
今年3月の自己隔離への移行に伴い、多くの企業と同様に、すべての食料品イベントをオンラインに移行しました。さて、あなたはサルとのウェビナーについてのこの素晴らしい写真を覚えています。過去6か月間で、私のチームが担当するデータセンターのトピックについてのみ、約25の2時間の記録されたウェビナー、合計50時間のビデオを蓄積しました。完全に成長している問題は、特定の質問に対する回答を探すためにどのビデオでどのように理解するかです。カタログ、タグ、簡単な説明は良いです、まあ、私たちはついにトピックに関する4つの2時間のビデオがあることを発見しました、そしてそれから何ですか?巻き戻しを見ますか?どういうわけか違う方法で可能ですか?そして、あなたがファッショナブルな方法で行動し、AIを台無しにしようとしたら?
せっかちな人のためのネタバレ:完全な奇跡のシステムを見つけることも、膝の上に組み立てることもできなかったので、この記事には意味がありません。しかし、数日(というよりは夜)の調査の結果、私は実用的なMVPを手に入れました。これについてお話ししたいと思います。この記事の目的は、この問題への関心のレベルを調べ、知識のある人々からアドバイスを得て、おそらく同じ問題を抱えている他の誰かを見つけることです。
私がしたいこと
一見、すべてがシンプルに見えました。ビデオを撮り、それをニューラルネットワークで実行し、テキストを取得してから、関心のあるトピックを説明するテキスト内のフラグメントを探します。カタログ内のすべてのビデオを一度に検索するとさらに便利です。実際、テキストのトランスクリプトをビデオと一緒にアップロードすることは長い間発明されてきました。Youtubeやほとんどの教育プラットフォームはこれを行うことができますが、そこで人々がこれらのテキストを編集することは明らかです。目でテキストをすばやくスキャンして、目的の質問に対する答えがあるかどうかを理解できます。おそらく、便利な機能から、テキストの興味のある場所を突いて、講師が言ったり示したりすることを聞くことができても害はありません。テキスト内の単語のマークアップが時間内にあれば、これも難しくありません。さて、私は開発の可能な方向性を夢見ていました、最後に話しましょう、それでは、チェーンをできるだけ効率的に実装してみましょう。
ビデオファイル->テキストフラグメント->ファジーテキスト検索。
最初は、すべてがとても単純で、このケースはすでに4年間すべてのAI会議で議論されているので、そのようなシステムは既製であるはずだと思いました。記事を検索して読んだ数時間は、そうではないことを示しました。ビデオは主に、コールセンターのソリューションの一部として、顔、車、その他の視覚オブジェクト(マスク/ヘルメット)、オーディオ(曲、トラック、スピーカーのトーン/イントネーション)を探すために使用されます。Deepgramシステムについてのこの言及だけを見つけることができました。しかし、残念ながら、彼女はロシア語をサポートしていません。また、MicrosoftはStreamsで非常によく似た機能を備えていますが、ロシア語のサポートについての言及はどこにも見つかりませんでした。明らかに、そこにもありません。
さて、再発明しましょう。私はプロのプログラマーではありませんが(ちなみに、コードに対する建設的な批判は喜んで受け入れます)、時々「自分のために」何かを書いています。音声をテキストに変換できるニューラルネットワークは、(サプライズサプライズ)、音声からテキストへと呼ばれます。公開のスピーチからテキストへのサービスを見つけることができれば、それを使用してすべてのウェビナーでスピーチを「デジタル化」し、テキストでファジー検索を行うことができます。これは簡単な作業です。最初は「クラウドに登る」とは思っていなかったので、すべてをローカルで収集したかったのですが、ハブレに関するこの記事を読んだ後、音声認識はクラウドで行う方が本当に良いと判断しました。
音声からテキストへのクラウドサービスを探しています
スピーチからテキストへの変換が可能なサービスの検索では、ロシアで開発されたものを含め、そのようなシステムがたくさんあることがわかりました。その中には、Google、Amazon、MSAzureなどのグローバルクラウドプロバイダーもあります。ロシア語を含むいくつかのサービスの説明はここにあります。通常、検索エンジンの結果の最初の20行は一意になります。しかし、別の問題があります。将来、このシステムを本番環境に移行したいと考えています。これにはコストがかかります。私は、主要なクラウドとグローバルに契約を結んでいるCiscoで働いています。それで、リスト全体から、私は今のところそれらだけを考慮することにしました。
だから私のリストはGoogle、Amazon、Azure、IBM Watson(タイトルへのリンクは下の表と同じです)。すべてのサービスには、それらを使用できるAPIがあります。残りの可能性を分析した後、私は小さな表をまとめました。

IBM Watsonはこの段階でレースを去りました。私がロシア語で録音したものはすべて、ウェビナーからの短い抜粋で残りのプロバイダーをテストすることにしました。 AWSとAzureでアカウントを設定しました。将来的には、Microsoftはアカウントの設定に関してひびを入れるのが難しいことが判明したと言えます。私はアムステルダムのどこかでインターネットに「着陸」する企業ネットワークで働いていました。登録プロセス中に、自分の住所がロシアであるかどうかを2回尋ねられた後、システムはアカウントが管理上ブロックされているというメッセージを表示しました。 ..。この記事を書いている5日後、状況は変わっていないので、Azureをまだテストできていません。これは残念です!私は理解しています-セキュリティですが、これではまだサービスを試すことができません。後で状況が解決したときに、これを実行しようとします。
これとは別に、Yandex.Cloudでそのような機能をテストしたいと思います。理論的には、ロシア語の音声の認識が最適であるはずです。ただし、残念ながら、サービスのテストアクセスページには、テキストを「言う」機能しかなく、ファイルのダウンロードは提供されていません。そこで、2位はAzureと一緒に延期します。
だから、グーグルとアマゾンがあります、すぐにそれをテストしましょう!コードを作成する前に、すべてを手動で確認および比較できます。両方のプロバイダーには、APIに加えて、管理インターフェイスがあります。テストのために、私は最初に、可能であれば、最小限の専門用語を使用して、一般的な性質の10分のフラグメントを準備しました。しかし、その後、Googleはテストモードで最大1分のフラグメントをサポートしていることが判明したため、この57秒のフラグメントを使用してサービスを比較しました。
作業の結果に基づいて、両方のサービスが認識されたテキストを発行し、1分間隔で作業の結果を比較できます。
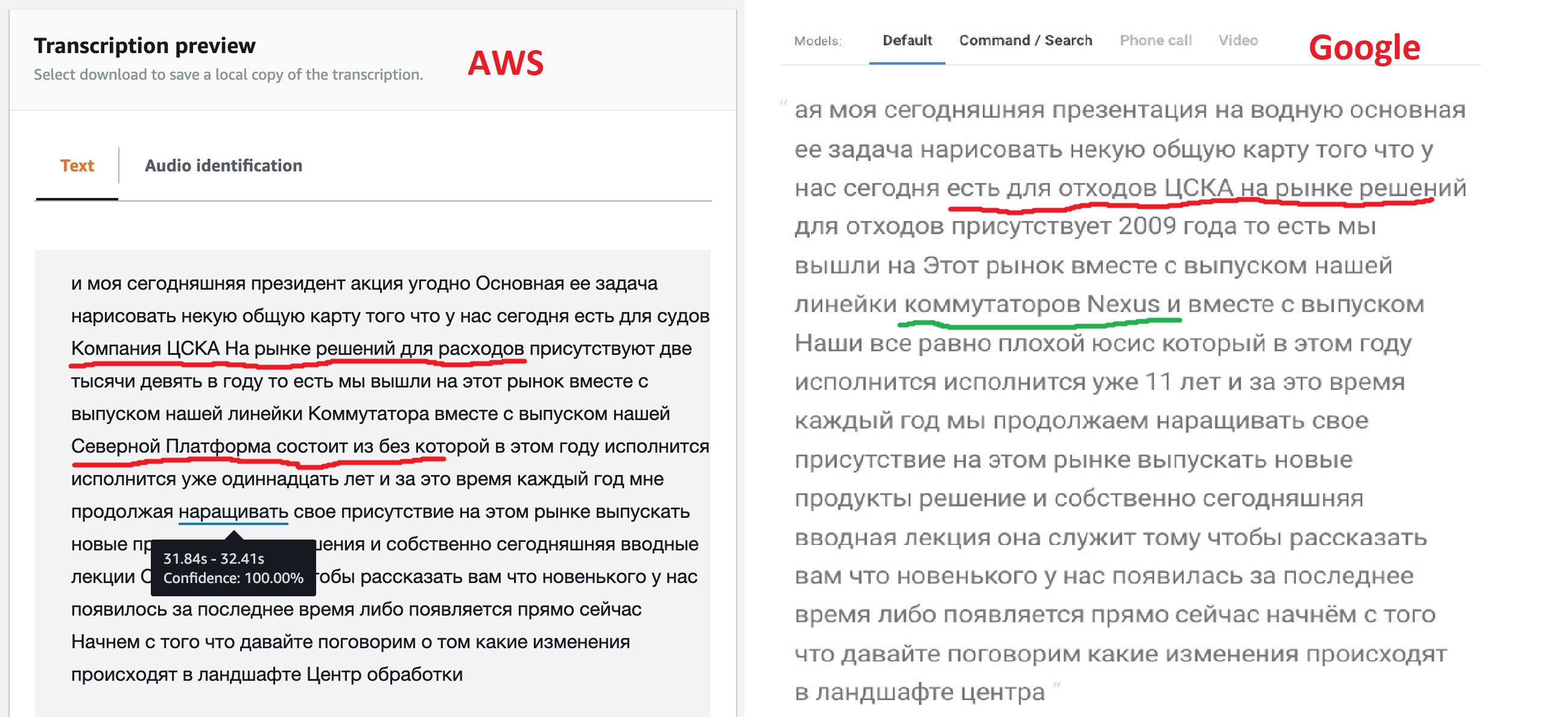
率直に言って、結果は期待どおりではありませんが、モデルがカスタマイズのためのさまざまなオプションを提供することは何の意味もありません。ご覧のとおり、「箱から出してすぐに」使用できるGoogleエンジンは、ほとんどのテキストをより明確に認識し、すべてではありませんが、一部の製品の名前も確認できました。これは、彼らのモデルが多言語テキストを可能にすることを示唆しています。アマゾン(後でこれが確認された)にはそのような機会がありません-彼らはロシア語を言いました、それは私たちが歌うことを意味します:「キンベイビーロム」とピリオド!
しかし、Amazonが提供するタグ付きJSONを取得する機能は、私には非常に興味深いように思えました。結局のところ、これにより、将来、目的のフラグメントが見つかったファイルの部分への直接遷移を実装できるようになります。すべての音声認識ニューラルネットワークがこのように機能するため、おそらくGoogleにもそのような機能がありますが、ドキュメントをざっと検索してもこの機能を見つけることができませんでした。

このJSONを見ると、翻訳されたテキスト(トランスクリプト)、単語の配列(アイテム)、およびセグメントのセット(セグメント)の3つのセクションで構成されていることがわかります。単語とセグメントの配列については、各要素について、その開始時刻と終了時刻、およびそれが正しく認識されたという神経ネットワークの信頼性が示されます。
データセンターを理解するためのニューラルネットワークの指導
そこで、この段階の終わりに、さらなる実験のためにAmazon Transcribeを選択し、学習モデルを設定することにしました。また、安定した認識が得られない場合は、Googleにご相談ください。さらなるテストは、10分のフラグメントで実行されました。
AWS Transcribeには、ニューラルネットワークが認識するものを調整するための2つのオプションと、テキストを後処理するための2つの機能があります。
- Custom Vocabularies – «» , , «» , . : «, , » Word 97- . , , .. .
- Custom Language Models – «» 10 . , . , , , .
- , , -. , – , .. -, .
それで、私はテキストのために私自身の言葉を作ることに決めました。明らかに、「ネットワーク、サーバー、プロファイル、データセンター、デバイス、コントローラー、インフラストラクチャ」などの単語が含まれます。 2〜3回のテストの後、私の語彙は60語に増えました。この辞書は、通常のテキストファイルで、1行に1単語、すべて大文字で作成する必要があります。単語の発音を指定する機能を備えた、より複雑なオプション(ここで説明)もありますが、最初の段階では、単純なリストを使用することにしました。
辞書を使用する前に、それを作成する必要があります。Amazon Transcribeの[ Custom vocabulary ]タブで、[ Create Vocabulary ]をクリックし、ファイルのテキストをロードし、ロシア語を指定し、残りの質問に答えると、辞書の作成プロセスが始まります。彼が出たら処理が準備完了になります-辞書を使用できます。
問題は残っています-「英語」の用語をどのように認識するか?辞書は1つの言語しかサポートしていないことを思い出させてください。最初は、英語の用語を使って別の辞書を作成し、同じテキストを実行することを考えました。Cisco、VLAN、UCSなどの用語が検出された場合等c確率率100%-指定された時間フラグメントに対してそれらを取得します。しかし、すぐに機能しなかったと言います。英語のアナライザーは、テキスト内の用語の半分以上を認識しませんでした。考えてみたところ、これらすべての用語を「ロシアのアクセント」で発音しているので、英米人でさえ初めて私たちを理解していないので、これは論理的であると判断しました。これは、「聞いたとおりに書かれている」という原則に従って、これらの用語をロシアの辞書に単純に追加するというアイデアを促しました。Cisco、usies、eisiai、vilan、viikslan-結局のところ、私たちはお互いに通信するときに正直に言っています。これにより、辞書が数十語増えましたが、将来的には、認識品質が1桁向上しました。
「いい考えが来る」ということわざにあるように、最初の辞書はすでに作成されているので、別の辞書を作成し、それにすべての略語を追加して、何が起こるかを比較することにしました。
辞書で認識を開始することで、同様に簡単です議事録のサービス上の転写ジョブ、タブを選択し、ジョブを作成し、ロシア語を指定し、辞書我々の必要性を指定することを忘れないでください。もう1つの便利なアクション-ニューラルネットワークにいくつかの代替検索結果を提供するように依頼できます。代替結果-はい項目、3つの代替オプションを設定します。後でファジーテキスト検索を行うときに、これは便利です。
10分のテキストの放送には4〜5分かかります。時間を無駄にしないために、結果を比較するプロセスを容易にする小さなツールを作成することにしました。 JSONファイルの最終テキストをブラウザに表示すると同時に、ニューラルネットワークによる個々の単語の検出の「信頼性」を強調します(同じ信頼性パラメータ)。結果のテキストには、デフォルトの翻訳、用語のない辞書、用語のある辞書の3つのオプションがあります。 3つのテキストすべてを3つの列に同時に表示します。信頼性の高い単語を緑で95%以上、黄色で95%から70%、赤で70%未満で強調表示します。結果のHTMLページの急いでコンパイルされたコードは以下のとおりです。JSONファイルはファイルと同じディレクトリにある必要があります。ファイル名は、FILENAME1変数などで指定されます。
結果を表示するためのHTMLページコード
<!DOCTYPE html>
<html lang="en">
<head> <meta charset="UTF-8"> <title>Title</title> </head>
<body onload="initText()">
<hr> <table> <tr valign="top">
<td width="400"> <h2 >- </h2><div id="text-area-1"></div></td>
<td width="400"> <h2 > 1: / </h2><div id="text-area-2"></div></td>
<td width="400"> <h2 > 2: / </h2><div id="text-area-3"></div></td>
</tr> </table> <hr>
<style>
.known { background-image: linear-gradient(90deg, #f1fff4, #c4ffdb, #f1fff4); }
.unknown { background-image: linear-gradient(90deg, #ffffff, #ffe5f1, #ffffff); }
.badknown { background-image: linear-gradient(90deg, #feffeb, #ffffc2, #feffeb); }
</style>
<script>
// File names
const FILENAME1 = "1-My_CiscoClub_transcription_10min-1-default.json";
const FILENAME2 = '2-My_CiscoClub_transcription_10min-2-Russian_only.json';
const FILENAME3 = '3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json';
// Read file from disk and call callback if success
function readTextFile(file, textBlockName, callback) {
let rawFile = new XMLHttpRequest();
rawFile.overrideMimeType("application/json");
rawFile.open("GET", file, true);
rawFile.onreadystatechange = function() {
if (rawFile.readyState === 4 && rawFile.status == "200") {
callback(textBlockName, rawFile.responseText);
}
};
rawFile.send(null);
}
// Insert text to text block and color words confidence level
function updateTextBlock(textBlockName, text) {
var data = JSON.parse(text);
let translatedTextList = data['results']['items'];
const listLen = translatedTextList.length;
const textBlock = document.getElementById(textBlockName);
for (let i=0; i<listLen; i++) {
let addWord = translatedTextList[i]['alternatives'][0];
// load word probability and setup color depends on it
let wordProbability = parseFloat(addWord['confidence']);
let wordClass = 'unknown';
// setup the color
if (wordProbability > 0.95) {
wordClass = 'known';
} else if (wordProbability > 0.7) {
wordClass = 'badknown';
}
// insert colored word to the end of block
let insText = '<span class="' + wordClass+ '">' + addWord['content'] + ' </span>';
textBlock.insertAdjacentHTML('beforeEnd', insText)
}
}
function initText() {
// read three files each to it's area
readTextFile(FILENAME1, "text-area-1", function(textBlockName, text){
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME2, "text-area-2", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
readTextFile(FILENAME3, "text-area-3", function(textBlockName, text) {
updateTextBlock(textBlockName, text);
});
}
</script>
</body></html>
3つのタスクすべてのasrOutput.jsonファイルをダウンロードし、HTMLスクリプトで記述された名前に変更すると、次のようになります。

ロシア語の用語を追加することで、ニューラルネットワークが特定の用語(「サービスプロファイル」など)をより正確に認識できるようになったことがはっきりとわかります。そして、2番目のステップでロシア語の文字起こしを追加すると、CSKAがciscoに変わりました。テキストはまだかなり「汚い」ですが、私のコンテキスト検索タスクにはすでに適しているはずです。新しいウェビナーが追加されて読まれるにつれて、語彙は徐々に拡大します。これは、忘れてはならないそのようなシステムを維持するプロセスです。
認識されたテキストのファジー検索
ファジー検索の問題を解決するには、おそらく12のアプローチがあります。ほとんどの場合、それらは、たとえばLevenshtein距離など、数学的なアルゴリズムの小さなセットに基づいています。これについての良い記事、もう1つそしてもう1つ。しかし、私は打ち上げや動作など、準備ができているものを見つけたかったのです。
ローカル文書検索のための既製のソリューションから、少し研究した後、私は比較的古いプロジェクトを見つけSPHINXを、フルテキスト検索の可能性は、それはそう、それはそれについて書かれている、PostgreSQLではあるHERE。しかし、ロシア語を含むほとんどの資料は、Elasticsearchについて見つかりました。のような良いスタートアップとセットアップガイドを読んだ後この投稿またはこのレッスン、ここに別のもの、およびPythonのドキュメントとAPIガイドがあり、私はそれを使用することにしました。
すべてのローカル実験で、私は長い間Dockerを使用してきましたが、何らかの理由でまだDockerを理解していないすべての人に、これを行うことを強くお勧めします。実際、私はローカルオペレーティングシステムで開発環境、ブラウザ、「ビューア」以外のものを実行しないようにしています。互換性の問題などがないことは別として。これにより、新製品をすばやく試して、うまく機能するかどうかを確認できます。
Elasticsearchを使用してコンテナをダウンロードし、次の2つのコマンドで実行します。
$ docker pull elasticsearch:7.9.1
$ docker run -d --name elasticsearch -p 9200:9200 -e "discovery.type=single-node" elasticsearch:7.9.1
コンテナを起動
http://localhost:9200すると、アドレスにエラスティックインターフェイスが表示され、ブラウザまたはPOSTMANツールのRESTAPIを使用してアクセスできます。しかし、私は便利なChromeプラグインを見つけました。
これは、上記のガイドの1つで説明されている面白い子猫に関する例でプラグインウィンドウがどのように見えるかです。
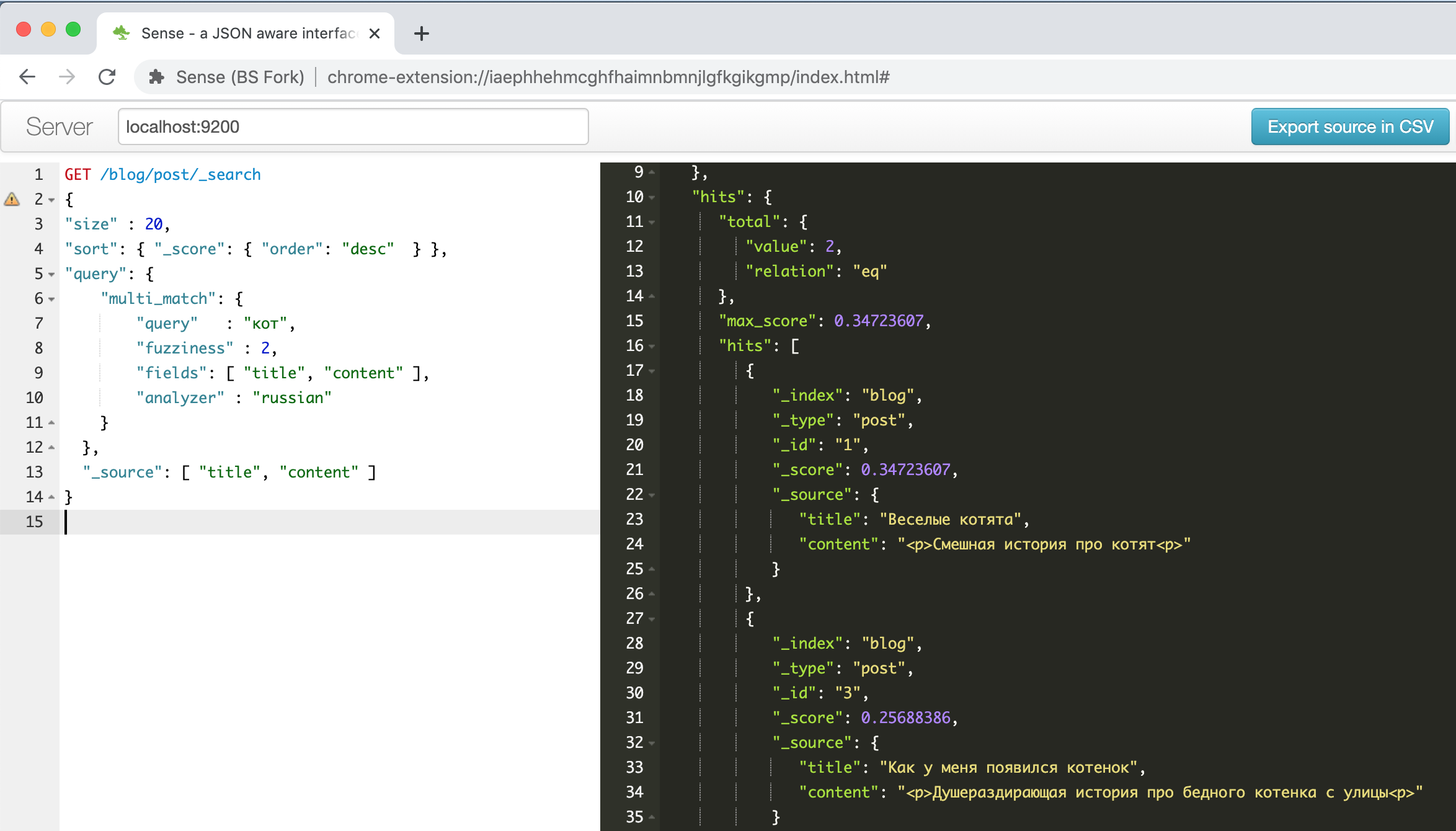
左側はリクエストです-右側は回答、自動完了、構文の強調表示、自動フォーマットです-生産性を高めるために他に何が必要ですか?さらに、このプラグインは、クリップボードから貼り付けられたテキストのCURLコマンドライン形式を認識して正しくフォーマットできます。たとえば、
「curl -X GET $ ES_URL」行を貼り付けて、何が起こるかを確認します。一般的には便利なものです。
何をどのように保存および検索しますか?Elasticsearchは、すべてのJSONドキュメントを取得し、それらをインデックスと呼ばれる構造に格納します。インデックスはいくつでも存在できますが、1つのインデックスに同種のデータとドキュメントを含めることができ、フィールドの構造は類似しており、検索方法も同じです。
ファジー検索の可能性を調査するために、前の手順で取得した転記ファイルのフレーズ(セグメント)セクションをダウンロードして検索することにしました。 JSONファイルのセグメントセクションでは、データは次の形式で保存されます。
- 1 (segment)
-> /
->
--> 1
---->
----> , (confidence)
--> 2
---->
----> , (confidence)
検索が成功する可能性を高めたいので、すべての代替オプションをデータベースにアップロードして検索し、見つかったフラグメントから全体の信頼性が高いものを選択します。
JSONドキュメントを再フォーマットしてElasticsearchにロードするには、小さなPythonスクリプトを使用します。スクリプトロジックは次のとおりです。
- まず、セグメントセクションのすべての要素とすべての代替転写オプションについて説明します。
- 各転写オプションについて、その全体的な認識の信頼性を考慮します。私は個々の単語の算術平均を取りますが、おそらく将来的には、これにもっと注意深く取り組む必要があります。
- 代替の転記オプションごとに、フォームのレコードをElasticsearchにロードします
{ "recording_id" : < >, "seg_id" : <id >, "alt_id" : <id >, "start_time" : < >, "end_time" : < >, "transcribe_score" : < (confidence) >, "transcript" : < > }
JSONファイルからElasticsearchにレコードをロードするPythonスクリプト
from elasticsearch import Elasticsearch
import json
from statistics import mean
#
TRANCRIBE_FILE_NAME = "3-My_CiscoClub_transcription_10min-v3_Russian_terminilogy.json"
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
es.indices.create(index=INDEX_NAME) # Create index for our recordings
# Open and load file
res = None
with open(TRANCRIBE_FILE_NAME) as json_file:
data = json.load(json_file)
res = data['results']
#
index = 1
for idx, seq in enumerate(res['segments']):
# enumerate fragments
for jdx, alt in enumerate(seq['alternatives']):
# enumerate alternatives for each segments
score_list = []
for item in alt['items']:
score_list.append( float(item['confidence']))
score = mean(score_list)
obj = {
"recording_id" : "rec_1",
"seg_id" : idx,
"alt_id" : jdx,
"start_time" : seq["start_time"],
"end_time" : seq ["end_time"],
"transcribe_score" : score,
"transcript" : alt["transcript"]
}
es.index( index=INDEX_NAME, id = index, body = obj )
index += 1
Pythonをお持ちでない場合でも、心配しないでください。Dockerが再びサポートしてくれます。私は通常、Jupyterノートブック付きのコンテナーを使用します。通常のブラウザーでコンテナーに接続して、必要なことをすべて実行できます。コンテナーが破棄されるとすべての情報が失われるため、結果の保存について考慮する必要があるのは1つだけです。これまでこのツールを使用したことがない場合は、初心者向けの優れた記事です。ちなみに、インストールに関するセクションはスキップしてかまいません。
次のコマンドを使用して、Pythonノートブックでコンテナを起動します。
$ docker run -p 8888:8888 jupyter/base-notebook sh -c 'jupyter notebook --allow-root --no-browser --ip=0.0.0.0 --port=8888'
そして、スクリプトが正常に起動された後に画面に表示されるアドレスにある任意のブラウザーで接続し
http://127.0.0.1:8888ます。これは、指定されたセキュリティキーを使用します。
新しいノートブックを作成します。最初のセルに次のように記述します。
!pip install elasticsearch
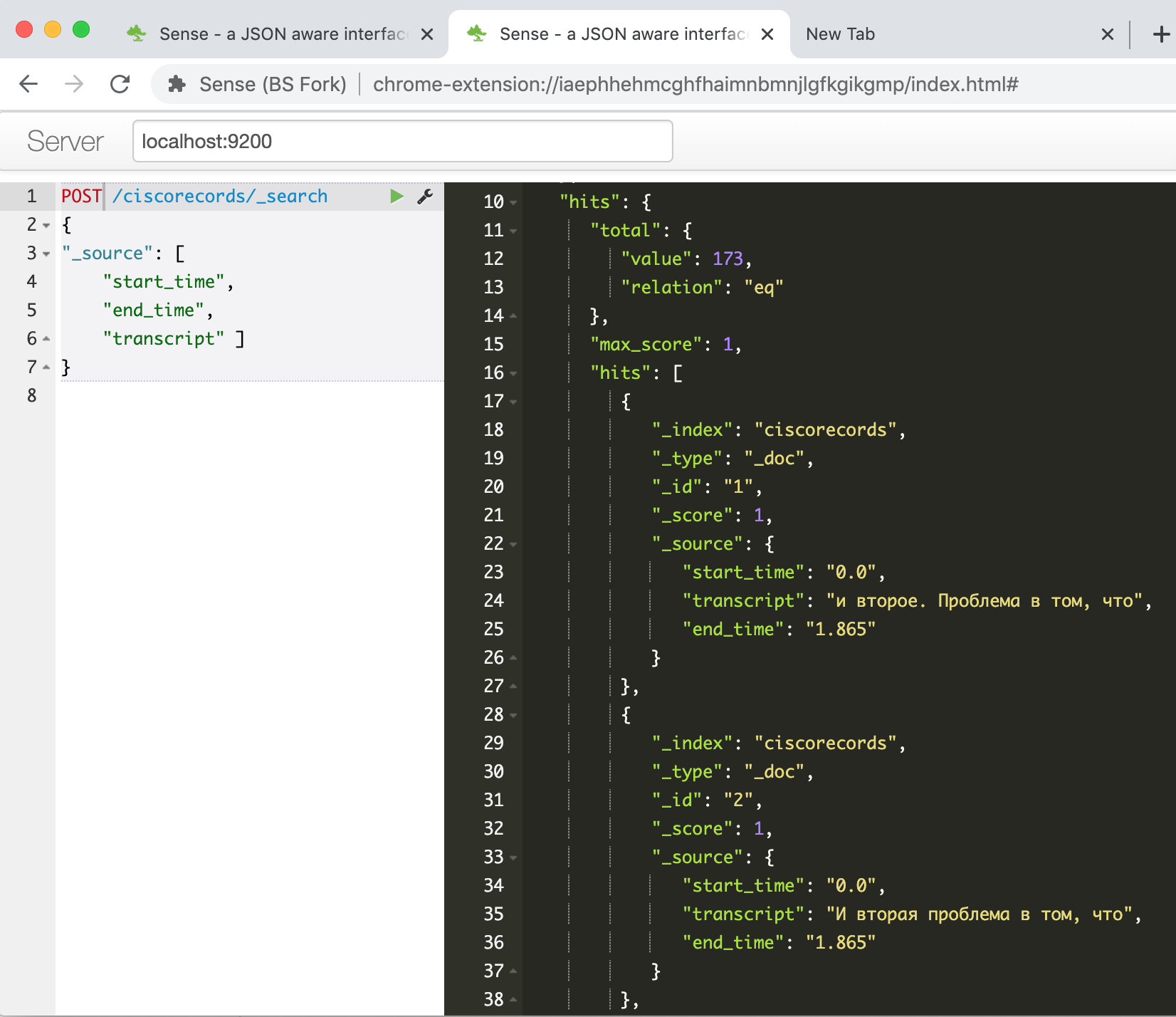
実行し、APIを介してESを操作するためのパッケージがインストールされるまで待ち、スクリプトを2番目のセルにコピーして実行します。作業後、すべてが成功した場合、Elasticsearchコンソールでデータが正常にロードされたことを確認できます。コマンドを入力する
GET /ciscorecords/_searchと、hits.total.valueフィールドに示されているように、ロードされたレコードが応答ウィンドウに合計173個表示されます。
今こそファジー検索を試すときです-それがすべてでした。たとえば、「データセンターネットワークのコア」というフレーズを検索するには、次のコマンドを実行する必要があります。
POST /ciscorecords/_search
{
"size" : 20,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : " ",
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
"_source": [ "transcript", "transcribe_score" ]
}
47もの結果が得られます!

当然のことながら、それらのほとんどは同じフラグメントの異なるバリエーションであるためです。別のスクリプトを作成して、各セグメントから信頼値が最も高い1つのレコードを選択してみましょう。
Elasticsearchデータベースにクエリを実行するPythonスクリプト
#####
#
# PHRASE = " "
# PHRASE = " "
PHRASE = " "
LOCAL_IP = "192.168.2.35"
INDEX_NAME = 'ciscorecords'
#
elastic_queary = {
"size" : 40,
"min_score" : 1,
"sort": { "_score": { "order": "desc" } },
"query": {
"multi_match": {
"query" : PHRASE,
"fuzziness" : 2,
"fields": [ "transcript" ],
"analyzer" : "russian"
}
},
}
# Setup Elasticsearch connection
es = Elasticsearch([{'host': LOCAL_IP, 'port': 9200}])
if not es.ping():
print ("ES connection error, check IP and port")
#
res = es.search(index=INDEX_NAME, body = elastic_queary)
print ("Got %d Hits:" % res['hits']['total']['value'])
#
search_results = {}
for hit in res['hits']['hits']:
seg_id = hit["_source"]['seg_id']
if seg_id not in search_results or search_results[seg_id]['score'] < hit["_score"]:
_res = hit["_source"]
_res["score"] = hit["_score"]
search_results[seg_id] = _res
print ("%s unique results \n-----" % len(search_results))
for rec in search_results:
print ("seg %(seg_id)s: %(score).4f : start(%(start_time)s)-end(%(end_time)s) -- %(transcript)s" % \
(search_results[rec]))
出力例:
Got 47 Hits:
16 unique results
-----
seg 39: 7.2885 : start(374.24)-end(377.165) -- , ..
seg 49: 7.0923 : start(464.44)-end(468.065) -- , ...
seg 41: 4.5401 : start(385.14)-end(405.065) -- . , , , , , ...
seg 30: 4.3556 : start(292.74)-end(298.265) -- , , ,
seg 44: 2.1968 : start(415.34)-end(426.765) -- , , , . -
seg 48: 2.0587 : start(449.64)-end(464.065) -- , , , , , .
seg 26: 1.8621 : start(243.24)-end(259.065) -- . . , . ...
結果がはるかに小さくなっていることがわかりました。これで、結果を表示して、最も関心のあるものを選択できます。
また、ビデオフラグメントの開始時刻と終了時刻があるため、ビデオプレーヤーを使用してページを作成し、プログラムで目的のフラグメントに「巻き戻す」ことができます。
ただし、このトピックに関する今後の出版物に関心がある場合は、このタスクを別の記事に入れます。
結論の代わりに
そこで、この記事の枠組みの中で、技術的なトピックに関するウェビナーの記録を備えたビデオツールを使用してテキスト検索システムを構築する問題をどのように解決したかを示しました。その結果、通常MVPと呼ばれるものになります。結果を取得し、その結果が原則として既存のテクノロジーで達成可能であることを証明するための最小限の作業アルゴリズム。
近い将来に実装できるアイデアから、最終製品に到達するまでにはまだ長い道のりがあります。
- あなたが聞くことができるようにビデオプレーヤーをねじ込み、見つかったフラグメントを見る
- テキスト編集の可能性を考えてください。100%認識された単語のテキストにアンカーを残すことができますが、認識品質が「低下」しているフラグメントのみを編集してください。
- elasticsearch, -
- speech-to-text, Google, Yandex, Azure. –
- , «»
- BERT (Bi-directional Encoder Representation from Transformer), . – « xx yy».
- , - - . Youtube , 15-20 , ,
- – , , ,
ご不明な点やご意見がございましたら、お気軽にお問い合わせください。また、プロセス全体を改善または簡素化するためのご提案をお待ちしております。これはHabrの最初の技術記事ですが、それが有用で興味深いものになったことを心から願っています。
あなたの創造的な検索のすべての人に頑張ってください、そしてフォースがあなたと一緒にいるかもしれません!