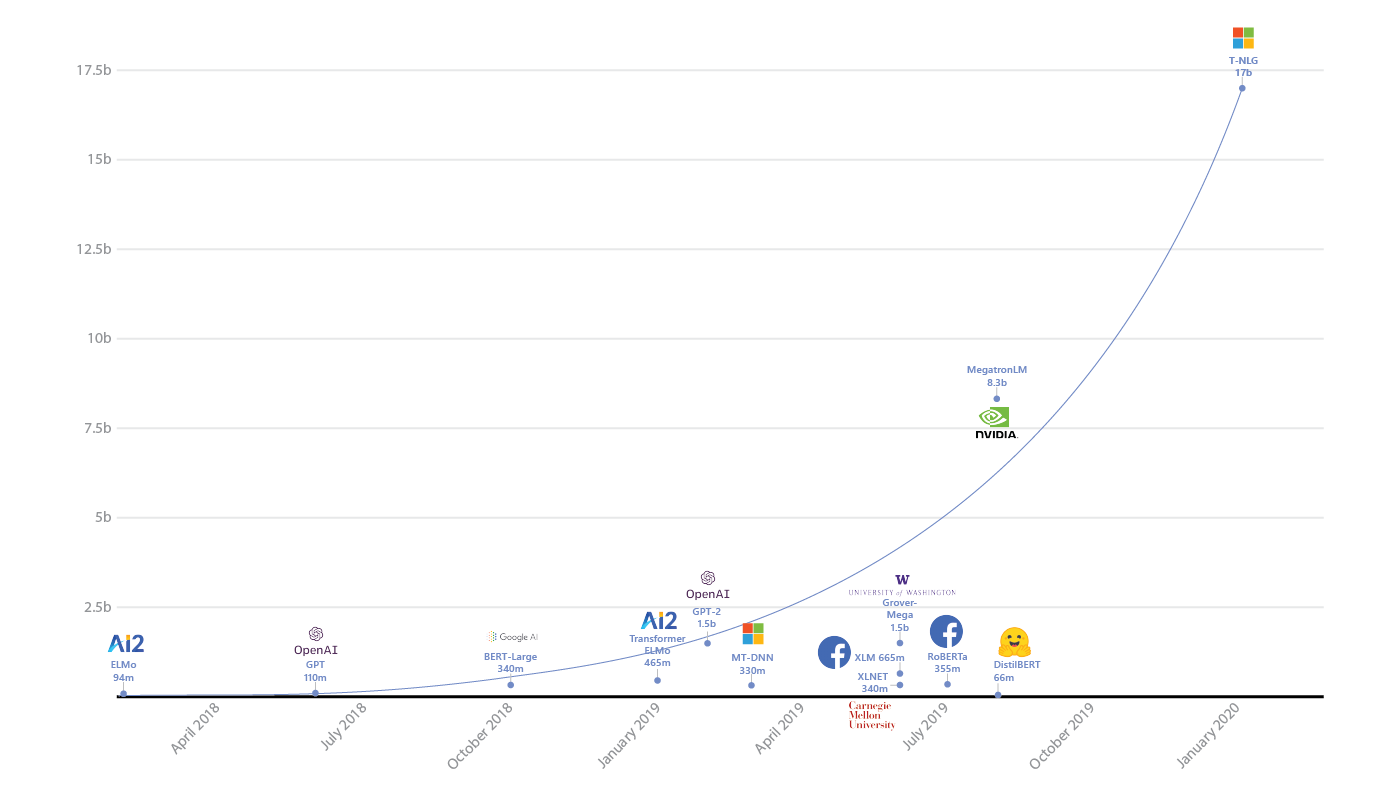
何十億ものパラメータを持つSparkまたはニューラルネットワークが本当に必要ですか?
まず、データの量を慎重に評価する必要があります。1台のマシンのメモリに簡単に収まるタスクでsparkが大量に使用されていることはすでに見てきました。
Sparkは、デバッグを複雑にし、オーバーヘッドを追加し、開発を複雑にします。必要のない場所で使用しないでください。クラシック。
次に、もちろん、モデルの複雑さを評価し、それをタスクに関連付ける必要があります。競合他社が優れた結果を示し、RandomForestを実行している場合、数十億のパラメーターを持つニューラルネットワークが必要な場合は、よく考えてみる価値があります。
そしてもちろん、本当に大きなデータがある場合、モデルはそれらを処理できる必要があることを考慮に入れる必要があります-バッチから学習する方法、またはある種の分散学習メカニズム(など)。また、同じ場所で、データ量の増加に伴って速度を落としすぎないようにしてください。たとえば、カーネルメソッドでは、デュアルスペースでの計算に2乗のメモリが必要であることがわかっています。データサイズが10倍になると予想される場合は、利用可能なリソースに収まるかどうかをよく考えてください。
既製モデルの入手可能性
もう1つの重要な詳細は、事前にトレーニングできる、すでにトレーニング済みのモデルを検索することです。次の場合に理想的です。
- 多くのデータはありませんが、それらは私たちのタスクに非常に固有です-たとえば、医療テキスト。
- トピックは一般的に比較的人気があります-たとえば、テキストトピックを強調する-NLPでは多くの作品があります。
- あなたのアプローチは、原則として、例えばある種のニューラルネットワークのように、事前学習を可能にします。
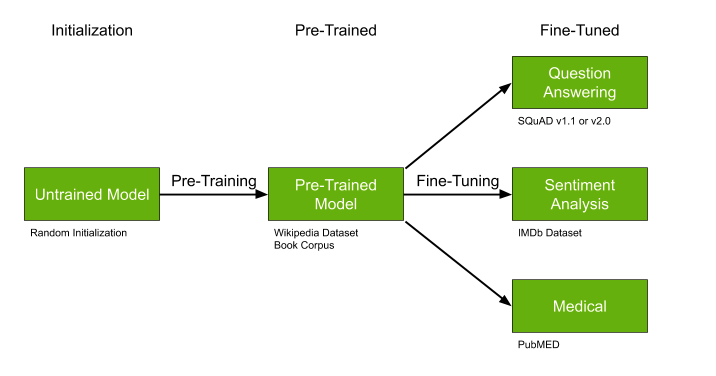
GPT-2やBERTのような事前にトレーニングされたモデルは、問題の解決を大幅に簡素化できます。すでにトレーニングされたモデルが存在する場合は、通り過ぎてこの機会を利用しないことを強くお勧めします。
機能の相互作用と線形モデル
一部のモデルは、機能間に複雑な相互作用がない場合(たとえば、線形モデルのクラス全体)、一般化された加法モデルのパフォーマンスが向上します。GA2Mと呼ばれる2つの機能間の相互作用の場合のために、これらのモデルの拡張があります-ペアワイズ相互作用を持つ一般化された加法モデル。
原則として、そのようなモデルはそのようなデータで良好な結果を示し、非常に規則化され、解釈可能で、ノイズに対してロバストです。したがって、それらに注意を払うことは間違いなく価値があります。
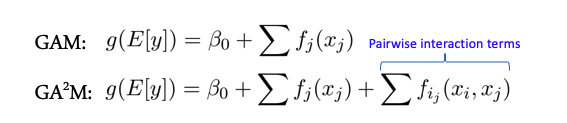
ただし、兆候が2つを超えるグループで活発に相互作用する場合、これらの方法ではそのような良好な結果は示されなくなります。
パッケージとモデルのサポート
記事からの多くのクールなアルゴリズムとモデルは、python、Rなどのモジュールまたはパッケージの形で提供されます。長期的にそのようなソリューションを使用して信頼する前に、本当によく考える価値があります(私は、このようなコードでMLに関する多くの記事を書いた人としてこれを言います)。作者は他のプロジェクトに従事する必要がある可能性が高く、時間もモジュールやリポジトリの開発に投資するインセンティブもないため、1年でサポートがゼロになる可能性は非常に高くなります。
この点で、la scikitが学習するライブラリは、実際に熱狂的なファンのグループが保証されており、何かが深刻に壊れた場合、遅かれ早かれ修正されるため、優れています。
バイアスと公平性
自動的な意思決定に加えて、そのような決定に不満を持っている人々が生き返ります-私たちが大学での奨学金や研究助成金の申請のためのある種のランキングシステムを持っていると想像してください。私たちの大学は珍しいでしょう-学生のグループは歴史家と数学者の2つだけです。突然、システムがそのデータと論理に基づいて、すべての助成金を歴史家に突然配り、どの数学者にも授与しなかった場合、これは数学者を弱く怒らせることはないかもしれません。彼らはそのようなシステムを偏ったと呼ぶでしょう。今では怠け者だけがこれについて話しません、そして企業と人々はお互いを訴えています。
従来、記事の引用を数え、歴史家がお互いに積極的に引用する単純化されたモデルを想像してみてください-平均は100引用ですが、数学はなく、平均20です-そして彼らはほとんど書いていません、そしてシステムは引用率が高いのですべての歴史家を「良い」と認識します100> 60(平均)、および数学者は、すべて平均20 <60よりも引用率がはるかに低いため、「悪い」と見なされます。このようなシステムは、誰かにとって適切とは思えません。
古典は現在、そのような偏ったアプローチと戦う意思決定とトレーニングモデルの論理を提示しています。したがって、各決定について、なぜそれが行われたのか、そしてモデルがでたらめにならないようにするために実際にどのように努力したのかを(条件付きで)説明します(ELI5GDPR)。ここで

Googleからもっと読む、またはここの記事で。
一般に、特にGDPRのリリースに照らして、多くの企業がそのような活動を開始しています。このような対策とチェックは、将来の問題を回避するのに役立ちます。
あるトピックが他のトピックよりも興味を持っている場合は、コメントに書き込んでください。さらに深く掘り下げます。(DFS)!
