
グラフデータベースは、データベースの専門家にとって重要なテクノロジーです。私はこの分野の革新と新技術についていくように努めており、リレーショナルデータベースとNoSQLデータベースを使用した後、グラフデータベースの役割がますます重要になっていると思います。複雑な階層データを処理する場合、従来のデータベースだけでなくNoSQLも効果がありません。多くの場合、リンクのレベル数とベースのサイズが増えると、パフォーマンスが低下します。また、関係がより複雑になると、JOINの数も増加します。
もちろん、階層を操作するためのリレーショナルモデルには解決策があります(たとえば、再帰CTEを使用する)が、これらは依然として回避策です。同時に、SQL Serverグラフデータベースの機能により、階層のいくつかのレベルを簡単に処理できます。データモデルとクエリの両方が単純化されているため、より効率的です。コードの量が大幅に削減されます。
グラフデータベースは、複雑なシステムを表現するための表現力豊かな言語です。このテクノロジーは、ソーシャルメディア、不正防止システム、ITネットワーク分析、ソーシャル推奨、製品およびコンテンツの推奨などの分野で、IT業界ですでに非常に広く使用されています。
SQL Serverのグラフデータベース機能は、データが緊密に結合され、明確に定義された関係を持つシナリオに適しています。
グラフデータモデル
グラフは、頂点(ノード、ノード)とエッジ(関係、エッジ)のセットです。頂点はエンティティを表し、エッジはリンクを表し、その属性には情報を含めることができます。
グラフデータベースは、グラフ理論で定義されているように、エンティティをグラフの形式でモデル化します。データ構造は頂点とエッジです。属性は、頂点とエッジのプロパティです。リンクは、頂点の接続です。
他のデータモデルとは異なり、グラフデータベースでは、エンティティ間の関係が優先されます。したがって、外部キーを使用したり、その他の方法で関係を計算する必要はありません。頂点とエッジの抽象化のみを使用して、複雑なデータモデルを作成できます。
現代の世界では、関係のモデリングにはますます高度な技術が必要です。関係をモデル化するために、SQL Server2017はグラフデータベース機能を提供します。グラフの頂点とエッジは、新しいタイプのテーブルとして表されます:NODEとEDGE。MATCH()と呼ばれる新しいT-SQL関数を使用して、グラフを照会します。この機能はSQLServer 2017に組み込まれているため、変換を必要とせずに既存のデータベースで使用できます。
グラフモデルの利点
今日、企業もユーザーも同様に、高いパフォーマンスと信頼性を期待しながら、ますます多くのデータを処理するアプリケーションを求めています。グラフ形式でのデータの表示は、複雑な関係を処理するための便利なツールを提供します。このアプローチは多くの問題を解決し、特定のコンテキスト内で結果を得るのに役立ちます。
将来的には、多くのアプリケーションがグラフデータベースの使用から恩恵を受けるようです。
データモデリング:リレーショナルモデルからグラフモデルへ
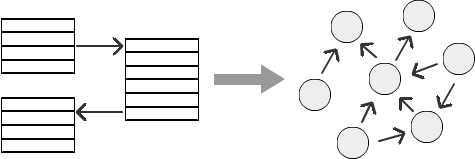
例
従業員の階層を持つ組織構造の例を見てみましょう。従業員はマネージャーに報告し、マネージャーは上級マネージャーに報告します。この階層には、特定の会社に応じて、任意の数のレベルを含めることができます。しかし、レベルの数が増えるにつれて、リレーショナルデータベースでの関係の計算はますます困難になります。従業員の階層、マーケティングまたはソーシャルメディア接続の階層を表すことはかなり困難です。 SQLGraphが階層のさまざまなレベルを処理する問題をどのように解決できるかを見てみましょう。
この例では、簡単なデータモデルを作成しましょう。EMPNO識別子とMGR列を持つEMP従業員テーブルを作成しましょう、従業員のマネージャー(マネージャー)の識別子を示します。階層に関するすべての情報はこのテーブルに格納されており、EMPNO列とMGR列を使用して照会できます。
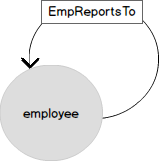
次の図は、より馴染みのある形式で4つのレベルのネストを使用した同じ組織チャートモデルを示しています。従業員は、EMPテーブルのグラフの頂点です。エンティティ「employee」は、リンク「submits」(ReportsTo)によってそれ自体にリンクされています。グラフの用語では、リンクは従業員のノード(NODE)を接続するエッジ(EDGE)です。
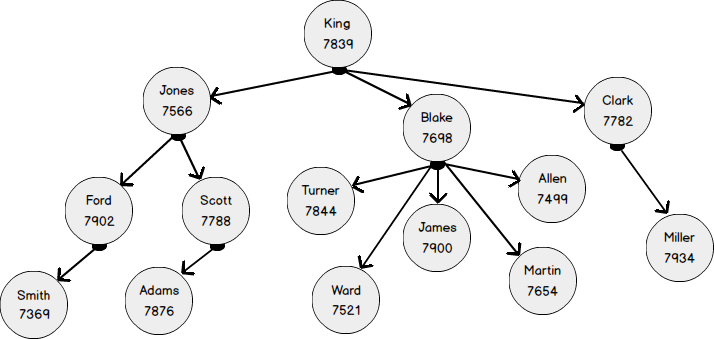
通常のEMPテーブルを作成し、上の図に従ってそこに値を追加しましょう。
CREATE TABLE EMP
(EMPNO INT NOT NULL,
ENAME VARCHAR(20),
JOB VARCHAR(10),
MGR INT,
JOINDATE DATETIME,
SALARY DECIMAL(7, 2),
COMMISIION DECIMAL(7, 2),
DNO INT)
INSERT INTO EMP VALUES
(7369, 'SMITH', 'CLERK', 7902, '02-MAR-1970', 8000, NULL, 2),
(7499, 'ALLEN', 'SALESMAN', 7698, '20-MAR-1971', 1600, 3000, 3),
(7521, 'WARD', 'SALESMAN', 7698, '07-FEB-1983', 1250, 5000, 3),
(7566, 'JONES', 'MANAGER', 7839, '02-JUN-1961', 2975, 50000, 2),
(7654, 'MARTIN', 'SALESMAN', 7698, '28-FEB-1971', 1250, 14000, 3),
(7698, 'BLAKE', 'MANAGER', 7839, '01-JAN-1988', 2850, 12000, 3),
(7782, 'CLARK', 'MANAGER', 7839, '09-APR-1971', 2450, 13000, 1),
(7788, 'SCOTT', 'ANALYST', 7566, '09-DEC-1982', 3000, 1200, 2),
(7839, 'KING', 'PRESIDENT', NULL, '17-JUL-1971', 5000, 1456, 1),
(7844, 'TURNER', 'SALESMAN', 7698, '08-AUG-1971', 1500, 0, 3),
(7876, 'ADAMS', 'CLERK', 7788, '12-MAR-1973', 1100, 0, 2),
(7900, 'JAMES', 'CLERK', 7698, '03-NOV-1971', 950, 0, 3),
(7902, 'FORD', 'ANALYST', 7566, '04-MAR-1961', 3000, 0, 2),
(7934, 'MILLER', 'CLERK', 7782, '21-JAN-1972', 1300, 0, 1)次の図は、従業員を示しています。
- EMPNO7369の従業員は7902に報告します。
- EMPNO7902の従業員は7566に従います
- EMPNO7566の従業員は7839に従います
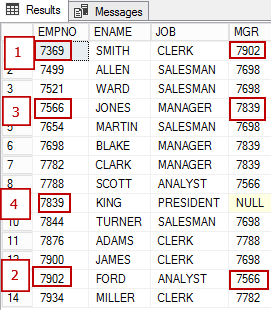
次に、同じデータのグラフ表現を見てみましょう。EMPLOYEEノードにはいくつかの属性があり、「従う」関係(EmplReportsTo)によってそれ自体に関連付けられています。EmplReportsToは、関係の名前です。
エッジテーブル(EDGE)に属性を含めることもできます。
EmpNodeノード表に作成し
たノードを作成するための構文は非常に単純です:CREATE TABLEの文がされて追加「AS NODE」終わり。
CREATE TABLE dbo.EmpNode(
ID Int Identity(1,1),
EMPNO NUMERIC(4) NOT NULL,
ENAME VARCHAR(10),
MGR NUMERIC(4),
DNO INT
) AS NODE;次に、データを通常のテーブルからグラフのテーブルに変換しましょう。次のINSERTは、EMPリレーショナルテーブルからデータを挿入します。
INSERT INTO EmpNode(EMPNO,ENAME,MGR,DNO) select empno,ename,MGR,dno from emp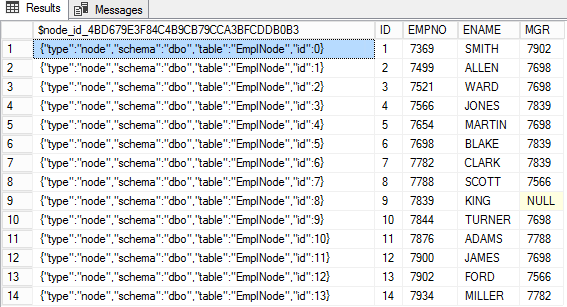
ノード
$node_id_*IDは、JSONの形式でノードテーブルの特別な列に格納されます。このテーブルの残りの列には、ノード属性が含まれています。
エッジの作成(EDGE)
エッジテーブルの作成は、キーワード「AS EDGE」が使用されることを除いて、ノードテーブルの作成と非常に似ています。
CREATE TABLE empReportsTo(Deptno int) AS EDGE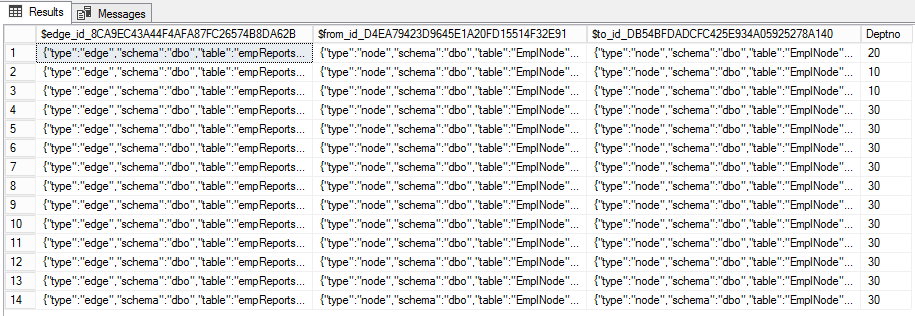
次に、EMPNO列とMGR列を使用して従業員間の関係を定義しましょう。組織チャートは、INSERTの記述方法を示しています。
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 1),
(SELECT $node_id FROM EmpNode WHERE id = 13),20);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 2),
(SELECT $node_id FROM EmpNode WHERE id = 6),10);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 3),
(SELECT $node_id FROM EmpNode WHERE id = 6),10)
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 4),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 5),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 6),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 7),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 8),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 9),
(SELECT $node_id FROM EmpNode WHERE id = 9),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 10),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 11),
(SELECT $node_id FROM EmpNode WHERE id = 8),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 12),
(SELECT $node_id FROM EmpNode WHERE id = 6),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 13),
(SELECT $node_id FROM EmpNode WHERE id = 4),30);
INSERT INTO empReportsTo VALUES ((SELECT $node_id FROM EmpNode WHERE ID = 14),
(SELECT $node_id FROM EmpNode WHERE id = 7),30);デフォルトのエッジテーブルには3つの列があります。1つ目
$edge_idは、エッジのJSON識別子です。他の2つ($from_idおよび$to_id)は、ノード間の通信を表します。さらに、リブは追加のプロパティを持つことができます。私たちの場合、これはDeptnoです。
システムビュー
システムビューに
sys.tables2つの新しい列があります。
- is_edge
- is_node
SELECT t.is_edge,t.is_node,*
FROM sys.tables t
WHERE name like 'emp%'
SSMS
グラフ関連のオブジェクトは、GraphTablesフォルダーにあります。ノードテーブルアイコンはドットでマークされ、エッジテーブルアイコンは2つの接続された円でマークされます(これはガラスのように見えます)。

MATCH式
MATCH 式は、CQL(Cypher Query Language)から取得されます。これは、グラフのプロパティをクエリする効率的な方法です。CQLはMATCH式で始まります。
構文
MATCH (<graph_search_pattern>)
<graph_search_pattern>::=
{<node_alias> {
{ <-( <edge_alias> )- }
| { -( <edge_alias> )-> }
<node_alias>
}
}
[ { AND } { ( <graph_search_pattern> ) } ]
[ ,...n ]
<node_alias> ::=
node_table_name | node_alias
<edge_alias> ::=
edge_table_name | edge_alias例
いくつかの例を見てみましょう。
以下のクエリは、スミスと彼のマネージャーが報告する従業員を表示します。
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR
FROM
empnode e, empnode e1, empReportsTo m
WHERE
MATCH(e-(m)->e1)
and e.ENAME='SMITH'
次のクエリは、スミスの第2レベルの従業員とマネージャーを見つけることです。WHERE句を削除すると、結果にはすべての従業員が表示されます。
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2
WHERE
MATCH(e-(m)->e1-(m1)->e2)
and e.ENAME='SMITH'
そして最後に、第3レベルの従業員とマネージャーへのリクエスト。
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e-(m)->e1-(m1)->e2-(m2)->e3)
and e.ENAME='SMITH'
それでは、方向を変えてスミスのボスを獲得しましょう。
SELECT
E.EMPNO,E.ENAME,E.MGR,E1.EMPNO,E1.ENAME,E1.MGR,E2.EMPNO,e2.ENAME,E2.MGR,E3.EMPNO,e3.ENAME,E3.MGR
FROM
empnode e, empnode e1, empReportsTo m ,empReportsTo m1, empnode e2, empReportsTo M2, empnode e3
WHERE
MATCH(e<-(m)-e1<-(m1)-e2<-(m2)-e3)
結論
SQL Server 2017は、さまざまなITビジネスの課題に対する完全なエンタープライズソリューションとしての地位を確立しています。SQLGraphの最初のバージョンは非常に有望です。いくつかの制限はありますが、グラフの機能を調べるのに十分な機能がすでにあります。
SQLグラフ機能はSQLエンジンに完全に統合されています。ただし、前述のように、SQL Server2017には次の制限があります
。多態性のサポートはありません。
- .
- $from_id $to_id UPDATE.
- (transitive closure), CTE.
- In-Memory OLTP.
- (System-Versioned Temporal Table), .
- NODE EDGE.
- (cross-database queries).
- - (wizard) .
- GUI, Power BI.

: