
Amazon SageMakerは、Jupyterでノートブックを管理する機能だけでなく、機械学習モデルを作成、トレーニング、最適化、および展開できる構成可能なサービスを提供します。特にSageMakerを使い始めるときによくある誤解は、これらのサービスを使用するにはSageMaker NotebookインスタンスまたはSageMaker(Studio)Notebookが必要であるというものです。実際、すべてのサービスをローカルコンピューターまたはお気に入りのIDEから直接実行できます。
先に進む前に、AmazonSageMakerサービスと対話する方法を見てみましょう。 2つのAPIがあります
。SageMakerPythonSDK-機械学習モデルを構築、トレーニング、および展開するためのコードを抽象化する高レベルのPythonAPI。特に、ファーストクラスまたは組み込みアルゴリズムのエバリュエーターを提供し、TensorFlow、MXNETなどのフレームワークもサポートします。ほとんどの場合、これを使用してインタラクティブな機械学習タスクを操作します。
AWS SDKサポートされているすべてのAWSサービスと対話するために使用される低レベルのAPIであり、必ずしもSageMaker用ではありません。AWS SDKは、Java、Javascript、Python(boto)などの最も一般的な言語で利用できます。ほとんどの場合、このAPIは、自動化リソースの作成や、SageMaker PythonSDKでサポートされていない他のAWSサービスとのやり取りなどに使用します。
なぜローカル環境?
最初に頭に浮かぶのはコストですが、ネイティブIDEを使用する柔軟性と、オフラインで作業し、準備ができたときにAWSクラウドでタスクを実行する機能も重要な役割を果たします。
ローカル環境の仕組み
モデルを構築するためのコードを記述しますが、SageMakeNotebookまたはSageMakerStudio Notebookのインスタンスの代わりに、JupyterのローカルマシンまたはIDEから記述します。次に、すべての準備ができたら、AWS上のSageMakerインスタンスのトレーニングを開始します。トレーニング後、モデルはAWSに保存されます。その後、ローカルマシンからデプロイメントまたはバッチ変換を実行できます。
condaで環境をセットアップする
Python仮想環境をセットアップすることをお勧めします。この例では、condaを使用して仮想環境を管理しますが、virtualenvを使用することもできます。ここでも、AmazonSageMakerはcondaを使用して環境とパッケージを管理します。すでにcondaがインストールされていることを前提としています。インストールされていない場合は、ここにアクセスしてください。
新しいコンダ環境を作成する
conda create -n sagemaker python=3環境を活性化して検証します

必要なパッケージのインストール
パッケージをインストールするには、コマンド
condaまたはを使用しますpip。condaでオプションを選択しましょう。
conda install -y pandas numpy matplotlibAWSパッケージのインストール
AWS SDK for Python(boto)、awscli、およびSageMaker PythonSDKをインストールします。SageMaker Python SDKはcondaパッケージとして利用できないため、ここで使用します
pip。
pip install boto3 awscli sagemakerawscliを初めて使用する場合は、構成する必要があります。ここでは、その方法を確認できます。
SageMaker PythonSDKの2番目のバージョンがデフォルトでインストールされます。SDKの2番目のバージョンで重大な変更がないか必ず確認してください。
Jupyterのインストールとコアの構築
conda install -c conda-forge jupyterlab
python -m ipykernel install --user --name sagemaker環境を確認し、バージョンを確認します
jupyter labからJupyterを起動し、
sagemaker上記で作成したコアを選択します。
次に、ノートブックのバージョンをチェックして、必要なバージョンであることを確認します。
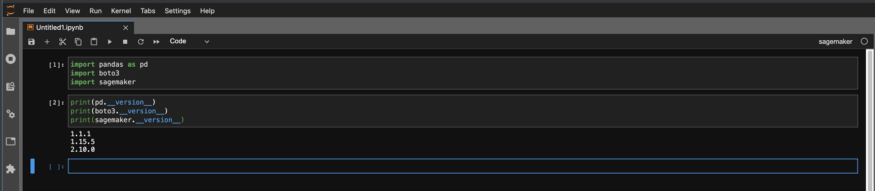
作成してトレーニングします
これで、ローカルでモデルの構築を開始し、準備ができたらAWSで学習を開始できます。
パッケージのインポート
必要なパッケージをインポートし、役割を指定します。ここでの主な違いは
arn、ではなく、直接ロールを指定する必要があることですget_execution_role()。ロールを持つノートブックインスタンスではなく、AWS資格情報を使用してローカルマシンからすべてを実行しているため、この機能get_execution_role()は機能しません。
from sagemaker import image_uris # Use image_uris instead of get_image_uri
from sagemaker import TrainingInput # Use instead of sagemaker.session.s3_input
region = boto3.Session().region_name
container = image_uris.retrieve('image-classification',region)
bucket= 'your-bucket-name'
prefix = 'output'
SageMakerRole='arn:aws:iam::xxxxxxxxxx:role/service-role/AmazonSageMaker-ExecutionRole-20191208T093742'評価者を作成する
エバリュエーターを作成し、通常どおりにハイパーパラメーターを設定します。以下の例では、組み込みの画像分類アルゴリズムを使用して画像分類子をトレーニングします。また、Stagemakerインスタンスのタイプとトレーニングに使用するインスタンスの数を指定します。
s3_output_location = 's3://{}/output'.format(bucket, prefix)
classifier = sagemaker.estimator.Estimator(container,
role=SageMakerRole,
instance_count=1,
instance_type='ml.p2.xlarge',
volume_size = 50,
max_run = 360000,
input_mode= 'File',
output_path=s3_output_location)
classifier.set_hyperparameters(num_layers=152,
use_pretrained_model=0,
image_shape = "3,224,224",
num_classes=2,
mini_batch_size=32,
epochs=30,
learning_rate=0.01,
num_training_samples=963,
precision_dtype='float32')
学習チャネル
いつもの方法で学習チャネルを指定します。ノートブックのコピーで行う方法と比較して変更はありません。
train_data = TrainingInput(s3train, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data = TrainingInput(s3validation, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
train_data_lst = TrainingInput(s3train_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
validation_data_lst = TrainingInput(s3validation_lst, distribution='FullyReplicated',
content_type='application/x-image', s3_data_type='S3Prefix')
data_channels = {'train': train_data, 'validation': validation_data,
'train_lst': train_data_lst, 'validation_lst': validation_data_lst}トレーニングを開始します
fitメソッドを呼び出してSageMakerでトレーニングタスクを開始します。これにより、SageMakerAWSインスタンスでトレーニングが開始されます。
classifier.fit(inputs=data_channels, logs=True)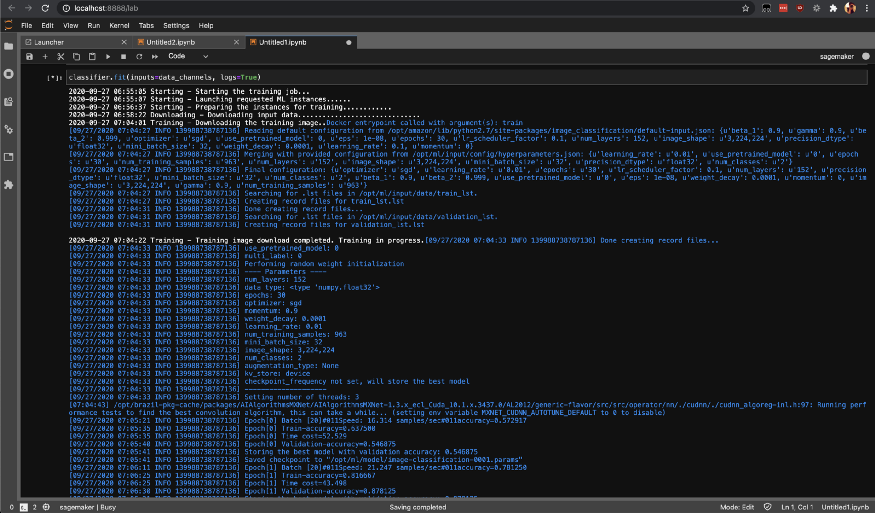
list-training-jobs を使用してトレーニングジョブのステータスを確認できます。
それで全部です。今日は、SageMaker環境をローカルにセットアップし、Jupyterを使用してローカルマシンでマシン学習モデルを構築する方法を理解しました。Jupyterの他に、独自のIDEからも同じことができます。
幸せな学習!
