多くの場合、コンバージョン数が多く、その価格が許容範囲内であり、売上が伸びず、さらには落ち込む場合に発生します。ここでは、「クリックあたりの利益の前」の分析では、理由を見つけるのにもはや十分ではありません。そして、「マネージャーからの利益の前に」分析が助けになります。広告がどれほど理想的に設定されていても、顧客は最初にマネージャーと対話し、次に決定を下します。あなたのビジネスの成功はあなたの従業員の仕事の質に依存します。
従来の分析システムは、CRMを使用して、販売の事実/マネージャーとの接触を記録します。ただし、このアプローチは問題を部分的にしか解決しません。つまり、従業員の効率を「最終的に」評価します。つまり、売上とコンバージョンを示していますが、クライアントとのコミュニケーションそのものを「船外」に残しています。しかし、結果はコミュニケーションのレベルに依存します。
ギャップを埋めるために、各呼び出しを処理したマネージャーに自動的にリンクするツールを開発しました。 CRMやサードパーティのサービスを使用する必要はありません。実際、私たちのシステムは、すべての着信コールに「マネージャーの名前」というタグを付けます。
したがって、営業/顧客サービス部門の責任者は、作業の品質を管理し、問題のある領域を見つけて分析を構築します。それらを受信するマネージャーへの呼び出しの高速セグメンテーションは、これに役立ちます。
問題の定式化
私たちが設定したタスクは次のとおりです。電話を受けることができるすべてのマネージャーの音声パターンをシステムに通知します。次に、新しい電話をかけるには、マネージャーにタグを付ける必要があります。マネージャーの声は、既知のリストの会話の中で最も「類似」しています。
この場合、新しい電話が成功したことが事前に考慮されます。つまり、マネージャーとクライアントの間の会話が実際に行われました。非公式に言えば、このタスクは「教師と一緒に教える」というタスクのクラス、つまり分類に起因する可能性があります。
オブジェクトとして-何らかの方法でベクトル化された(デジタル化された)オーディオ録音で、マネージャーの声だけが鳴ります。応答はクラスラベル(マネージャー名)です。次に、タグ付けアルゴリズムのタスクは次のとおりです。
- オーディオファイルからの意味のある機能の抽出
- 最適な分類アルゴリズムの選択
- アルゴリズムの学習とマネージャーモデルの保存
- アルゴリズムの品質を評価し、そのパラメーターを変更する
- 新しい通話のタグ付け(分類)
これらのタスクの一部は、個別のサブタスクに分類されます。これは、アルゴリズムが動作しなければならない条件の詳細によるものです。通常、電話はうるさいです。1つの会話内のクライアントは、複数のマネージャーと通信できます。また、それはまったく行われず、通話にはIVRなどが含まれることがよくあります。
たとえば、新しい通話にタグを付けるタスクは次のように分割できます。
- 呼び出しが成功したかどうかを確認する(呼び出しがあるという事実)
- ステレオをモノラルトラックに分割
- ノイズフィルタリング
- スピーチのあるエリアの識別(音楽やその他の無関係な音のフィルタリング)
将来的には、そのような各サブタスクについて個別に説明します。それまでの間、入力データ、結果のソリューション、および分類アルゴリズム自体に課す技術的制約を定式化します。
ソリューションの制約
制限の必要性は、実装の複雑さの手法と要件、およびアルゴリズムの普遍性とその操作の精度との間のバランスによって部分的に決定されます。
入力ファイルとトレーニングサンプルファイルの制限:
- フォーマット-wavまたはwave(さらにmp3に再コーディングできます)
- その後、ステレオはオペレーターとクライアントの2つのトラックに分割する必要があります
- サンプリングレート-16,000Hz以上
- ビット深度-16ビット以上から
- モデルをトレーニングするためのファイルは、少なくとも30秒の長さで、特定のマネージャーの声のみが含まれている必要があります
- , , ,
上記の要件はすべて、最後の要件を除いて、アルゴリズムの設定段階で実行された一連の実験の結果として策定されました。この組み合わせは、エラーの可能性を最小限に抑えるという点で最も効果的であることが示されています。つまり、負担の少ないチューニング条件下での誤分類です。
たとえば、トレーニングセット内のファイルが長いほど、分類子の精度が高くなることは明らかです。しかし、コールログ(トレーニングサンプル)でそのようなファイルを見つけるのはより困難です。したがって、30秒の長さは、設定の正確さと複雑さの間の妥協点です。最後の要件(成功)が必要です。システムは、実際には会話がなかった通話にマネージャーをタグ付けしてはなりません。
アルゴリズムの制限により、次の解決策が導き出されました。
- , . « ». . - , .
- . , , .
最初の要件は実験から来ました。次に、「不明な」マネージャーがソリューションのアーキテクチャを複雑にしていることが判明しました。このため、従業員が「認識されない」として分類されるしきい値を選択する必要があります。また、「不明な」マネージャーは精度を10パーセントポイント低下させます。
さらに、既知のマネージャーが不明として分類されると、第2の種類のエラーが表示されます。このようなエラーの確率は、既知のエラーの数に応じて7〜10%です。この要件は必須と言えます。アルゴリズムチューナーは、トレーニングサンプル内のすべてのマネージャーを示す必要があります。また、そこに新入社員のモデルを紹介し、辞めた人を排除します。
2番目の要件は、実際的な考慮事項と、使用しているアルゴリズムのアーキテクチャに由来します。つまり、アルゴリズムは分析されたオーディオを音声フラグメントに分割し、それぞれをトレーニング済みのすべてのマネージャーモデルと1つずつ「比較」します。
その結果、「ミニタグ」が各ミニフラグメントに割り当てられます。このアプローチでは、一部のフラグメントが誤って認識される可能性が高くなります。たとえば、ノイズが多い場合や長さが短すぎる場合などです。
そして、最終的なソリューションですべての「ミニタグ」が表示されると、実際のマネージャーのタグに加えて、多くの「ゴミ箱」のタグが表示されます。したがって、最も「頻繁な」タグのみが表示されます。
入力/出力データの説明
入力データを2つのタイプに分けます。
マネージャーのモデルを生成するためのアルゴリズムの入力でのデータ(トレーニング用のデータ):
- オーディオファイル+クラスラベル
タグ付けアルゴリズムの入力時のデータ(テスト/通常操作用のデータ):
- 外部データ(オーディオファイル)
- 内部データ(保存されたモデル)
出力も2つのタイプに分けられます:
- モデル生成アルゴリズムの出力データ
- 訓練を受けたマネージャーモデル
- タグ付けアルゴリズムからの出力
- マネージャータグ
アルゴリズムの入力では、その動作のどのモードでも、要件を満たすオーディオファイルが受信されます。それらは「制限」セクションにあります。
モデル生成アルゴリズムの入力では、複数の入力ファイルが1つのクラス(マネージャー)に対応することが許可されます。ただし、1つのファイルを複数のマネージャーに対応させることはできません。クラスラベル名はファイル名に入れることができます。または、従業員ごとに個別のディレクトリを作成します。
入力データに基づくモデルトレーニングアルゴリズムは、トレーニング中にロードできる多くのモデルを生成します。それらの数は、オーディオファイルのセット内の異なるタグの数に対応します。
したがって、nでマークされたM個のファイルがある場合 異なるクラスラベルの場合、アルゴリズムはトレーニング段階でマネージャーのn個のモデルを作成します。
- Model_manager_1.pkl
- Model_manager_2.pkl
- ..。
- Model_manager_n.pkl
ここで、「manager _...」の代わりにクラスの名前があります。
タグ付けアルゴリズムへの入力は、ラベルのないオーディオファイルであり、マネージャーとクライアント、およびn人の従業員モデルの間で事前に会話が行われます。その結果、アルゴリズムはタグ(最も「もっともらしい」マネージャーのクラスの名前)を返します。
データの前処理
オーディオファイルは前処理されます。これはシーケンシャルであり、タグ付けモードとモデルトレーニングモードの両方で実行されます。
- 通話の成功の確認-タグ付けの段階でのみ
- ステレオを2つのモノラルトラックに分割し、さらにオペレーターのトラックでのみ機能します
- デジタル化-オーディオ信号パラメータの抽出
- ノイズフィルタリング
- 「長い」一時停止の削除-音声でフラグメントを識別する
- 非音声フラグメントのフィルタリング-音楽、背景などの削除。
- フラグメントとスピーチの融合(トレーニングの段階でのみ)
成功チェックの段階にはこだわらない。これは別の記事の主題です。つまり、ステージの本質は、「生きている人々」の会話があるかどうかによって通話が分類されるということです。「生きている人々」とは、音声アシスタントや音楽などではなく、クライアントとマネージャーを意味します。
通話の成功は、外部しきい値(「通話が成功したと見なされるまでの会話の最小時間」)を備えた特別に訓練された分類子を使用してチェックされます。
第2段階では、ステレオファイルはマネージャーとクライアントの2つのトラックに分割されます。それ以降の処理は、従業員のトラックに対してのみ実行されます。
デジタル化の段階で、信号のデジタル表現であるオペレータートラックから「機能」のパラメーターが抽出されます。Calltouchではチョーク-cepstralコンポーネントを使用しました。さらに、パラメータはウィンドウ幅(0.025秒)と呼ばれる非常に小さなフラグメントで抽出されます。すべての機能が同時に正規化されます。
nfft=2048 //
appendEnergy = False
def get_MFCC(sr,audio): // , sr=16000 -
features = mfcc.mfcc(audio, sr, 0.025, 0.01, 13, 26, nfft, 0, 1000, appendEnergy)
features = preprocessing.scale(features)
return features
count = 1
features = np.asarray(()) //
for path in file_paths: //
path = path.strip()
sr,audio = read(source + path) //
vector = get_MFCC (sr, audio) #
if features.size == 0:
features = vector
else:
features = np.vstack((features, vector))出力では、各オーディオファイルが配列に変わります。この配列には、0.025秒の各フラグメントのセルセプトラル特性が1行ずつ記録されます。
ファイルのさらなる処理は、ノイズのフィルタリング、長い一時停止(音の間の一時停止ではない)の削除、および音声の検索で構成されます。これらのタスクは、さまざまなツールを使用して実行できます。私たちのソリューションでは、pyaudioanalysisライブラリのメソッドを使用しました。
clear_noise(fname,outname,ch_n) # .- fname-入力ファイル
- outname-出力ファイル
- ch_n-チャネル数
出力では、ファイルfnameから、ノイズからクリーンアップされたサウンドを含むファイルoutnameを取得します。
silenceRemoval(x, Fs, stWin, stStep) # « »- x-入力アレイ(デジタル化された信号)
- Fs-サンプリングレート
- stWin-特徴抽出ウィンドウの幅
- stStep-オフセットステップサイズ
出力で、次の形式の配列を取得します。
[l_1、r_1]
[l_2、r_2]
[l_3、r_3]
…
[l_N、r_N]
ここで、l_iはi番目のセグメントの開始時間(秒)、r_iはi番目のセグメントの終了時間(秒)です。 )。
detect_audio_segment(x,thrs) # .- x-入力アレイ(デジタル化された信号)
- 時間-検出された音声フラグメントの最小長(秒単位)
出力では、我々はそれらの断片を取得[L_iを、R_iと]スピーチが含まれているから、持続THRSの秒。
前処理の結果、入力オーディオファイルは配列の形式に変換されます:
[l_1、r_1]
[l_2、r_2]
[l_3、r_3]
…
[l_N、r_N]、
ここで各フラグメントはクリーンアップされた音声ファイルの時間間隔です。
したがって、このような各フラグメントを、モデルのトレーニングおよびタグ付けの段階で使用される特徴のマトリックス(小さな脳の特徴)と一致させることができます。
使用される方法/アルゴリズム
上記のように、私たちのソリューションは、Python2.7で記述されたpyaudioanalysis.pyライブラリに基づいています。一般的なソリューションがPython3.7で実装されているため、一部のライブラリ関数が変更され、このバージョンの言語に適合しています。
一般に、マネージャーにタグを付けるためのツールのアルゴリズムは、次の2つの部分に分けることができます。
- モデルマネージャーのトレーニング
- タグ付け
各パーツの詳細な説明は次のようになります。
モデルマネージャーのトレーニング:
- トレーニングサンプルの読み込み
- データの前処理
- クラスの数を数える
- 各クラスのマネージャーモデルの作成
- モデルの保存
タグ付け:
- 通話の読み込み
- 成功の呼びかけをチェックする
- 成功した通話の前処理
- トレーニングを受けたすべてのマネージャーモデルを読み込む
- 処理された呼び出しの各フラグメントの分類
- 最も可能性の高いマネージャーモデルを見つける
- タグ付け
データの前処理のタスクについては、すでに詳細に説明しました。それでは、マネージャーモデルを作成する方法を見てみましょう。モデル
としてGMM(Gaussian Mixture Model)アルゴリズムを使用しました。彼は、ガウスの混合によって記述される分布を持つランダム変数の実現であるという仮定の下で私たちのデータをモデル化します-それぞれが独自の分散と独自の数学的期待を持っています。
このような混合物の最適なパラメータを見つけるための最も一般的なアルゴリズムは、EM (期待値最大化)アルゴリズムであることが知られています。彼は、多次元ランダム変数の可能性を最大化するという難しい問題を、低次元の一連の最大化問題に分割します。
一連の実験の結果、GMMアルゴリズムの次のパラメータに到達しました。
gmm = GMM(n_components = 16, n_iter = 200, covariance_type='diag',n_init = 3)このようなモデルはマネージャーごとに作成され、トレーニングされます。そのパラメーターは特定のデータに合わせて調整されます。
gmm.fit(features)次に、タグ付け段階で使用するためにモデルが保存されます。
picklefile = path[path.find('/')+1:path.find('.')]+".gmm"
pickle.dump(gmm,open(dest + picklefile,'wb'))タグ付けの段階で、以前に保存したモデルをロードします。
gmm_files = [os.path.join(modelpath,fname) for fname in
os.listdir(modelpath) if fname.endswith('.gmm')]modelpathは、モデルを保存したディレクトリです。
models = [pickle.load(open(fname,'rb'),encoding='latin1') for fname in gmm_files]また、モデルの名前をロードします(これらは私たちのタグです):
speakers = [fname.split("/")[-1].split(".gmm")[0] for fname
in gmm_files]タグ付けするアップロードされたオーディオファイルは、ベクトル化されて前処理されます。さらに、スピーチを含む各フラグメントは、トレーニングされたモデルと比較され、勝者は可能性の最大対数の観点から決定されます。
log_likelihood = np.zeros(len(models)) #
for i in range(len(models)):
gmm = models[i] #
scores = np.array(gmm.score(vector))
log_likelihood[i] = scores.sum() # i –
winner = np.argmax(log_likelihood) #
print("\tdetected as - ", speakers[winner])その結果、アルゴリズムの結論はおおよそ次のようになります。
開始:1.92終了:8.72
[-10400.93604115 -12111.38278205]
として検出-オルガ
開始:9.22終了:15.72
[-10193.80504138 -11911.11095894]
検出-オルガ
開始:26.7終了in:29.82
[-4867.97641331 -5506.44233563]
として検出-Ivan
開始:33.34で終了:
47.14 [-21143.02629011 -24796.44582627]
として検出-Ivan
開始:52.56で終了:59.24
[-10916.83282132-12124.26855538]
として検出-Olga
開始で:116.32で終わる:134.56
[-36764.94876054 -34810.38959083]
として検出-オルガで
始まる:151.18で終わる:154.86
[-8041.33666572 -6859.14253903]
として検出-オルガの
開始:159.7終了:162.92
[-6421.72235531 -5983.90538059]
として検出-オルガの
開始:185.02終了:208.7
…
開始:442.04終了:445.5
[-7451.0289772 -6286.6619 ]
として検出
-Olga *******
WINNER-Olga
この例では、少なくとも2つのクラスがあることを前提としています- [Olga、Ivan]。オーディオファイルはセグメント[1.92、8.72]、[9.22、15.72]、…、[442.04、445.5]にカットされ、各セグメントに最適なモデルが決定されます。
累積尤度対数は、各チャンクの横の括弧内に示されています。[-10400.93604115 -12111.38278205]、最初の要素はオルガの可能性であり、2番目の要素はイワンです。最初の引数が2番目の引数よりも大きいため、このセグメントはOlgaとして分類されます。最終的な勝者は、フラグメントの「投票」の大部分によって決定されます。
結果
最初に、「不明な」マネージャーが着信コールに存在する可能性がある、つまり、彼のモデルがトレーニングサンプルに存在しないという前提で、アルゴリズムを設計しました。
このようなユーザーを検出するには、log_likelihoodベクトルにメトリックを入力する必要があります。その値の特定は、このフラグメントが既存のモデルのいずれによっても適切に記述されていない可能性が高いことを示します。テストとして、次のメトリックを提案しました。
Leukl=(log_likelihood-np.min(log_likelihood))/(np.max(log_likelihood)-np.min(log_likelihood))
-sorted(-np.array(Leukl))[1]<Tこの値は、スコアがlog_likelihoodベクトルでどの程度「均等に」分散されているかを示します。推定値の均一性(相互の近さ)は、すべてのモデルが同じように動作し、明確なリーダーがないことを意味します。
これは、ほとんどの場合、すべてのモデルが間違っており、トレーニング段階になかったマネージャーがいることを示しています。Tと分類の質の関係を図に示します。
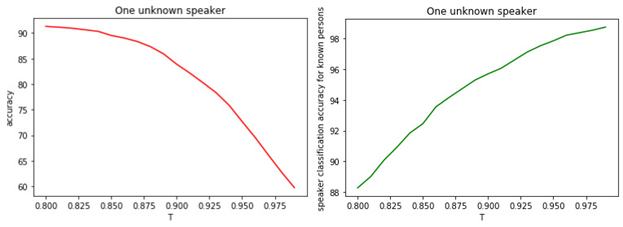
図: 1.
a)既知および未知のマネージャーのバイナリ分類の精度。
b)有名なマネージャーの分類の正確さ。

図: 2.
a)有名なマネージャーのクラスに割り当てられた有名なマネージャーの割合。
b)既知のクラスに割り当てられた未知のマネージャーの割合。
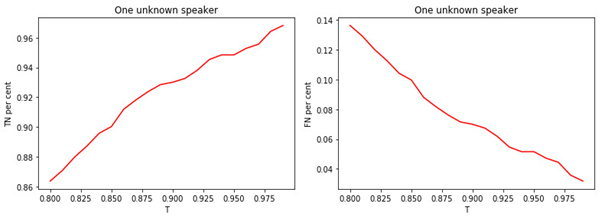
図: 3.3。
a)未知のクラスに割り当てられた未知のマネージャーのシェア。
b)未知のクラスに割り当てられた有名なマネージャーの割合。
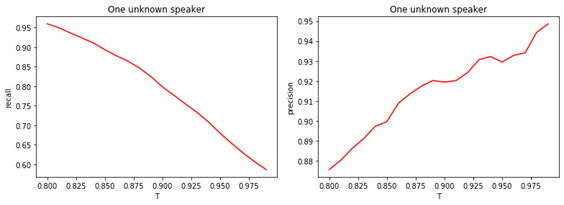
図: 4.
a)バイナリ分類の完全性(リコール)。
b)バイナリ分類の精度(精度)。
しきい値Tの値と分類(タグ付け)の品質との関係は明らかです。Tが大きいほど(マネージャーを不明のクラスに割り当てるための条件が厳しくなります)、有名なマネージャーが不明として分類される可能性は低くなります。しかし、未知のマネージャーを「見逃す」可能性が高くなります。
最適なしきい値は0.8です。有名なマネージャーを約90%の精度で分類しているためそして、81%の精度で「未知数」を決定します。すべてのマネージャーが私たちに「精通している」と仮定すると、精度は約98%になります。
結論
この記事では、通話中のマネージャーを識別するためのツールの機能に関する一般的な考え方について説明しました。もちろん、私たちのアルゴリズムが最適であり、改善できないふりをしているわけではありません。
これは、実際には常に満たされるとは限らないいくつかの仮定に基づいています。たとえば、彼に関するデータがない場合、未知のマネージャーに遭遇する可能性があります。または、2人以上のマネージャーが「均等に」クライアントと会話を行うことができます。アルゴリズムの観点から、さらなる改善のための以下の指示を提案することができます。
- GMMとは異なるアルゴリズムモデルの選択
- GMMパラメータの最適化
- 新しいマネージャーを検出するための別のメトリックの選択
- 音声信号の最も重要な機能を検索する
- さまざまなオーディオ前処理ツールの組み合わせとこれらのメソッドのパラメーターの最適化