(NLP) Deep Learning(DL)は、コンピューティング能力に対する需要が高い分野であるため、GPUの選択によって、この分野での経験が基本的に決まります。しかし、新しいGPUを購入する際に考慮すべき重要なプロパティは何ですか?メモリ、コア、テンソルコア?お金の価値の観点から最良の選択をする方法は?この記事では、これらすべての質問、よくある誤解を詳細に分析し、GPUを直感的に理解できるようにするとともに、正しい選択を行うためのヒントをいくつか紹介します。
この記事は、GPUについてのいくつかの異なるレベルの理解を提供するために書かれています。 NVIDIAの新しいAmpereシリーズ。選択肢があります:
- GPUの詳細、GPUを正確に高速化する理由、およびNVIDIA RTX 30 Ampereシリーズの新しいGPUの独自性に興味がない場合は、記事の冒頭をスキップして、速度と1ドルあたりの速度のグラフ、および推奨事項のセクションに進むことができます。これがこの記事の核心であり、最も価値のあるコンテンツです。
- 特定の質問に興味がある場合は、記事の最後の部分で最も頻繁に取り上げました。
- GPUとTensorCoreがどのように機能するかを深く理解する必要がある場合は、この記事を最初から最後まで読むことをお勧めします。特定の主題に関する知識に応じて、1〜2章をスキップできます。
各セクションの前には、全体を読むかどうかを判断するのに役立つ短い要約があります。
コンテンツ
GPU?
GPU,
/ L1 /
Ampere
Ampere
Ampere
Ampere / RTX 30
GPU
GPU
GPU
11 ?
11 ?
GPU-
GPU
GPU?
PCIe 4.0?
PCIe 8x/16x?
RTX 3090, 3 PCIe?
4 RTX 3090 4 RTX 3080?
GPU ?
NVLink, ?
. ?
?
?
Intel GPU?
?
AMD GPU + ROCm - NVIDIA GPU + CUDA?
, – GPU?
,
この記事は次のように構成されています。まず、GPUを高速化する理由を説明します。プロセッサとGPUの違い、テンソルコア、メモリ帯域幅、GPUメモリ階層、およびそれらすべてがGOタスクのパフォーマンスにどのように関連するかについて説明します。これらの説明は、必要なGPUパラメーターをよりよく理解するのに役立つ場合があります。次に、GPUパフォーマンスの理論的推定値と、バイアスのない信頼性の高いパフォーマンスデータを取得するための、いくつかのNVIDIA速度テストとの対応について説明します。購入時に考慮すべきNVIDIARTX 30AmpereシリーズGPUの独自の機能について説明します。次に、1〜2チップ、4、8、およびGPUクラスターのGPUに関する推奨事項を示します。次に、Twitterで尋ねられたよくある質問への回答のセクションがあります。また、一般的な誤解を払拭し、クラウドとデスクトップ、冷却、AMDとNVIDIAなどのさまざまな問題を浮き彫りにします。
GPUはどのように機能しますか?
GPUを頻繁に使用する場合は、GPUがどのように機能するかを理解しておくと役立ちます。この知識は、GPUが遅い場合と速い場合がある理由を理解するのに役立ちます。そして、GPUが必要かどうか、そして将来どのハードウェアオプションがGPUと競合できるかを理解できます。特定のGPUを選択するための有用なパフォーマンス情報と引数が必要な場合は、このセクションをスキップできます。GPUがどのように機能するかについての最も一般的な説明は、Quoraの回答にあります。
これは一般的な説明であり、GPUがプロセッサよりもGOに適している理由の問題をよく説明しています。詳細を調べると、GPUの違いがわかります。
処理速度に影響を与える最も重要なGPU特性
このセクションは、GOの分野でのパフォーマンスについてより直感的に考えるのに役立ちます。この理解は、将来のGPUを自分で評価するのに役立ちます。
テンソルコア
概要:
- テンソルカーネルは、乗算と加算をカウントするために必要なクロックサイクル数を16倍削減します。私の例では、32×32マトリックスの場合は128から8クロックサイクルになります。
- テンソルカーネルは、メモリアクセスサイクルを節約することにより、共有メモリへの繰り返しアクセスへの依存を減らします。
- テンソルカーネルは非常に高速であるため、計算はもはやボトルネックではありません。唯一のボトルネックは、それらへのデータの転送です。
今日、安価なGPUが非常に多いため、ほとんどの人がテンソルコアを備えたGPUを購入できます。したがって、私は常にTensorCoreを備えたGPUをお勧めします。マトリックス乗算に特化したこれらの計算モジュールの重要性を理解するには、それらがどのように機能するかを理解することが役立ちます。すべての行列のサイズが32×32である行列乗算A * B = Cの簡単な例を使用して、テンソルカーネルがある場合とない場合の乗算がどのように見えるかを示します。
これを理解するには、最初にバーの概念を理解する必要があります。プロセッサは1 GHzで動作している場合、それは10を行い91秒あたりのティック数。各クロックは計算の機会です。ただし、ほとんどの場合、操作には1クロックサイクルより長い時間がかかります。パイプラインが判明しました。1つの操作の実行を開始するには、最初に、前の操作を完了するために必要な数のクロックサイクルを待機する必要があります。これは、遅延操作とも呼ばれます。
操作の重要な期間または遅延をティック単位で次に示します。
- 最大48GBのグローバルメモリへのアクセス:〜200クロックサイクル。
- 共有メモリアクセス(ストリーミングマルチプロセッサあたり最大164 KB):〜20クロック。
- 複合乗算-加算(SUS):4小節。
- テンソルカーネルでのマトリックス乗算:1クロックサイクル。
また、GPUのスレッドの最小単位(32スレッドのパケット)はワープと呼ばれることを知っておく必要があります。ワープは通常同期して機能します。ワープ内のすべてのスレッドは互いに待機する必要があります。すべてのGPUメモリ操作はワープ用に最適化されています。たとえば、グローバルメモリからのロードには、32 * 4バイト-32個の浮動小数点数が必要です。ワープ内のスレッドごとに1つのそのような数です。ストリーミングマルチプロセッサ(GPUのプロセッサコアに相当)では、最大32のワープ= 1024スレッドが存在する可能性があります。マルチプロセッサリソースは、すべてのアクティブなワープ間で共有されます。したがって、1つのワープに多くのレジスタ、共有メモリ、およびテンソルコアリソースが含まれるように、動作に必要なワープが少なくなる場合があります。
両方の例で、同じコンピューティングリソースがあると仮定しましょう。この32×32マトリックス乗算の小さな例では、8つのマルチプロセッサ(RTX 3090の約10%)とマルチプロセッサで8つのワープを使用します。
テンソルカーネルを使用しないマトリックス乗算
それぞれが32×32のサイズの行列A * B = Cを乗算する必要がある場合、アクセス遅延は約10分の1であるため、常にアクセスしているメモリから共有メモリにデータをロードする必要があります( 200バー、および20バー)。共有メモリ内のメモリのブロックは、多くの場合、メモリタイル、または単にタイルと呼ばれます。 2つの32x32フローティングポイント番号を共有メモリタイルにロードするには、2 * 32ワープを使用して並行して実行できます。それぞれ8つのワープを持つ8つのマルチプロセッサがあるため、並列化のおかげで、グローバルメモリから共有メモリへの1つのシーケンシャルロードを実行する必要があります。これには200クロックサイクルかかります。
行列を乗算するには、共有メモリAと共有メモリBから32個の数値のベクトルをロードし、CMSを実行してから、出力をレジスタCに格納する必要があります。各マルチプロセッサが8つのスカラー積(32×32)を処理するように、この作業を分割します。 )Cの8つの出力データを計算します。なぜそれらが正確に8つあるのか(古いアルゴリズムでは-4)、これは純粋に技術的な機能です。それを理解するには、ScottGrayの記事を読むことをお勧めします。これは、共有メモリへのアクセスが8回あり、それぞれ20サイクルのコストがかかり、8回のSLS操作(32並列)がそれぞれ4サイクルのコストになることを意味します。合計で、コストは次のようになります
。200ティック(グローバルメモリ)+ 8 * 20ティック(共有メモリ)+ 8 * 4ティック(CMS)= 392ティック次に
、テンソルコアのこのコストを見てみましょう。
テンソルカーネルによるマトリックス乗算
テンソルカーネルを使用すると、1サイクルで4×4の行列を乗算できます。これを行うには、メモリをテンソルコアにコピーする必要があります。上記のように、グローバルメモリ(200ティック)からデータを読み取り、共有メモリに保存する必要があります。32×32の行列を乗算するには、テンソルカーネルで8×8 = 64の操作を実行する必要があります。1つのマルチプロセッサには8つのテンソルコアが含まれています。8つのマルチプロセッサで、64のテンソルコアがあります-必要な数だけです!共有メモリからテンソルコアに1回の転送(20クロックサイクル)でデータを転送し、これら64の操作すべてを並行して(1クロックサイクル)実行できます。これは、テンソルコアでのマトリックス乗算の総コストが次のようになることを意味します:
200クロックサイクル(グローバルメモリ)+ 20クロックサイクル(共有メモリ)+ 1クロックサイクル(テンソルコア)= 221クロックサイクル
したがって、テンソルカーネルを使用すると、マトリックス乗算のコストを392から221クロックサイクルに大幅に削減できます。簡略化した例では、テンソルカーネルによって共有メモリアクセスとSNS操作の両方のコストが削減されました。
この例は、テンソルカーネルがある場合とない場合の一連の計算ステップに大まかに従いますが、これは非常に単純化された例であることに注意してください。実際の場合、マトリックスの乗算には、大きなメモリタイルと、わずかに異なる一連のアクションが含まれます。
ただし、この例では、次の属性であるメモリ帯域幅がテンソルコアを備えたGPUにとって非常に重要である理由が明らかになっているように思われます。マトリックスにテンソルコアを乗算する場合、グローバルメモリは最も高価なものであるため、グローバルメモリへのアクセスの待ち時間を短縮できれば、GPUははるかに高速になります。これは、メモリクロック速度を上げる(1秒あたりのクロックサイクルを増やすが、熱と電力の消費量を増やす)か、一度に転送できる要素の数(バス幅)を増やすことによって実行できます。
メモリ帯域幅
前のセクションでは、テンソルカーネルの速度について説明しました。それらは非常に高速であるため、ほとんどの時間アイドル状態になり、グローバルメモリからのデータが到着するのを待ちます。たとえば、非常に大きなマトリックスが使用されたBERT Largeプロジェクトのトレーニング中(テンソルカーネルの場合は大きいほど良い)、TFLOPSでのテンソルカーネルの使用率は約30%でした。これは、テンソルカーネルがアイドル状態であった時間の70%を意味します。
これは、2つのGPUをテンソルコアと比較する場合、それぞれの最高のパフォーマンス指標の1つがメモリ帯域幅であることを意味します。たとえば、A100GPUの帯域幅は1.555GB / sですが、V100の帯域幅は900 GB / sです。簡単な計算によると、A100はV100よりも1555/900 = 1.73倍高速になります。
共有メモリ/ L1キャッシュ/レジスタ
速度制限要因はテンソルコアのメモリへのデータの転送であるため、GPUの他のプロパティに目を向ける必要があります。これにより、それらへのデータの転送を高速化できます。これに関連するのは、共有メモリ、L1キャッシュ、およびレジスタの数です。メモリ階層がデータ転送をどのように高速化するかを理解するには、GPUでマトリックスがどのように乗算されるかを理解することが役立ちます。
マトリックス乗算では、低速のグローバルメモリから高速のローカル共有メモリ、そして超高速レジスタへと進むメモリ階層を使用します。ただし、メモリが高速であるほど、メモリは小さくなります。したがって、マトリックスを小さなものに分割してから、ローカル共有メモリでこれらの小さなタイルを乗算する必要があります。そうすれば、それはストリーミングマルチプロセッサ(PM)にすばやく近くなります。これはプロセッサコアに相当します。テンソルコアを使用すると、もう1つのステップを実行できます。すべてのタイルを取得し、それらの一部をテンソルコアにロードします。共有メモリはマトリックスタイルをグローバルGPUメモリよりも10〜50倍速く処理し、テンソルコアレジスタはそれをグローバルGPUメモリよりも200倍速く処理します。
タイルのサイズを大きくすると、より多くのメモリを再利用できます。これについては、私の記事TPU vsGPUで詳しく説明しました。TPUでは、テンソルコアごとに非常に大きなタイルがあります。TPUは、グローバルメモリからの新しい転送ごとに、より多くのメモリを再利用できるため、GPUよりもマトリックス乗算の処理がわずかに効率的になります。
タイルサイズは、各PMのメモリ量によって決まります。これはGPUのプロセッサコアに相当します。アーキテクチャに応じて、これらのボリュームは次のとおりです。
- ボルタ:96KB共有メモリ/ 32KB L1
- チューリング:64KB共有メモリ/ 32KB L1
- アンペア:164KB共有メモリ/ 32KB L1
Ampereにははるかに多くの共有メモリがあることがわかります。これにより、より大きなタイルを使用できるようになり、グローバルメモリアクセスの数が減ります。したがって、AmpereはGPUメモリ帯域幅をより効率的に使用します。これにより、パフォーマンスが2〜5%向上します。この増加は、巨大なマトリックスで特に顕著です。
アンペアテンソルカーネルには別の利点があります。複数のスレッドに共通する大量のデータがあります。これにより、レジスタ呼び出しの数が減ります。レジスタのサイズは、PMあたり64 k、またはスレッドあたり255に制限されています。 Voltaと比較して、Ampere Tensor Coreは3分の1のレジスタを使用するため、共有メモリ内のタイルごとにより多くのアクティブなTensorCoreがあります。つまり、同じ数のレジスタで3倍のテンソルコアをロードできます。ただし、帯域幅は依然としてボトルネックであるため、実際のTFLOPSの増加は、理論値と比較してごくわずかです。新しいテンソルカーネルにより、パフォーマンスが約1〜3%向上しました。
全体として、Ampereアーキテクチャは、グローバルメモリから共有メモリタイル、テンソルコアレジスタまで、改善された階層を通じてメモリ帯域幅をより効率的に使用するように最適化されていることがわかります。
GOにおけるAmpereの有効性の評価
概要:
- Ampere GPUのメモリ帯域幅と改善されたメモリ階層に基づく理論上の推定では、1.78〜1.87倍の加速が予測されます。
- NVIDIAは、TeslaA100およびV100GPUの速度測定に関するデータをリリースしました。彼らはよりマーケティング的ですが、偏りのないモデルはそれらに基づいて構築することができます。
- 偏りのないモデルは、V100と比較して、Tesla A100は自然言語処理で1.7倍、コンピュータービジョンで1.45倍高速であることを示唆しています。
このセクションは、AmpereGPUのパフォーマンススコアを取得する方法の技術的な詳細を詳しく調べたい方を対象としています。興味がない場合は、スキップしても問題ありません。
理論上の速度の推定
上記の議論を考えると、テンソルコアを備えた2つのGPUアーキテクチャの違いは、主にメモリ帯域幅にあるはずです。追加の利点は、共有メモリとL1キャッシュの増加、およびレジスタの効率的な使用から得られます。
Tesla A100 GPUの帯域幅は、TeslaV100と比較して1555/900 = 1.73倍に増加しています。また、総メモリが大きいために速度が2〜5%向上し、テンソルコアが改善されたために1〜3%向上すると予想するのも妥当です。加速は1.78から1.87倍でなければならないことがわかります。
Ampere
Ampere、Turing、VoltaなどのアーキテクチャのGPUスコアが1つあるとします。これらの結果を同じアーキテクチャまたはシリーズの他のGPUに外挿するのは簡単です。幸い、NVIDIAは、コンピューターのビジョンと自然な言語の理解に関連するさまざまなタスクについて、A100とV100を比較するベンチマークをすでに実施しています。残念ながら、NVIDIAは、これらの数値を直接比較できないように可能な限りのことを行っています。テストでは、異なるデータパケットサイズと異なる数のGPUを使用したため、A100は勝てませんでした。したがって、ある意味で、得られたパフォーマンス指標は、一部は正直で、一部は宣伝です。一般に、A100のメモリが多いため、データパケットサイズの増加は正当化されると主張できますが、GPUアーキテクチャを比較するには、同じデータパケットサイズのタスクで偏りのないパフォーマンスデータを比較する必要があります。
偏りのない見積もりを取得するには、2つの方法でV100とA100の測定値をスケーリングできます。データパケットサイズの違いを考慮するか、GPUの数の違い(1と8)を考慮します。幸運なことに、NVIDIAが提供するデータで、両方のケースで同様の見積もりを見つけることができます。
パケットサイズを2倍にすると、スループットが1秒あたりの画像数で13.6%増加します(畳み込みニューラルネットワーク、CNNの場合)。 RTX TitanのTransformerアーキテクチャを使用して同じタスクの速度を測定したところ、驚くべきことに、同じ結果(13.5%)が得られました。これは信頼できる見積もりのようです。
ネットワークの並列化を増やし、GPUの数を増やすと、ネットワークに関連するオーバーヘッドのためにパフォーマンスが低下します。ただし、A100 8x GPUは、V100 8x GPU(NVLink 2.0)と比較してネットワーキング(NVLink 3.0)でのパフォーマンスが優れています。これも混乱を招く要因です。 NVIDIAからのデータを見ると、SNSを処理するために、8番目のA100を備えたシステムのオーバーヘッドが8番目のV10000を備えたシステムよりも5%少ないことがわかります。つまり、1番目のA10000から8番目のA10000への遷移で7.0倍の加速が得られた場合、1番目のV10000から8番目のV10000への遷移では6.67倍の加速しか得られません。変圧器の場合、この数値は7%です。
この情報を使用して、NVIDIAから提供されたデータから、特定のGOアーキテクチャの加速を直接見積もることができます。Tesla A100には、TeslaV100に比べて次の速度上の利点があります。
- SE-ResNeXt101:1.43回。
- Masked-R-CNN:1.47回。
- トランスフォーマー(12層、機械変換、WMT14 en-de):1.70回。
したがって、コンピュータビジョンの場合、数値は理論上の推定値を下回って取得されます。これは、テンソル測定値が小さいこと、img2colやFFTなどの行列乗算を準備するために必要な操作のオーバーヘッド、またはGPUを飽和させることができない操作(結果のレイヤーが比較的小さいことが多い)が原因である可能性があります。また、特定のアーキテクチャ(グループ化された畳み込み)のアーティファクトである可能性もあります。
変圧器の速度の実際的な評価は、理論的な評価に非常に近いものです。おそらく、大きな行列を操作するためのアルゴリズムが非常に単純だからです。GPUの費用対効果を計算するために、実際の見積もりを使用します。
見積もりの不正確さの可能性
上記はA100とV100の比較評価です。これまで、NVIDIAは「ゲーム」RTX GPUのパフォーマンスを密かに低下させていました。テンソルコアの使用率が低下し、冷却用のゲームファンが追加され、GPU間のデータ転送が禁止されていました。RT30シリーズもAmpereA100に対して未知の障害を引き起こした可能性があります。
Ampere / RTX30の場合に他に考慮すべきこと
概要:
- Ampereを使用すると、スパースマトリックスに基づいてネットワークをトレーニングできます。これにより、トレーニングプロセスが最大2倍高速化されます。
- スパースネットワークトレーニングはまだめったに使用されませんが、そのおかげで、Ampereはすぐに時代遅れになることはありません。
- Ampereには、低精度の使用をはるかに容易にする新しい低精度データタイプがありますが、必ずしも以前のGPUよりも速度が向上するとは限りません。
- 新しいファンの設計は、GPU間に空きスペースがある場合に適していますが、互いに近くに立っているGPUが効果的に冷却されるかどうかは明らかではありません。
- RTX 3090の3スロット設計は、4つのGPUビルドにとって課題となります。考えられる解決策は、2スロットオプションまたはPCIeエクスパンダを使用することです。
- 4つのRTX3090は、市場に出回っている標準のPSUが提供できるよりも多くの電力を必要とします。
新しいNVIDIAAmpere RTX 30には、NVIDIA Turing RTX 20に比べて追加の利点があります。つまり、スパーストレーニングとニューラルネットワークによるデータ処理の改善です。新しいデータタイプなどの残りのプロパティは、単純な利便性の向上と見なすことができます。追加のプログラミングを必要とせずに、Turingシリーズと同じ方法で処理を高速化します。
スパースラーニング
Ampereを使用すると、スパースマトリックスを高速かつ自動的に乗算できます。これは次のように機能します。マトリックスを取得して4つの要素に分割すると、スパースマトリックスをサポートするテンソルカーネルにより、これら4つの要素のうち2つをゼロにすることができます。これにより、マトリックス乗算中の帯域幅要件が半分になるため、2倍の速度向上が実現します。
私の研究では、まばらな学習ネットワークを使用してきました。特に、「ネットワークに必要なFLOPSを減らしますが、GPUはスパース行列をすばやく乗算できないため、速度を上げない」という事実について、この作業は批判されました。まあ-スパースマトリックス乗算のサポートは、テンソルカーネル、私のアルゴリズム、または他のアルゴリズム(リンク、link、link、link)は、スパースマトリックスを操作するため、トレーニング中に実際に2倍の速度で動作できるようになりました。
このプロパティは現在実験的なものと見なされており、スパースネットワークトレーニングは普遍的に適用されていませんが、GPUがこのテクノロジーをサポートしている場合は、スパーストレーニングの将来に備えることができます。
低精度の計算
新しいデータタイプが私の仕事で忠実度の低い逆伝播の安定性をどのように改善できるか をすでに示しました。これまでのところ、16ビットの浮動小数点数を使用した安定した逆伝播の問題は、通常のデータタイプがスパン[-65,504、65,504]のみをサポートすることです。勾配がこのギャップを超えると、爆発してNaN値が生成されます。これを防ぐために、通常、逆伝播する前に値に小さな数を掛けて値をスケーリングし、勾配の爆発を回避します。
Brain Float 16(BF16)形式は指数に多くのビットを使用するため、可能な値の範囲はFP32と同じです:[-3 * 10 ^ 38、3 * 10 ^ 38]。 BF16の精度は低くなります。重要な桁数は少なくなりますが、ネットワークをトレーニングするときの勾配の精度はそれほど重要ではありません。したがって、BF16を使用すると、スケーリングを行ったり、勾配の爆発を心配したりする必要がなくなります。この形式では、精度がわずかに低下しますが、トレーニングの安定性が向上するはずです。
これが意味すること:BF16の精度はFP16の精度よりも一貫している可能性がありますが、速度は同じです。TF32の精度により、ほぼFP32のような安定性と、ほぼFP16のような加速が得られます。さらに、これらのデータタイプを使用すると、コードを何も変更せずに、FP32をTF32に、FP16をBF16に変更できます。
一般に、これらの新しいデータタイプは、古いデータタイプと少しのプログラミング(正しくスケーリング、初期化、正規化、Apexを使用)を使用してすべての利点を得ることができるという意味で、怠惰と見なすことができます。したがって、これらのデータタイプは加速を提供しませんが、トレーニングで忠実度の低いものを使用しやすくします。
新しいファンの設計と熱放散の問題
RTX 30シリーズの新しいファン設計には、エアブローファンとエアプルファンがあります。デザイン自体は独創的で、GPU間に空きスペースがある場合は非常に効率的に機能します。ただし、GPUが相互に強制された場合にGPUがどのように動作するかは明確ではありません。ブローファンは他のGPUから空気を吹き飛ばすことができますが、その形状が以前とは異なるため、これがどのように機能するかを判断することはできません。 4つのスロットがある場所に1つまたは2つのGPUを配置することを計画している場合は、問題はないはずです。ただし、3〜4個のRTX 30 GPUを並べて使用する場合は、最初に温度条件に関するレポートを待ってから、ファン、PCIeエキスパンダー、またはその他のソリューションがさらに必要かどうかを判断しました。
いずれにせよ、水冷はヒートシンクの問題を解決するのに役立ちます。多くのメーカーがRTX3080 / RTX 3090カードにこのようなソリューションを提供しているため、4枚でも暖かくなりません。ただし、4つのGPUを搭載したコンピューターを構築する場合は、ほとんどの場合非常に難しいため、既製のGPUソリューションを購入しないでください。ラジエーターを配布します。
冷却の問題に対する別の解決策は、PCIeエキスパンダーを購入し、ケース内にカードを配布することです。これは非常に効果的です-私とバニントン大学の他の大学院生はこのオプションを使用して大成功を収めています。見た目はあまり良くありませんが、GPUは熱くなりません!また、このオプションは、GPUを収容するのに十分なスペースがない場合に役立ちます。ケースに余裕がある場合は、たとえば、3つのスロットを備えた標準のRTX 3090を購入し、エクスパンダーを使用してケース全体に配布できます。したがって、4つのRTX3090のスペースと冷却の問題を同時に解決することが可能

です。1:PCIeエキスパンダーを備えた4 GPU
3スロットカードと電源の問題
RTX 3090は3つのスロットを占有するため、NVIDIAのデフォルトのファンでそれぞれ4つ使用することはできません。 350WのTDPが必要なため、これは驚くべきことではありません。 RTX 3080はわずかに劣っており、320WのTDPが必要であり、4つのRTX3080でシステムを冷却することは非常に困難です。
350W = 1400Wの4枚のカードでシステムに電力を供給することも困難です。 1600 Wの電源(PSU)がありますが、プロセッサとマザーボードには200Wでは不十分な場合があります。最大電力消費は全負荷でのみ発生し、HEの間、プロセッサは通常軽負荷です。したがって、1600WPSUは4つのRTX3080に適している可能性がありますが、4つのRTX 3090には、1700W以上のPSUを探すことをお勧めします。現在、そのようなPSUは市場に出回っていません。サーバーPSUまたはクリプトマイナー用の特別なブロックが機能する場合がありますが、それらには異常なフォームファクターがある場合があります。
深層学習におけるGPU効率
次のテストには、TeslaA100とTeslaV100の比較だけでなく、このデータに適合するモデルを作成し、Titan V、Titan RTX、RTX 2080 Ti、RTX 2080をテストした4つの異なるテスト(リンク、リンク、リンク、リンク)を作成しました。
また、テストデータポイントを補間することにより、RTX 2070、RTX 2060、QuadroRTXなどのミッドレンジカードのベンチマーク結果をスケーリングしました。通常、GPUアーキテクチャでは、このようなデータは、マトリックスの乗算とメモリ帯域幅に関して線形にスケーリングされます。
FP32番号を使用したトレーニングを使用する理由がないため、混合精度のFP16トレーニングテストからのみデータを収集しました。

図:図2:RTX 2080Tiによって正規化されたパフォーマンスRTX2080 Ti
と比較して、RTX 3090は、畳み込みネットワークでは1.57倍、トランスでは1.5倍高速で動作し、コストは15%高くなります。Ampere RTX 30は、Turing RTX20シリーズ以降大幅な改善を示していることがわかりました。
コストあたりのGPUディープラーニングレート
どのGPUがお金に見合う最高の価値でしょうか?それはすべて、システムの総コストに依存します。高価な場合は、より高価なGPUに投資するのが理にかなっています。
以下は、PCIe 3.0上の3つのアセンブリに関するデータです。これは、2つまたは4つのGPUを備えたシステムのコストのベースラインとして使用します。この基本コストを取得して、GPUコストを追加します。私は後者をAmazonとeBayからのオファー間の平均価格として計算します。新しいAmpereの場合、私は1つの価格のみを使用します。上記のパフォーマンスデータと合わせて、これは1ドルあたりのパフォーマンス値を示します。GPUが8つあるシステムの場合、RTXサーバーの業界標準としてSupermicroベアボーンを採用しています。表示されているグラフには、メモリ要件は含まれていません。最初に必要なメモリについて考え、次にグラフで最適なオプションを探す必要があります。メモリのヒントの例:
- 事前にトレーニングされたトランスフォーマーを使用するか、小さなトランスフォーマーを最初からトレーニングする> = 11GB。
- 研究または生産における大規模な変圧器または畳み込みネットワークのトレーニング:> = 24GB。
- ニューラルネットワークのプロトタイピング(トランスフォーマーまたはコンボリューションネットワーク)> = 10GB。
- Kaggleコンテストへの参加> = 8GB。
- コンピュータービジョン> = 10GB。
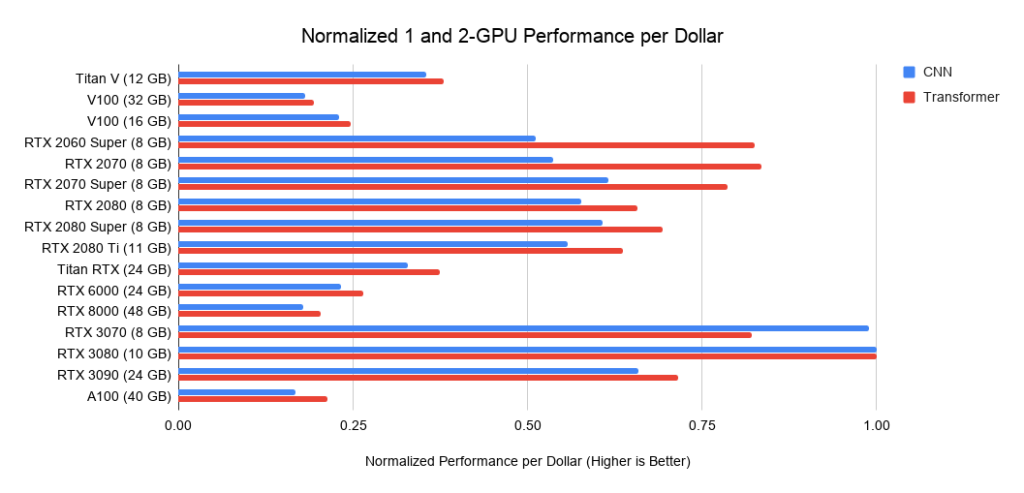
図:

図3:RTX3080に対する正規化されたドルのパフォーマンス。図4:RTX3080に対する正規化されたドルのパフォーマンス
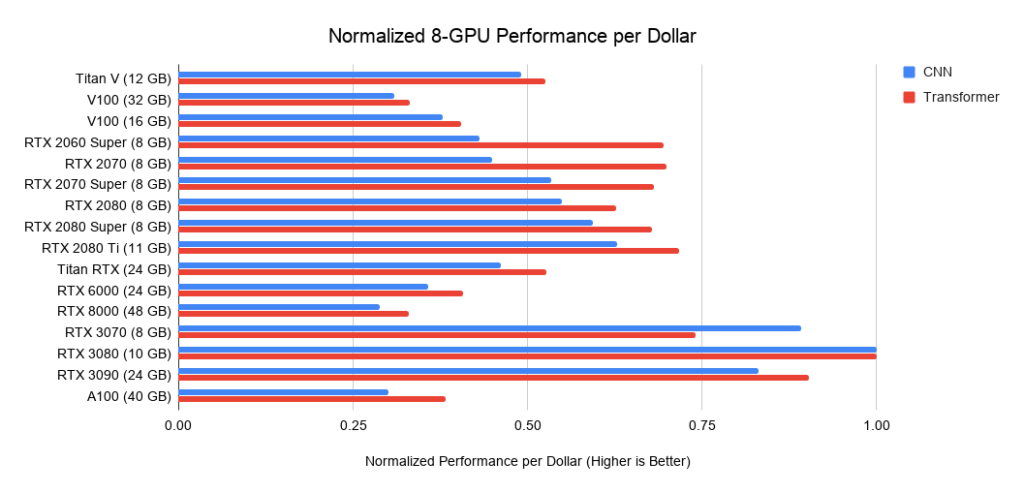
。5:RTX3080に対する正規化されたドルのパフォーマンス。
GPUの推奨事項
繰り返しになりますが、GPUを選択するときは、まず、タスクに十分なメモリがあることを確認してください。GPUを選択する手順は次のとおりです。
- , GPU: Kaggle, , , , - .
- , .
- GPU, .
- GPU - ? , RTX 3090, ? GPU? , GPU?
一部の手順では、必要なものについて考え、同じことをしている他の人が使用しているメモリの量について少し調査する必要があります。アドバイスはできますが、この分野のすべての質問に完全に答えることはできません。
11GBを超えるストレージが必要になるのはいつですか?
変圧器を使用する場合は少なくとも11GBが必要であり、この分野で研究を行う場合は少なくとも24GBが必要であることはすでに述べました。以前の事前トレーニング済みモデルのほとんどは、非常に高いメモリ要件があり、少なくとも11GBのメモリを備えたRTX2080Ti以上のGPUでトレーニングされています。したがって、メモリが11 GB未満の場合、一部のモデルの起動が困難になるか、不可能になる可能性があります。
大量のメモリを必要とする他の領域は、医療画像、高度なコンピュータビジョンモデル、およびすべて大きな画像です。
全体として、研究、産業用アプリケーション、Kaggleの競争など、競争をしのぐことができるモデルの開発を検討している場合は、メモリを追加することで競争力を高めることができます。
11 GB未満のメモリでいつ問題を解決できますか?
RTX3070およびRTX3080カードは強力ですが、メモリが不足しています。ただし、多くのタスクでは、その量のメモリは必要ない場合があります。
RTX 3070は、GOトレーニングに最適です。ほとんどのアーキテクチャの基本的なネットワーキングスキルは、ネットワークを縮小するか、より小さなイメージを使用することで習得できます。GOを学ぶ必要がある場合は、RTX 3070を選択します。余裕があれば、RTX3070を選択します。
RTX 3080は、今日最も費用効果の高いカードであるため、プロトタイピングに最適です。プロトタイピングには大量のメモリが必要であり、メモリは安価です。プロトタイピングとは、研究、Kaggleコンテスト、スタートアップのアイデアの試行、研究コードの実験など、あらゆる分野でのプロトタイピングを意味します。これらすべてのアプリケーションには、RTX3080が最適です。
たとえば、研究所やスタートアップを経営している場合、総予算の66〜80%をRTX 3080マシンに費やし、信頼性の高い水冷を備えたRTX 3090マシンに20〜33%を費やします。 RTX 3080はより費用効果が高く、Slurmからアクセスできます。..。プロトタイピングはアジャイルモードで実行する必要があるため、より小さなモデルとデータセットで実行する必要があります。そして、RTX3080はそのために最適です。学生/同僚が優れたプロトタイプモデルを作成したら、それをRTX 3090に展開して、より大きなモデルにスケールアップできます。
一般的な推奨事項
全体として、RTX 30シリーズモデルは非常に強力であり、絶対にお勧めします。前述のメモリ要件、および電力と冷却の要件を考慮してください。 GPU間に空きスロットがある場合は、冷却に問題はありません。それ以外の場合は、RTX 30カードに水冷、PCIeエキスパンダー、または効率的なファン付きカードを提供します。
全体として、RTX3090を購入できる人にはお勧めします。それは今あなたに合うだけでなく、次の3-7年間非常に効果的であり続けるでしょう。今後3年間でHBMメモリが大幅に安くなる可能性は低いため、次のGPUはRTX 3090よりも25%だけ優れています。5〜7年後には、おそらく安価なHBMメモリが表示されます。その後、必ずフリートを更新する必要があります。 ..。
複数のRTX3090からシステムを構築している場合は、十分な冷却と電力を供給してください。
競争上の優位性に対する厳しい要件がない限り、RTX 3080をお勧めします。これはより費用効果の高いソリューションであり、ほとんどのネットワークに迅速なトレーニングを提供します。必要なメモリトリックを実行し、余分なコードを記述してもかまわない場合は、24GBネットワークを10GBGPUに詰め込むためのトリックがたくさんあります。
RTX 3070は、GOトレーニングやプロトタイピングにも最適なカードであり、RTX 3080よりも200ドル安いです。RTX3080を購入できない場合は、RTX3070を選択してください。
予算が厳しく、RTX 3070が高すぎる場合は、eBayで中古のRTX2070を約260ドルで見つけることができます。RTX 3060が発売されるかどうかはまだ明確ではありませんが、予算が厳しい場合は待つ価値があるかもしれません。RTX2060およびGTX1060と一致する価格の場合、約250ドルから300ドルであり、良好に機能するはずです。
GPUクラスターに関する推奨事項
GPUクラスターのレイアウトは、その用途に大きく依存します。1024 GPU以上のシステムの場合、主なものはネットワークの存在ですが、一度に32個以下のGPUを使用する場合、強力なネットワークの構築に投資する意味はありません。
一般に、RTXカードは、CUDA契約に基づくデータセンターでは使用できません。ただし、大学はこの規則の例外となることがよくあります。このような許可を取得したい場合は、NVIDIAの担当者に連絡することをお勧めします。 RTXカードを使用できる場合は、Supermicroの標準の8 GPU RTX3080またはRTX3090システムをお勧めします(冷却状態を維持できる場合)。 8つのA10000ノードの小さなセットにより、特に8つのRTX 3090を備えた冷却サーバーが不可能な場合に、プロトタイピング後にモデルを効率的に使用できます。この場合、A10000は非常に費用対効果が高く、すぐに古くなることはないため、RTX 6000 / RTX8000よりもA10000をお勧めします。
GPUクラスター(256 GPU以上)で非常に大規模なネットワークをトレーニングする必要がある場合は、A10000を備えたNVIDIA DGXSuperPODシステムをお勧めします。 256のGPUから、ネットワーキングが不可欠になります。 256 GPUを超えて拡張する場合は、標準ソリューションが機能しなくなる高度に最適化されたシステムが必要になります。
特に1,024GPUスケール以上では、市場で競争力のあるソリューションはGoogle TPUPodとNVIDIADGXSuperPodだけです。この規模では、専用のネットワークインフラストラクチャがNVIDIA DGX SuperPodよりも見栄えがよいため、Google TPU Podを好みます。ただし、原則として、2つのシステムはかなり近いです。アプリケーションとハードウェアでは、GPUシステムはTPUよりも柔軟性がありますが、TPUシステムはより大きなモデルをサポートし、より適切に拡張できます。したがって、どちらのシステムにも長所と短所があります。
どのGPUを購入しないほうがよいか
冷却の問題に対処するPCIeエクスパンダーがない限り、一度に複数のRTX FoundersEditionまたはRTXTitansを購入することはお勧めしません。それらはただウォームアップし、グラフに示されているものと比較して速度が劇的に低下します。 4つのRTX2080 Ti Founders Editionは、90°Cまで急速に加熱され、クロック速度が低下し、通常冷却されているRTX2070よりも低速で動作します。
Tesla V100またはA100は、企業のデータセンターでの使用が禁止されているため、極端な場合にのみ購入することをお勧めします。または、巨大なGPUクラスターで非常に大規模なネットワークをトレーニングする必要がある場合はそれらを購入してください-それらの価格/パフォーマンス比は理想的ではありません。
もっと良いものを買う余裕があるなら、GTX16シリーズカードを買わないでください。テンソルコアがないため、GOでのパフォーマンスが低下します。代わりに、中古のRTX 2070 / RTX 2060 / RTX 2060Superを使用します。予算が非常に限られている場合は借りることができます。
新しいGPUを購入しないほうがよいのはいつですか。
すでにRTX2080 Ti以上を所有している場合、RTX3090にアップグレードしてもほとんど意味がありません。 GPUはすでに優れており、取得した電力と冷却の問題と比較して、速度のメリットはごくわずかです。それだけの価値はありません。
4つのRTX2080Tiから4つのRTX3090にアップグレードしたい唯一の理由は、計算能力に大きく依存する非常に大きな変圧器やその他のネットワークを研究していた場合です。ただし、メモリに問題がある場合は、最初にさまざまなトリックを検討して、大きなモデルを既存のメモリに詰め込む必要があります。
1つ以上のRTX2070を所有している場合、アップグレードする前に私があなたであるかどうかをよく考えます。これらはかなり良いGPUです。他の多くのGPUの場合と同様に、8GBでは不十分な場合は、eBayで販売してRTX3090を購入するのが理にかなっているかもしれません。十分なメモリがない場合は、更新が行われています。
質問や誤解への回答
概要:
- PCIeレーンとPCIe4.0は、デュアルGPUシステムには関係ありません。GPUが4つあるシステムの場合、実際にはそうではありません。
- RTX3090およびRTX3080の冷却は困難です。ウォータークーラーまたはPCIeエキスパンダーを使用してください。
- NVLinkは、GPUクラスターにのみ必要です。
- 同じコンピューターで異なるGPUを使用できますが(たとえば、GTX 1080 + RTX 2080 + RTX 3090)、効率的な並列化は機能しません。
- 3台以上のマシンを並行して実行するには、Infinibandと50Gbpsネットワークが必要です。
- AMDプロセッサはIntelプロセッサよりも安価であり、Intelプロセッサにはほとんど利点がありません。
- エンジニアの英雄的な努力にもかかわらず、AMD GPU + ROCmは、今後1〜2年でコミュニティと同等のテンソルコアが不足するため、NVIDIAと競合することはほとんどできません。
- クラウドGPUは、使用期間が1年未満の場合に役立ちます。その後、デスクトップ版が安くなります。
PCIe 4.0が必要ですか?
通常はそうではありません。PCIe4.0はGPUクラスターに最適です。8GPUマシンを使用している場合に便利です。それ以外の場合、ほとんど利点がありません。並列化が改善され、データが少し速く転送されます。しかし、データ転送はボトルネックではありません。コンピュータービジョンでは、ボトルネックはデータストレージである可能性がありますが、GPUからGPUへのPCIeデータ転送ではありません。したがって、ほとんどの人がPCIe4.0を使用する理由はありません。これにより、4つのGPUの並列化が1〜7%向上する可能性があります。
PCIe 8x / 16xレーンが必要ですか?
PCIe 4.0と同様に、通常はそうではありません。PCIeレーンは、並列化と高速データ転送に必要ですが、これがボトルネックになることはほとんどありません。GPUが2つある場合は、4行で十分です。4つのGPUの場合、GPUごとに8つのラインを使用することをお勧めしますが、4つのラインがある場合、パフォーマンスは5〜10%しか低下しません。
それぞれが3つのPCIeスロットを使用する場合、4つのRTX 3090をどのように適合させますか?
1つのスロットに対して2つのオプションのいずれかを購入するか、PCIeエクスパンダを使用してそれらを配布できます。スペースに加えて、すぐに冷却と適切な電源について考える必要があります。どうやら、最も簡単な解決策は、専用の水冷却ループを備えた4 x RTX 3090EVGAハイドロカッパーを購入することです。EVGAは長年にわたって銅製の水冷バージョンのカードを製造しており、GPUの品質を信頼できます。おそらくもっと安いオプションがあります。
PCIeエキスパンダーはスペースと冷却の問題を解決できますが、ケースにはすべてのカードを収納できる十分なスペースが必要です。そして、エクステンダーが十分に長いことを確認してください!
4 RTX3090または4RTX 3080を冷却する方法は?
前のセクションを参照してください。
複数の異なるGPUタイプを使用できますか?
はい。ただし、作業を効果的に並列化することはできません。3 RTX 3070 + 1 RTX 3090を実行しているシステムを想像できます。一方、モデルをそれらに詰め込むと、4つのRTX3070間の並列化が非常に迅速に機能します。そして、それが必要になるもう1つの理由は、古いGPUを使用していることです。動作しますが、最速のGPUが同期ポイントで最も遅いGPUを待機するため(通常は勾配更新時)、並列化は効果的ではありません。
NVLinkとは何ですか?必要ですか?
通常、NVLinkは必要ありません。複数のGPU間の高速通信です。128以上のGPUのクラスターがある場合に必要です。その他の場合、標準のPCIeデータ転送に勝る利点はほとんどありません。
私はあなたの最も安い推薦のためにさえお金を持っていません。何をすべきか?
間違いなく中古GPUを購入する。使用済みのRTX2070($ 400)およびRTX 2060($ 300)で問題ありません。それらを買う余裕がない場合、次善の選択肢は中古のGTX 1070($ 220)またはGTX 1070 Ti($ 230)でしょう。それが高すぎる場合は、中古のGTX 980 Ti(6GB $ 150)またはGTX 1650 Super($ 190)を見つけてください。それも高額な場合は、クラウドサービスを使用することをお勧めします。それらは通常、GPUに時間または電力制限を提供し、その後は料金を支払う必要があります。独自のGPUを購入できるようになるまで、サービスを交換します。
2台のマシン間でプロジェクトを並列化するには何が必要ですか?
2台のマシン間で並列化して作業を高速化するには、50Gbps以上のネットワークカードが必要です。少なくともEDRInfiniband、つまり少なくとも50Gbpsの速度のネットワークカードをインストールすることをお勧めします。eBayのケーブル付きの2枚のEDRカードは、500ドルを戻します。
場合によっては、10 Gbpsイーサネットでうまくいくこともありますが、これは通常、特定のタイプのニューラルネットワーク(特定の畳み込みネットワーク)または特定のアルゴリズム(Microsoft DeepSpeed)でのみ機能します。
スパースマトリックス乗算アルゴリズムは、スパースマトリックスに適していますか?
どうやらそうではありません。マトリックスは4つの要素ごとに2つのゼロを持つ必要があるため、スパースマトリックスは適切に構造化されている必要があります。4つの値を2つの値の圧縮表現として処理することでアルゴリズムをわずかに微調整することはおそらく可能ですが、これは、Ampereによるスパースマトリックスの正確な乗算が利用できないことを意味します。
複数のGPUを実行するにはIntelプロセッサが必要ですか?
Kaggleコンテスト(プロセッサに線形代数計算がロードされている)でプロセッサに過負荷をかけている場合を除いて、Intelプロセッサの使用はお勧めしません。そして、そのような競争でも、AMDプロセッサは素晴らしいです。AMDプロセッサは、GOにとって平均して安価で優れています。4-GPUビルドの場合、Threadripperが私の決定的な選択です。私たちの大学では、そのようなプロセッサをベースにした数十のシステムを収集しており、それらはすべて問題なく完全に機能します。GPUが8つあるシステムの場合、製造元が経験したプロセッサを使用します。8カードシステムのプロセッサとPCIeの信頼性は、速度やコスト効率よりも重要です。
ケースの形状は冷却に重要ですか?
番号。通常、GPU間にわずかなギャップがある場合でも、GPUは完全に冷却されます。ハウジングが異なると1〜3°Cの差が生じ、カードの間隔が異なると10〜30°Cの差が生じる可能性があります。一般的に、カード間に隙間があれば、冷却に問題はありません。ギャップがない場合は、適切なファン(ブローファン)または別のソリューション(水冷、PCIeエキスパンダー)が必要です。いずれにせよ、ケースの種類とそのファンは関係ありません。
AMD GPU + ROCmはNVIDIAGPU + CUDAをキャッチしますか?
今後数年ではありません。 3つの問題があります:テンソルカーネル、ソフトウェア、コミュニティ。
AMDのGPUクリスタル自体は優れています。FP16での優れたパフォーマンス、優れたメモリ帯域幅です。ただし、テンソルコアまたはそれに相当するものがないため、NVIDIAのGPUと比較してパフォーマンスが低下します。また、ハードウェアにテンソルコアを実装しないと、AMDGPUが競争力を持つことはありません。噂によると、2020年にはテンソルコアに類似したデータセンター用のカードが計画されていますが、正確なデータはまだありません。サーバー用のTensorCoreと同等のカードしかない場合は、AMD GPUを購入できる人がほとんどいないことを意味し、NVIDIAに競争力を与えます。
AMDが将来テンソルコアのようなものを備えたハードウェアを導入するとしましょう。その後、多くの人がこう言います。「しかし、AMD GPUで動作するプログラムはありません!どうすれば使えますか?」これは主に誤解です。 ROCmを実行するAMDソフトウェアはすでに十分に開発されており、PyTorchでのサポートは適切に編成されています。また、AMD GPU + PyTorchの動作に関するレポートはあまり見たことがありませんが、すべてのソフトウェア機能がそこに統合されています。どうやら、任意のネットワークを選択して、AMDGPUで実行できます。したがって、AMDはこの分野ですでに十分に開発されており、この問題は実質的に解決されています。
しかし、ソフトウェアの問題とテンソルコアの欠如を解決した後、AMDはもう1つ、コミュニティの欠如に直面しています。 NVIDIA GPUで問題が発生した場合は、Googleで解決策を検索して見つけることができます。これにより、NVIDIAGPUへの信頼が高まります。 NVIDIA GPUの使用を容易にするインフラストラクチャが登場しています(GOが機能するためのあらゆるプラットフォーム、あらゆる科学的タスクがサポートされています)。 NVIDIA GPU(たとえば、apex)をはるかに簡単に使用できるようにするハックやトリックがたくさんあります。 NVIDIA GPUの専門家とプログラマーはすべての茂みの下にいますが、AMDGPUの専門家ははるかに少ないと思います。
コミュニティの観点からは、AMDの状況はJulia対Pythonの状況と似ています。ジュリアには多くの可能性があり、多くの人がこのプログラミング言語が科学的研究により適していることを正しく指摘するでしょう。ただし、JuliaはPythonと比較してほとんど使用されません。Pythonコミュニティが非常に大きいというだけです。Numpy、SciPy、Pandasなどの強力なパッケージの周りにはたくさんの人が集まっています。この状況は、NVIDIAとAMDの状況に似ています。
したがって、AMDがNVIDIAに追いつくのは、テンソルコアに相当するものとROCmを中心に構築された強固なコミュニティが導入されるまでです。AMDは、常に特定のサブグループ(暗号通貨マイニング、データセンター)で市場シェアを獲得します。しかし、NVIDIAはおそらくさらに2年間独占を維持するでしょう。
クラウドサービスを使用する方がよいのはいつですか。専用のGPUコンピューターはいつですか。
簡単なルール:1年以上GOを実行する予定の場合は、GPUを搭載したコンピューターを購入する方が安価です。それ以外の場合は、クラウドプログラミングの豊富な経験があり、GPUの数を自由にスケーリングできるようにしたい場合を除いて、クラウドサービスを使用することをお勧めします。
クラウドGPUが自分のコンピューターよりも高価になる正確な転換点は、使用するサービスに大きく依存します。自分で計算することをお勧めします。以下は、1つのV100を備えたAWS V100サーバーの計算例であり、パフォーマンスが近い1つのRTX3090を備えたデスクトップコンピューターのコストと比較しています。 RTX 3090 PCの価格は2200ドル(2-GPUベアボーン+ RTX 3090)です。米国にいる場合は、電気用にkWhあたり0.12ドルを追加します。これを、AWSのサーバーあたり1時間あたり2.14ドルと比較してください。
年間15%のリサイクルで、コンピューターは
(350 W(GPU)+ 100 W(CPU))* 0.15(リサイクル)* 24時間* 365日= 591 kWh /年を使用します。
年間591kWhは、さらに71ドルを提供します。
コンピューターとクラウドの価格を15%の使用率で比較すると、転換点は300日目あたりになります(2,311ドル対2,270ドル):
2.14ドル/時間* 0.15(リサイクル)* 24時間* 300日= 2,311ドル
計算すると、 GOモデルの寿命が300日を超える場合は、AWSを使用するよりもコンピューターを購入することをお勧めします。
コンピュータとクラウドのどちらを使用するかを決定するために、任意のクラウドサービスに対して同様の計算を行うことができます。
計算能力の利用に関する一般的な数値は次のとおりです。
- PhDコンピューター:<15%;
- PhD SlurmのGPUクラスター:> 35%
- Slurmの企業研究クラスター:> 60%。
一般に、実用的なソリューションを開発するよりも最先端のアイデアを考えることが重要な分野では、リサイクル率が低くなります。一部の領域では使用率が低く(解釈可能性の調査)、他の領域でははるかに高くなっています(機械変換、言語モデリング)。一般的に、自家用車のリサイクルは常に過大評価されています。通常、ほとんどのパーソナルシステムは5〜10%リサイクルされます。したがって、研究チームや企業は、個別のデスクトップではなく、SlurmでGPUクラスターを編成することを強くお勧めします。
怠惰すぎて読めない人のためのヒント
全体的に最高のGPU:RTX 3080およびRTX3090。
避けるべきGPU(研究者として):Teslaカード、Quadro、Founders Edition、Titan RTX、Titan V、TitanXP 。
優れたパフォーマンス/価格比、しかし高価:RTX3080。
優れたパフォーマンス/価格比、より安い:RTX 3070、RTX2060スーパー。
お金が少ない:中古カードを買う。階層:RTX 2070($ 400)、RTX 2060($ 300)、GTX 1070($ 220)、GTX 1070 Ti($ 230)、GTX 1650 Super($ 190)、GTX 980 Ti(6GB $ 150)。
私にはほとんどお金がありません。多くのスタートアップがクラウドサービスを宣伝しています。クラウドで無料のクレジットを使用し、GPUを購入できるようになるまでサークルで変更します。
Kaggleコンペティションに参加します:RTX3070。
コンピュータービジョン、事前学習、または機械変換で競争に勝とうとしています:4個のRTX3090。ただし、十分な冷却と十分な電力を備えたアセンブリがあることを専門家が確認するまで待ちます。
私は自然な言語処理を学んでいます。機械翻訳、言語モデリング、または事前学習に興味がない場合は、RTX3080で十分です。
私はGOを始めて、本当にそれに夢中になりました。RTX3070から始めます。6〜9か月で飽きない場合は、4つのRTX 3080を販売および購入します。次に選択するもの(起動、Kaggle、調査、適用GO)に応じて、数年3つで、GPUを販売し、より良いもの(次世代RTX GPU)を購入します。
GOを試したいのですが、真剣な意図はありません。RTX2060Superは優れた選択肢ですが、PSUの交換が必要になる場合があります。マザーボードにPCIex16スロットがあり、PSUが約300ワットを生成する場合、GTX 1050 Tiは他の投資を必要としないため、優れたオプションになります。
128 GPU未満の並列シミュレーション用のGPUクラスター:クラスター用にRTXを購入できる場合:66%8x RTX 3080および33%8x RTX 3090(アセンブリを十分に冷却できる場合のみ)。冷却が不十分な場合は、33%RTX 6000GPUまたは8xTeslaA100を購入してください。 RTX GPUを購入できない場合は、8つのSupermicroA100ノードまたは8つのRTX6000ノードを選択します
。128を超えるGPUを使用した並列シミュレーション用のGPUクラスター:8テスラA100の車について考えてみてください。512を超えるGPUが必要な場合は、DGX A100SuperPODシステムを検討してください。