 Yandexカッププログラミングチャンピオンシップのトライアルラウンドは本日から始まります。これは、Yandex.Contestシステムを使用して、予選ラウンドで発生する問題と同様の問題を解決できることを意味します。これまでのところ、結果は何にも影響しません。
Yandexカッププログラミングチャンピオンシップのトライアルラウンドは本日から始まります。これは、Yandex.Contestシステムを使用して、予選ラウンドで発生する問題と同様の問題を解決できることを意味します。これまでのところ、結果は何にも影響しません。
投稿では、スポイラーに意図的に隠されている分析トラックと分析のタスクの条件を見つけることができます。解決策を確認するか、最初に自分でタスクを実行してみてください。チェックは自動的に行われます。コンテストはすぐに結果を報告し、別の解決策を提案する機会があります。
A.国の嘘つきを数える
コンテストで解決する10,000人が州に住んでいます。彼らは真実の愛好家と嘘つきに分けられます。真実を愛する人は80%の確率で真実を語り、嘘つきは40%の確率で真実を語ります。州は、100人の住民の調査に基づいて、真実を愛する人と嘘つきを数えることにしました。ランダムに選ばれた人に「うそつきですか?」と聞かれるたびに。-そして答えを書き留めます。ただし、1人で数回調査に参加できます。居住者がすでに調査に参加している場合、彼は最初と同じように答えます。真実を愛する人の70%と嘘つきの30%がいることを私たちは知っています。州が嘘つきの数を過小評価する可能性はどのくらいですか。つまり、調査によると嘘つきの数は30%未満であることが示されます。ピリオドを区切り文字としてパーセンテージで回答し、結果を100分の1に四捨五入します(入力例:00.00)。
決定
1. «» « ?».
«, » «» «» .
«, » :
: «» * = 0,2 * 0,7.
: «» * ( – ) + «» * ( ) = «» * = 0,2 * 0,7.
«, » 0,14 , . .
, «, » : 0,2 * 0,7 + 0,4 * 0,3 = 0,26.
2. .
, , — n = 100, p = 0,26.
, 30 (30% 100 ): P (x < 30). n = 100, p = 0,26 0,789458. : stattrek.com/online-calculator/binomial.aspx.
, : 78,95.
«, » «» «» .
«, » :
: «» * = 0,2 * 0,7.
: «» * ( – ) + «» * ( ) = «» * = 0,2 * 0,7.
«, » 0,14 , . .
, «, » : 0,2 * 0,7 + 0,4 * 0,3 = 0,26.
2. .
, , — n = 100, p = 0,26.
, 30 (30% 100 ): P (x < 30). n = 100, p = 0,26 0,789458. : stattrek.com/online-calculator/binomial.aspx.
, : 78,95.
B.劇場のシーズンと電話
コンテストで決定する国際チケットサービスは、劇場シーズンの在庫を取ることを決定しました。指標の1つとして、プロジェクトマネージャーは、さまざまなパフォーマンスのチケットを購入したユーザーの数をカウントしたいと考えています。
チケットを購入するとき、ユーザーは自分の電話番号を示します。一意の電話番号の数が最も多い番組を見つける必要があります。そして、一致する一意の電話番号の数を数えます。
入力形式
購入ログは、ticket_logs.csvファイルで入手できます。最初の列には、サービスデータベースのパフォーマンスの名前が含まれています。 2番目-ユーザーが購入時に残した電話番号。陰謀のために、電話の国コードは現在サービスが提供されていないゾーンに置き換えられていることに注意してください。
出力フォーマット
一意の番号の数。
決定
main.py.
. . 801–807.
:
1. 8-(801)-111-11-11
2. 8-801-111-11-11
3. 8801-111-11-11
4. 8-8011111111
5. +88011111111
6. 8-801-flowers, — ( )
:
1. 1–4 replace.
2. 5 , 1. 11 , .
3. 6 , . , .
, . .
. . 801–807.
:
1. 8-(801)-111-11-11
2. 8-801-111-11-11
3. 8801-111-11-11
4. 8-8011111111
5. +88011111111
6. 8-801-flowers, — ( )
:
1. 1–4 replace.
2. 5 , 1. 11 , .
3. 6 , . , .
, . .
C.pFoundを計算する
コンテストで解決アーカイブは3つのテキストファイルが含まれています。- qid_query.tsv-タブで区切られたクエリIDとクエリテキスト。
- qid_url_rating.tsv-リクエストID、ドキュメントURL、リクエストとのドキュメントの関連性。
- hostid_url.tsv-ホストIDとドキュメントのURL。
上位10件のドキュメントから計算されたpFoundメトリックの最大値を使用して要求テキストを表示する必要があります。要求に応じた発行は、以下の規則に従って行われます。
- 1つのホストから、発行されているドキュメントは1つだけです。同じホストIDを持つリクエストのドキュメントが複数ある場合は、最も関連性の高いドキュメントが取得されます(また、複数のドキュメントが最も関連性の高いものである場合は、いずれかが取得されます)。
- オンデマンドのドキュメントは、関連性の高い順に並べ替えられます。
- 異なるホストからの複数のドキュメントの関連性が同じである場合、それらの順序は任意です。
pFoundの計算式:
pFound =pLook [i]・pRel [i]
pLook [1] = 1
pLook [i] = pLook [i-1]⋅(1-pRel [i-1])⋅(1-pBreak)
pBreak = 0.15
出力形式
最大メトリック値を持つ要求テキスト。たとえば、open_task.zipの場合、正解は次のとおりです。
決定
. - — pFound . pandas — .
import pandas as pd
#
qid_query = pd.read_csv("hidden_task/qid_query.tsv", sep="\t", names=["qid", "query"])
qid_url_rating = pd.read_csv("hidden_task/qid_url_rating.tsv", sep="\t", names=["qid", "url", "rating"])
hostid_url = pd.read_csv("hidden_task/hostid_url.tsv", sep="\t", names=["hostid", "url"])
# join , url
qid_url_rating_hostid = pd.merge(qid_url_rating, hostid_url, on="url")
def plook(ind, rels):
if ind == 0:
return 1
return plook(ind-1, rels)*(1-rels[ind-1])*(1-0.15)
def pfound(group):
max_by_host = group.groupby("hostid")["rating"].max() #
top10 = max_by_host.sort_values(ascending=False)[:10] # -10
pfound = 0
for ind, val in enumerate(top10):
pfound += val*plook(ind, top10.values)
return pfound
qid_pfound = qid_url_rating_hostid.groupby('qid').apply(pfound) # qid pfound
qid_max = qid_pfound.idxmax() # qid pfound
qid_query[qid_query["qid"] == qid_max]D.スポーツトーナメント
コンテストで解決する| テストの制限時間 | 2秒 |
| テストごとのメモリ制限 | 256 MB |
| 入力 | 標準入力またはinput.txt |
| 出力 | 標準出力またはoutput.txt |
入力フォーマット
最初の行は整数3≤N≤2含有16 1 - 、N = 2 K -1-過去のゲームの数。次のn行には、スペースで区切られた2つのプレーヤーの姓(ラテン大文字)が含まれています。選手の名前が違います。すべての姓は一意であり、同僚の間に名前の由来はありません。
入力フォーマット
マーシャがゲームを誤って記憶していて、このグリッドを使用してオリンピックシステムに従ってトーナメントを取得することが不可能な場合は、「ソリューションなし」(引用符なし)を印刷します。トーナメントグリッドが可能な場合は、2つの姓を1行に印刷します。最初の候補者の名前です(順序は重要ではありません)。
例1
| 入力 | 出力 |
7
|
IURKOVSKII GORBOVSKII |
| 入力 | 出力 |
3
|
NO SOLUTION |
プレーオフとも呼ばれるオリンピックシステムは、最初の敗北後に競技者がトーナメントから排除される競争組織システムです。オリンピックシステムの詳細については、Wikipediaをご覧ください。
条件からの最初のテストのスキーム:
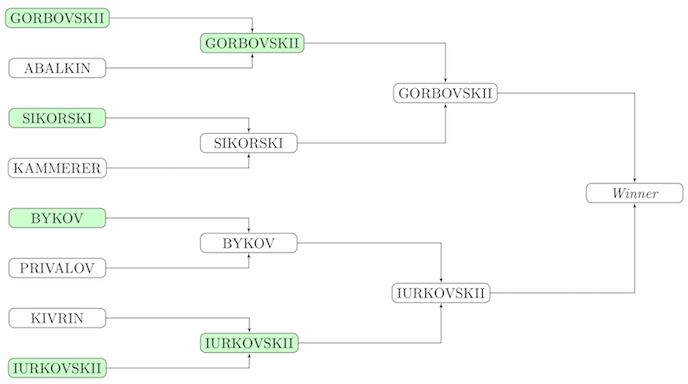
決定
n = 2^k – 1 k. , i- , n_i. , ( k ). , . , i j min(n_i, n_j), - ( ). r (i, j), min(n_i, n_j) = r. :
. 2^k – 1 , :
1. .
2. r 2^{k – r}.
. : , . k. k = 1 — . k – 1 -> k.
-, , . , q . , q- . , 1, 2, ..., q. , , , , 2^k. , 2^{k – 1} n_i = 1. .
, 2^{k – 1} n_i > 1 — . , n_i = 1 2^{k – 1}, . , : n_i = 1, — n_i > 1. k – 1 ( n_i 1). , .
. 2^k – 1 , :
1. .
2. r 2^{k – r}.
. : , . k. k = 1 — . k – 1 -> k.
-, , . , q . , q- . , 1, 2, ..., q. , , , , 2^k. , 2^{k – 1} n_i = 1. .
, 2^{k – 1} n_i > 1 — . , n_i = 1 2^{k – 1}, . , : n_i = 1, — n_i > 1. k – 1 ( n_i 1). , .
import sys
import collections
def solve(fname):
games = []
for it, line in enumerate(open(fname)):
line = line.strip()
if not line:
continue
if it == 0:
n_games = int(line)
n_rounds = n_games.bit_length()
else:
games.append(line.split())
gamer2games_cnt = collections.Counter()
rounds = [[] for _ in range(n_rounds + 1)]
for game in games:
gamer_1, gamer_2 = game
gamer2games_cnt[gamer_1] += 1
gamer2games_cnt[gamer_2] += 1
ok = True
for game in games:
gamer_1, gamer_2 = game
game_round = min(gamer2games_cnt[gamer_1], gamer2games_cnt[gamer_2])
if game_round > n_rounds:
ok = False
break
rounds[game_round].append(game)
finalists = list((gamer for gamer, games_cnt in gamer2games_cnt.items() if games_cnt == n_rounds))
for cur_round in range(1, n_rounds):
if len(rounds[cur_round]) != pow(2, n_rounds - cur_round):
ok = False
break
cur_round_gamers = set()
for gamer_1, gamer_2 in rounds[cur_round]:
if gamer_1 in cur_round_gamers or gamer_2 in cur_round_gamers:
ok = False
break
cur_round_gamers.add(gamer_1)
cur_round_gamers.add(gamer_2)
print ' '.join(finalists) if ok else 'NO SOLUTION'
def main():
solve('input.txt')
if name == '__main__':
main()チャンピオンシップの他のトラックの問題を解決するには、ここで登録する必要があります。