Surfでは、独自のインタープリターを作成し、モバイルアプリケーションのクライアントで使用しています。最初は、これは一般的にモバイル開発とはほとんど関係がないように思われますが。実際、インタープリターとコンパイラーは、どこにでもある問題を解決するためのツールです。したがって、それがどのように機能するかを理解し、独自に作成できることは役に立ちます。
今日は、マスクをある形式から別の形式に変換する例を使用して、インタープリターの作成の基本に精通し、正式な文法、抽象的な構文ツリー、変換ルールの使用方法を確認します。これには、ビジネス上の問題を解決するためも含まれます。

マスクについて少し:マスクとは何か、なぜマスクが必要なのか
. , , - — , . -: , , .
, . , . , API - , : 9161234567 — 8, .
, , :
, , . , , , — . ? — .
— , . , .
, :

, , : . .
, . , . , API - , : 9161234567 — 8, .
, , :
- , , .
- : , , , .
- , .
, , . , , , — . ? — .
— , . , .
, :
- . , , .
- « »: -, .
- .
, , : . .
— UX-
マスクを手に取って説明できないのはなぜですか
マスクはクールで快適です。ただし、特定の条件では避けられない問題があります。クライアントに1つのマスク形式があり、サーバーに多くの異なるデータプロバイダーがあり、それぞれに独自の形式がある場合です。同じフォーマットになるという事実を当てにすることはできません。サーバーに尋ねる:「私たちが好きなようにマスクを合わせてください」-また。あなたはそれと一緒に暮らすことができる必要があります。
問題が発生します。バックエンド仕様があり、フロントエンド(モバイルアプリケーション)を作成する必要があります。アプリケーションのすべてのマスクを手動で書き込むことができます。これは、プロバイダーが1つだけで、マスクが少ない場合に適したオプションです。もちろん、プログラマーは、マスクの少なくとも2つの仕様(バックエンドとフロント)を理解するために時間を費やす必要があります。次に、特定のバックエンドマスクを対応するフロントエンドマスクに変換する必要があります。それも時間がかかります、人的要因があります-あなたは間違っている可能性があります。それは簡単な仕事ではありません、翻訳は難しいです:いくつかのマスク言語は主に人間のためではなくコンピュータのために書かれています。
サーバー上のマスクが突然変更された場合、または新しいマスクが表示された場合、アプリケーションは最初に動作を停止する可能性があります。第二に、翻訳の大変な作業をもう一度行う必要があります。新しいアプリケーションをリリースする必要があります。時間、労力、およびお金がかかります。疑問が生じます:プログラマーの作業を最小限に抑える方法は?これはすべて機械で行う必要があるようですが、何らかの理由で人が行っています。
答えはイエスです、私たちは解決策を持っています。マスクはコンピューターの言語で書かれています。これが、人が彼と一緒に仕事をしたり、ある言語から別の言語に翻訳したりすることが難しい理由の1つです。この作業をコンピューターに転送する必要があります。マスクは正式な文法のように見えるため、ある文法を別の文法に変換する最も確実な方法は次のとおりです。
- 元の文法を構築するためのルールを理解し、
- ターゲット文法を構築するためのルールを理解し、
- ソース文法からターゲットへの翻訳ルールを記述し、
- これらすべてをコードで実装します。
これは、コンパイラとトランスレータが書かれているものです。
それでは、正式な文法に基づいたソリューションを詳しく見ていきましょう。
バックグラウンド
私たちのアプリケーションでは、バックエンド駆動の原則に従って形成されるかなりの数の異なる画面があります。画面の完全な説明は、データとともに、サーバーから取得されます。

ほとんどの画面には、さまざまな入力フォームが含まれています。サーバーは、フォームにあるフィールドとそのフォーマット方法を決定します。マスクは、これらの要件を説明するためにも使用されます。
マスクがどのように機能するか見てみましょう。
さまざまな形式のマスクの例
最初の例として、電話番号を入力するのと同じ形式を取りましょう。そのような形のマスクはこのように見えるかもしれません。

一方では、マスク自体が区切り文字、括弧を追加し、誤った文字の入力を禁止します。一方、同じマスクは、フォーマットされた入力から有用な情報を抽出してサーバーに送信します。
定数と呼ばれる部分は赤で強調表示されています。これらは自動的に表示されるシンボルです-ユーザーはそれらを入力しないでください:

次に動的部分があります-それは常に山括弧で囲まれています:

さらに本文では、この式を「動的式」、または略してDWと呼びます。
入力をフォーマットする式は次のとおり

です。動的パーツのコンテンツを担当する部分は赤で強調表示されています。
\\ d-任意の桁。
+-通常のリピーター:少なくとも1回繰り返します。
$ {3}は、繰り返し回数を指定するメタ情報シンボルです。この場合、3文字である必要があります。
次に、式\\ d + $ {3}は、3桁でなければならないことを意味します。
この形式のマスクでは、動的パーツ内にリピーターは1つしか存在できません。

この制限は理由で発生しました。ここで、その理由を説明します。
サイズがハードコードされたDVがあるとしましょう:4要素。そして、リピーターで2つの要素を与えます: `<!^ \\ d + \\ v + $ {4}>`。次の組み合わせは、このようなDVに該当します。
- 1abc
- 12ab
- 123a
そのようなDVは、2番目の文字(数字または文字)の代わりに何を期待するかという明確な答えを私たちに与えないことがわかりました。
マスクを取り、ユーザー入力で追加します。フォーマットされた電話番号を取得し

ます。クライアントでは、マスクのフォーマットが異なる場合があります。たとえば、Redmadrobotの入力マスクライブラリでは、電話番号のマスクは

次のようになります。見栄えがよく、理解しやすいです。
サーバーのマスクとクライアントのマスクの記述は異なることがわかりましたが、同じことを行います。

問題を再定式化しましょう:異なるフォーマットのマスクを組み合わせる方法
これらのマスクを互いに組み合わせる必要があります-または、どういうわけか1つから2番目を取得します。
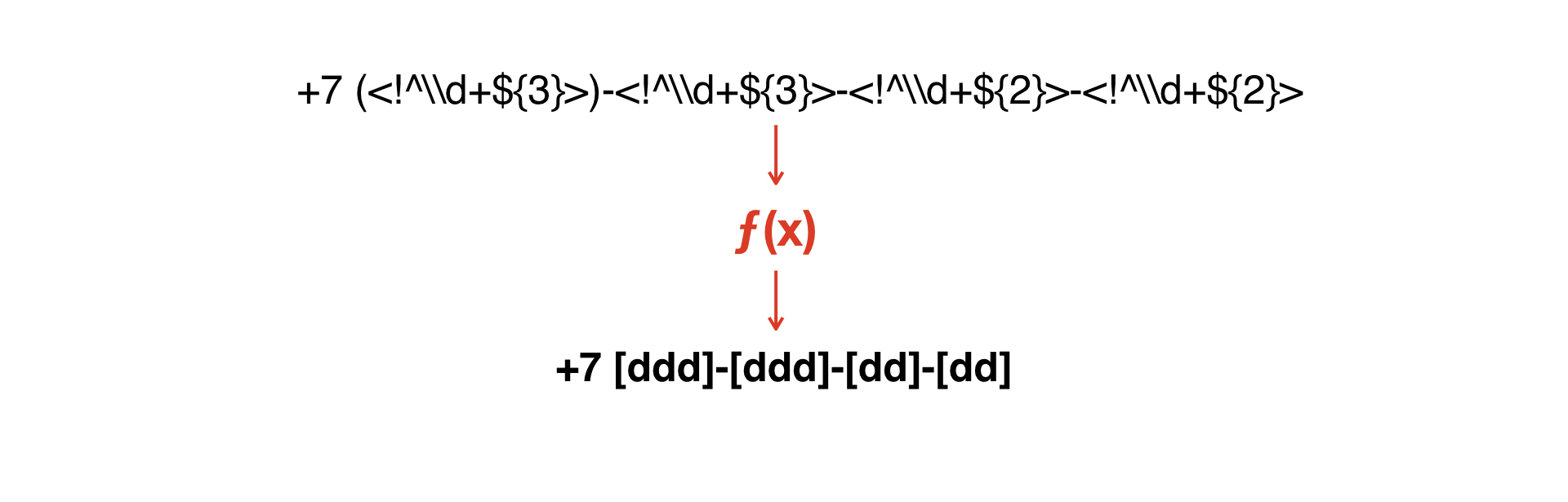
1つのマスクを別のマスクに変換する関数を作成する必要があります。
そしてここで、1つの文法から2番目の文法を取得できる非常に単純なインタープリターを作成するというアイデアが生まれました。
通訳に着いたので、文法について話しましょう。
解析の方法
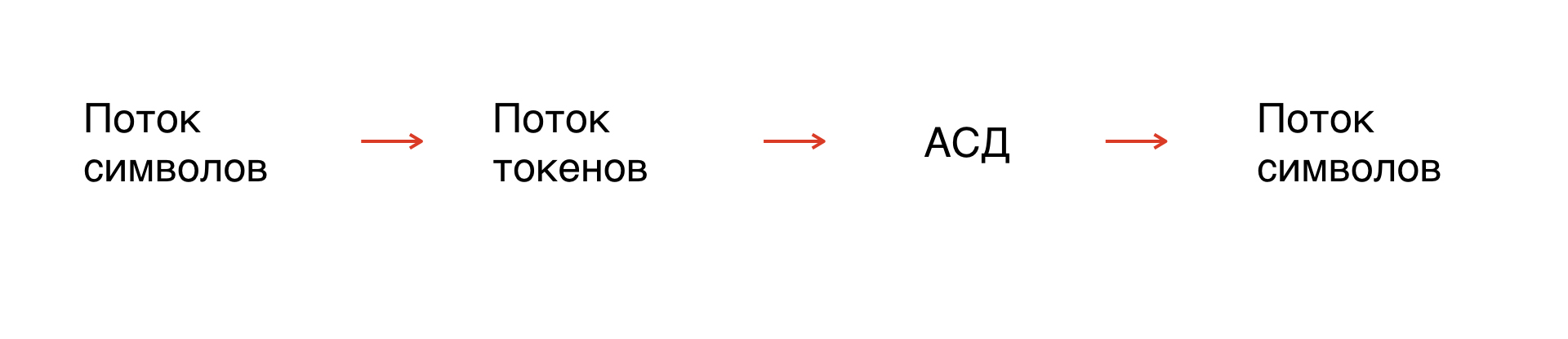
まず、文字のストリーム、つまりマスクがあります。実際、これは私たちが操作する文字列です。ただし、記号は形式化されていないため、文字列を形式化する必要があります。つまり、通訳者が理解できる要素に分割します。
このプロセスはトークン化と呼ばれます。シンボルのストリームがトークンのストリームに変わります。トークンの数は限られており、形式化されているため、分析することができます。
さらに、文法規則に基づいて、トークンフローに沿って抽象的な構文ツリーを構築します。ツリーから、必要な文法のシンボルのストリームを取得します。
表現があります。それを見ると、上で説明した定数があることがわかります。

すべての定数をCSトークンとして表し、その引数は定数自体です

。次のタイプのトークンはDWの始まりです。

さらに、そのようなトークンはすべて特殊文字として解釈されます。私たちの例では、それらの多くはありませんが、実際のマスクでは、はるかに多くなる可能性があります。

次に、リピーターがあります。
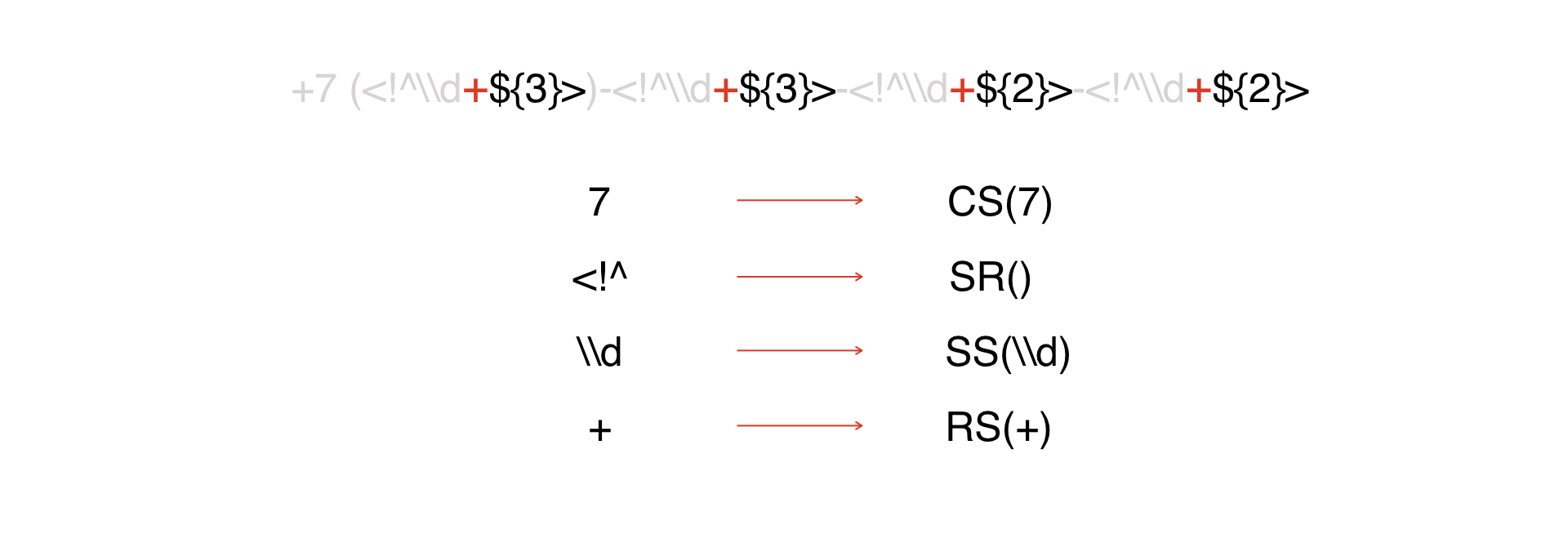
次に、メタデータと見なされるいくつかの文字。簡単にできるので、それらを1つのトークンとしてチートして表現します。

極東の終わり。したがって、すべてをトークンに分解しました。

電話番号のマスクをトークン化する例
原則として、トークン化プロセスがどのように行われ、インタープリターがどのように機能するかを確認するために、電話番号のマスクを取得して、トークンのストリームに変換します。

まず、+記号。定数+に変換します。次に、7と他のすべてのシンボルについて同じことを行います。トークンの配列を取得します。これはまだ構造ではありません。この配列をさらに分析します。
レクサーとASDの構築
ここで注意が必要なのはレクサーです。

左側には、凡例が説明されています。これは、字句規則を説明するために使用される特殊な文字です。右側はルールそのものです。
symbolRuleはシンボルを記述します。このルールが適用される場合、それが真である場合、それは私たちが特別な文字または定数文字のいずれかに遭遇したことを意味します。これは機能と言えます。
次はrepeaterRuleです。このルールは、文字が検出され、その後にリピータートークンが続く状況を記述します。
その後、すべてが似ています。LWの場合は、シンボルまたはリピーターのいずれかです。私たちの場合、このルールはより広いです。そして最後に、メタデータを含むトークンが必要です。
最後のルールはmaskRuleです。これは一連のシンボルとDVです。
それではビルドしましょうトークンの配列からの抽象構文ツリー(AST)。
これがトークンのリストです。ツリーの最初のノードはルートノードであり、そこから構築を開始します。それは意味がありません、それはただルートを必要とします。

最初のトークン+があります。これは、子ノードを追加するだけで、それだけです。

他のすべての定数シンボルについても同じことを行いますが、より複雑になります。 DVトークンに出くわしました。

これは単なる通常のサイトではありません。何らかのコンテンツが必要であることはわかっています。

コンテンツノードは、将来ナビゲートできる単なる技術ノードです。独自の子ノードがあり、次にどのノードがありますか?ストリームの次のトークンは特殊文字です。子ノードになりますか?

実際、この場合はありません。子ノードとしてリピーターがあります。

どうして?将来的には木材を扱う方が便利だからです。このツリーを解析して、そこからある種の文法を構築したいとします。ツリーを解析するときは、ノードのタイプを調べます。 CSノードがある場合は、同じCSノードに解析しますが、文法は異なります。慣例により、ツリーの上部を繰り返し、ある種のロジックを実行します。
ロジックは、ノードのタイプ、またはノードにあるトークンのタイプによって異なります。解析するには、どのトークンが目の前にあるかをすぐに理解する方がはるかに便利です。リピーターのような複合、またはCSのような単純です。これは、子ノードの二重解釈や継続的な検索が発生しないようにするために必要です。
これは、[abcde]などの文字のグループで特に顕著になります。その場合、明らかに、子ノードCS(a)CS(b)などのリストを持つある種の親GROUPノードが存在する必要があります。
メタデータを含むトークンに戻ります。コンテンツには含まれていませんが、サイドにあります。

これは、ツリーの操作を簡単にするために必要です。これにより、このノードはコンテンツとは見なされません。実際には、ツリーに属していないためです。
DVは終了しましたが、これをある種のノードとは見なしていません。これは、破棄できるトークンでした。これをツリーノードに変換しません。
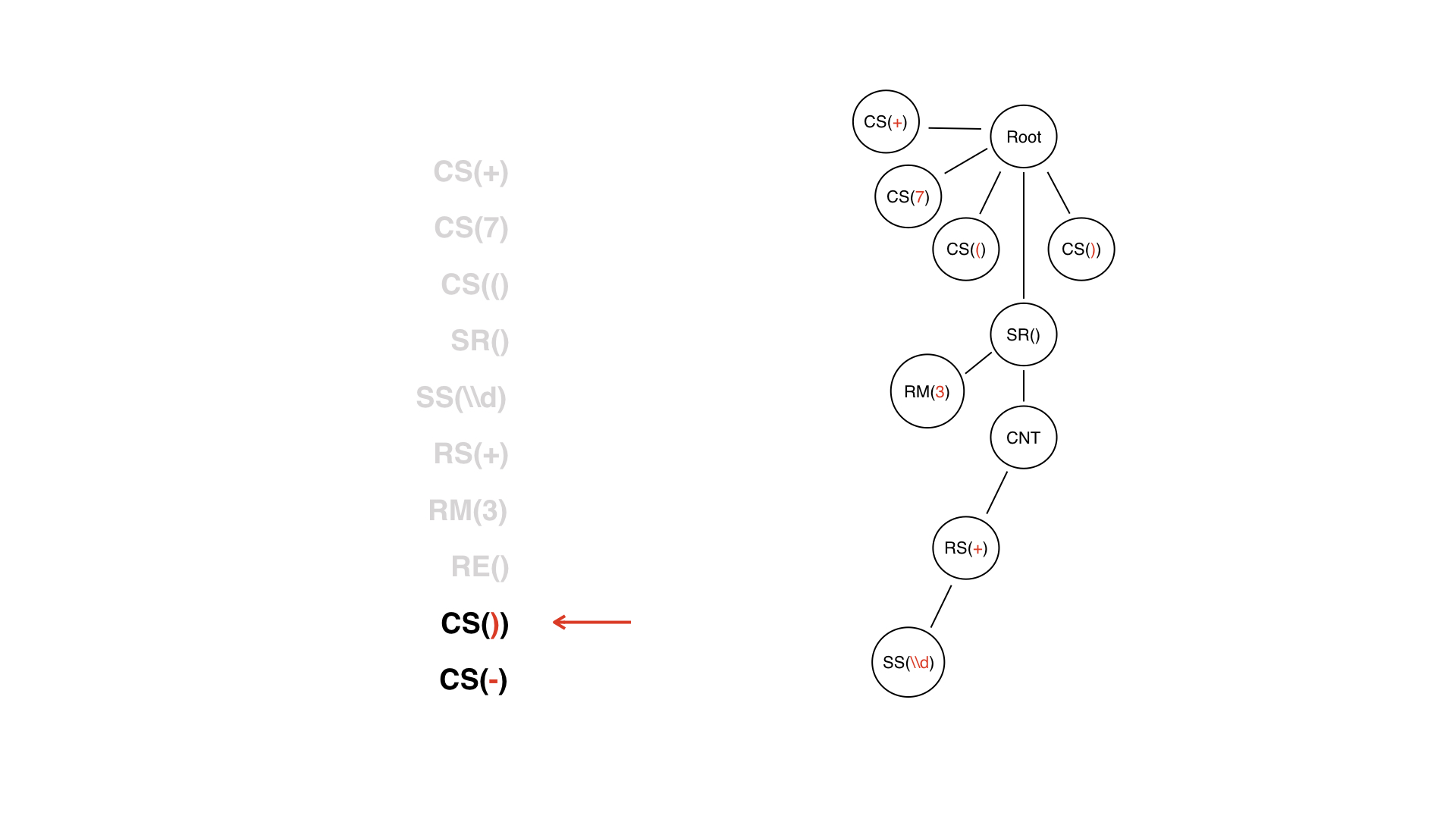
すでにサブツリーがあり、そのルートはSRノードです。つまり、非常に動的な部分です。LW終了トークンは、ツリー構築のプロセスで大いに役立ちます。LWのサブツリーがいつ終了するかを理解できます。しかし、このトークンには論理的な価値がありません。行ごとのツリーを見ると、DWがいつ終了するかは、いわばSRノードによって閉じられているためです。
さらに-通常の定数記号。

私たちは木を手に入れました。次に、このツリーを詳しく調べて、他の文法を構築しましょう。ノードに移動し、ノードの種類を確認して、このノードから別の文法の要素を生成する必要があります。
RedmadrobotによるInputMaskライブラリの構文
Redmadrobotライブラリの構文を見てみましょう。

これが同じ表現です。+7は、自動的に追加される定数です。中括弧の内側には、DV(動的部分)が記述されています。DVの中には特別なキャラクターdがあります。Redmadrobotには、数字を示すこのデフォルト表記があります。
表記は次のようになります

。表記は3つの部分で構成されます。
- 文字は、マスクを作成するために使用する文字です。マスクアルファベットの構成。たとえば、d。
- characterSet-ユーザーが入力した文字がこの表記と一致します。たとえば、0、1、2、3、4などです。
- isOptional-ユーザーがcharacterSet文字の1つを入力する必要があるか、何も入力しないかどうか。
ほら、これでそのようなマスクができました。

- 「b」文字には特別な数字表記があり、オプションではありません。
- 文字「c」の表記が異なります-CharacterSetが異なります。また、オプションではありません。
- また、文字「C」は「c」と同じですが、オプションです。これは、マスクでメタデータを調べて、厳しい制限ではなく弱い制限があることを確認するために必要です。
1〜10文字のルールを作成する必要がある場合、1文字はオプションではありません。そして、9文字はオプションになります。つまり、例の表記では大文字で表記されます。結果として、このルールは次のようになります。[cCCCCCCCCC]
例:電話番号マスクをバックエンド形式からInputMask形式に変換する
これが最後のステップで取得したツリーです。その上を歩く必要があります。最初に到達するのはルートです。

ルートからさらに離れると、定数記号+に自分自身が見つかります-すぐに+を生成します。右側では、マスクはInputMask形式で書き込まれています。

次の文字は理解できます-ちょうど7、その後に開いた括弧が続きます。
次に、動的パーツの一部が生成されますが、まだ埋められていません。

中に入って、コンテンツがあります。これはテクニカルノードです。私たちはどこにも何も書きません。

ここにリピーターがあります。マスクにそのような記号がないため、どこにも何も書き込みません。そのようなルールを書き留めることはできません。

最後に、ある種のコンテンツシンボルについて説明します。
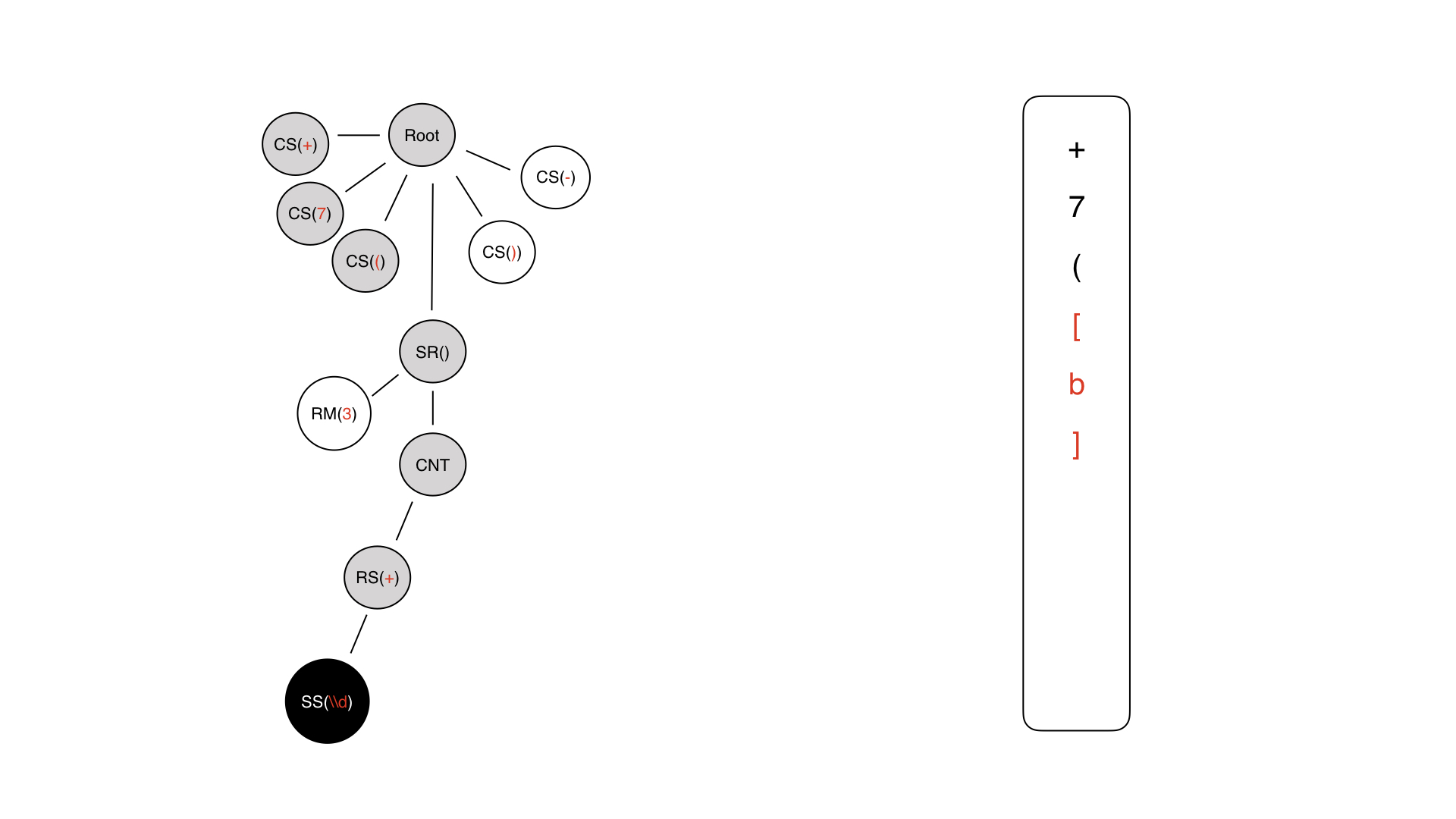
コンテンツシンボルは、定数シンボルまたは特別シンボルのいずれかです。この場合、特別なものが使用されます。これは、それだけが入力に対して何らかの意味的な負荷を運ぶためです。
それで私たちはそれを書きました、私たちは戻ってメタ情報のためだけに行きます。

そこにリピーターがあり、ここには3つあります-厳しい制限があります。したがって、それを3回繰り返すと、このようなダイナミックな作品が得られます。次に、定数シンボルを追加します。

その結果、ロボット形式のマスクのように見えるマスクが得られます。
実際には、1つの文法を取得し、それから別の文法を生成しました。
サーバー側からクライアント側の文法を生成するためのルール
次に、生成ルールについて少し説明します。大事です。
そのような難しいケースがあるかもしれません:動的な部分の中にDWのいくつかの異なる部分があります。中括弧の内側:これはDVと同じです-多くの1つです。通訳がこの状況をどのように処理するか見てみましょう。

最初に文字セットがあり、InputMaskに関して何らかの表記に変換する必要があります。どうして?これは、一致させる必要があるある種の限定された文字のセットだからです。ユーザー入力と文字を組み合わせる必要があるため、ここでは特定の表記法を記述します。
次に、\\ d文字があります。
さらに-オプションのサイズのDV。

1つ目は、ある文字bです。 abcdを含む文字セットがあります。
さらに、別の方法でパッチを適用したり、誤ってパッチを適用したりするため、すでに別のシンボルが存在することは明らかです。そして、この表現がこのようなものに変わります。
最後の部分には、少なくとも1つのシンボルが含まれている必要があります。この要件をdと指定しましょう。ただし、ユーザーは2つの追加文字を入力することもでき、それらはDDとして指定されます。
すべてを一緒に入れて。

生成される文字セットの例を次に示します。bは文字セットabcdに対応し、数字の場合は対応するプリセット文字セットであることがわかります。dとDの場合、対応する文字セットには12vfが含まれます。
結果
ある文法を別の文法に自動的に変換する方法を学びました。サーバーの仕様に従ってマスクがアプリケーションで機能するようになりました。
私たちが無料で入手したもう1つの機能は、私たちに届いたマスクの静的分析を実行する機能です。つまり、このマスクに必要なキーボードのタイプと、このマスクに含めることができる最大文字数を理解できます。また、フォーム要素ごとに常に同じキーボードを表示するわけではないため、さらにクールです。必要なフォーム要素の下に必要なキーボードを表示します。また、一部のフィールドが電話入力フィールドであることを条件付きで正確に定義することもできます。
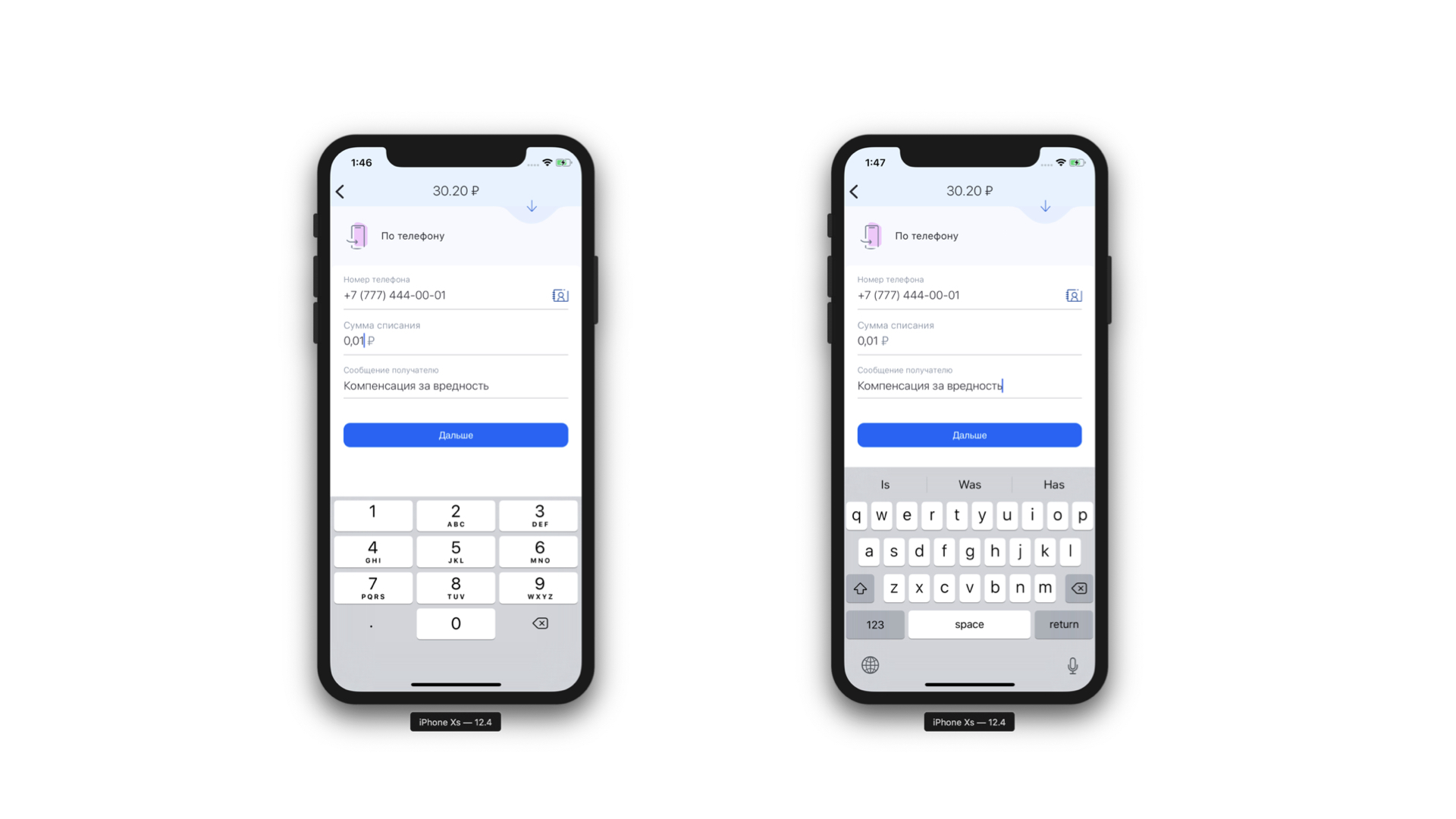
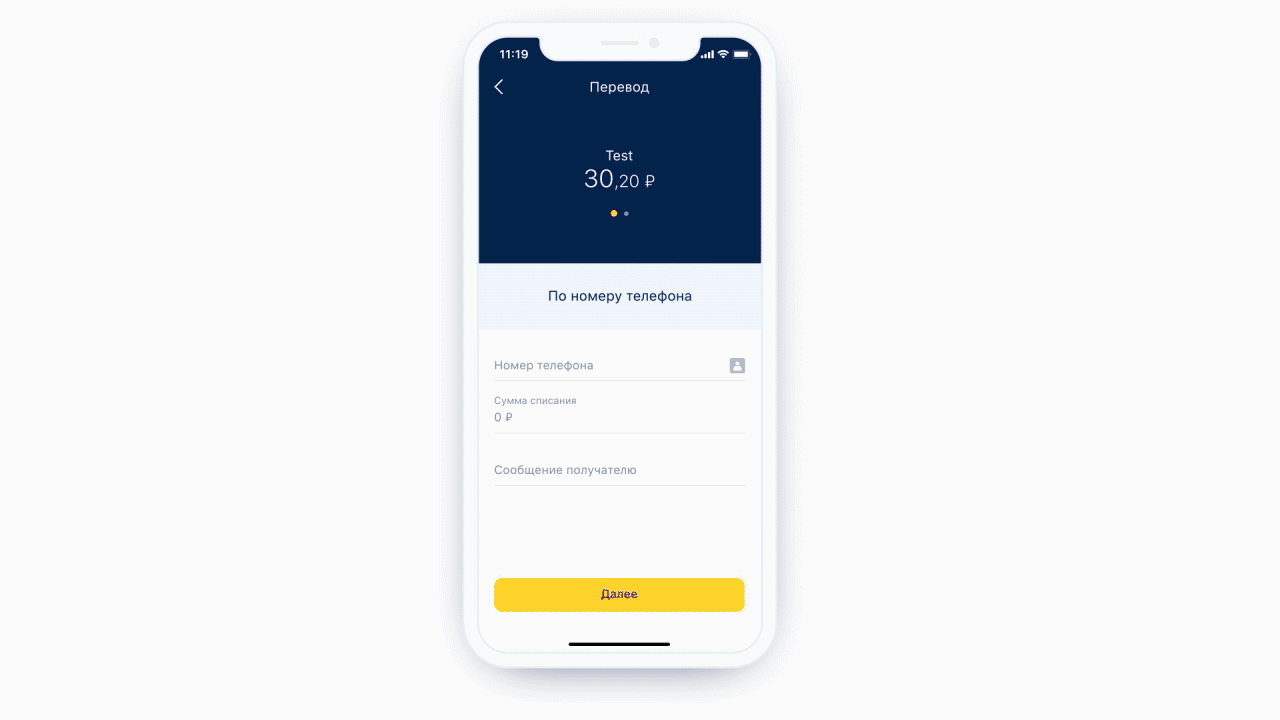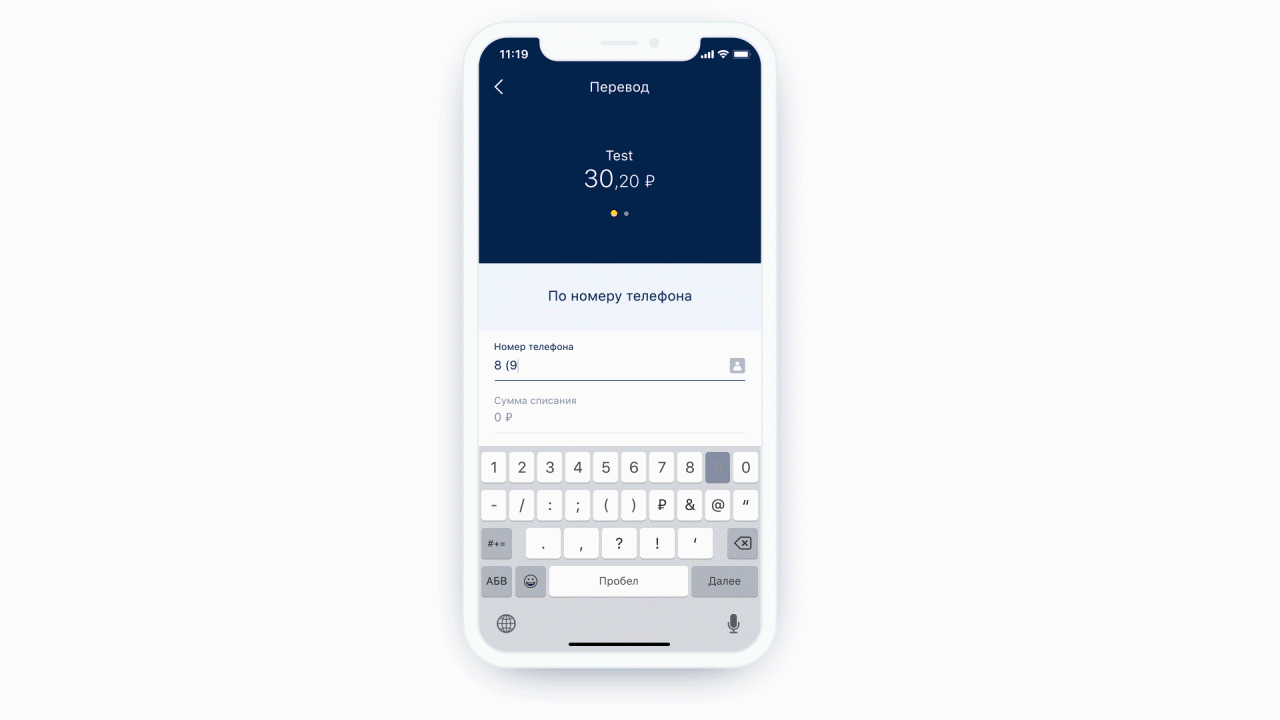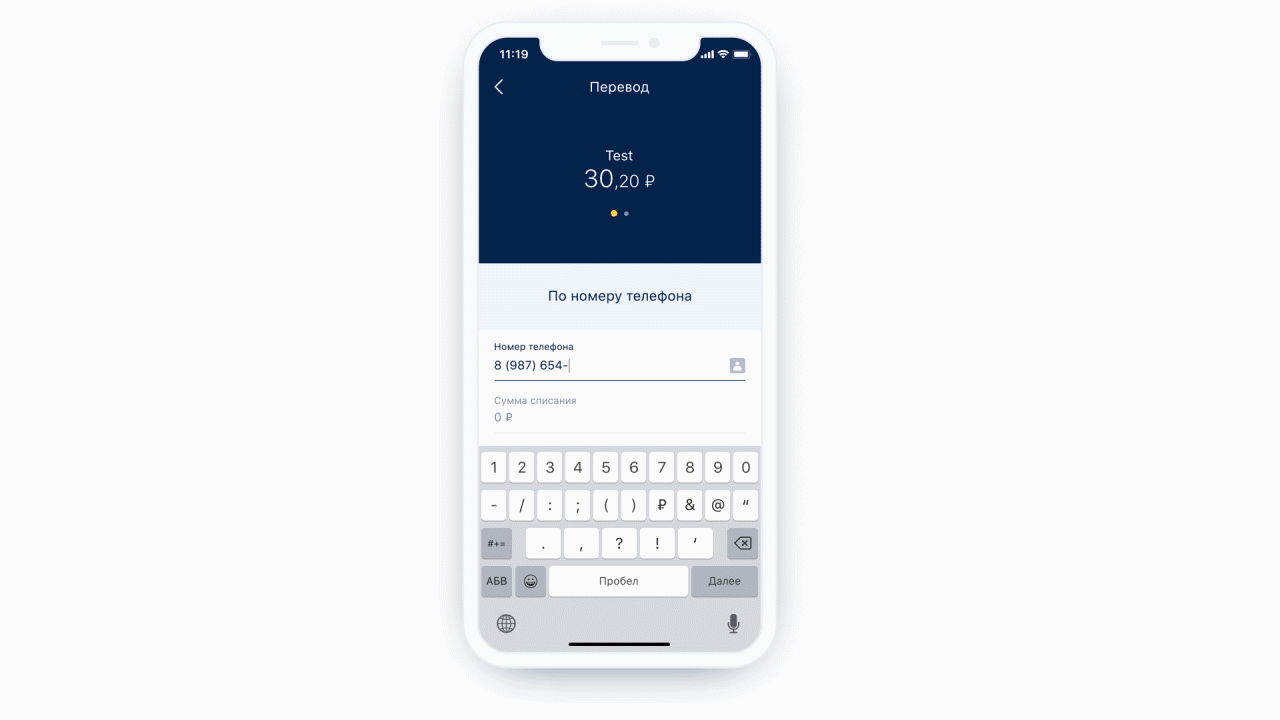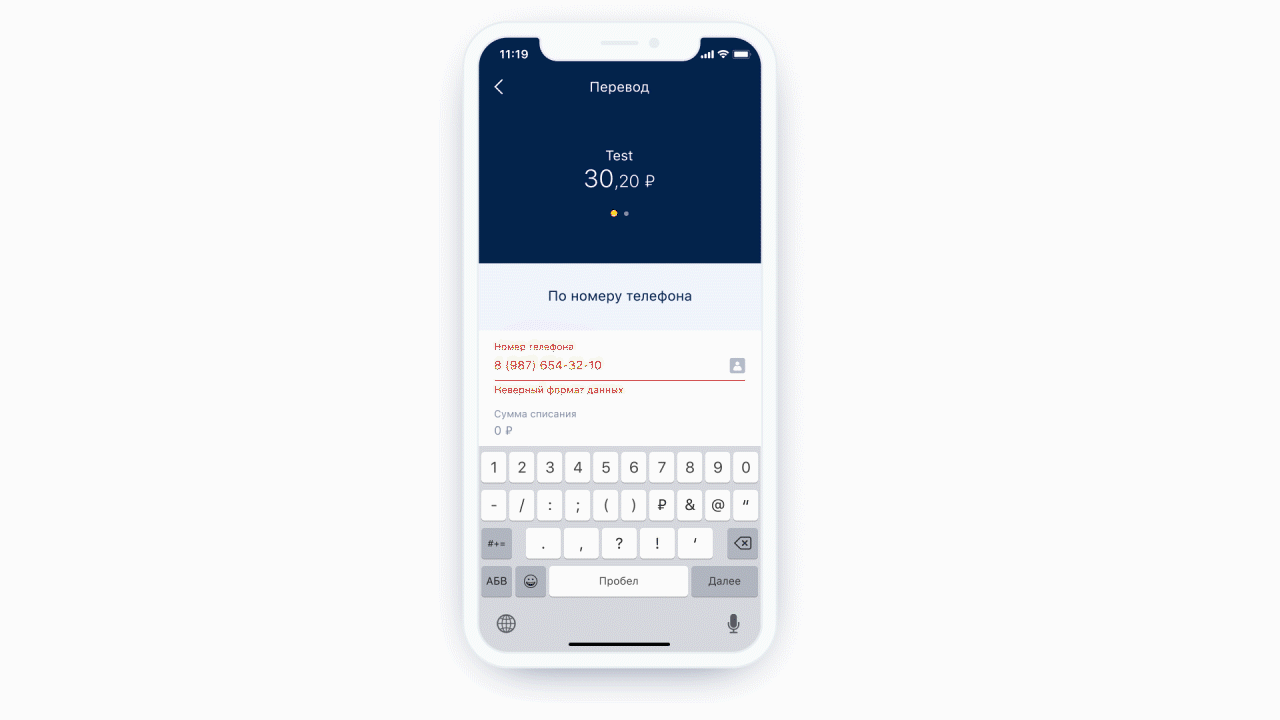
左:電話入力フィールドの上部に、ユーザーを連絡先リストに送信するアイコン(実際にはボタン)があります。右:通常のテキストメッセージ用のキーボードの例。
マスクを翻訳するための作業ライブラリ
上記のアプローチをどのように実装したかをご覧ください。ライブラリはGithubにあります。
異なるマスクの翻訳例
これは私たちが最初に見た最初のマスクです。これは、このRedMadRobot表現に解釈されます。

そしてこれは2番目のマスクです-何かのための単なる入力マスクです。それはそのような表現に変換されます。
