ほとんどすべてのビジネスは変動する負荷に直面しています。今は沈黙し、次にスコールです。あなたは例のために遠くまで行く必要はありません:
- オンラインストアのトラフィックは、時間帯や季節によって大きく変動する可能性があります。
- 企業の内部サービスは数週間「空」になる可能性があり、四半期報告書の提出の前夜に、彼らの出席は急激に増加します。
カットの下で、カスタムIOPSを備えた新しいストレージ階層を導入することにより、お客様がこの問題を解決するのをどのように支援したかについて説明します。
ディスクについて一言
すべてのクライアントは、ビジネスプロセスの要件を満たす信頼性の高いインフラストラクチャを手頃な価格で入手することを望んでいます。したがって、私たちはクラウドプロバイダーとして、各クライアントに最適なソリューションを簡単に見つけることができるような方法でサービスとサービスを構築するという課題に直面しています。
以前は、st2とgp2の2つのストレージ層がありました。内部用語の「2」という数字は、新しく改良されたバージョンを意味します。
st2:標準(HDD) -のんびりと安価なSASHDDメディア。 IOPSは重要ではないが、帯域幅は重要なサービスに最適です。
それらのパラメータは次のとおりです。応答時間-10ミリ秒以下、最大2000GBのディスクのパフォーマンス-500IOPS、2000GBから1000IOPS、帯域幅はギガバイトごとに増加し、同じ2000GBで500MB /秒に達します。
gp2:ユニバーサル(SSD) -より高価で高速なSASSSDドライブ。 IOPSの観点からアプリケーションがより要求の厳しいお客様に適しています。たとえば、オンラインストアのデータベース。
Gp2パラメーターはSLAで指定されます。 IOPSのパフォーマンスは、ボリュームによって計算されます。GBあたり10IOPSがあります。一番上のバーは10,000IOPSです。そして、そのようなディスクの応答時間は2ミリ秒以下です。これは非常に高性能で、ビジネスタスクの97%をカバーできます。
長年の作業を通じて、お客様に関する多くの統計と専門知識を蓄積してきましたが、2つのドライブオプションから選択することに完全に満足していないものもあることに気づきました。たとえば、ギガバイトあたり10IOPSよりも優れたパフォーマンスが必要な場合があります。または、フローティングロードでは、いずれかのタイプで停止できず、ラッシュアワーの準備のために料金を支払うことはできませんが、定期的にアイドル状態の容量もオプションではありません。
単純な局所的なケースをシミュレートできます。パンデミックの間、ある会社は従業員にパスを発行する必要がありました。彼らが安全にモスクワをドライブできるように。スタッフは2000人と大勢です。企業のCRMシステムの個人データを緊急に更新するように命令が出されました。否や言うほどない。 1000人以上が同時に情報を更新するために急いでいました。しかし、倹約家はCRMに従事していました。容量はほとんど割り当てられていません。 10人以上が同時に登るとは誰も予想していませんでした!すべてが落ちて、別の日のために上がることができませんでした。ビジネスプロセスが中断され、人々は家に座って罰金を恐れています。また、クラウド内のディスクのパフォーマンスを柔軟に「微調整」する機会があれば、IOPSを短時間上げてから元に戻すことで、CRMのダウンタイムを排除または大幅に削減します。
一方で、状況はグロテスクであり、そのようなニーズを持つ顧客の割合はそれほど多くありません。小さなプロバイダーは、統計上の異常として存在することさえあり、何の行動も取りません。一方、新しいレベルのストレージを編成することで、すべての顧客に対するサービスの柔軟性を高めることができます。それは私たちがそれをしなければならないことを意味します。
長い間ブログをフォローしている場合は、Dell EMC ScaleIO(現在はPowerFlex OS)を使用した一連の実験とCROCクラウドでの実装について説明した記事を覚えていると思います。とはいえ、一般的な理解のために、よく理解しておくことをお勧めします。
一般的に言って、ScaleIO(DellEMCは最初にScaleIOをVxFlex OSに、2020年6月25日からPowerFlex OSに名前を変更しました)は、非常に用途が広く信頼性の高いソフトウェア定義ストレージ、SDSです。信頼性は私たちの要件#0です。したがって、ストレージプールの一部を形成する各ノードは、個別のラックにインストールされます。これにより、データセンターまたはラック内で部分的に電力が失われた場合にデータが失われる可能性がなくなります。
ディスク、サーバー、またはラック全体に障害が発生した場合、データを他のホストに複製し、その後障害が発生した要素を置き換えるのに十分な時間があります。 2つのラックが同時に死んだ場合でも、何も失われません。この状況では、クラスターは緊急モードになり、ディスクからのデータの書き込みと読み取りは制限されますが、「落ちた」ラックとの接続が回復した後、PowerFlexOS自体がデータの再構築とクラスターの回復のプロセスを引き継ぎます。ちなみに、このプロセスはほとんどの場合、数分しかかかりません。
もちろん、これは緊急事態です。読み取りと書き込みができないアプリケーションはすぐに「フォールオフ」しますが、インフラストラクチャのそのような大部分が失われたとしても、データが破壊されることはありません。タービンホールの異なる部分にある2つのラックが故障する可能性は非常に低いですが、これはそれを考慮に入れるべきではないという意味ではありません。
汎用性の観点から、PowerFlex OS(以前のScaleIO)も私たちの要件に理想的です。実際、これはコンストラクターであり、あらゆるワークロードを受け入れる準備ができており、低速のSATA / SAS HDD、高速のSSD、および超高速のNVMEドライブを「受け入れる」ことができます。そして、これは本当に真実です-それは開発および保守チームの多くのステージおよびテストスタンドでテストされており、古い鉄の
5から6までの音楽
実際の例を使用して、顧客が柔軟なパフォーマンスを必要とする可能性があるシナリオの1つを見てみましょう。私たちのクライアントの中には楽器店のネットワークがあります。同社の技術者は、毎日および1時間にサイトにアクセスする訪問者の数を追跡します。これはSLAにも反映されています。17:00から18:00まで、ストアは最大数の顧客を受け入れるため、技術的な作業やダウンタイムは発生しません。
標準的な計算方法は、負荷の100%を24時間に分割する場合です。 1時間ごとに約4%になります。一連のミュージックストアの場合、この特定の時間は4ではなく10%「重く」なります。これは数万人の訪問者と顧客です。
したがって、この「ゴールデン」時間にディスクが魔法のように速くなれば、顧客にとって非常に便利です。
今では、最も忙しい時間帯に少なくとも30、少なくとも5万IOPSをクライアントに提供し、残りの時間はパフォーマンスを通常のレベルに保つ機会があります。このタイプのストレージをio2:Ultimate(SSD)と呼びました。このタイプのストレージに基づくディスクの応答時間は1ミリ秒以下です。
また、信頼性についても説明します。st2、gp2、および新しいio2は独立しており、PowerFlexクラスター内のストレージプールは互いに独立しています。
以前にクライアントがディスクを選択して固定パフォーマンスを受け取った場合、クライアントはディスクのパフォーマンスを選択して構成できるようになりました。ボリュームに関係なく。哲学は次のとおりです。多数のプロバイダーから巨大で高速なディスクを入手できますが、100%の時間で支払う準備はできていますか?
管理する方法
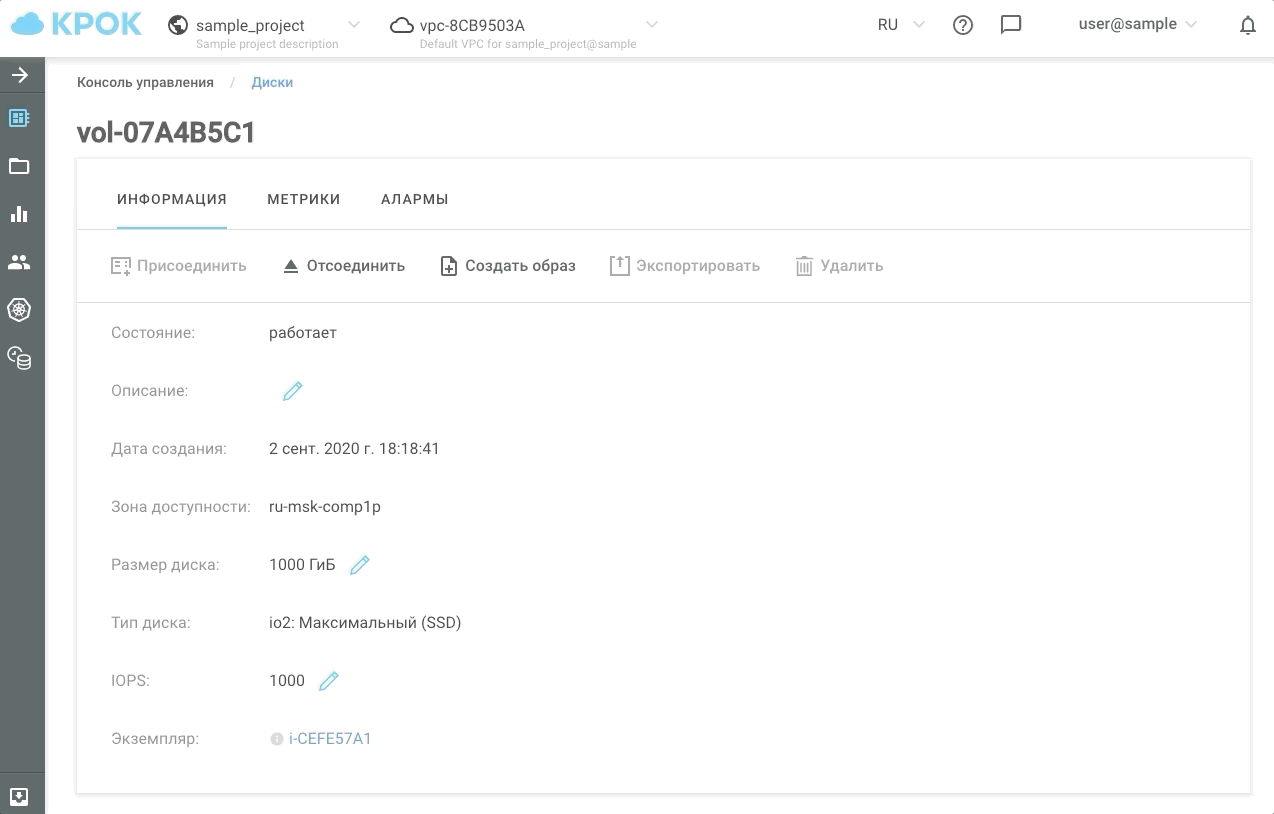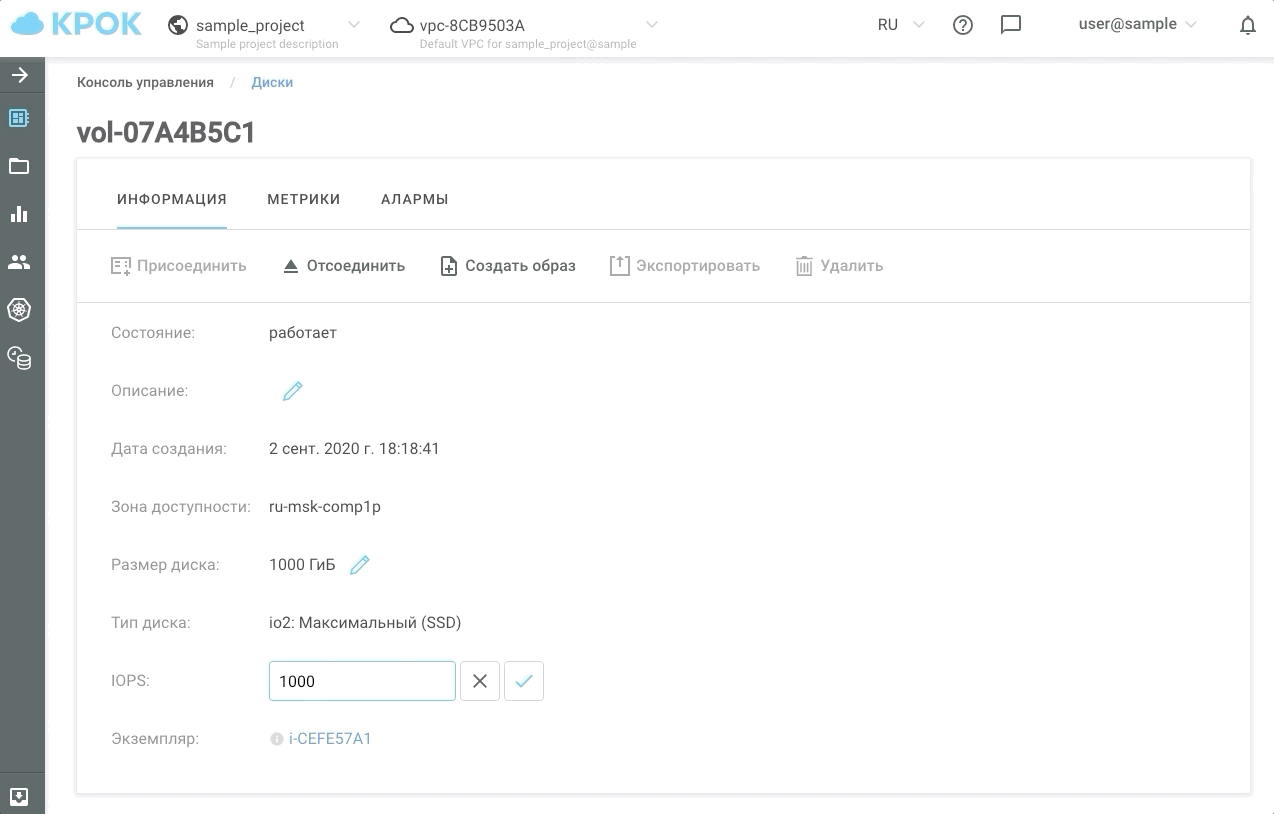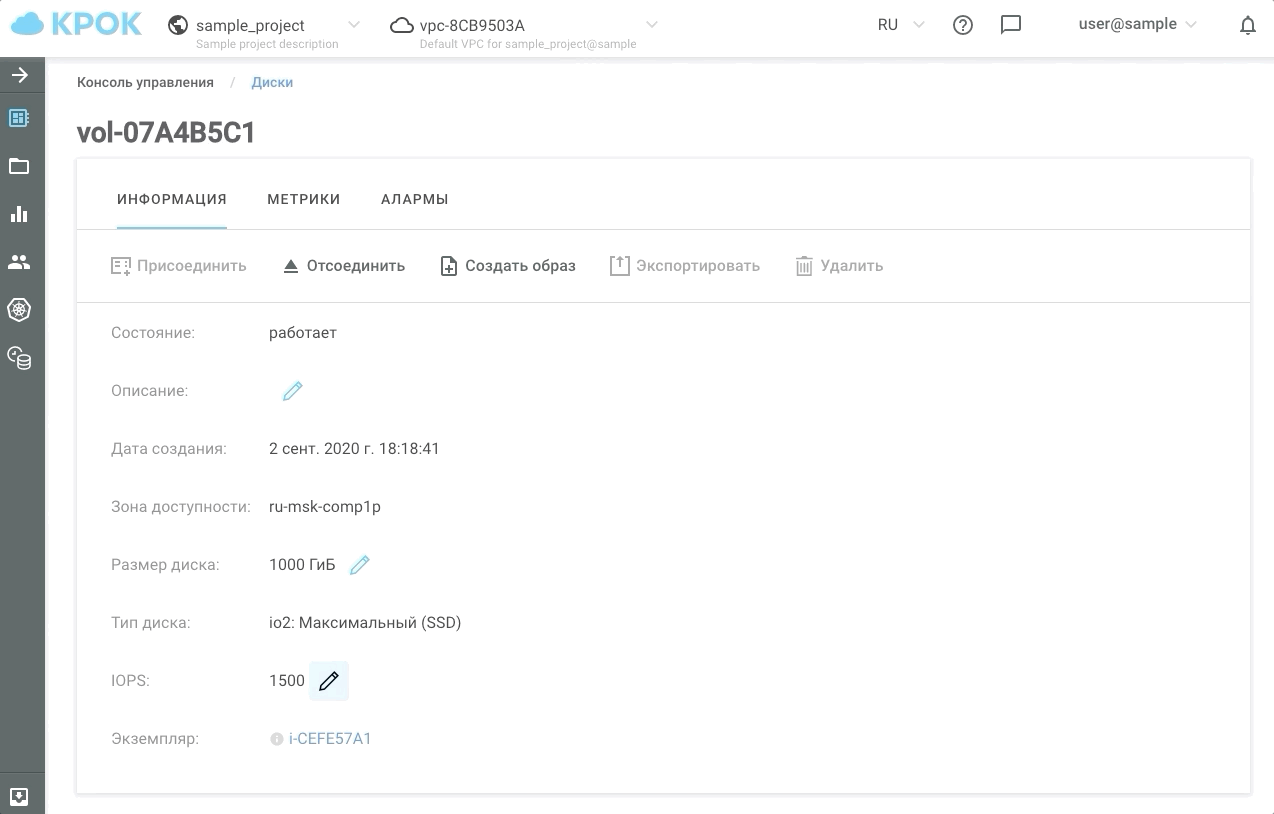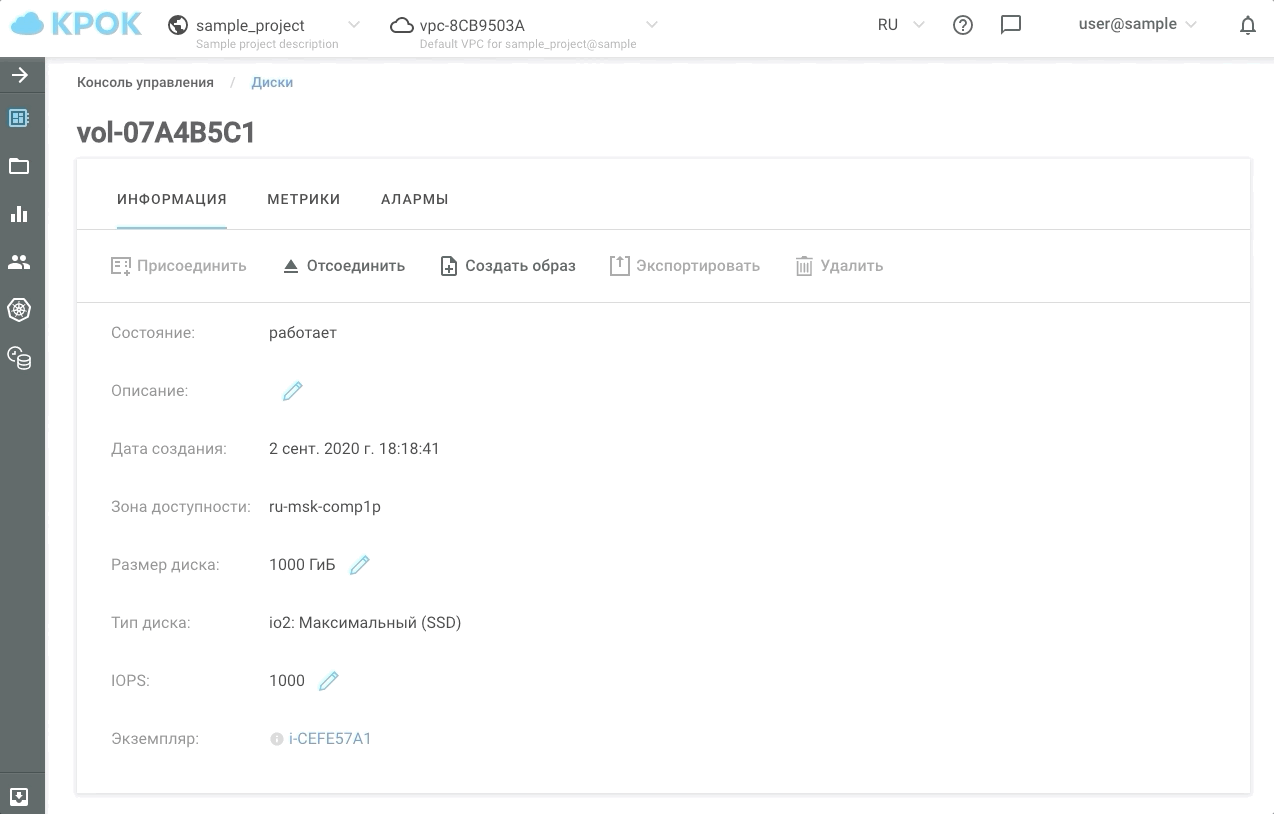
パフォーマンスを管理するには、2つの方法があります。それは、Webインターフェイスを使用する方法と、APIを使用する方法です。これにより、スケジュールに従ってディスクを「スピードアップ」または「スローダウン」する簡単なスクリプトを作成できるため、コストを節約できます。
以前はクライアントが必要とする負荷をかけることができましたが、今では最良の価格でそれを行うことができます。
これが実際の外観です。
クラウドインフラストラクチャの適応性を高めることは、関連性があり、非常に正しい傾向です。あなたは顧客に言うことはできません:「彼らが与えるものを取りなさい、さもないとこれさえ起こらないでしょう!」彼は、必要なリソース、時期、量を決定できなければなりません。将来は、そのような柔軟で信頼性の高いソリューションにあります。
私たちは私たちのサービスを保証します:すべてのパラメーターはSLAで詳しく説明されており、「紙」の数字が実際の数字から逸脱しないという事実を信頼できます。
また、クラウドプロバイダーを確認する方法については、前の記事ですでに説明しました。