
近年の深い学習は、Goのゲームで人々を打ち負かすことから、画像認識、音声認識、テキスト翻訳、その他のタスクで世界をリードすることまで、継続的な一連の成果です。しかし、この進歩には、計算能力に対する飽くなき増加が伴いました。 MIT、ヨンセ大学(韓国)、ブラジリア大学の科学者グループが、機械学習に関する1,058の科学論文のメタ分析を発表しました。機械学習(ML)の進歩が、システムの計算能力の派生物であることを明確に示しています。コンピューターのパフォーマンスは常にMLの機能を制限してきましたが、現在、新しいMLモデルのニーズはコンピューターのパフォーマンスよりもはるかに速く成長しています。
この研究は、機械学習の進歩は本質的にムーアの法則の結果にすぎないことを示しています。このため、コンピュータの物理的な制限により、多くのMLの問題は解決されません。
研究者は、画像分類(ImageNet)、オブジェクト認識(MS COCO)、質問回答(SQuAD 1.1)、名前付きエンティティ認識(COLLN 2003)、およびマシン変換(WMT 2014 En-to-Fr)に関する科学論文を分析しました。

コンピューティングクエリML、ログスケール
5つの領域すべての進捗状況は、コンピューティング能力の向上に大きく依存していることが示されています。この関係を外挿すると、これらの分野の進歩が急速に経済的、技術的、環境的に持続不可能になっていることが明らかになります。したがって、これらのアプリケーションをさらに進歩させるには、はるかに計算効率の高い方法が必要になります。
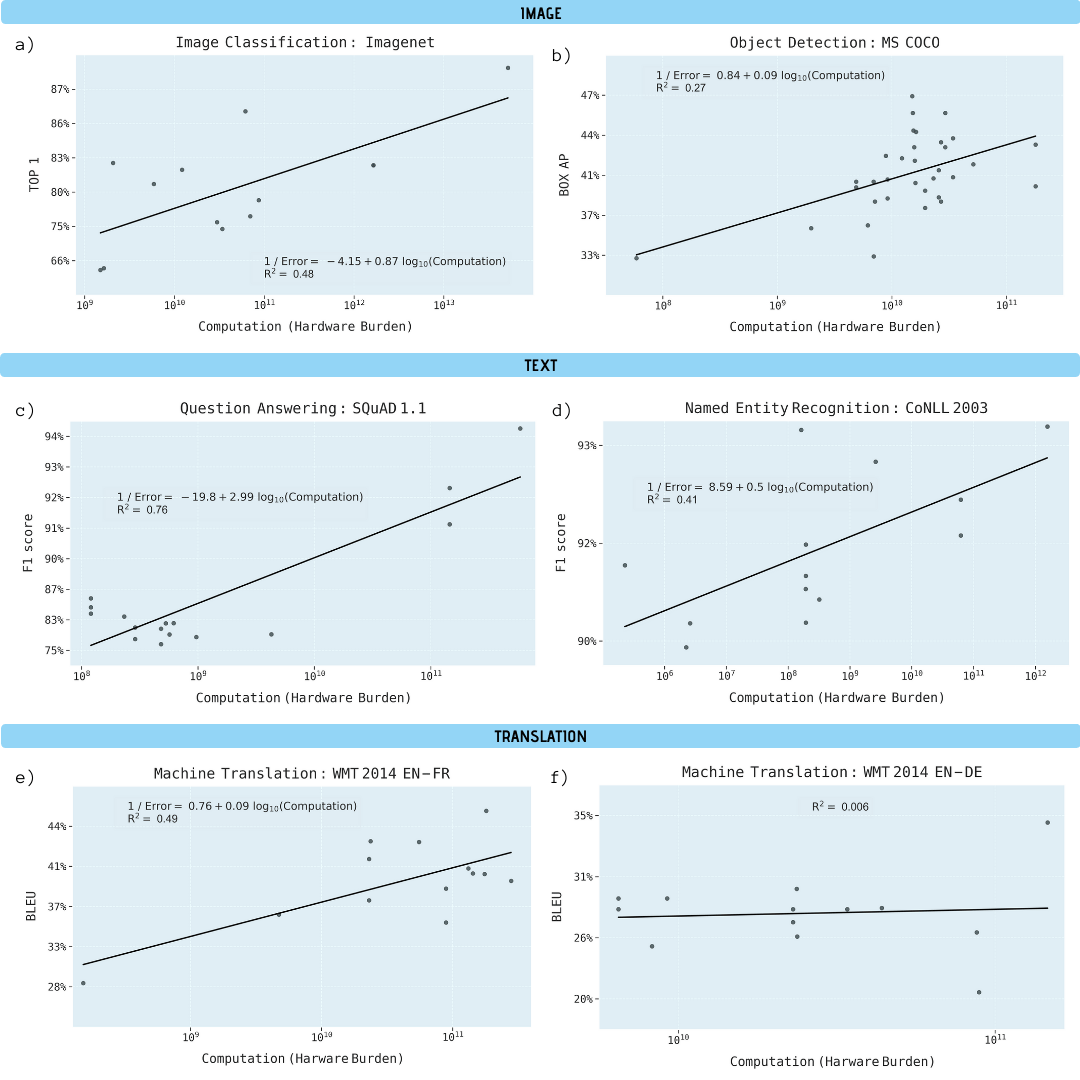
学習モデルの計算能力の関数としてのさまざまな機械学習タスクのパフォーマンスの向上(ギガフロップ単位)
なぜ機械学習は計算能力にそれほど依存しているのですか
深い学習は本質的に他の方法よりも計算に依存していると信じる重要な理由があります。特に、ハイパーパラメータ化の役割とシステムのスケールアップ方法により、追加のトレーニングデータを使用して結果の品質を向上させる場合(たとえば、分類エラーの頻度を減らすため、平均二乗回帰エラーなど)。
ハイパーパラメータ化は、トレーニングに使用できるデータポイントの数よりも多くのパラメータを使用してニューラルネットワークを実装するという大きな利点を提供することが証明されています。古典的に、これはオーバーフィットにつながります。しかし、確率的勾配最適化手法は、早期停止を犠牲にして正規化効果を提供し、中間点で妥当な予測を維持しながら、トレーニングデータがほぼ正確に適合する補間モードにニューラルネットワークを配置します。ハイパーパラメータ化を使用した大規模ネットワークの例は、120万のImageNetデータポイントに対して4億8000万のパラメータを持つ最高のパターン認識システムNoisyStudentの1つです。
ハイパーパラメータ化の問題は、データポイントの数が増えるにつれて、深層学習パラメータの数を増やす必要があることです。深層学習モデルのトレーニングのコストは、パラメーターの数とデータポイントの数の積に比例するため、これは、計算要件が、ハイパーパラメーター化されたシステムのデータポイントの数の少なくとも2乗だけ増加することを意味します。二次スケーリングでは、線形パフォーマンスを向上させるためにトレーニングデータの量を線形よりもはるかに速くスケーリングする必要があるため、深層学習ネットワークの成長速度を十分に見積もることはできません。
可能な1000のうち10の非ゼロ値を持つ生成モデルを検討し、これらのパラメーターを発見しようとする4つのモデルを検討します:
- : 10
- : 9 1
- : 1000 ,
- : , 1000 , ()
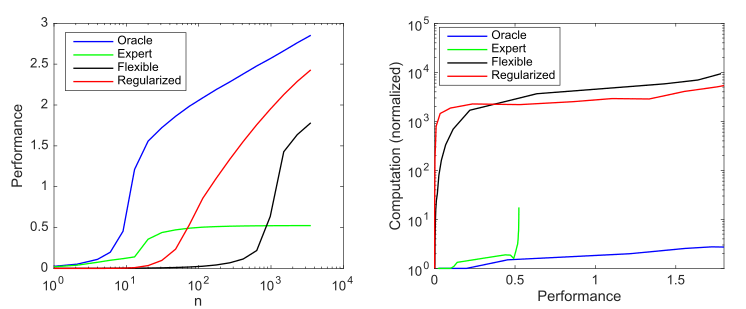
モデルの複雑さと正規化がモデルのパフォーマンス(負のlog 10正規化ルート平均二乗誤差対最適な予測子として測定)およびケースあたり1000回のシミュレーションで平均化された計算要件に与える影響。 a)サンプルサイズの増加に伴う平均生産性。 b)パフォーマンスを向上させるために必要な平均計算
このグラフは、Andrew Ngによって概説された原則をまとめたものです。従来の機械学習方法は小さなデータでうまく機能しますが、柔軟なMLモデルは大きなデータでうまく機能します。アジャイルモデルの一般的な現象は、潜在能力が高いだけでなく、データと計算のニーズが大幅に増えることです。
深層学習は、ハイパーパラメータ化を使用して非常に柔軟なモデルを作成し、(暗黙の)正規化を使用してサンプルの複雑さを許容可能なレベルに低減するため、うまく機能することがわかります。ただし、同時に、深層学習は、より効率的なモデルよりも計算量が大幅に多くなります。したがって、MLの柔軟性を高めることは、大量のデータと計算に依存することを意味します。
計算上の制限
コンピュータのパフォーマンスは常にMLシステムの能力を制限してきました。
たとえば、Frank Rosenblattは、1960年に最初の3層ニューラルネットワークについて説明しました。彼女は「パーセプトロンをパターン認識デバイスとして使用する可能性を実証する」ことが期待されていました。しかし、Rosenblattは、「ネットワーク上の接続数が増えると、一般的なデジタルコンピューターの負荷がすぐに過剰になる」ことを発見しました。 1969年の後半、MinskyとPapertは、単純なXOR関数を学習できないなど、3層ネットワークの制限について説明しました。しかし、彼らは潜在的な解決策を指摘しました。「実験者は、中間ユニットのより長いチェーンを導入することによって(つまり、より深い神経ネットワークを構築することによって)この困難を回避する興味深い方法を見つけました」。この潜在的な回避策にもかかわらず、この分野の学術研究の多くは放棄されました。当時は単に十分な計算能力がなかったからです。
KDPVに示されているように、その後の数十年間で、ハードウェアの改善により約50,000倍のパフォーマンスが向上し、ニューラルネットワークはそれに比例して計算ニーズを増加させました。計算能力の1ドルの増加は、チップあたりの計算能力とほぼ一致するため、このようなモデルを実行するための経済的コストは、長期にわたってほぼ安定しています。
このような大幅なCPU加速にもかかわらず、2009年の大規模アプリケーションには、深層学習モデルは依然として遅すぎました。これにより、研究者は小規模なモデルに集中するか、使用するトレーニング例を少なくする必要がありました。
ターニングポイントは、GPUへのディープラーニングの移行でした。5〜15回、2012年までに35倍に成長し、2012年のImagenetコンペティションでAlexNetに重要な勝利をもたらしました。しかし、画像認識は、深層学習システムが勝った最初のベンチマークにすぎませんでした。彼らはすぐに、オブジェクトの検出、名前付きエンティティの認識、マシンの翻訳、質問への回答、および音声認識で勝ちました。
GPU(そしてASIC)での深層学習の採用は、これらのシステムの広範な採用につながりました。しかし、最新のMLシステムの計算能力はさらに速く、2012年から2019年まで年に約10回増加しました。この速度は、GPUへの移行による全体的な改善、ムーアの法則の最後のあえぎからの適度な増加、またはニューラルネットワークトレーニングの効率の改善よりもはるかに高速です。
代わりに、ML効率の主な向上は、より多くのマシンでモデルを長期間実行することによってもたらされました。たとえば、2012年にAlexNetは2つのGPUで5〜6日間トレーニングし、2017年にはResNeXt-101は8つのGPUで10日以上トレーニングし、2019年にはNoisyStudentは約1,000のTPUで6日間トレーニングしました。もう1つの極端な例は、Evolved Transformerマシン変換システムです。これは、トレーニングに200万時間を超えるGPU時間を使用し、数百万ドルの費用がかかりました。
ハードウェアクロックまたはチップを増やすことによって深層学習計算をスケーリングすることは、長期的には問題があります。これは、コストが計算能力の増加とほぼ同じ割合で拡大することを意味し、それがすぐにそれ以上の成長を不可能にするためです。
未来
上記からの悲しい結論。
次の表は、現在のモデルから推定した場合に、システムの計算能力とコストがML問題の特定の目標を達成する量を示しています。 機械学習タスクは、最も強力なスーパーコンピューターで実行されます。 科学研究の著者は、設定された目標の要件が満たされないだろうと信じています。彼らはそれらを達成するための理論的に可能なオプションを検討しています:パフォーマンスを上げずに効率を改善する、TPUやFPGAなどのハードウェアアクセラレータ、ニューロモーフィックコンピューティング、量子コンピューティングなど、これらのテクノロジーはどれも(まだ)MLの計算限界を克服することはできません。

. .
