
1999年に最初のGPUが発明されて以来、NVIDIAは3DグラフィックスとGPUアクセラレーションコンピューティングの最前線に立ってきました。各NVIDIAアーキテクチャは、革新的なレベルのパフォーマンスと効率を提供するように注意深く設計されています。
NVIDIA Ampereアーキテクチャを備えた最初のGPUであるA100は、2020年5月にリリースされました。 AIトレーニング、HPC、およびデータ分析に驚異的な加速を提供します。 A100はGA100チップに基づいています。これは純粋に計算用であり、GA102とは異なり、まだゲーム化されていません。
GA10x GPUは、NVIDIA TuringGPUアーキテクチャに基づいています。Turingは、高性能のリアルタイムレイトレース、AIアクセラレーショングラフィックス、およびプロフェッショナルグラフィックスレンダリングをすべて1つのデバイスで提供する世界初のアーキテクチャです。
この記事では、新しいNVIDIAビデオカードのアーキテクチャにおける主な変更点を、以前のカードと比較して分析します。

図1.AmpereGA10xアーキテクチャ
GA102の主な機能
GA102は、NVIDIA独自の8nmテクノロジーである8N NVIDIACustomを使用して製造されています。このチップには、628.4mm2のダイに283億個のトランジスタが含まれています。すべてのGeForceRTXと同様に、GA102は、次の3種類のコンピューティングリソースを含むプロセッサに基づいています。
- プログラム可能なシェーディング用のCUDAカーネル。
- RT-, (BVH) ;
- , .
Ampere
GPC, TPC SM
GA102は、その前身と同様に、グラフィックス処理クラスター(GPC)、テクスチャ処理クラスター(TPC)、ストリーミングマルチプロセッサー(SM)、ラスターオペレーター(ROP)ラスター化ユニット、およびメモリコントローラーで構成されています。完全なチップには、7つのGPCユニット、42のTPC、84のSMがあります。
GPCは、すべての主要なグラフィックを含む主要な高レベルブロックです。各GPCには専用のラスターエンジンがあり、それぞれ8ブロックの2つのROPセクションもあります。これはAmpereアーキテクチャの革新です。さらに、GPCには6つのTPCが含まれ、それぞれに2つのマルチプロセッサと1つのPolyMorphエンジンが含まれています。
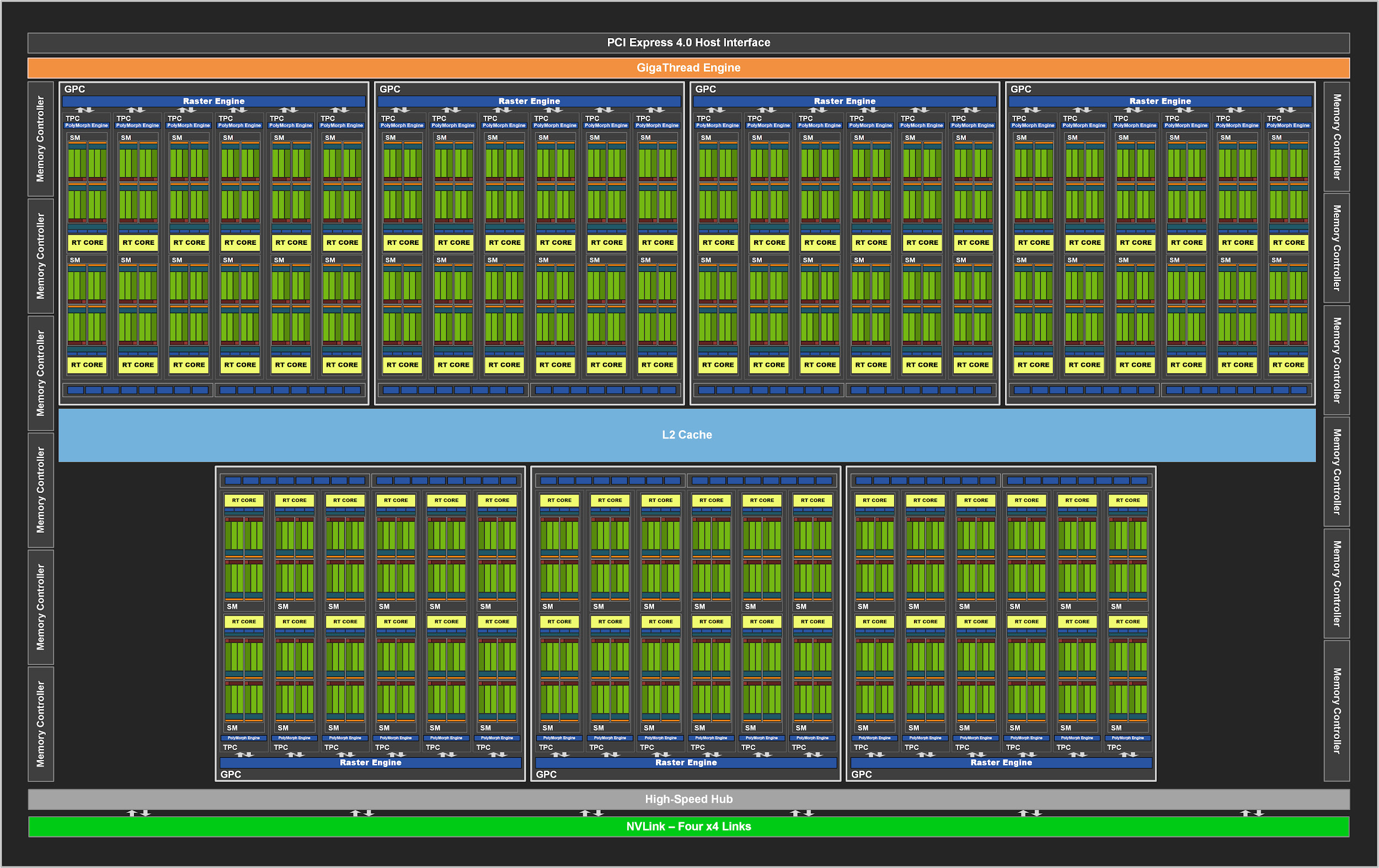
図2.84個のSMブロックを備えた完全なGPUGA102
次に、GA10xの各SMには、128個のCUDAコア、第3世代の4個のTensorコア、256 KBのレジスタファイル、4個のテクスチャユニット、第2世代の1個のレイトレースコア、および128 KBのL1 /共有メモリが含まれ、さまざまな容量に設定できます。コンピューティングまたはグラフィックスタスクのニーズに応じて。
ROPの最適化
以前のNVIDIAGPUでは、ROPはメモリコントローラーとL2キャッシュに関連付けられていました。GA10x以降、これらはGPCの一部であり、ROPの総数を増やすことでラスターのパフォーマンスを向上させます。
合計で、各GPCに7つのGPCと16のROPがあり、GA102 GPUは、たとえばTU102では96ではなく112のROPで構成されます。これらはすべて、マルチサンプルアンチエイリアシング、ピクセルフィルレート、およびブレンディングにプラスの効果をもたらします。
NVLink第3世代
GA102 GPUは、4つのx4レーンを含む第3世代のNVIDIA NVLinkをサポートし、それぞれが2つのGPU間でいずれかの方向に14.0625 GB / sの帯域幅を提供します。4つのチャネルを合わせると、各方向に56.25 GB / sの帯域幅が提供され、2つのGPU間で合計112.5 GB / sの帯域幅が提供されます。したがって、NVLinkを使用すると、2つのRTX 3090GPUを接続できます。
PCIe Gen 4
GA10xGPUにはPCIExpress 4.0が搭載されており、PCIe 3.0の2倍の帯域幅、最大16GTransfers /秒の転送速度を提供し、x16 PCIe4.0スロットのおかげでピーク帯域幅は64GB /秒に達します。
GA10xマルチプロセッサアーキテクチャ
Turingマルチプロセッサアーキテクチャは、レイトレース操作を高速化するために個別のコアを備えたNVIDIAで最初のものでした。次に、Voltaは最初のテンソルカーネルを導入し、Turingは改良された第2世代のテンソルカーネルを導入しました。TuringとVoltaのもう1つの革新は、FP32とINT32の操作を同時に実行する機能です。GA10xのマルチプロセッサは、上記のすべての機能をサポートし、独自の改善点もいくつかあります。
8つの第2世代テンソルコアを備えたTU102とは異なり、GA10xマルチプロセッサには4つの第3世代テンソルコアがあり、各GA10xテンソルコアはTuringの2倍強力です。
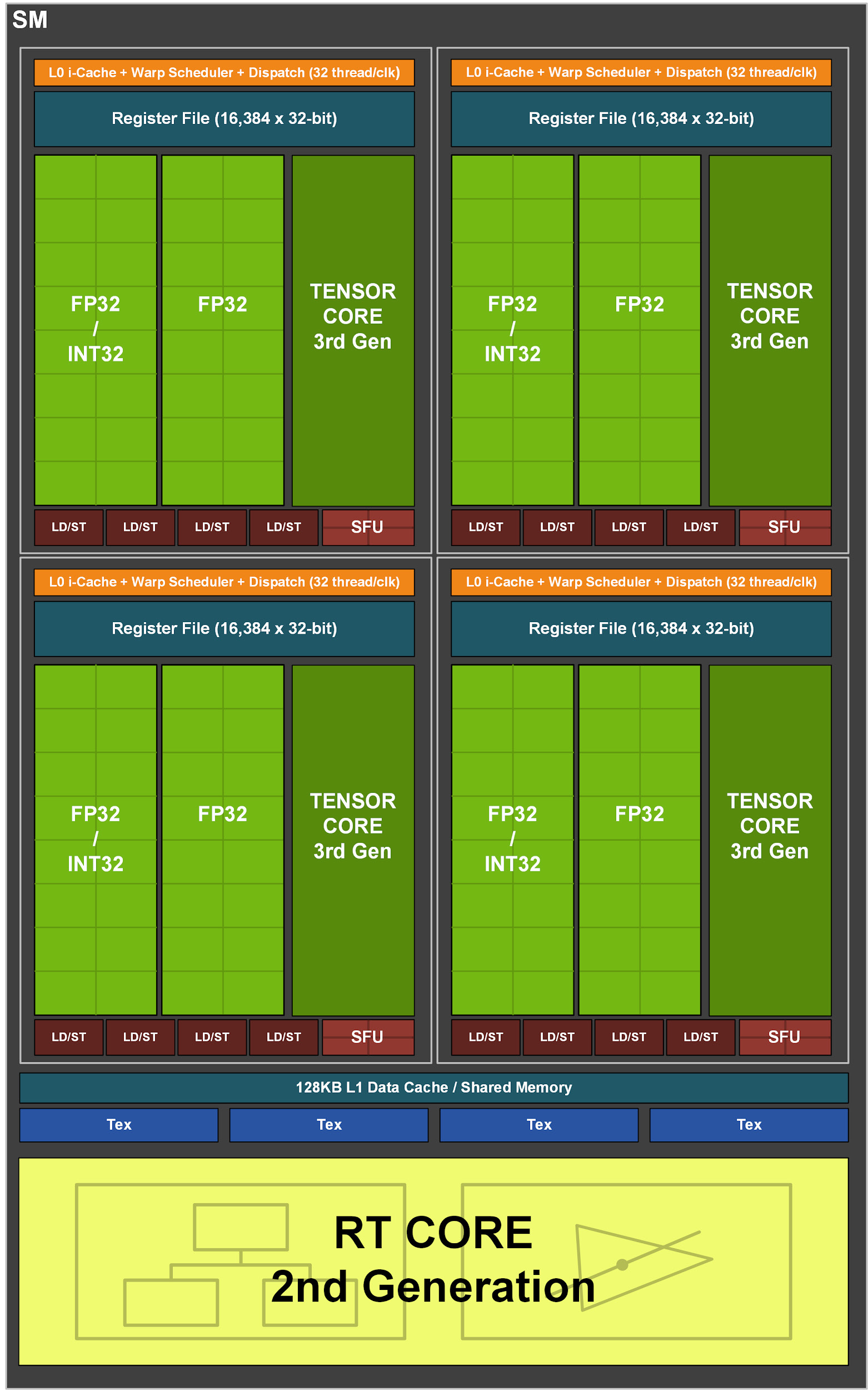
図3.GA10xストリーミングマルチプロセッサ
FP32コンピューティングの2倍の速度
グラフィック計算のほとんどは、32ビット浮動小数点(FP32)操作です。 Ampere GA10xストリーミングマルチプロセッサは、両方のデータチャネルでFP32操作の2倍の速度を提供します。その結果、FP32のコンテキストでは、GeForce RTX 3090は35テラフロップ以上を提供します。これは、Turingの2倍以上の機能です。
GA10Xは、クロックごとに128のFP32操作または64のFP32操作と64のINT32操作を実行できます。これは、Turing計算の2倍の速度です。
最新のゲームタスクには、幅広い処理ニーズがあります。多くの計算には、一連のFP32操作(FFMA、浮動小数点加算(FADD)、浮動小数点乗算(FMUL)など)と、より単純な整数計算が必要です。
GA10xマルチプロセッサは、引き続きデュアルスピードFP16(HFMA)操作をサポートします。これは、Turingでもサポートされていました。また、TU102、TU104、およびTU106 GPUと同様に、GA10xでは、標準のFP16操作もテンソルコアによって処理されます。
共有メモリとL1データキャッシュ
GA10xには、共有メモリ、L1データキャッシュ、およびテクスチャキャッシュの統合アーキテクチャがあります。この統一された設計は、ワークロードとニーズに基づいて変更できます。
GA102チップには10,752KBのL1キャッシュが含まれています(TU102の6912 KBと比較して)。これとは別に、GA10xにはTuringの2倍の共有メモリ帯域幅もあります(128バイト/サイクル対64バイト/サイクル)。GeForce RTX3080の合計L1帯域幅は219GB /秒ですが、GeForce RTX2080スーパーの場合は116GB /秒です。
ワットあたりのパフォーマンス
すべてのNVIDIAAmpereアーキテクチャは、ロジック、メモリ、電力、熱の管理からPCBの設計、ソフトウェア、アルゴリズムに至るまで、効率を向上させるように構築されています。同じパフォーマンスレベルで、Ampere GPUは、同等のTuringデバイスよりも最大1.9倍電力効率が高くなっています。
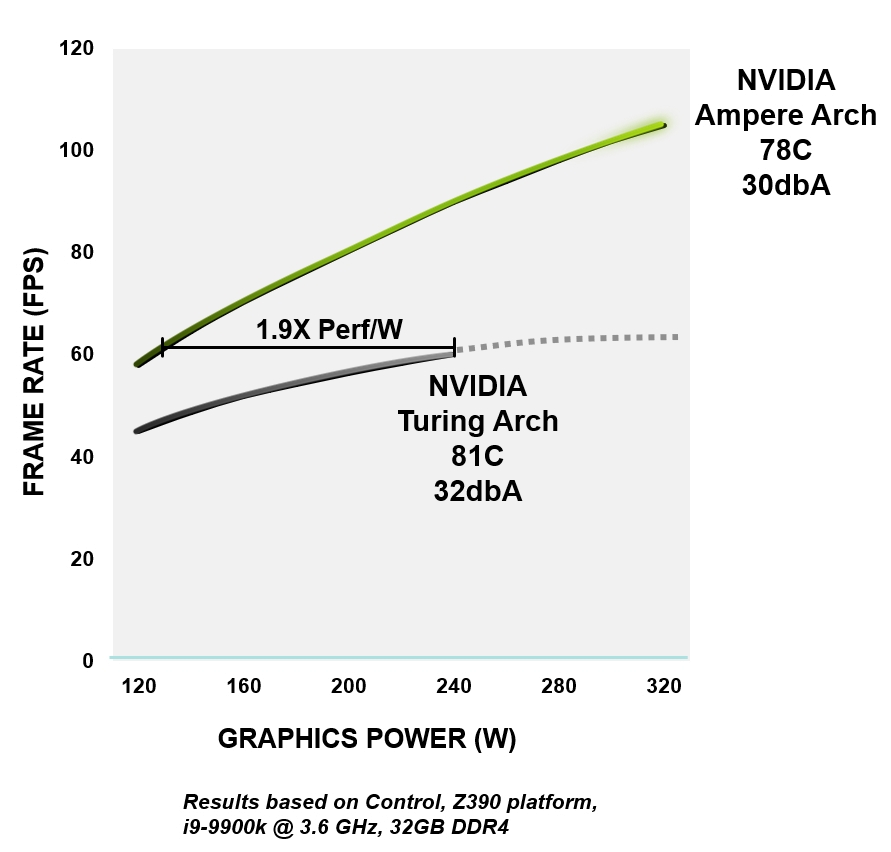
図4.RTX3080の電力効率とGeForceRTX2080スーパーアーキテクチャの比較
第2世代RTコア
新しいRTコアは、更新されたキャッシングシステムと組み合わせて、TuringよりもAmpereプロセッサのレイトレースパフォーマンスを効果的に2倍にする多くの拡張機能を備えています。さらに、GA10xを使用すると、他のプロセスをRTコンピューティングと同時に実行できるため、多くのタスクが大幅に高速化されます。
GA10xの第2世代レイトレース
Turingアーキテクチャに基づくGeForceRTXは、映画のような光線追跡がPCゲームで実現された最初のGPUでした。GA10xには、第2世代のレイトレーステクノロジーが搭載されています。Turingと同様に、GA10xのマルチプロセッサには、BVHおよび三角形との光線の交差をチェックするための専用のハードウェアブロックがあります。同時に、Ampereマルチプロセッサのコアは、Turingと比較して光線と三角形の交差をテストする速度が2倍になります。
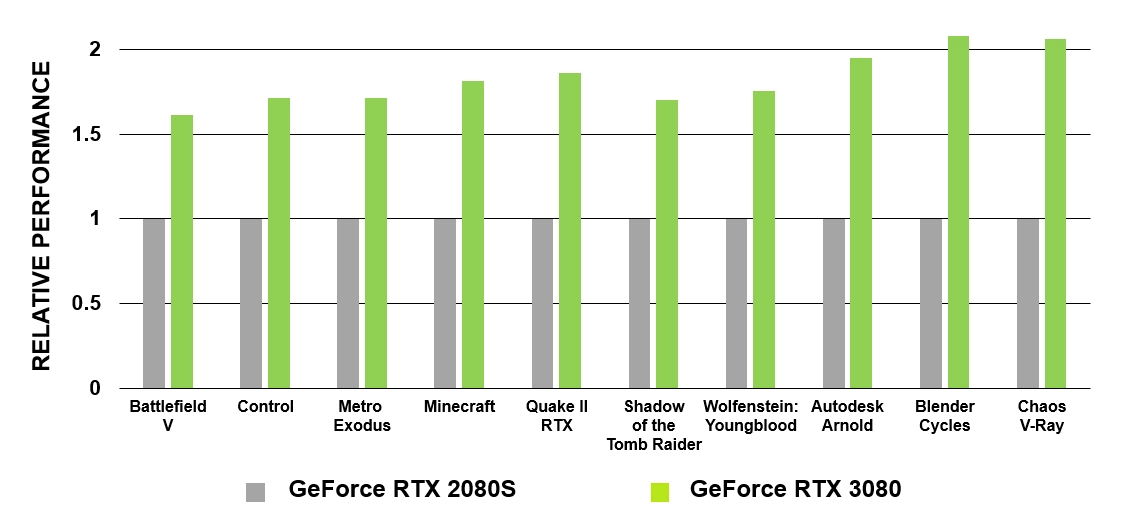
図5.GeForce RTX3080とGeForceRTX2080スーパーのRTコアのパフォーマンスの比較
GA10xマルチプロセッサは、操作を同時に実行でき、前世代のGPUの場合のように、コンピューティングとグラフィックスに限定されません。そのため、たとえばGA10xでは、ノイズリダクションアルゴリズムをレイトレースと同時に実行できます。

図6.GA10x GPUの第2世代RTコア
RTを多用するワークロードは、マルチプロセッサコアの負荷を大幅に増加させないため、マルチプロセッサの処理能力を他のタスクに使用できることに注意してください。これは、専用のRTコアを持たないため、グラフィックスとレイトレースの両方にビルディングブロックを使用する必要がある他の競合するアーキテクチャに比べて大きな利点です。
動作中のAmpereRTXプロセッサ
レイトレースとシェーダーは計算量が多くなります。ただし、CUDAコアだけですべてを実行する方がはるかにコストがかかるため、テンソルコアとRTコアを含めると、処理が大幅に高速化されます。図7は、さまざまなシナリオでレイトレースが有効になっているWolfenstein:Youngbloodゲームの例を示しています。
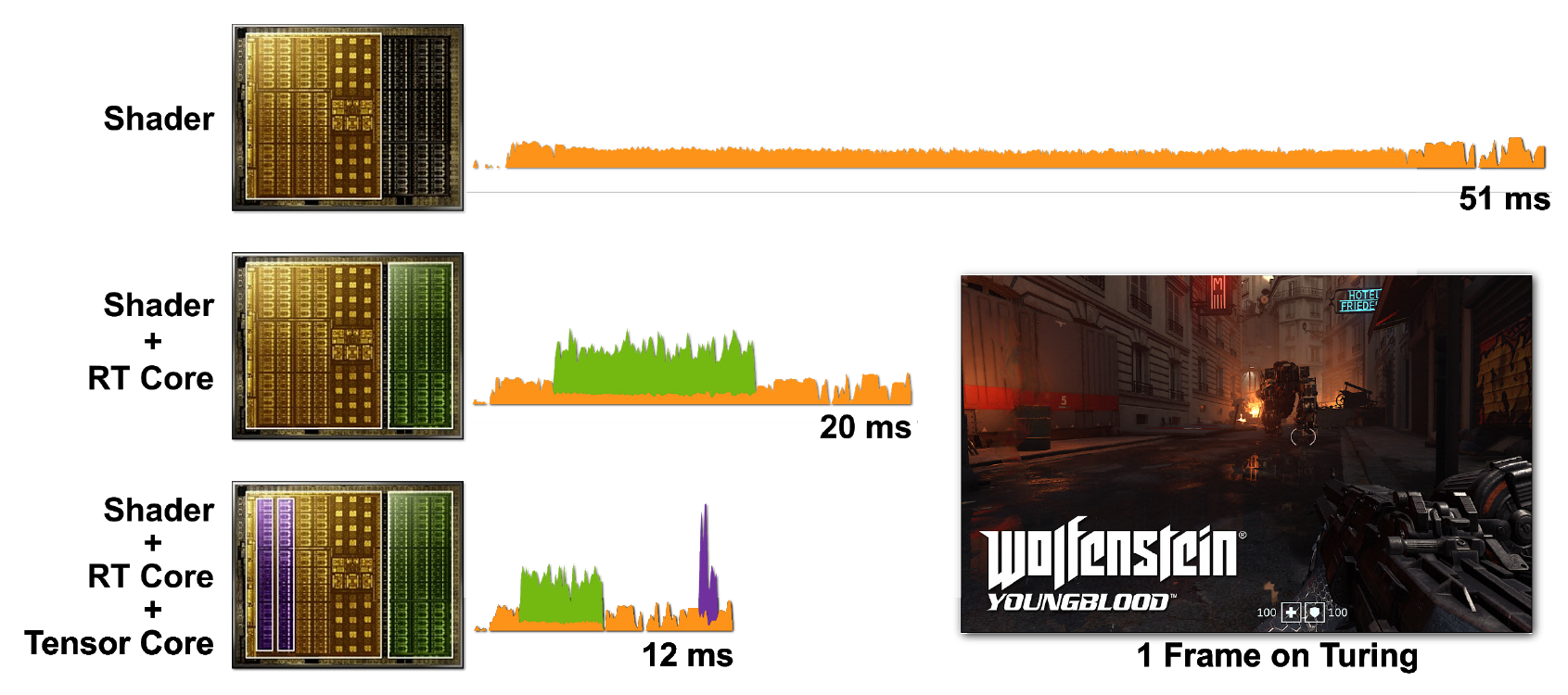
図7.Wolfensteinの単一フレームのレンダリング:a)シェーダーコア(CUDA)、b)シェーダーコアとRTコア、c)シェーダーコア、テンソルコア、RTコアを使用したRTX2080スーパーGPUでのYoungblood。さまざまなRTXプロセッサコアの能力を追加すると、フレーム時間が徐々に減少することに注意してください。
最初のケースでは、1つのフレームを開始するのに51ミリ秒(約20 fps)かかります。RTコアをオンにすると、フレームは20ミリ秒(50 fps)ではるかに高速にレンダリングされます。テンソルコアでDLSSを使用すると、フレーム時間が12ミリ秒(約83 fps)に短縮されます。
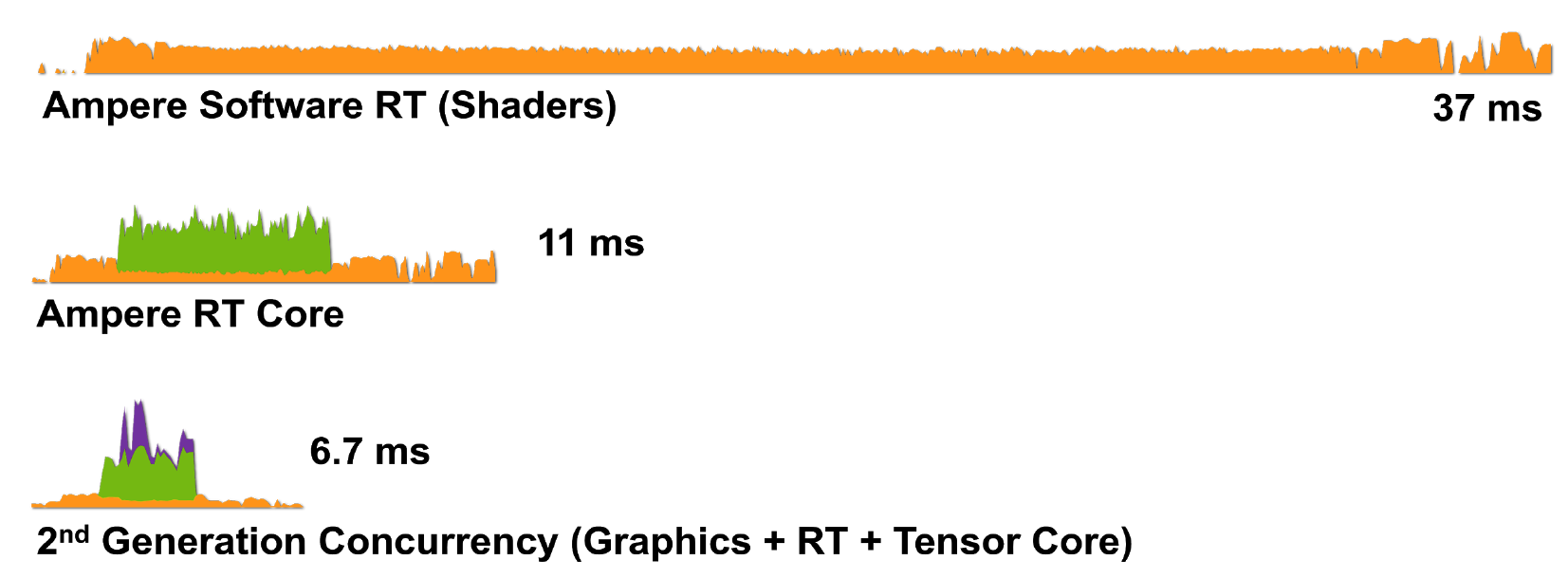
図8.a)シェーダーコア(CUDA)、b)シェーダーコアとRTコア、c)シェーダーコア、テンソル、RTコアを使用したRTX 3080でのWolfenstein:Youngbloodの単一フレームのレンダリング。
したがって、Ampereアーキテクチャを使用したRTXテクノロジは、レンダリングタスクの処理においてさらに効率的です。RTX3080は、フレームを6.7ミリ秒(150 fps)でレンダリングします。これは、RTX2080よりも大幅に改善されています。
モーションブラーを使用したハードウェア加速光線追跡
モーションブラーは、コンピューターグラフィックスでよく使用される動きです。写真画像は即座に作成されるのではなく、限られた時間フィルムを光にさらすことによって作成されます。カメラの露光時間と比較して十分に速く動いている被写体は、写真に縞または斑点として表示されます。 GPUが、シーン内のオブジェクトが静的カメラの前をすばやく移動するときにリアルな外観のモーションブラーを作成するには、カメラとフィルムがそのようなシーンでどのように機能するかをシミュレートできる必要があります。映画は毎秒24フレームで再生され、モーションブラーのないシーンはシャープで途切れ途切れに見えるため、モーションブラーは映画制作で特に重要です。
チューリングGPUは、一般的にモーションブラーを加速するのにかなり良い仕事をします。ただし、ジオメトリを移動する場合、BVHに関する情報は空間内のオブジェクトの位置によって変化するため、タスクはより困難になる可能性があります。
図9に示すように、Turing RTコアは、BVH階層のハードウェアトラバーサルを実行し、光線とBBoxおよび三角形との交差をチェックします。 GA10xはすべて同じことを実行できますが、それに加えて、レイトレースのモーションブラーを加速する新しいInterpolate TrianglePositionブロックがあります。
TuringコアとGA10xRTコアはどちらも、複数のビームを同時に処理できる複数命令複数データ(MIMD)アーキテクチャを実装しています。
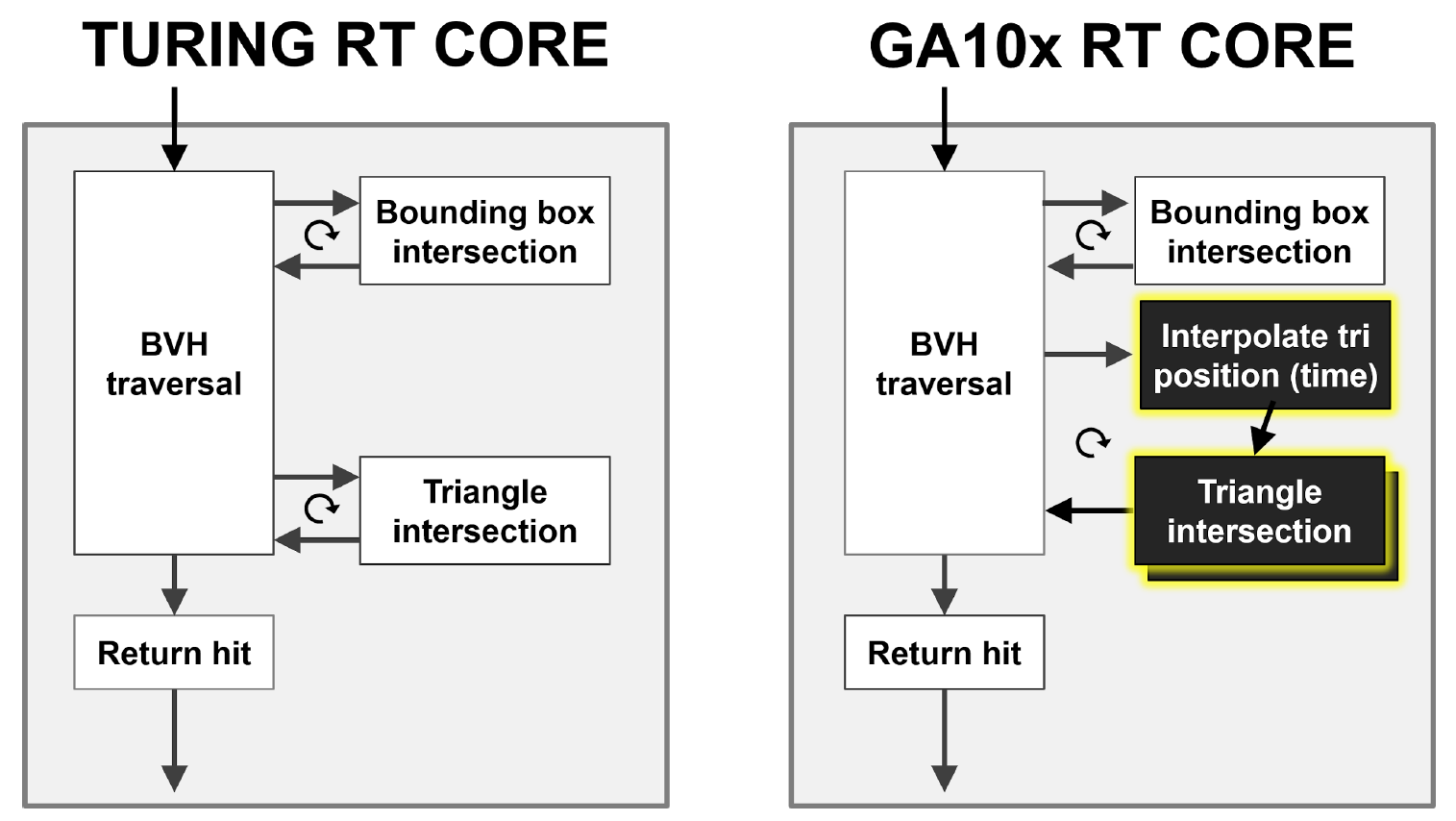
図9.TuringとAmpere
の場合のモーションブラーのハードウェア加速の比較モーションブラーの主な問題は、シーン内の三角形が時間内に固定されていないことです。基本的なレイトレースでは、静的交差テストが実行され、レイが三角形に当たると、そのヒットに関する情報が返されます。図10に示すように、モーションブラーを使用すると、どの三角形も固定座標を持ちません。各光線には、追跡時間を示すためにタイムスタンプが付けられ、三角形の位置と光線の交点は、BVH方程式から決定されます。
このプロセスがハードウェアによって加速されない場合、その非線形性などが原因で、多くの問題が発生する可能性があります。
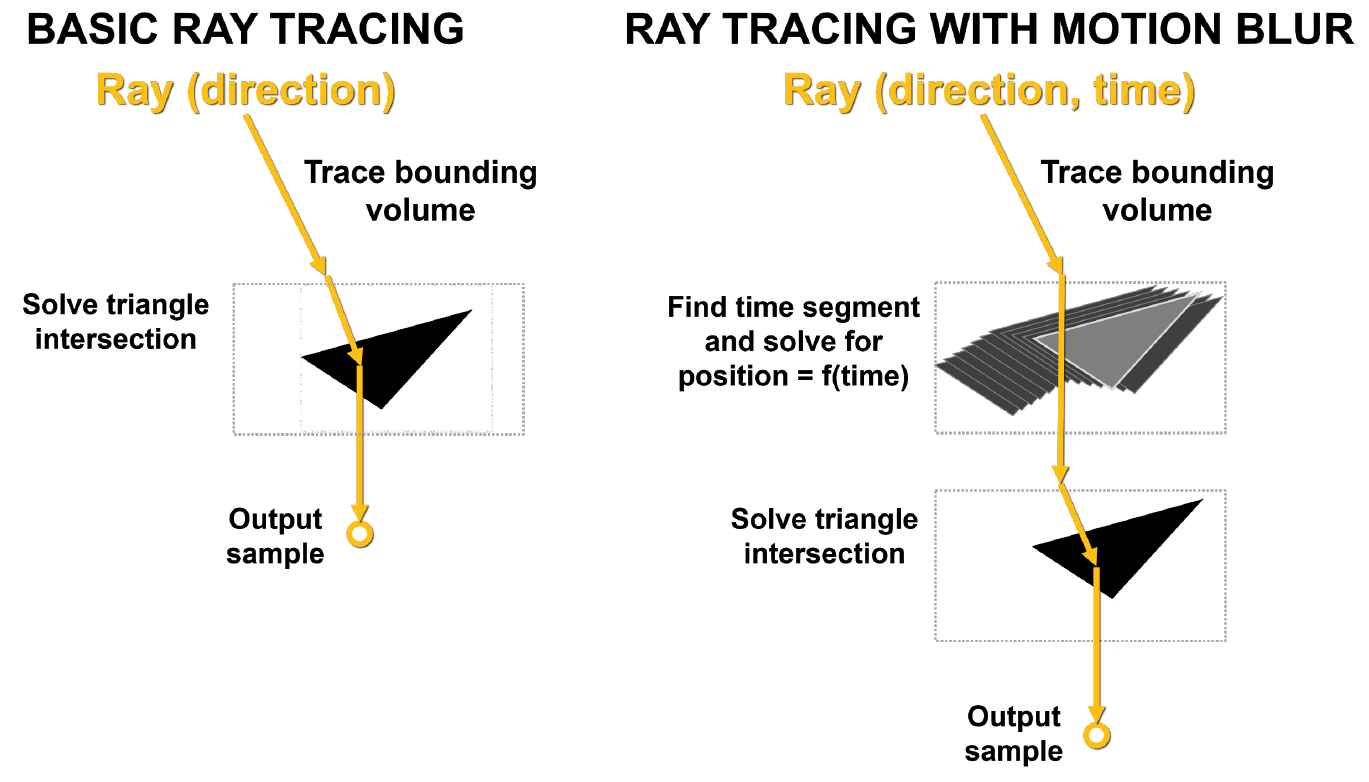
図。 10.基本的なレイトレースとモーションブラーを使用したレイトレース
図11の左側では、静的シーンに送信されたレイが同じ三角形に同時に当たります。白い点は衝撃の場所を示し、この結果は返されます。モーションブラーの場合、各光線は独自の時点で存在します。各ビームには、ランダムに異なるタイムスタンプが割り当てられます。たとえば、オレンジ色の光線がオレンジ色の三角形を同時に通過しようとすると、緑と青の光線は同じことを行います。最後に、サンプルがブレンドされ、より数学的に正しいぼやけた結果が生成されます。
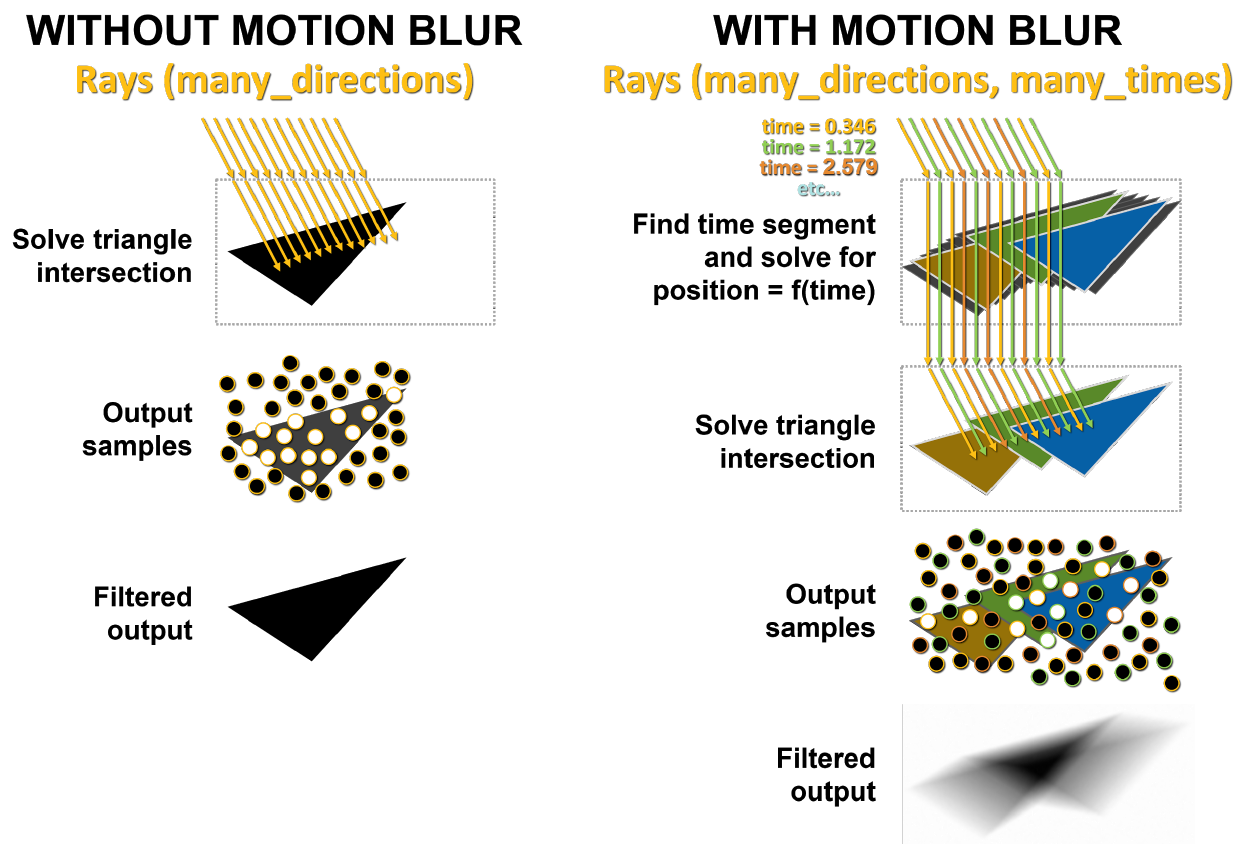
図11.GA10xでのモーションブラーなしおよびブラーありのレンダリング
Interpolate Triangle Positionブロックは、オブジェクトの動きに基づいて既存の三角形間のBVHの三角形を補間し、光線のタイムスタンプで指定された瞬間に、光線が予想される位置でそれらと交差するようにします。このアプローチにより、レイトレースされたモーションブラーをTuringよりも最大8倍高速に正確にレンダリングできます。
GA10xハードウェアアクセラレーションモーションブラーは、NVIDIA OptiX 7.0APIを使用するBlender2.90、Chaos V-Ray 5.0、Autodesk Arnold、およびRedshift Renderer3.0.Xでサポートされています。
モーションブラーのレンダリング速度は、RTX2080スーパーと比較してRTX3080で最大5倍高速です。
GA10xGPUの第3世代テンソルコア
GA10xには、新しい第3世代のNVIDIA Tensorコアが組み込まれており、新しいデータタイプのサポート、パフォーマンス、効率の向上、プログラミングの柔軟性が特徴です。新しいスパース機能は、前世代のTuringよりもTensorCoreのパフォーマンスを2倍にします。 AI超解像度用のNVIDIADLSS(現在は8Kをサポート)、音声およびビデオ処理用のNVIDIA Broadcast、描画用のNVIDIACanvasなどのAI機能も高速です。
テンソルカーネルは、テンソル/マトリックス操作を実行するように設計された特殊な実行ユニットです。これは、深層学習の主要な計算機能です。これらは、DLSS(Deep Learning Super Sampling)、AIベースのノイズキャンセル、RTX Voiceを使用したゲームボイスチャット内のバックグラウンドノイズの除去、およびその他の多くのアプリケーションでグラフィック品質を向上させるために必要です。
GeForceゲーミングGPUへのTensorCoreの導入により、ゲーミングアプリケーションでのリアルタイムの詳細な学習が初めて可能になりました。GA10x GPUの第3世代テンソルコア設計は、生のパフォーマンスをさらに向上させ、TF32やBFloat16などの新しい計算精度モードを活用します。これは、AIベースのNVIDIA NGXニューラルサービスアプリケーションで大きな役割を果たし、グラフィックス、レンダリング、およびその他の機能を改善します。
チューリングとアンペアテンソルコアの比較
Ampere Tensor Coreは、効率を改善し、電力消費を削減するためにTuring上で再編成されました。Ampere SMコアアーキテクチャにはテンソルコアが少なくなっていますが、それぞれがより強力です。
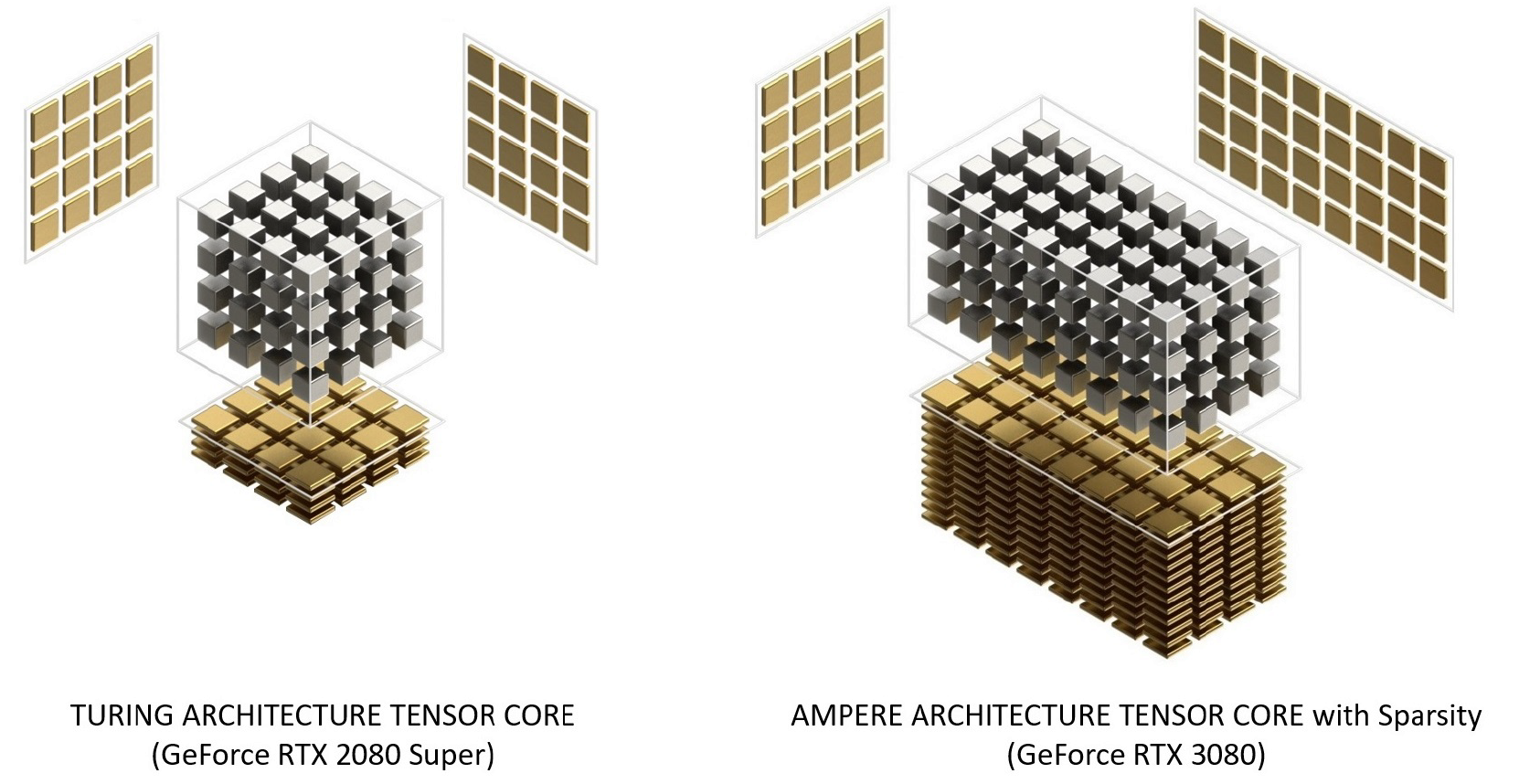
図12.TuringおよびAmpereアーキテクチャのテンソルコア。GeForce RTX 3080は、GeForce RTX2080スーパーより2.7倍速いFP16TensorCoreピーク帯域幅を提供します。
きめ細かい構造化されたスパース性
NVIDIAは、A100 GPUを使用して、ディープニューラルネットワークの計算帯域幅を2倍にする新しいアプローチであるFine-Grained StructuredSparsityを導入しました。この機能はGA10xGPUでもサポートされており、AIベースのグラフィックレンダリング操作を高速化するのに役立ちます。
深層学習ネットワークはフィードバック学習を通じて重みを適応させることができるため、一般に、構造上の制約はトレーニング済みモデルの精度に影響を与えません。
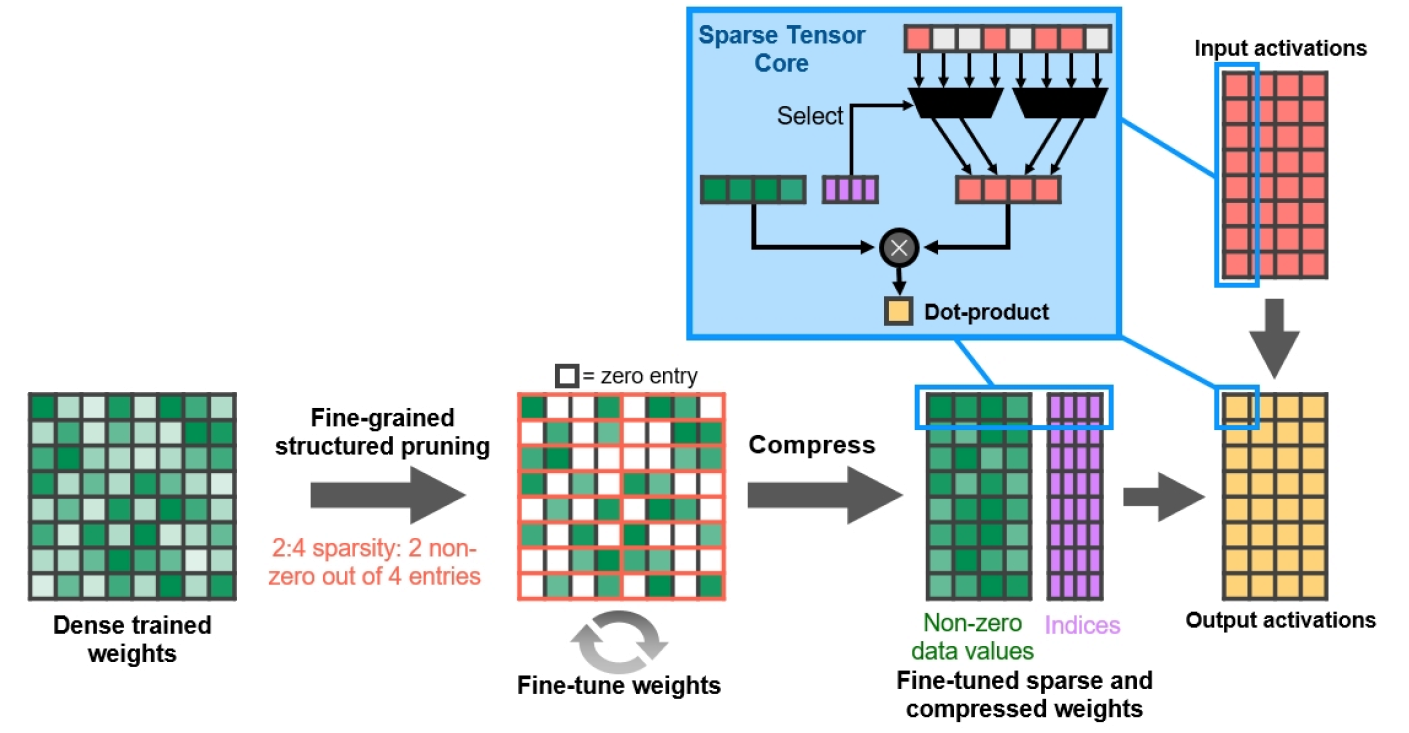
図13.きめ細かい構造化されたスパース性
NVIDIAは、構造化された2:4スパースパターンを使用して、シンプルで用途の広いディープニューラルネットワークスパースネスアルゴリズムを開発しました。ネットワークは最初に密な重みでトレーニングされ、次にきめ細かい構造化されたプルーニングが行われ、その後ゼロ値を破棄でき、残りの数学はスループットを向上させるために圧縮されます。このアルゴリズムは、トレーニングされた推論ネットワークの精度には影響せず、速度を上げるだけです。
NVIDIA DLSS 8K
高いフレームレートでレイトレースを使用して画像をレンダリングすると、計算コストが非常に高くなります。 NVIDIA Turingが登場する前は、その実装には何年もかかると考えられていました。この問題を解決するために、NVIDIAはDeep Learning Supersampling(DLSS)を作成しました。

図14.ウォッチドッグ:1080p、4K、および8KのDLSSを備えた軍団。 DLSSが8Kで提供するより鮮明なテキストと詳細
DLSSは、第3世代のテンソルコアと9倍の超解像度スケーリング係数を使用することでNVIDIA Ampereでのみ改善されていることに注意してください。これにより、初めて8K、60fpsでレイトレースゲームを実行できるようになります。
15. GeForce RTX 3090 60 fps 8K DLSS . , . Core i9-10900K
GDDR6X
最新のPCゲームとクリエイティブアプリケーションは、ますます複雑になるシーンジオメトリ、より詳細なテクスチャ、レイトレース、AI推論、そしてもちろんシェーディングとスーパーサンプリングを処理するために、大幅に多くのメモリ帯域幅を必要とします。
GDDR6Xは、900 GB / sを超える最初のグラフィックメモリです。これを実現するために、革新的な信号技術と4レベルのパルス振幅変調(PAM4)が採用され、データがメモリ内で移動される方法に革命をもたらしました。 PAM4アルゴリズムを使用すると、GDDR6Xはより多くのデータをはるかに高速で転送し、一度に2ビットのデータを移動します。これにより、以前のPAM2 / NRZスキームのI / Oデータレートが2倍になります。
GDDR6Xは現在、GeForce RTX3090で19.5Gbps、GeForce RTX3080で19Gbpsをサポートしています。このおかげで、GeForce RTX 3080は、その前身であるRTX 2080Superの1.5倍のメモリパフォーマンスを提供します。 ..。
図16に、GDDR6(左)とGDDR6X(右)の構造の比較を示します。 GDDR6Xは、GDDR6の半分の周波数で同じデータを送信します。または、GDDR6Xは、同じ周波数を維持しながら、実効帯域幅を2倍にすることもできます。

図16.PAM4信号を使用したGDDR6Xは、GDDR6よりも優れたパフォーマンスと効率を示しています
PAM4シグナリングで発生するSNRの問題に対処するために、新しいMTA(Maximum Transition Prevention)コーディングスキームが開発されました。MTAは、高速信号が最高から最低に、またはその逆に進むのを防ぎます。

図17.GDDR6Xの新しいエンコーディング
GA10xチップで最大19.5GbpsのデータレートをサポートするGDDR6Xは、GeForceRTXで使用されるTU102GPUより52%多い最大936 GB / sのピークメモリ帯域幅を提供します2080 Ti GDDR6Xは、GeForce 200シリーズGPUに続いて、10年間で帯域幅が最大に飛躍しました。
RTX IO
現代のゲームには巨大な世界が含まれています。写真測量などの技術の開発に伴い、それらはますます現実を模倣し、その結果、ますますボリュームのあるファイルに含まれています。最大のゲームプロジェクトは200GB以上を占めます。これは4年前の3倍であり、この数は時間の経過とともに増加します。
ゲーマーは、ゲームのロード時間を短縮するためにSSDにますます注目しています。ハードドライブは50〜100MB /秒の帯域幅に制限されていますが、最新のM.2 PCIe Gen4SSDは最大7GB /秒でデータを読み取ります。
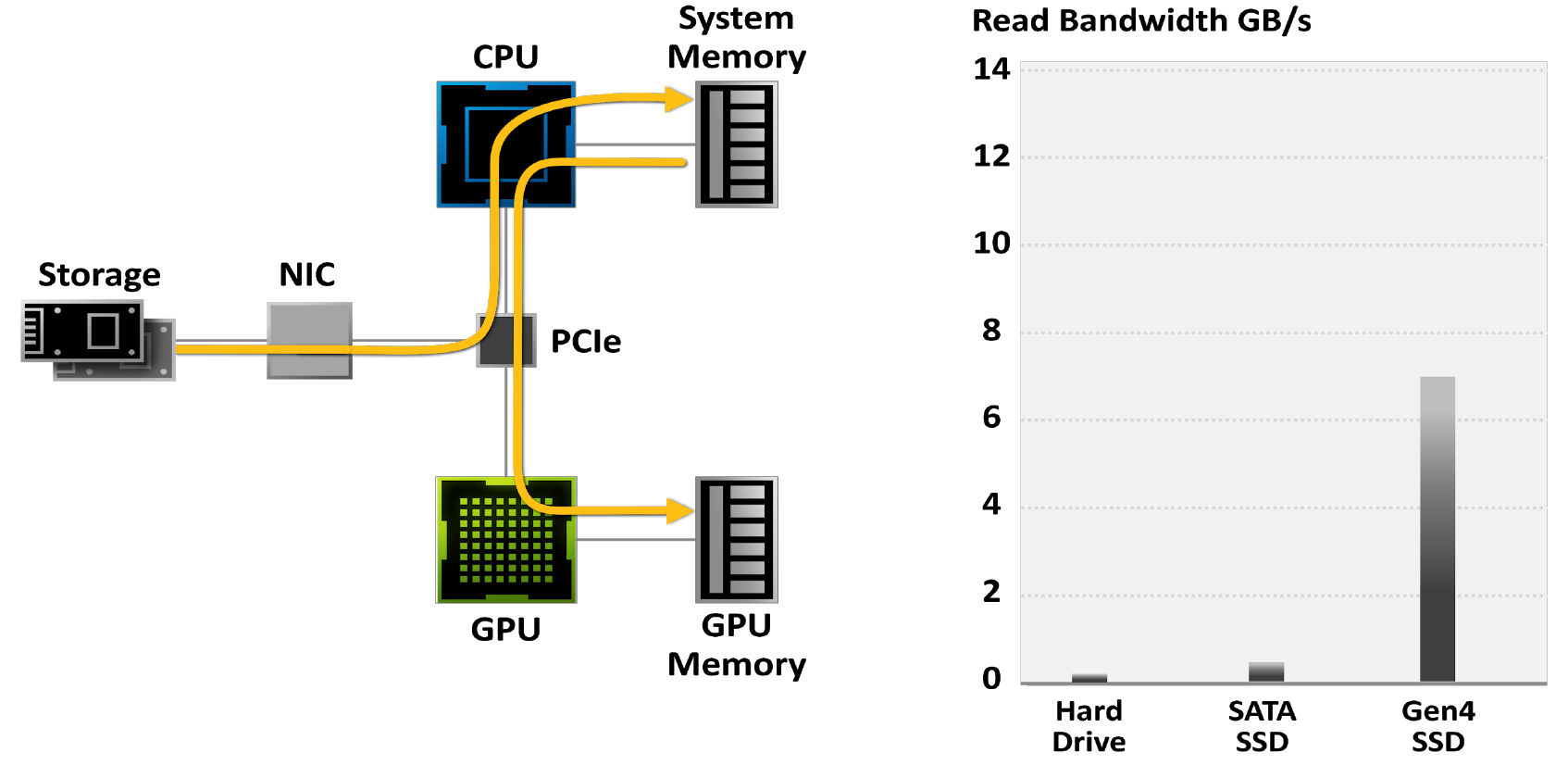
図18.従来のI / Oシステムによって制限されるゲーム

図19.従来のストレージモデルを使用すると、ゲームの解凍には24個のプロセッサコアすべてが必要になります。最新のゲームエンジンは、従来のストレージAPIの機能を上回っています。これが、新世代のI / Oアーキテクチャが必要な理由です。ここで、灰色のバーはデータ転送速度、黒と青のブロック、つまりこれに必要なCPUコアを示しています。
NVIDIA RTX IOは、GPUベースのアセットの高速ロードとアンパックを提供し、ハードドライブや従来のストレージAPIよりも最大100倍高速なI / Oパフォーマンスを提供する一連のテクノロジーです。
NVIDIA RTX IOは、今日のNVMeSSDゲーミングPC用に特別に設計された次世代ストレージであるMicrosoftDirectStorageAPIを搭載しています。NVIDIA RTX IOは損失のない解凍を提供し、データをDirectStorageを介して圧縮形式で読み取り、GPUに配信できるようにします。これにより、データをより効率的な圧縮形式でストレージからGPUに移動し、I / Oパフォーマンスを2倍にすることで、CPUの負荷を軽減します。

図20.RTX IOは、100倍の帯域幅と20倍のCPU使用率を提供します。灰色と緑色のバーはボーレートを示し、このCPUコアには黒色と青色のブロックが必要です。
ディスプレイおよびビデオエンジン
DisplayPort1.4aとDSC1.2a
より高い解像度とより高いフレームレートへの道のりは続いており、NVIDIA Ampere GPUは、両方を提供するために業界の最前線にとどまるよう努めています。ゲーマーは、120Hzの4K(3820 x 2160)ディスプレイと60Hzの8K(7680 x 4320)でプレイできるようになりました。これは4Kのピクセル数の4倍です。
Ampere Architecture Engineは、現在利用可能な最速のディスプレイインターフェイスに含まれる多くの新しいテクノロジーをサポートするように設計されています。これには、VESAディスプレイストリーム圧縮(DSC)1.2aで8K @ 60Hzを提供するDisplayPort1.4aが含まれます。新しいAmpereGPUは、ディスプレイごとに1本のケーブルで2つの8K60Hzディスプレイに接続できます。
DSP1.2とDSC1.2a
NVIDIA Ampereアーキテクチャは、ディスクリートGPUで初めて、HDMI仕様の最新アップデートであるHDMI2.1のサポートを追加します。HDMIは最大帯域幅を48Gbpsに増やしました。これにより、動的HDRフォーマットも可能になります。HDRで8K @ 60Hzをサポートするには、DSC 1.2a圧縮または4:2:0ピクセル形式が必要です。
第5世代NVDEC-ハードウェアアクセラレーションビデオデコード
NVIDIA GPUには、さまざまな一般的なコーデックに完全なハードウェアビデオデコードを提供する第5世代ハードウェアアクセラレーションビデオデコード(NVDEC)が含まれています。

図21.GA10x
GPUでサポートされるビデオのエンコードおよびデコード形式GA10xの第5世代NVIDIAデコーダーは、WindowsおよびLinuxプラットフォームで次のビデオコーデックのハードウェアアクセラレーションデコードをサポートします:MPEG-2、VC-1、H.264(AVCHD)、H.265 (HEVC)、VP8、VP9、およびAV1。
NVIDIAは、AV1デコードのハードウェアサポートを提供する最初のGPUメーカーです。
AV1ハードウェアデコード
AV1はビデオの圧縮に非常に効率的ですが、デコードには計算量が多くなります。最新のソフトウェアデコーダーはCPU使用率が高く、超高精細ビデオの再生を困難にします。NVIDIAテストでは、Intel i99900Kプロセッサは8K60HDRでYouTubeで平均28フレーム/秒で、CPU使用率は85%を超えていました。GA10x GPUは、デコードをNVDECに渡すことでAV1を再生できます。これは、非常に低いCPU使用率(前のテストと同じCPUで最大4%)で最大8K60のHDRコンテンツを再生できます。
第7世代NVENC-ハードウェアアクセラレーションビデオエンコーディング
ビデオエンコーディングは複雑な計算タスクになる可能性がありますが、NVENCにアップロードすると、グラフィックエンジンとCPUが他の操作のために解放されます。たとえば、Open Broadcaster Software(OBS)を使用してTwitch.tvにゲームをストリーミングする場合、ビデオエンコーディングをNVENCにオフロードすると、ゲームのレンダリングにGPUのグラフィックエンジンが割り当てられ、他のユーザータスクにCPUが割り当てられます。
NVENCは以下を許可します:
- CPUを使用しない高品質の超低遅延エンコーディングとゲームおよびアプリケーションのストリーミング。
- アーカイブ、OTTストリーミング、Webビデオ用の非常に高品質のエンコーディング。
- ストリームごとの超低電力エンコーディング(W /ストリーム)。
TwitchとYouTubeの共有ストリーミング設定により、GA10x GPUでのNVENCベースのハードウェアエンコーディングは、Fastプリセットを使用したx264ソフトウェアエンコーダーよりも優れており、通常2台のコンピューターの能力を必要とするプリセットであるx264Mediumと同等です。これにより、CPU使用率が大幅に削減されます。4Kエンコーディングは、一般的なCPU構成には負担が大きすぎますが、GA10x NVENCエンコーダーは、H.264では最大4K、HEVCでは最大8Kのシームレスな高解像度エンコーディングを提供します。
結論
NVIDIAは、新しいプロセッサアーキテクチャごとに、画質を向上させる新機能を導入しながら、次世代に革新的なパフォーマンスを提供するよう努めています。 Turingは、ハードウェアで高速化されたレイトレースを導入した最初のGPUでした。これは、かつてコンピュータグラフィックスの聖杯と見なされていた機能です。今日、信じられないほどリアルで物理的に正確なレイトレース効果が多くの新しいAAA PCゲームに追加されており、GPUで高速化されたレイトレースはほとんどのPCゲーマーにとって必須と見なされています。新しいNVIDIAGA10x Ampere GPUは、現在利用可能なフレームレートの最大2倍のフレームレートで、これらの新しいレイトレースゲームを楽しむために必要な機能とパフォーマンスを提供します。チューリングのもう1つの機能(ノイズキャンセル、レンダリング、その他のグラフィックアプリケーションを改善する改善されたCPUアクセラレーションAI処理)も、Ampereアーキテクチャのおかげで次のレベルに引き上げられます。
最後に、完全なドキュメントへのリンク。