私たちは、文書のレジスタを持っていると仮定し、その中で事業者や会計士の仕事VLSI、このような: 伝統的に、ディスプレイ用途のいずれかを直接(新しい下)または(新しいトップを)逆日付と序数識別子によってソート文書を作成するときに割り当てられた-または..。 この場合に発生する一般的な問題については、「PostgreSQLアンチパターン:レジストリのナビゲート」の記事ですでに説明しました。しかし、いくつかの理由のために、ユーザが「非定型」に望んでいる場合-例えば、ソートつのフィールド、および「そのような」別の「このような」 -

ORDER BY dt, idORDER BY dt DESC, id DESC
ORDER BY dt, id DESC?ただし、2番目のインデックスはデータベースへの挿入と余分なボリュームを遅くするため、作成する必要はありません。
インデックスのみを使用してこの問題を効果的に解決することは可能
(dt, id)ですか?
まず、インデックスの順序をスケッチしましょう
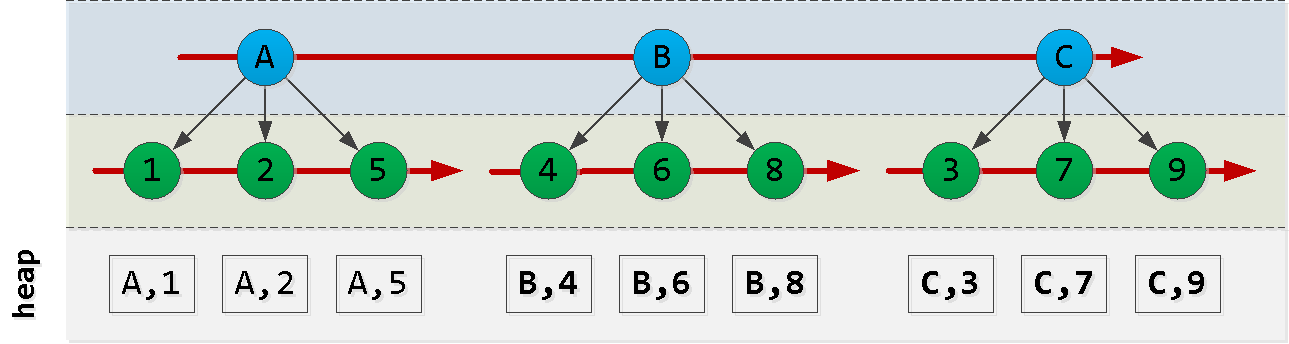
。idレコードの作成順序は、必ずしもdtの順序と一致するとは限らないため、信頼できず、何かを発明する必要があることに注意してください。
今、私たちは、ポイント(A、2)であり、ソートの「次」の6つの項目を読みたいと仮定: アハを!最初のノードからいくつかの「ピース」、最後のノードから別の「ピース」、およびそれらの間のノードからのすべてのレコードを選択しました()。このような各ブロックは、適切な順序ではありませんが、インデックスによって正常に読み取られます。 次のようなクエリを作成してみましょう。
ORDER BY dt, id DESC
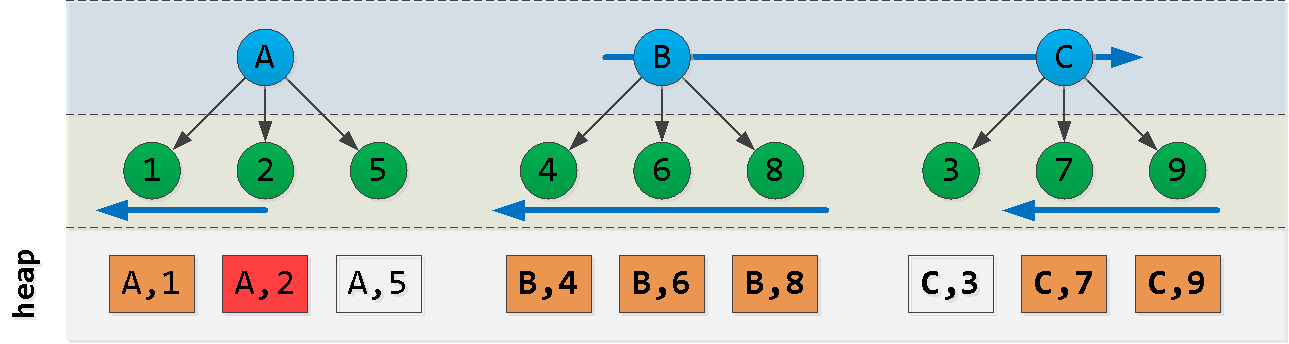
ACB(dt, id)
- 最初に、開始レコードの「左側」のブロックAから読み取ります-レコードを取得し
Nます - さらに
L - N、値Aの「右側」を読みます - 最後のブロックで最大キーCを見つけます
- このキーを使用して前の選択からすべてのレコードを除外し、「右側」で減算します
それでは、コードで描写してモデルを確認してみましょう。
CREATE TABLE doc(
id
serial
, dt
date
);
CREATE INDEX ON doc(dt, id); --
-- ""
INSERT INTO doc(dt)
SELECT
now()::date - (random() * 365)::integer
FROM
generate_series(1, 10000);すでに読み取られたレコードの数と、それとターゲット数の差を計算しないようにするために、「ハック」
UNION ALLとLIMIT:を使用してPostgreSQLにこれを強制的に実行させましょう。
(
... LIMIT 100
)
UNION ALL
(
... LIMIT 100
)
LIMIT 100次に、最後の既知の値からターゲットを並べ替えて、次の100レコードを収集しましょう。
(dt, id DESC)
WITH src AS (
SELECT
'{"dt" : "2019-09-07", "id" : 2331}'::json -- ""
)
, pre AS (
(
( -- 100 "" "" A
SELECT
*
FROM
doc
WHERE
dt = ((TABLE src) ->> 'dt')::date AND
id < ((TABLE src) ->> 'id')::integer
ORDER BY
dt DESC, id DESC
LIMIT 100
)
UNION ALL
( -- 100 "" "" A -> B, C
SELECT
*
FROM
doc
WHERE
dt > ((TABLE src) ->> 'dt')::date
ORDER BY
dt, id
LIMIT 100
)
)
LIMIT 100
)
-- C ,
, maxdt AS (
SELECT
max(dt)
FROM
pre
WHERE
dt > ((TABLE src) ->> 'dt')::date
)
( -- "" C
SELECT
*
FROM
pre
WHERE
dt <> (TABLE maxdt)
ORDER BY
dt, id DESC -- , B
LIMIT 100
)
UNION ALL
( -- "" C 100
SELECT
*
FROM
doc
WHERE
dt = (TABLE maxdt)
ORDER BY
dt, id DESC
LIMIT 100
)
LIMIT 100;何が起こったのか見てみましょう:

[explain.tensor.ruを見てください]
- したがって、最初のキーを使用して
A = '2019-09-07'3つのレコードを読み取ります。 - 彼らは別97を読み終え
BやC原因の正確なヒットにIndex Scan。 - すべてのレコードの中で、18は最大キーでフィルタリングされました
C。 Bitmap Scan最大キーを使用して、23レコード(検索された18レコードではなく)を読み取りました。- すべてがターゲット100レコードを再ソートおよびトリミングしました。
- ...そしてそれはすべて1ミリ秒未満かかりました!
もちろん、この方法は普遍的ではなく、多数のフィールドにインデックスを付けると非常にひどいものになりますが、ベースを
Seq Scan大きなテーブルに「折りたたむ」ことなく「非標準」の並べ替えをユーザーに提供したい場合は、慎重に使用できます。