
この点で、DBMSは同じ原則に従って動作します-「彼らは掘ると言った、そして私は掘る」。リクエストは、隣接するプロセスの速度を低下させ、プロセッサリソースを常に占有するだけでなく、データベース全体を完全に「ドロップ」して、使用可能なすべてのメモリを「消費」する可能性があります。したがって、無限の再発から保護することは、開発者自身の責任です。
PostgreSQLでは、
WITH RECURSIVEバージョン8.4の記念すべき時から、再帰クエリを使用する機能が登場しましたが、潜在的に脆弱な「無防備な」クエリに定期的に遭遇する可能性があります。この種の問題から身を守る方法は?
再帰的なクエリを記述しないでください
そして、非再帰的に記述します。敬具あなたのK.O.実際、PostgreSQLは、再帰を回避するために使用できるかなり大量の機能を提供します。
タスクに根本的に異なるアプローチを使用する
「反対側から」問題を見ることができる場合もあります。このような状況の例を「SQLHowTo:1000と1つの集計方法」の記事で示しました。カスタム集計関数を使用せずに一連の数値を乗算します。
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, val) AS (
SELECT
1::bigint
, 1
UNION ALL
SELECT
i + 1
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
val
FROM
T
ORDER BY --
i DESC
LIMIT 1;このような要求は、数学の専門家からの変形に置き換えることができます。
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
exp(sum(ln(prime)))::integer val
FROM
src;ループの代わりにgenerate_seriesを使用する
文字列のすべての可能なプレフィックスを生成するタスクに直面しているとしましょう
'abcdefgh':
WITH RECURSIVE T AS (
SELECT 'abcdefgh' str
UNION ALL
SELECT
substr(str, 1, length(str) - 1)
FROM
T
WHERE
length(str) > 1
)
TABLE T;?正確には、あなたが使用している場合は...ここに再帰する必要がない
LATERALとgenerate_series、その後も、のCTEを必要としません、:
SELECT
substr(str, 1, ln) str
FROM
(VALUES('abcdefgh')) T(str)
, LATERAL(
SELECT generate_series(length(str), 1, -1) ln
) X;データベース構造を変更する
たとえば、ソーシャルネットワーク上の誰かまたはスレッドに誰が回答したかへのリンクを含むフォーラム投稿のテーブルがあります。
CREATE TABLE message(
message_id
uuid
PRIMARY KEY
, reply_to
uuid
REFERENCES message
, body
text
);
CREATE INDEX ON message(reply_to);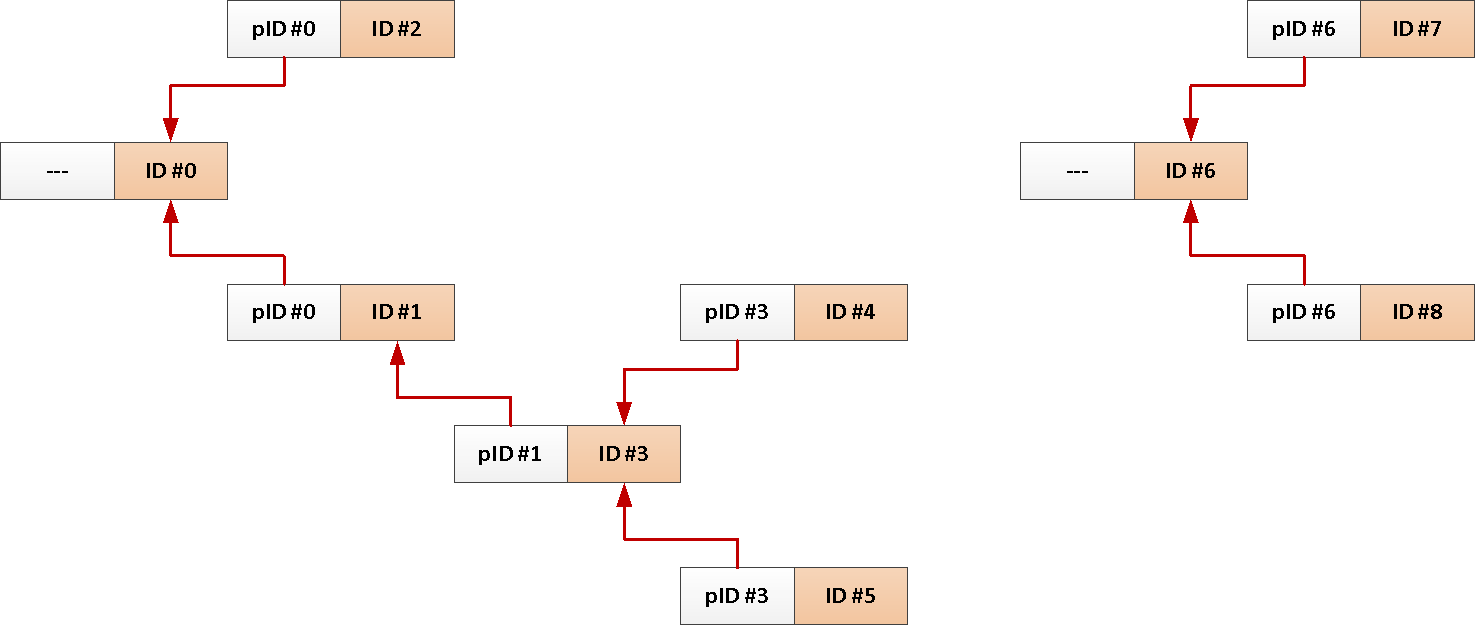
1つのトピックに関するすべてのメッセージをダウンロードする一般的なリクエストは、次のようになります。
WITH RECURSIVE T AS (
SELECT
*
FROM
message
WHERE
message_id = $1
UNION ALL
SELECT
m.*
FROM
T
JOIN
message m
ON m.reply_to = T.message_id
)
TABLE T;しかし、ルートメッセージの件名全体が常に必要なので、その識別子を各投稿に自動的に追加してみませんか?
--
ALTER TABLE message
ADD COLUMN theme_id uuid;
CREATE INDEX ON message(theme_id);
--
CREATE OR REPLACE FUNCTION ins() RETURNS TRIGGER AS $$
BEGIN
NEW.theme_id = CASE
WHEN NEW.reply_to IS NULL THEN NEW.message_id --
ELSE ( -- ,
SELECT
theme_id
FROM
message
WHERE
message_id = NEW.reply_to
)
END;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER ins BEFORE INSERT
ON message
FOR EACH ROW
EXECUTE PROCEDURE ins();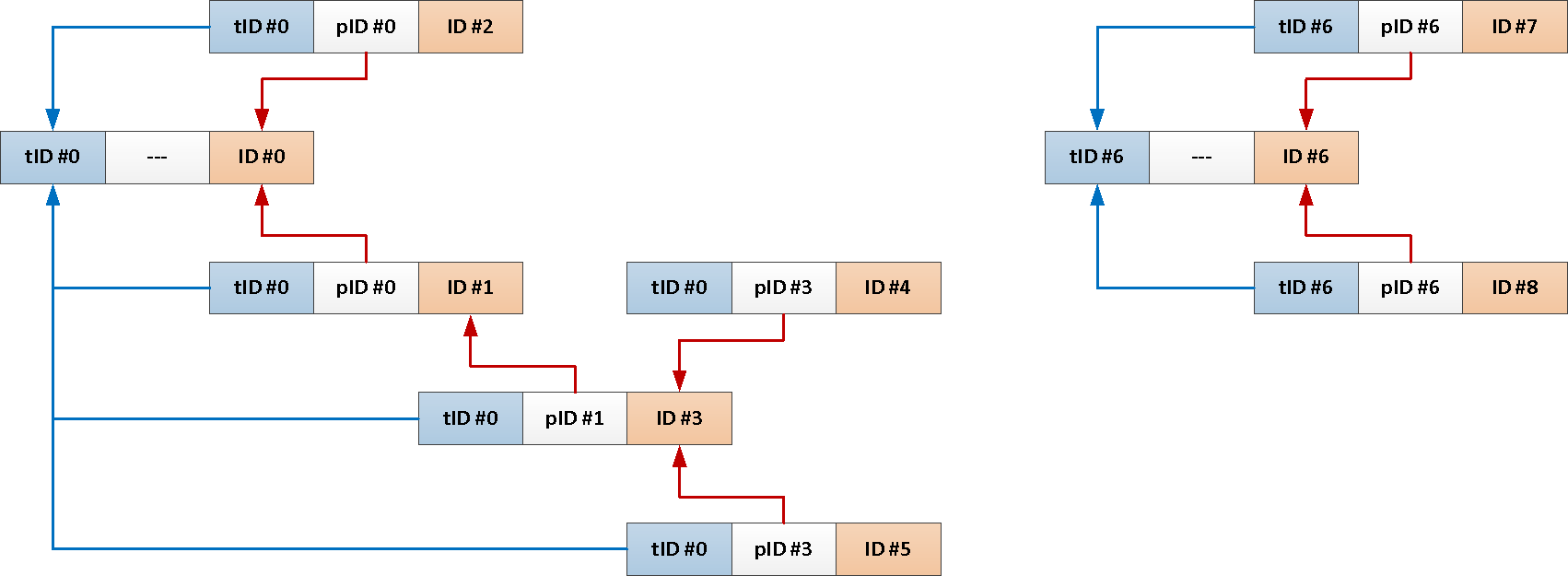
これで、再帰クエリ全体を次のように減らすことができます。
SELECT
*
FROM
message
WHERE
theme_id = $1;適用された「制約」を使用する
何らかの理由でデータベースの構造を変更できない場合は、データにエラーが存在しても無限の再帰が発生しないように、何を信頼できるかを見てみましょう。
再帰「深度」カウンター
制限に達するまで、再帰の各ステップでカウンターを1つずつ増やしますが、これは明らかに不十分であると考えられます。
WITH RECURSIVE T AS (
SELECT
0 i
...
UNION ALL
SELECT
i + 1
...
WHERE
T.i < 64 --
)長所:ループしようとしても、「深さ」で指定された反復制限を超えないようにします。
対照:たとえば、深さが15と25の場合、同じレコードが再度処理されないという保証はありません。その後、+ 10ごとに処理されます。そして、誰も「幅」について何も約束しませんでした。
正式には、このような再帰は無限ではありませんが、各ステップでレコード数が指数関数的に増加する場合、それがどのように終了するかは誰もがよく知っています...

「道」の守護者
再帰パスに沿って遭遇したすべてのオブジェクト識別子を1つずつ配列に追加します。これは、それに固有の「パス」です。
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) --
)長所:データにループがある場合、同じパス内で同じレコードを何度も処理することは絶対にありません。
対照的:しかし同時に、文字通り、繰り返すことなくすべての録音をバイパスすることができます。
パスの長さの制限
理解できない深さでの再帰の「さまよう」状況を回避するために、前の2つの方法を組み合わせることができます。または、不要なフィールドをサポートしたくない場合は、パスの長さの見積もりで再帰継続条件を補足します。
WITH RECURSIVE T AS (
SELECT
ARRAY[id] path
...
UNION ALL
SELECT
path || id
...
WHERE
id <> ALL(T.path) AND
array_length(T.path, 1) < 10
)お好みの方法をお選びください!