
こんにちは!
私の名前はニキータです。DomClickでいくつかのプロジェクトの開発を監督しています。今日もRabbitMQの世界で「おもしろい写真」をテーマにしたいと思います。彼の記事の中で、 Alexey Kazakovは、遅延キューや再試行戦略のさまざまな実装などの強力なツールを検討しました。今日は、RabbitMQを使用して定期的なタスクをスケジュールする方法について説明します。
なぜ私たちは自分の自転車を作る必要があり、なぜ私たちはセレリーや他のタスク管理ツールを放棄したのですか?事実、当社では非常に厳しい耐障害性のタスクや要件に適合していませんでした。
DockerとKubernetesに切り替えると、多くの開発者は定期的なタスクを整理するという問題に直面し、クラウンはタンバリンで起動され、プロセスの制御には多くの要望が残されています。そして、日中のピーク負荷に問題があります。
私の仕事は、プロジェクトに定期的なタスクを処理するための信頼性の高いシステムを実装すると同時に、簡単にスケーラブルで障害に耐えることでした。私たちのプロジェクトはPythonで行われているので、Celeryがどのように私たちに適しているかを見るのは論理的でした。これは優れたツールですが、信頼性、スケーラビリティ、シームレスなリリースの問題が頻繁に発生します。 1つのポッド-1つのプロセスグループ。 Celeryをスケーリングする場合、ポッド間の同期がないため、1つのポッドのリソースを増やす必要があります。これは、一時的ではありますが、タスクの処理を停止することを意味します。また、タスクも長期にわたる場合は、管理がいかに難しいかをすでに推測しています。 2番目の明らかな欠点:箱から出して非同期はサポートされていません。タスクには主にI / O操作が含まれ、Celeryはスレッドで実行されるため、これは重要です。
当時(2018年)、適切な既製のツールが見つからず、独自のツールを開発し始めました。タスクの延期実行とデッドレター交換の機能を基本として、定期的なタスクを処理するシステムを作成することにしました。コンセプトは次のようになりまし
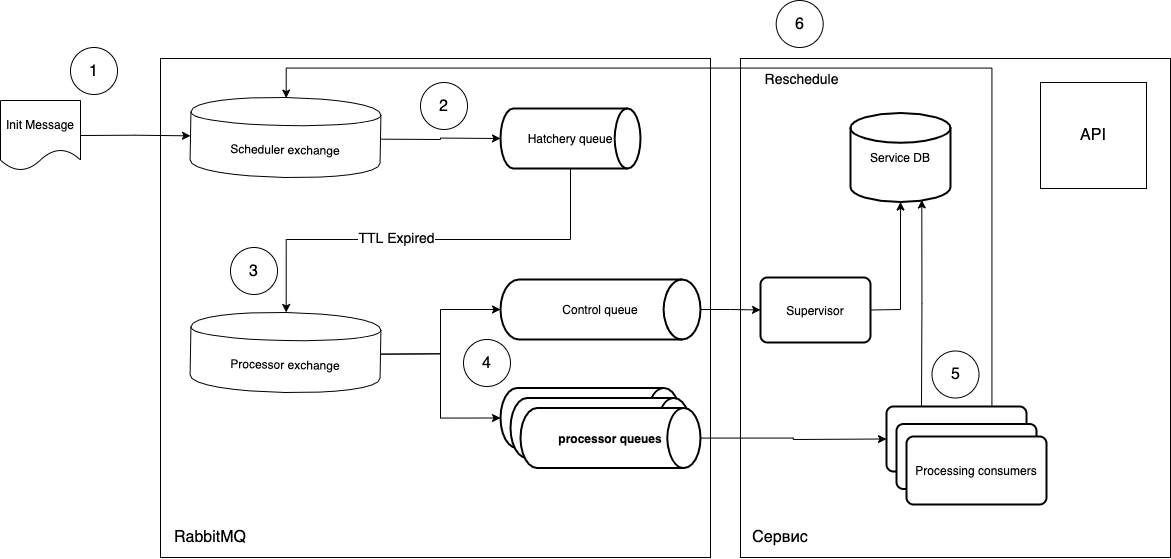
た。何が何であるかを説明しようと思います。
- タスクは、メッセージの形式でスケジューラ交換に送信されます。
routing_keyソフトウェアは、パラメータを持っている必要孵化場キュー、になりmessage_ttl、また、取引手紙交換などのプロセッサ交換との接続。「成熟」キューは、タスクのタイプに関連付けられていません。「タイマー」の役割のみを果たします。つまり、必要な数のキューを作成し、を介して管理できますrouting_key。- キューにはリスナーがないため、キューで「成熟」した後のメッセージはプロセッサ交換に送られます。
- 次に、無料のコンシューマー(処理中のコンシューマー)がメッセージを取得して実行します。実行後、必要に応じてこのサイクルが繰り返されます。
そのようなスキームの利点は何ですか?
- 段階的実行、つまり、前のタスクが完了していない場合、新しいタスクは処理されません。
- 単一のリスナー(消費者)、つまり、ユニバーサルワーカーと特殊ワーカーの両方を作成できます。必要なポッドの数を増やすだけでスケーリングできます。
- 現在のタスクの作業を中断することなく、新しいタスクを展開します。リスナーポッドをソフトに更新し、適切なメッセージをキューに送信するだけで十分です。つまり、新しいメッセージを処理する新しいコードでポッドを起動でき、現在のプロセスは古いポッドで存続します。これにより、シームレスな更新が可能になります。
- スタックに依存せずに、非同期コードと任意のインフラストラクチャを使用できます。
- ネイティブ
ack/レベルでタスクの実行を制御できrejectます。また、タスクのライフサイクルを追跡できる追加のオプションのキュー(制御キュー)を取得することもできます。
回路は実際には非常に単純で、すぐに実用的なプロトタイプを作成しました。そして、コードは美しいです。メッセージのライフサイクルを制御する単純なデコレータでコールバック関数をマークするだけで十分です。
def rmq_scheduler(routing_key_for_delay_queue, routing_key_for_processing_queue):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
log_error(e)
redelivered_count = get_count_of_redelivery_attempts(properties)
if redelivered_count <= 3:
await resend_msg(
channel=channel,
body=body,
properties=properties,
routing_key=routing_key_for_processing_queue)
else:
async with app.natalya_db_engine.acquire() as conn:
async with conn.begin():
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return wrapper
return decorator
現在、このスキームを使用して定期的な順次タスクのみを実行していますが、実行自体に時間をシフトせずに、特定の時間にタスクの実行を開始することが重要な場合にも使用できます。これを行うには、メッセージがスーパーバイザーに到達した後にタスクを再スケジュールするだけで十分です。
確かに、このアプローチには追加のオーバーヘッドコストがあります。エラーが発生した場合、メッセージはキューに戻り、別のワーカーがそれを取得してすぐに実行を開始することを理解する必要があります。したがって、重要度に応じてエラー処理を分離し、特定のエラーが発生した場合にメッセージをどう処理するかを事前に検討する必要があります。
可能なオプション:
- エラーは自動的に修正されます(たとえば、システムエラーです):
noackエラー処理を送信して繰り返します。 - ビジネスロジックエラー:サイクルを中断する必要があります-送信します
ack。 - ポイント1の間違いは頻繁に繰り返されます。私たち
rejectは開発者を毒殺し、合図します。ここにオプションがあります。解析後にメッセージを返すために、保存するメッセージの取引レターキューを作成するか、再試行手法を使用できます(指定message_ttl)。
デコレータの例:
def auto_ack_or_nack(log_message):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
await channel.basic_client_nack(envelope.delivery_tag, requeue=False)
log_error(log_message, exception=e)
return wrapper
return decorator
このスキームは半年間私たちと協力してきました、それは非常に信頼性が高く、実際には注意を必要としません。アプリケーションのクラッシュはスケジューラーを壊さず、タスクの実行をわずかに遅らせるだけです。
マイナスのないプラスはありません。このスキームにも重大な脆弱性があります。RabbitMQに何かが起こってメッセージが消えた場合は、失われたものを手動で確認して、ループを再開する必要があります。しかし、これは、このサービスについて最後に考える必要がある非常にまれな状況です:)
PS定期的なタスクのスケジュールのトピックが興味深いと思われる場合は、次の記事で、キューの作成を自動化する方法と、スーパーバイザーについて詳しく説明します。
リンク: