
ビルドが失敗した後の2.5ギガバイトのログを想像してみてください。これは300万行です。100万行目に現れるバグまたはリグレッションを探しています。そのような行を手動で見つけることはおそらく不可能です。1つのオプションは、バグがログに異常な行を書き込んでいることを期待して、最後に成功したビルドと失敗したビルドを区別することです。Netflixのソリューションは、LogReduceよりも高速で正確です。
Netflixとログスタックの行
標準のmd5diffは高速ですが、行の違いを示しているため、表示用に少なくとも数十万の候補行を出力します。logreduceのバリエーションは、約40,000の候補を見つけるk-nearestネイバー検索を使用したファジーdiffですが、1時間かかります。以下のソリューションは、20分で20,000の候補文字列を見つけます。オープンソースの魔法のおかげで、これはたった100行のPythonコードです。
解決策-単語と文の意味情報をエンコードするベクトル単語表現と、場所ベースのハッシュの組み合わせ(LSH-ローカルセンシティブハッシュ)。これは、ほぼ近い要素をいくつかのグループに、離れた要素を他のグループに効果的に分散します。単語のベクトル表現とLSHを組み合わせることは、10年未満 前の素晴らしいアイデアです。
注:Tensorflow 2.2をCPUで実行し、転送学習とscikit-learnNearestNeighborをk個の最近傍で即時実行しました。モデルベースの最近傍問題を解決するのに適した最近傍の複雑な近似があります。
ベクトルワード表現:それは何で、なぜですか?
構築Kカテゴリ(K-ホット符号化、単一の符号化の一般化)を持つ単語の袋は、非構造化および半構造化テキストとの間の重複排除、検索、および類似の問題のための典型的な(かつ有用)を出発点です。このタイプの単語の袋のコーディングは、個々の単語とその番号が記載された辞書のように見えます。「ログインエラー、ログを確認してください」という文の例。
{"log": 2, "in": 1, "error": 1, "check": 1}
このエンコーディングもベクトルで表され、インデックスは単語に対応し、値は単語の数に対応します。以下に示すのは、「log in error、check log」というフレーズをベクトルとして示したものです。最初のエントリは「log」という単語をカウントするために予約され、2番目のエントリは「in」という単語をカウントするために予約されています。
[2, 1, 1, 1, 0, 0, 0, 0, 0, ...]
注意:ベクトルは多くのゼロで構成されています。ゼロは、この文にない辞書内の他のすべての単語です。可能なベクトルエントリの総数、またはベクトルの次元は、言語の語彙のサイズであり、多くの場合、数百万語以上ですが、巧妙な トリックで数十万に縮小します。
「problemauthentificating」というフレーズの辞書とベクトル表現を見てみましょう。最初の5つのベクトルエントリに一致する単語は、新しい文にはまったく表示されません。
{"problem": 1, "authenticating": 1}
それが判明:
[0, 0, 0, 0, 1, 1, 0, 0, 0, ...]
「認証の問題」と「ログインエラー、ログの確認」のステートメントは意味的に類似しています。つまり、それらは本質的に同じですが、字句的に可能な限り異なります。彼らには一般的な言葉はありません。ファジーdiffに関しては、類似しすぎて区別できないと言えますが、md5エンコーディングとk-hotとkNNで処理されたドキュメントはこれをサポートしていません。
次元縮小では、線形代数または人工ニューラルネットワークを使用して、意味的に類似した単語、文、またはログ行を新しいベクトル空間に並べて配置します。ベクトル表現が使用されます。この例では、「ログインエラー、ログの確認」は、次のことを表す5次元のベクトルを持つことができます。
[0.1, 0.3, -0.5, -0.7, 0.2]
「問題の認証」というフレーズは、
[0.1, 0.35, -0.5, -0.7, 0.2]
これらのベクトルは、ワードバッグベクトルとは対照的に、コサイン類似性などの測定値の点で互いに近接しています。高密度で低次元のビューは、アセンブリラインやsyslogなどの短いドキュメントに非常に役立ちます。
実際、辞書の数千以上の次元を、情報が豊富な100次元の表現(5つではない)に置き換えることになります。次元削減への最新のアプローチには、単語共起行列(GloVe)と特殊なニューラルネットワーク(word2vec、BERT、ELMo)の特異値分解が含まれます。
クラスタリングはどうですか?ビルドログに戻りましょう
Netflixは時折ビデオをストリーミングするログ作成サービスであると冗談を言っています。ロギング、ストリーミング、例外処理-これらは1秒あたり数十万のリクエストです。したがって、テレメトリとロギングに適用されたMLを適用する場合は、スケーリングが必要です。このため、テキストの重複排除のスケーリング、意味の類似性の検索、テキストの異常の検出には注意が必要です。ビジネス上の問題がリアルタイムで解決される場合、他の方法はありません。
私たちのソリューションでは、各行を低次元のベクトルで表現し、オプションで「微調整」するか、埋め込みモデルを同時に更新してクラスターに割り当て、異なるクラスターの線を「異なる」として定義します。ロケーション認識ハッシュ-一定の時間でクラスターを割り当て、ほぼ一定の時間で最近傍を検索できる確率的アルゴリズム。
LSHは、ベクトル表現を一連のスカラーにマッピングすることによって機能します。標準のハッシュアルゴリズムは、一致する2つの入力間の衝突を回避する傾向があります。 LSHは、入力が離れている場合は衝突を回避しようとし、入力が異なるがベクトル空間で互いに近い場合は衝突を促進します。
「ログインエラー、チェックエラー」というフレーズを表すベクトルは、2進数と一致させることができます
01。次に01クラスターを表します。確率の高いベクトル「problemauthentificating」も01に表示できます。したがって、LSHはファジー比較を提供し、逆の問題であるファジー差を解決します。 LSHの初期のアプリケーションは、一連の単語からの多次元ベクトル空間を介して行われました。彼が単語のベクトル表現のスペースを使用しない理由は1つも考えられませんでした。指摘がある他の人が 考えて も同じ。

上記は、同じグループに文字を逆さまに配置する場合のLSHの使用法を示しています。
ビルドログでテキストの異常を検出することでLSHとベクトルの切り取りビューを適用するために行った作業により、エンジニアはログ行のごく一部を表示して、潜在的なビジネスクリティカルエラーを特定して修正できるようになりました。また、ほぼすべてのログ行のセマンティッククラスタリングをリアルタイムで実現できます。
このアプローチは、Netflixのすべてのビルドで機能するようになりました。セマンティック部分を使用すると、一見異なるアイテムをその意味に基づいてグループ化し、それらのアイテムを排出量レポートに表示できます。
いくつかの例
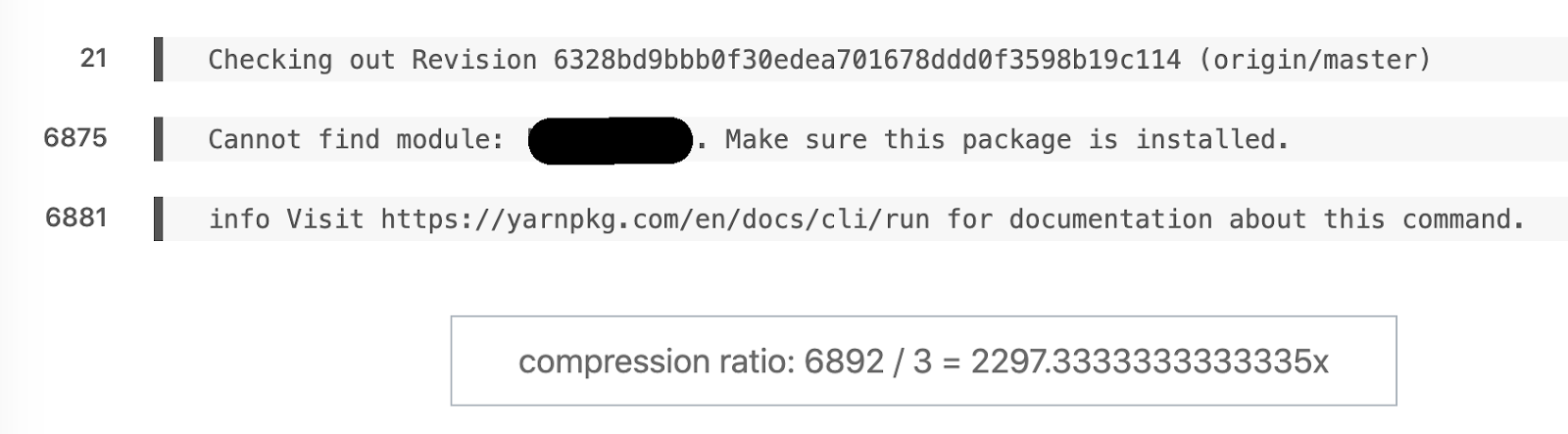
セマンティックdiffのお気に入りの例。6892行が3になりました。
別の例:このアセンブリは6044行を記録しましたが、171がレポートに残っていました。主な問題は4036行でほぼすぐに表面化しました。

もちろん、6044よりも171行を解析する方が高速です。家電製品のストレステストである何千ものビルドタスクのいくつかは、トレースモードで実行されます。前処理なしでこのような量のデータを処理することは困難です。

圧縮率:91366/455 = 205.3。
フレームワーク、言語、ビルドスクリプト間の意味の違いを反映するさまざまな例があります。
結論
オープンソースの転送学習製品とSDKの成熟により、LSHはほんの数行のコードでセマンティック最近傍検索の問題を解決することができました。転移学習と微調整がアプリにもたらす特別なメリットに興味がありました。私たちは、そのような問題を解決し、人々がより良く、より速く行うことを支援できることを嬉しく思います。
Netflixに参加して、機械学習で生活を楽にする素晴らしい同僚の1人になることを検討してください。エンゲージメントはNetflixのコアバリューであり、私たちは特に技術チームのさまざまな視点を育むことに関心を持っています。したがって、分析、エンジニアリング、データサイエンス、またはその他の分野にいて、業界に典型的ではない経歴をお持ちの場合は、特にご意見をお聞かせください。
Netflixの機能について質問がある場合は、LinkedInの寄稿者に連絡してください:Stanislav Kirdey、William Highログ検索の問題をどのように解決します
か?
オンラインのSkillFactoryコースを受講して、注目を集める職業をゼロから取得する方法、またはスキルと給与をレベルアップする方法の詳細を確認してください。
- Machine Learning (12 )
- «Machine Learning Pro + Deep Learning» (20 )
- « Machine Learning Data Science» (20 )
- Data Science (12 )
E
