強化学習は悪いです、あるいはむしろ、高次元ではまったく機能しません。また、物理シミュレータが非常に遅いという問題にも直面しています。したがって、最近、これらの制限を回避する方法は、物理エンジンをシミュレートする別のニューラルネットワークをトレーニングすることによって普及しています。それは想像の類似物のようなものであり、そこではさらに基本的な学習が行われます。
この分野でどのような進歩があったかを見て、主要なアーキテクチャを見てみましょう。
物理シミュレータの代わりにニューラルネットワークを使用するというアイデアは新しいものではありません。最新のCPUでMuJoCoやBulletのような単純なシミュレータは、少なくとも100〜200 FPS(より多くの場合は60)を提供でき、ニューラルネットワークシミュレータを並列バッチで実行すると、2000〜10000FPSが簡単に生成されます。同等の品質。確かに、10〜100ステップの小さな範囲では、強化学習にはこれで十分なことがよくあります。
しかし、もっと重要なことは、物理エンジンを模倣するようにニューラルネットワークをトレーニングするプロセスには、通常、次元の削減が含まれます。このようなニューラルネットワークをトレーニングする最も簡単な方法は、自動エンコーダーを使用することです。自動エンコーダーを使用すると、自動的に実行されます。
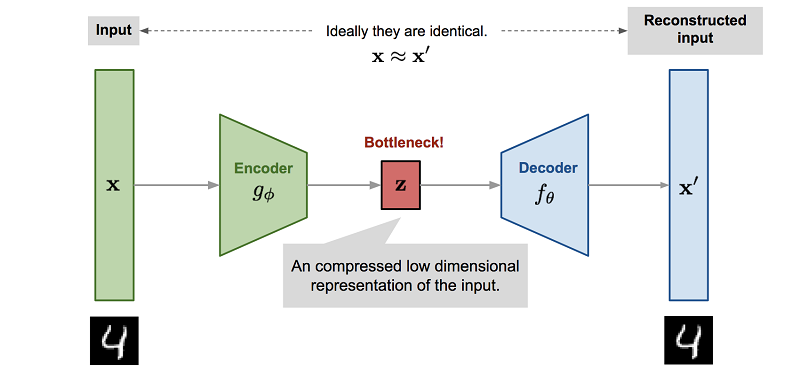
, , . , . - , , , , Z.
Z Reinforcement Learning. , , ( , , ). , .
, — , , . . , Z , model-based , , .
, Reinforcement Learning. "" : , , , .
World Models
( ), 2018 World Models.
: - "" , Z. ( ).
VAE:
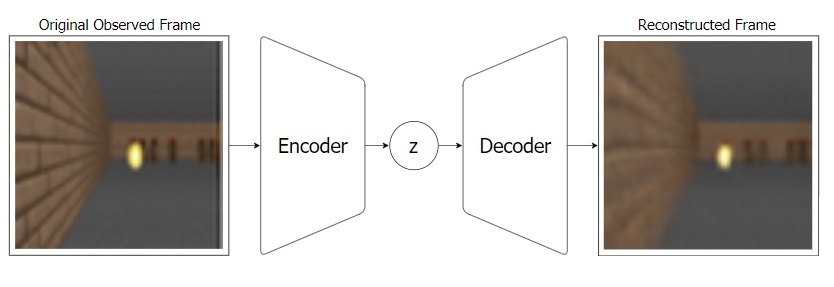
, VAE ( MDN-RNN), . VAE , . , RNN Z . .
:

, : VAE(V) Z MDN-RNN(M) . Z, . MDN-RNN , Z , .
, "" ( - MDN-RNN), . ( ), .
, "" (. ) MDN-RNN (Controller — "", ). , , environment. , C , . VAE(V).
Controller ©, ? ! , -"", Controller. , . , CMA-ES. , Z , . . , , , .
, , .
PlaNet
PlaNet. (, , Controller reinforcement learning), PlaNet Model-Based .
, Model-Based RL — . . , . , , RL , .
Model-Based , , , . (CEM PDDM).
- , ! , .
, . , . .
, . . . (.. state, Reinforcement Learning) , , . Model-Based .
PlaNet, World Models , , Z ( S — state).

Z (, S) , , . , - .
S (, Z) . , , . , .
S , . Model-Based ( ""). .
, , .. -"", A. Model-Based — . , state S . R , state S , ( ). , , ! ( ). Model-Based , .. , , , S R. , World Models, .
Model-Based , PlaNet . 50 . , , , , Model-Free .

Model-Based , (-), . , . . , Model-Based, PlaNet . ( ), .
Dreamer
PlaNet Dreamer. .
PlaNet, Dreamer S, , . Dreamer Value , . Reinforcement Learning. . , . Model-Based ( PlaNet) .

, , Dreamer Actor , . Model-Free , actor-critic.
actor-critic Model-Free , actor , critic ( value, advantage), Dreamer actor . Model-Free .
Dreamer' , . Actor , (. ). Value , , value reward .

, Dreamer Model-Based . Model-Free. model-based ( , ) Actor . Dreamer . , PlaNet Model-Based .
, Dreamer 20 , , Model-Free . , Dreamer 20 , ( ) .

Dreamer Reinforcement Learning . MuJoCo, , .
Plan2Explore
. Reinforcement Learning , .
, - , . , - , , . , , ! Plan2Explore .
Reinforcement Learning , , . , .
, . . , -, . -, , - , .
, . , , Plan2Explore , . , .
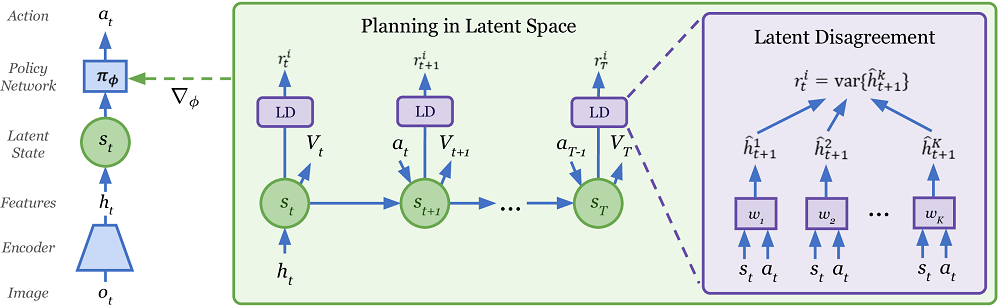
Plan2Explore : , . , - , . . . zero-shot . ( , . World Models ), few-shot .
Plan2Explore , Dreamer Model-Free , , . , .
興味深いことに、Plan2Exploreは、世界を探索しながら、新しい場所の新規性を評価する珍しい方法を使用しています。このために、世界のモデルのみでトレーニングされ、一歩先を予測するモデルのアンサンブルがトレーニングされます。新規性の高い状態では予測が異なると主張されていますが、データセット(サイトへの頻繁なアクセス)として、ランダムな確率的環境でも予測が一致し始めます。ワンステップ予測は、この確率的な環境で最終的にいくつかの平均値に収束するためです。あなたが何も理解していないなら、あなたは一人ではありません。記事の中でそれが説明されていることはあまり明確ではありません。しかし、どういうわけかそれはうまくいくようです。