
深層学習と強化学習を使用してスネークをプレイするニューラルネットワークについて話しましょう。Githubのコード、エラーの分析、AIのデモンストレーション、およびその実験がカットの下にあります。
AlphaGoに関するNetflixのドキュメンタリーを見て以来、私は強化学習に魅了されてきました。そのような学習は人間の学習に匹敵します:あなたは何かを見て、あなたは何かをし、そしてあなたの行動は結果をもたらします。良いまたは悪い。あなたは結果と正しい行動から学びます。強化学習には、自律運転、ロボット工学、取引、ゲームなど、多くの用途があります。強化学習に精通している場合は、次の2つのセクションをスキップしてください。
強化学習
原理は単純です。エージェントは、環境との相互作用を通じて学習します。彼は行動を選択し、状態(または観察)と報酬の形で環境から応答を受け取ります。このサイクルは、継続的に、または中断されるまで続きます。その後、新しいエピソードが始まります。概略的には次のようになります。

エージェントの目標は、エピソードごとに最大の報酬を獲得することです。トレーニングの開始時に、エージェントは環境を調べます。同じ状態でさまざまなアクションを試行します。学習が進むにつれて、エージェントはますます研究を減らします。代わりに、彼は自分の経験に基づいて最もやりがいのある行動を選択します。
深層強化学習
ディープラーニングは、ニューラルネットワークを使用して入力から出力を生成します。隠しレイヤーが1つしかないため、詳細な学習で任意の機能にズームインできます。使い方?ニューラルネットワークは、ノードを持つレイヤーです。最初のレイヤーは入力データレイヤーです。非表示の第2層は、重みとアクティブ化関数を使用してデータを変換します。最後のレイヤーは予測レイヤーです。

名前が示すように、深層強化学習は深層学習と強化学習の組み合わせです。エージェントは、入力としての状態、出力としてのアクションの値、および正しい方向に重みを調整するための報酬を使用して、特定の状態に最適なアクションを予測することを学習します。深層強化学習を使ってスネークを書いてみましょう。

アクション、報酬、条件の定義
エージェントのためにゲームを準備するために、問題を形式化します。アクションの定義は簡単です。エージェントは、上、右、下、または左の方向を選択できます。報酬とスペースの状態はもう少し複雑です。多くの解決策があり、1つはうまく機能し、もう1つは悪くなります。そのうちの1つを以下に説明し、試してみましょう。
スネークがリンゴを手に取った場合、彼女の報酬は10ポイントです。スネークが死んだ場合、賞金から100ポイントを差し引きます。エージェントを助けるために、蛇がリンゴの近くを通過するときに1ポイントを追加し、蛇がリンゴから離れるときに1ポイントを減算します。
州には多くの選択肢があります。スネークとリンゴの座標、またはリンゴへの方向をとることができます。エージェントが生き残ることを学ぶために、障害物の場所、つまりスネークの壁と体を追加することが重要です。以下は、アクション、条件、および報酬の要約です。状態調整がパフォーマンスにどのように影響するかについては後で説明します。

環境とエージェントを作成する
Snakeプログラムにメソッドを追加することで、強化学習環境を作成します。方法は次のとおりです。
reset(self)、step(self, action)とget_state(self)。さらに、エージェントの各ステップで報酬を計算する必要があります。を見てくださいrun_game(self)。
エージェントはDeepQネットワークと連携して、最適なアクションを見つけます。以下のモデルパラメータ:
# epsilon sets the level of exploration and decreases over time
params['epsilon'] = 1
params['gamma'] = .95
params['batch_size'] = 500
params['epsilon_min'] = .01
params['epsilon_decay'] = .995
params['learning_rate'] = 0.00025
params['layer_sizes'] = [128, 128, 128]
コードを見ることに興味がある場合は、GitHubで見つけることができます。
エージェントはスネークを演じます
そして今、重要な質問です!エージェントは遊ぶことを学びますか?それが環境とどのように相互作用するかを見てみましょう。以下は最初のゲームです。エージェントは何も理解していません:

最初のリンゴ!しかし、それでもニューラルネットワークはそれが何をしているのかを知らないようです。

最初のリンゴを見つけます...そして後で壁にぶつかります。第14ゲームの始まり:

エージェントは学習します:リンゴへの彼の道は最短ではありませんが、彼はリンゴを見つけます。以下は30番目のゲームです。

わずか30ゲームの後、スネークはそれ自体との衝突を回避し、リンゴへの迅速な方法を見つけます。
宇宙で遊ぼう
状態空間を変更して、同等以上のパフォーマンスを実現できる場合があります。以下は可能なオプションです。
- 方向性なし:スネークが移動している方向をエージェントに伝えないでください。
- 座標付きの状態:リンゴの位置(上、右、下、および/または左)をリンゴ(x、y)とヘビ(x、y)の座標に置き換えます。座標値は0から1までのスケールです。
- 方向0または1の状態。
- 壁のみの状態:壁がある場合にのみ報告します。しかし、体がどこにあるかについてではありません:下、上、右または左。

以下は、さまざまな状態のパフォーマンスグラフです。
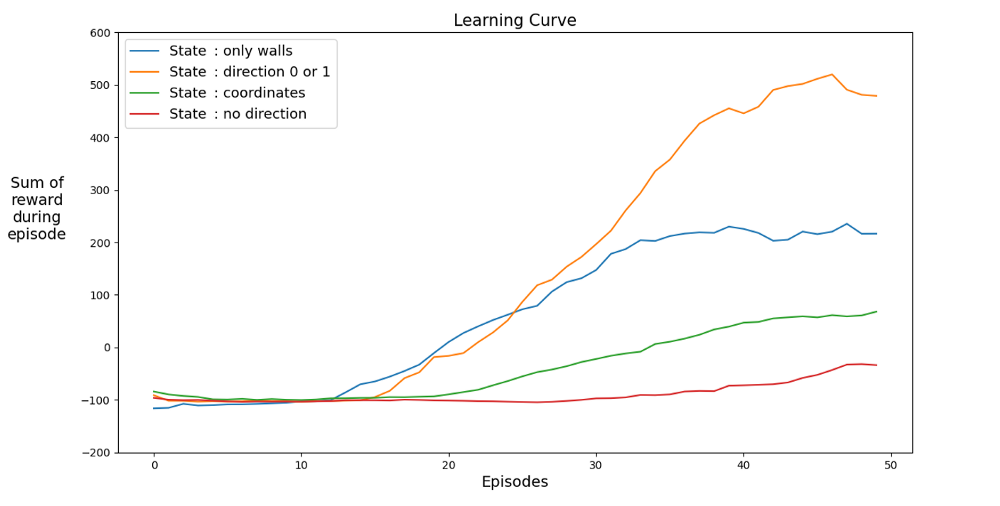
学習をスピードアップするスペースを見つけましょう。グラフは、さまざまな状態での過去12試合の平均成果を示しています。
状態空間に方向性がある場合、エージェントはすばやく学習し、最良の結果を達成することは明らかです。しかし、座標のあるスペースの方が優れています。たぶん、ネットワークをより長くトレーニングすることで、より良い結果を達成できるでしょう。学習が遅い理由は、考えられる状態の数である可能性があります:20⁴*2⁴* 4 = 1,024,000。20 x 20コース、64の障害物オプション、4つの現在の見出しオプション。元のバリアント空間の場合、3²*2⁴* 4 = 576。これは1,024,000の1700分の1であり、もちろん学習に影響します。
賞で遊びましょう
より良い内部報酬ロジックはありますか?スネークは次のように授与されることを思い出させてください。

最初の間違い。円を描く
ように歩く-1を+1に変更した場合はどうなりますか?これは学習曲線を遅くする可能性がありますが、最終的にはスネークは死にません。そして、これはゲームにとって非常に重要です。エージェントはすぐに死を避けることを学びます。

ある時間間隔で、エージェントは生存のために1ポイントを受け取ります。
2番目の間違い。壁にぶつかる
りんごを回るポイント数を-1に変えてみましょう。リンゴ自体の報酬を100ポイントに設定しましょう。何が起こるか?エージェントは移動ごとにペナルティを受け取るため、できるだけ早くリンゴに移動します。発生する可能性がありますが、別のオプションがあります。

AIは、損失を最小限に抑えるために最も近い壁に沿って歩きます。
経験
必要なのは30ゲームだけです。人工知能の秘密は、以前のゲームの経験にあります。これは、ニューラルネットワークがより速く学習するように考慮されています。通常の各ステップで、一連の再生ステップ(パラメーター
batch_size)が実行されます。アクションと状態の特定のペアについて、報酬と次の状態にほとんど違いがないため、これは非常にうまく機能します。
間違い番号3。経験なし経験は
本当に重要ですか?取り出しましょう。そして、リンゴの100ポイントの報酬を受け取ります。以下は、2500ゲームをプレイした経験のないエージェントです。

エージェントは2500(!)ゲームをプレイしましたが、ヘビはプレイしていません。ゲームはすぐに終了します。そうでなければ、10,000ゲームは数日かかったでしょう。 3000試合後、リンゴは3つしかありません。 10,000試合後、リンゴはまだ3です。それは運ですか、それとも学習成果ですか。
確かに、経験は大いに役立ちます。少なくとも報酬とスペースの種類を考慮に入れた経験。ステップごとに何回のリプレイが必要ですか?答えは驚きかもしれません。この質問に答えるために、batch_sizeパラメーターを試してみましょう。元の実験では、500に設定されていました。さまざまな経験による結果の概要:

経験の異なる200ゲーム:1ゲーム(経験なし)、2および4。20ゲームの平均。
2つのゲームの経験があっても、エージェントはすでにプレイを学んでいます。グラフでは、影響がわかります
batch_size。2ではなく4を使用すると、100ゲームで同じパフォーマンスが達成されます。記事のソリューションで結果が得られます。エージェントはスネークのプレイ方法を学び、50ゲームで40〜60個のリンゴを集めて良い結果を達成します。
注意深い読者は言うかもしれません:ヘビのリンゴの最大数は399です。なぜAIは勝てないのですか?実際、60と399の違いはわずかです。そして、これは本当です。そして、ここに問題があります:ヘビはループバックするときに衝突を避けません。
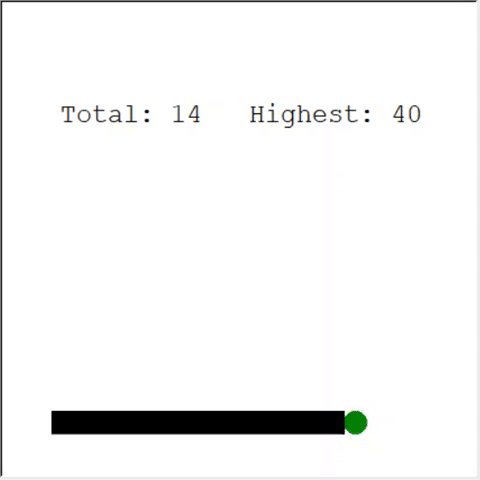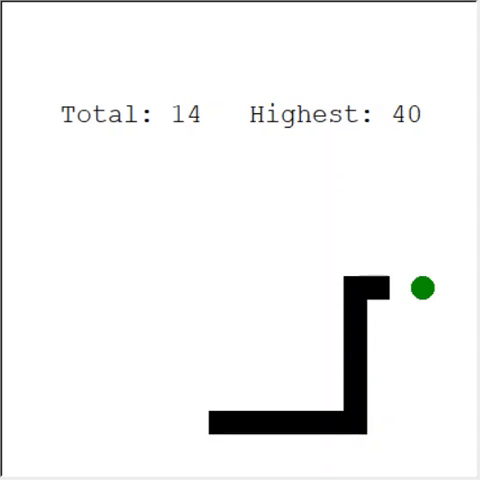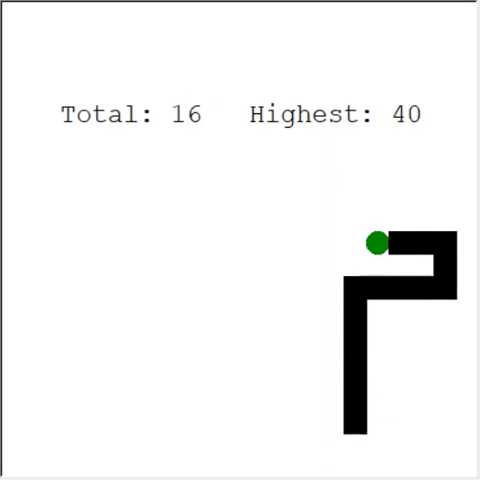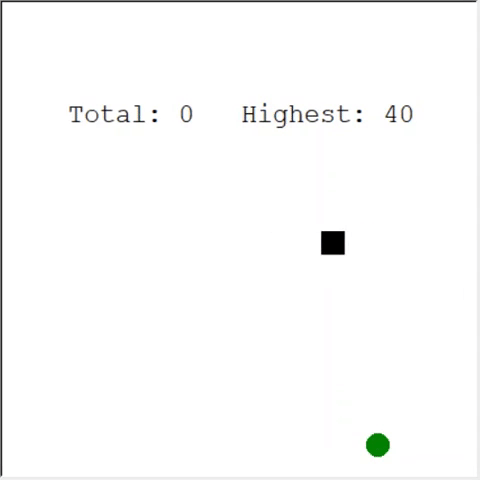
この問題を解決する興味深い方法は、CNNをプレイの分野に使用することです。このようにして、AIは近くの障害物だけでなく、ゲーム全体を見ることができます。彼は勝つために回る必要がある場所を認識することができるでしょう。
書誌
[1] K. Hornik, M. Stinchcombe, H. White, Multilayer feedforward networks are universal approximators (1989), Neural networks 2.5: 359–366
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
[2] Mnih et al, Playing Atari with Deep Reinforcement Learning (2013)
, Level Up , - SkillFactory:
- Machine Learning (12 )
- « Machine Learning Data Science» (20 )
- «Machine Learning Pro + Deep Learning» (20 )
- Data Science (12 )
E
- - (8 )
- - Data Analytics (5 )
- (6 )
- (18 )
- «Python -» (9 )
- DevOps (12 )
- Java- (18 )
- JavaScript (12 )
- UX- (9 )
- Web- (7 )
