前書き
この記事は別の記事をまとめたものです。その中で、私はデータ分析に焦点を合わせて、ビッグデータを扱うためのツールに集中するつもりです。
したがって、生データを受け入れて処理し、さらに使用する準備ができたとします。
データの操作に使用されるツールは多数あり、それぞれに長所と短所があります。それらのほとんどはOLAP指向ですが、OLTPに最適化されているものもあります。標準フォーマットを使用し、クエリの実行のみに焦点を当てているものもあれば、パフォーマンスを向上させるために、独自のフォーマットまたはストレージを使用して処理済みデータをソースに転送するものもあります。スターやスノーフレークなどの特定のスキーマを使用してデータを保存するように最適化されているものもあれば、より柔軟なものもあります。要約すると、次のような反対意見があります。
- データウェアハウスとレイク
- Hadoopとオフラインストレージ
- OLAPとOLTP
- クエリエンジンとOLAPメカニズム
また、クエリを実行する機能を備えたデータを処理するためのツールについても見ていきます。
データ処理ツール
上記のツールのほとんどは、Hiveなどのメタデータサーバーに接続してクエリを実行したり、ビューを作成したりできます。これは、追加の(改善された)レポートレベルを作成するためによく使用されます。
Spark SQLは、SQLクエリをSparkプログラムとシームレスに混合する方法を提供するため、DataFrameAPIをSQLと混合できます。Hive統合と標準のJDBCまたはODBC接続を備えているため、Tableau、Looker、または任意のBIツールをSparkを介してデータに接続できます。

Apache FlinkSQLAPIも提供します。FlinkのSQLサポートは、SQL標準を実装するApacheCalciteに基づいています。また、HiveCatalogを介してHiveと統合します。たとえば、ユーザーはHiveCatalogを使用してKafkaまたはElasticSearchテーブルをHive Metastoreに保存し、後でSQLクエリで再利用できます。
KafkaはSQL機能も提供します。一般に、ほとんどのデータ処理ツールはSQLインターフェイスを提供します。
クエリツール
このタイプのツールは、さまざまな形式のさまざまなデータソースへの統合クエリに重点を置いています。いくつかの制限はありますが、SQLを使用して、通常のリレーショナルデータベースであるかのようにクエリをデータレイクにルーティングするという考え方です。これらのツールの中には、NoSQLデータベースなどにクエリを実行できるものもあります。これらのツールは、TableauやLookerなどの外部ツールへのJDBCインターフェイスを提供して、データレイクに安全に接続します。クエリツールは最も遅いオプションですが、最も柔軟性があります。
アパッチピッグ:Hiveと並ぶ最初のツールの1つ。 SQL以外の独自の言語があります。 Pigによって作成されたプログラムの特徴は、その構造が重要な並列化に役立つことです。これにより、非常に大きなデータセットを処理できるようになります。このため、最新のSQLベースのシステムと比較してまだ時代遅れではありません。
プレスト:Facebookのオープンソースプラットフォーム。これは、任意のサイズのデータソースに対してインタラクティブな分析クエリを実行するための分散SQLクエリエンジンです。 Prestoを使用すると、Hive、Cassandra、リレーショナルデータベース、ファイルシステムなど、どこにいてもデータをクエリできます。大規模なデータセットを数秒でクエリできます。 PrestoはHadoopから独立していますが、ほとんどのツール、特にHiveと統合して、SQLクエリを実行します。
アパッチドリル:Hadoop、NoSQL、さらにはクラウドストレージ用のスキーマフリーSQLクエリエンジンを提供します。 Hadoopに依存しませんが、Hiveなどのエコシステムツールと多くの統合があります。 1つのクエリで複数のストアのデータを組み合わせて、各ストアに固有の最適化を実行できます。これはとても良いですアナリストが実際にファイルを読み取っている場合でも、データをテーブルとして扱うことができます。ドリルは標準SQLを完全にサポートします。ビジネスユーザー、アナリスト、およびデータサイエンティストは、Tableau、Qlik、Excelなどの標準的なビジネスインテリジェンスツールを使用して、DrillJDBCおよびODBCドライバーを使用して非リレーショナルデータストアと対話できます。その上、開発者は、カスタムアプリケーションでシンプルなREST APIドリルを使用して、美しい視覚化を作成できます。
OLTPデータベース
HadoopはOLAP用に最適化されていますが、対話型アプリケーションに対してOLTPクエリを実行したい場合もあります。
HBaseは、拡張可能に構築されており、すぐに使用できるACID機能を提供しないため、設計上、ACIDプロパティが非常に制限されていますが、一部のOLTPシナリオで使用できます。
Apache PhoenixはHBaseの上に構築されており、Hadoopエコシステム全体でOTLPクエリを実行する方法を提供します。Apache Phoenixは、Spark、Hive、Pig、Flume、MapReduceなどの他のHadoop製品と完全に統合されています。また、メタデータを保存し、テーブルの作成をサポートし、DDLコマンドを使用してバージョン管理の増分変更をサポートできます。ドリルやその他を使用するよりも非常に高速に動作します
リクエストのメカニズム。
Cassandra、YugaByteDB、ScyllaDB for OTLPなど、Hadoopエコシステムの外部にある大規模なデータベースを使用できます。
最後に、MongoDBやMySQLなど、あらゆるタイプの高速データベースでは、データのサブセットが遅く、通常は最新のものであることが非常に一般的です。上記のクエリエンジンは、1つのクエリで低速ストレージと高速ストレージの間でデータを組み合わせることができます。
分散インデックス
これらのツールは、構造化されていないテキストデータを保存および取得する方法を提供し、データを保存するために特殊な構造を必要とするため、Hadoopエコシステムの外部に存在します。アイデアは、高速検索を行うために反転インデックスを使用することです。このテクノロジーは、テキスト検索に加えて、ログやイベントの保存など、さまざまな目的に使用できます。 2つの主なオプションがあります:
Solr:これは、ApacheLucene上に構築された人気のある非常に高速なオープンソースのエンタープライズ検索プラットフォームです。 Solrは、堅牢でスケーラブルで復元力のあるツールであり、分散インデックス作成、負荷分散されたレプリケーションとクエリ、自動フェイルオーバーとリカバリ、集中プロビジョニングなどを提供します。テキスト検索には最適ですが、ElasticSearchと比較して使用例が限られています。
ElasticSearch:これも非常に人気のある分散インデックスですが、APM、検索、テキストストレージ、分析、ダッシュボード、機械学習など、多くのユースケースにまたがる独自のエコシステムに成長しました。非常に用途が広いため、DevOpsまたはデータパイプラインのいずれかのツールボックスに含めることは間違いなくツールです。また、ビデオや画像を保存および検索することもできます。
ElasticSearch高度な検索機能のために、データレイクの高速ストレージレイヤーとして使用できます。接続がないために検索機能が非常に制限されているHBaseやCassandraなどの大規模なキー値データベースにデータを保存している場合は、ElasticSearchをその前に配置して、クエリを実行し、IDを返します。データベースでクイック検索を実行します。
分析にも使用できます。データをエクスポートしてインデックスを作成し、Kibanaを使用してクエリを実行できますダッシュボードやレポートなどを作成することで、ヒストグラムや複雑な集計を追加したり、データの上で機械学習アルゴリズムを実行したりすることもできます。ElasticSearchエコシステムは巨大であり、調査する価値があります。
OLAPデータベース
ここでは、クエリスキーマのメタデータストアも提供できるデータベースについて説明します。クエリ実行システムと比較して、これらのツールはデータストレージも提供し、特定のストレージスキーム(スタースキーマ)に適用できます。これらのツールはSQL構文を使用します。Sparkまたは他のプラットフォームはそれらと相互作用できます。
Apacheハイブ:HiveをSparkやその他のツールの中央スキーマリポジトリとしてSQLを使用できるようにすることについてはすでに説明しましたが、Hiveはデータも保存できるため、リポジトリとして使用できます。彼はHDFSまたはHBaseにアクセスできます。 Hiveから要求されると、Apache Tez、Apache Spark、またはMapReduceを使用し、TezまたはSparkよりもはるかに高速です。また、HPL-SQLと呼ばれる手続き型言語もあります。 Hiveは、SparkSQLで非常に人気のあるメタデータストアです。
Apache Impala:これは、Hadoopのネイティブ分析データベースであり、データを保存して効率的にクエリするために使用できます。彼女はHiveに接続して、Hcatalogを使用してメタデータを取得できます。 Impalaは、Hadoop(Apache Hiveなどのパッケージプラットフォームでは提供されない)のビジネスインテリジェンスおよび分析クエリに低遅延と高同時実行性を提供します。 Impalaは、マルチユーザー環境でも線形にスケーリングします。これは、Hiveよりも優れたクエリの代替手段です。 Impalaは、認証のために独自のHadoopおよびKerberosセキュリティと統合されているため、データアクセスを安全に管理できます。データストレージにHBaseとHDFSを使用します。

Apache Tajo:これはHadoopのもう1つのデータウェアハウスです。 Tajoは、HDFSやその他のデータソースに保存されている大規模なデータセットに対して、低遅延とスケーラビリティ、オンライン集約、およびETLでアドホッククエリを実行するように設計されています。共通のスキーマにアクセスするためのHiveメタストアとの統合をサポートします。また、多くのクエリ最適化があり、スケーラブルで障害耐性があり、JDBCインターフェイスを提供します。
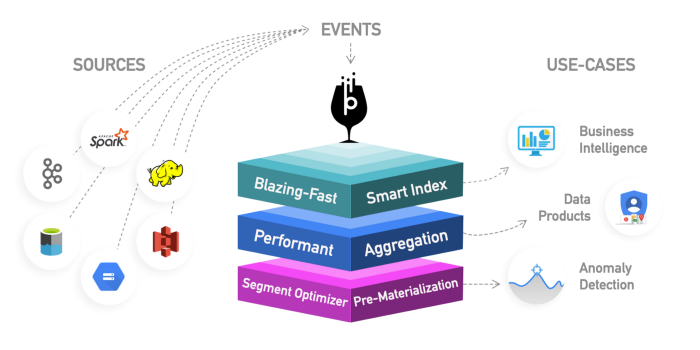
Apache Kylin:これは新しい分散分析データウェアハウスです。Kylinは非常に高速であるため、ダッシュボードやインタラクティブレポートなど、パフォーマンスが重要なユースケースでHiveなどの他のデータベースを補完するために使用できます。これはおそらく最高のOLAPデータウェアハウスですが、使用するのは困難です。もう1つの問題は、ストレッチが大きいため、より多くのストレージスペースが必要になることです。クエリエンジンまたはHiveの速度が十分でない場合は、Kylinで「キューブ」を作成できます。これは、事前に計算されたOLAP最適化多次元テーブルです。
ダッシュボードまたはインタラクティブレポートからクエリできる値。Sparkから直接、Kafkaからほぼリアルタイムでキューブを作成できます。
OLAPツール
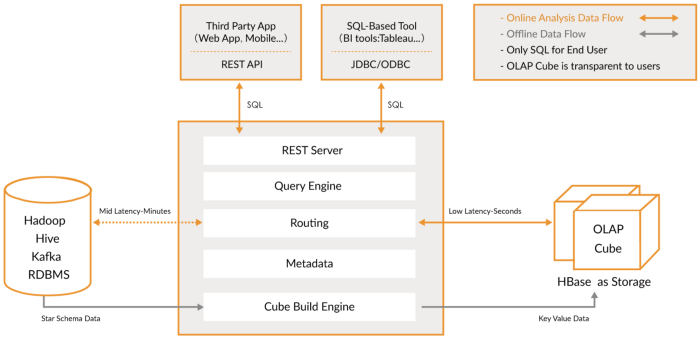
このカテゴリには、より多くの機能を提供する以前のOLAPデータベースの進化を表す新しいエンジンが含まれ、包括的な分析プラットフォームが作成されます。実際、これらは、OLAPデータベースにインデックスを追加する前の2つのカテゴリのハイブリッドです。それらはHadoopプラットフォームの外部にありますが、緊密に統合されています。この場合、通常は処理ステップをスキップして、これらのツールを直接使用します。
リアルタイムデータと履歴データを均一にクエリする問題を解決しようとしているため、リアルタイムデータが利用可能になり次第、低レイテンシの履歴データとともにすぐにクエリを実行できるため、インタラクティブなアプリケーションやダッシュボードを構築できます。これらのツールを使用すると、多くの場合、ELTスタイルの変換をほとんどまたはまったく行わずに生データをクエリできますが、従来のOLAPデータベースよりもパフォーマンスが高くなります。
それらに共通しているのは、データの統合ビュー、ライブおよびバッチデータの取り込み、分散インデックス、ネイティブデータ形式、SQLサポート、JDBCインターフェイス、ホットおよびコールドデータのサポート、複数の統合、およびメタデータストレージを提供することです。
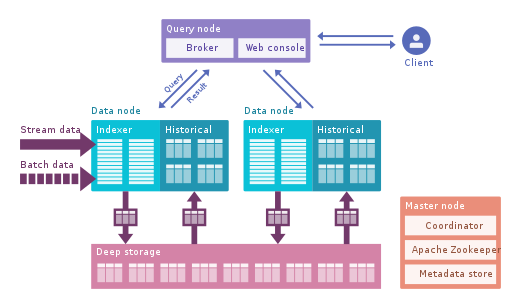
Apache Druid:これは最も有名なリアルタイムOLAPエンジンです。時系列データに焦点を当てていますが、どのデータにも使用できます。データを大量に圧縮できる独自の列形式を使用し、反転インデックス、テキストエンコーディング、自動折りたたみデータなど、多くの最適化機能が組み込まれています。データは、待ち時間が非常に短いTranquilityまたはKafkaを使用してリアルタイムで読み込まれ、書き込みに最適化された文字列形式でメモリに保存されますが、到着するとすぐに、以前にダウンロードしたデータと同様にクエリに使用できるようになります。バックグラウンドプロセスは、HDFSなどのディープストレージシステムに非同期でデータを移動する役割を果たします。データがディープストレージに移動されると、データは小さなチャンクに分割されます。セグメントと呼ばれる時間分離されたもので、低遅延クエリ用に最適化されています。このセグメントには、フィルタリングと集計に使用できるいくつかのディメンションのタイムスタンプと、事前に計算された状態であるメトリックがあります。バースト受信では、データは直接セグメントに保存されます。 Apache Druidは、プッシュとプルの飲み込み、Hive、Spark、さらにはNiFiとの統合をサポートしています。 Hiveメタデータストアを使用でき、Hive SQLクエリをサポートします。HiveSQLクエリは、Druidが使用するJSONクエリに変換されます。 Hive統合はJDBCをサポートしているため、任意のBIツールをプラグインできます。また、独自のメタデータリポジトリがあり、通常はMySQLがこれに使用されます。膨大な量のデータを受け入れ、非常に適切に拡張できます。主な問題は、多くのコンポーネントがあり、管理と展開が難しいことです。
Apache Pinot:これはLinkedInの新しいオープンソースDruidの代替品です。 Druidと比較すると、部分的な事前計算を行うStartreeインデックスのおかげで待ち時間が短くなるため、ユーザー中心のアプリケーションに使用できます(LinkedInフィードの取得に使用されました)。反転インデックスの代わりにソートされたインデックスを使用するため、より高速です。拡張可能なプラグインアーキテクチャがあり、多くの統合もありますが、Hiveをサポートしていません。また、バッチ処理とリアルタイム処理を統合し、高速読み込み、スマートインデックスを提供し、データをセグメントに格納します。 Druidに比べて展開は簡単で高速ですが、現時点では少し未成熟に見えます。
ClickHouse:C ++で記述されたこのエンジンは、OLAPクエリ、特に集計に対して驚異的なパフォーマンスを提供します。リレーショナルデータベースのようなものなので、データを簡単にモデル化できます。セットアップは非常に簡単で、多くの統合があります。3つのエンジンを詳細に比較するこの記事を
読んでください。
決定を下す前に、データを調べることから始めましょう。これらの新しいメカニズムは非常に強力ですが、使用するのは困難です。何時間も待つことができる場合は、バッチ処理とHiveやTajoなどのデータベースを使用してください。次に、Kylinを使用してOLAPクエリを高速化し、よりインタラクティブにします。それだけでは不十分で、必要なレイテンシとリアルタイムデータがさらに少ない場合は、OLAPエンジンを検討してください。Druidは、リアルタイム分析に適しています。Kaileenは、OLAPのケースに重点を置いています。Druidは、ライブストリーミングとしてKafkaとうまく統合されています。Kylinは、ライブ受信が計画されていますが、HiveまたはKafkaからバッチでデータを受信しています。
最後に、Greenplum もう1つのOLAPエンジンであり、人工知能に重点を置いています。
データの視覚化
Qlik、Looker、Tableauなど、視覚化のための商用ツールがいくつかあります。
オープンソースを好む場合は、SuperSetに目を向けてください。これは、前述のすべてのツールをサポートする優れたツールであり、優れたエディターを備え、非常に高速です。SQLAlchemyを使用して多くのデータベースをサポートします。
他の興味深いツールはMetabaseまたはFalconです。
結論
Prestoのような柔軟なクエリエンジンからKylinのような高性能ストレージまで、データの操作に使用できるさまざまなツールがあります。万能の解決策はありません。利用可能なデータを調べて、小規模から始めることをお勧めします。クエリエンジンは、柔軟性があるため、出発点として適しています。次に、さまざまな使用例で、必要なサービスレベルを達成するためにツールを追加する必要がある場合があります。
DruidやPinotなどの新しいツールに特に注意してください。これらのツールは、非常に低いレイテンシで大量のデータを分析する簡単な方法を提供し、パフォーマンスの点でOLTPとOLAPの間のギャップを埋めます。集計の処理や事前計算などについて考えたくなるかもしれませんが、作業を簡素化したい場合は、これらのツールを検討してください。