この記事はこのニュアンスについてです。
私はいつものようにセレンを実行し、タタルスタン共和国の選挙結果が記載された必要なテーブルが配置されているリンクを最初にクリックした後、クラッシュします

ご存知のように、ニュアンスは、リンクをクリックするたびにキャプチャが表示されるという事実にあります。
サイトの構造を分析したところ、リンク数は約3万に達していることがわかりました。
キャプチャを認識する方法をインターネットで検索するしかありませんでした。 1つのサービスが見つかりました
+ Captchaは人と同じように100%認識されます
-平均認識時間は9秒です。これは、約3万の異なるリンクがあり、Captchaを追跡して認識する必要があるため、非常に長いです。
私はすぐにこの考えをあきらめました。キャプチャを取得しようと何度か試みた後、私はそれがあまり変わらないことに気づきました。すべて同じ黒い数字が緑の背景にあります。
そして、ずっと「ビジョンコンピュータ」に手で触れたいと思っていたので、みんなのお気に入りのMNIST問題を自分で試す絶好のチャンスだと思いました。
すでに17時だったので、数字を認識するための事前に訓練されたモデルを探し始めました。このキャプチャでそれらをチェックした後、精度は私を満足させませんでした-まあ、それは写真を集めてあなたの神経ネットワークを訓練する時です。
まず、トレーニングサンプルを収集する必要があります。
Chrome Webドライバーを開き、フォルダー内の1000個のキャプチャをスクリーニングします。
from selenium import webdriver
i = 1000
driver = webdriver.Chrome('/Users/aleksejkudrasov/Downloads/chromedriver')
while i>0:
driver.get('http://www.vybory.izbirkom.ru/region/izbirkom?action=show&vrn=4274007421995®ion=27&prver=0&pronetvd=0')
time.sleep(0.5)
with open(str(i)+'.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
i = i - 12色しかないので、キャプチャをbwに変換しました。
from operator import itemgetter, attrgetter
from PIL import Image
import glob
list_img = glob.glob('path/*.png')
for img in list_img:
im = Image.open(img)
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
#
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
im2.save(img)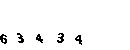
次に、キャプチャを数値にカットして、10 * 10の単一サイズに変換する必要があります。
まず、キャプチャを数字にカットします。次に、キャプチャがOY軸に沿ってシフトするため、不要なものをすべてトリミングし、画像を90°回転させる必要があります。
def crop(im2):
inletter = False
foundletter = False
start = 0
end = 0
count = 0
letters = []
name_slise=0
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
# OX
if foundletter == False and inletter == True:
foundletter = True
start = y
# OX
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter = False
for letter in letters:
#
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
# 90°
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
#
for y in range(im3.size[0]): # slice across
for x in range(im3.size[1]): # slice down
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
#
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
#
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
resized_img.save(path+name_slise+'.png')
name_slise+=1
「もう時間です、18:00、この問題を終わらせる時です」と私は思いました。
画像の拡張マトリックスを入力として受け入れる単純なモデルを宣言します。
これを行うには、画像のサイズが10 * 10であるため、100ニューロンの入力レイヤーを作成します。出力層として10個のニューロンがあり、それぞれが0から9までの数字に対応します。
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation, BatchNormalization, AveragePooling2D
from tensorflow.keras.optimizers import SGD, RMSprop, Adam
def mnist_make_model(image_w: int, image_h: int):
# Neural network model
model = Sequential()
model.add(Dense(image_w*image_h, activation='relu', input_shape=(image_h*image_h)))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])
return model
データをトレーニングセットとテストセットに分割します。
list_folder = ['0','1','2','3','4','5','6','7','8','9']
X_Digit = []
y_digit = []
for folder in list_folder:
for name in glob.glob('path'+folder+'/*.png'):
im2 = Image.open(name)
X_Digit.append(np.array(im2))
y_digit.append(folder)それをトレーニングセットとテストセットに分けます。
from sklearn.model_selection import train_test_split
X_Digit = np.array(X_Digit)
y_digit = np.array(y_digit)
X_train, X_test, y_train, y_test = train_test_split(X_Digit, y_digit, test_size=0.15, random_state=42)
train_data = X_train.reshape(X_train.shape[0], 10*10) # 100
test_data = X_test.reshape(X_test.shape[0], 10*10) # 100
# 10
num_classes = 10
train_labels_cat = keras.utils.to_categorical(y_train, num_classes)
test_labels_cat = keras.utils.to_categorical(y_test, num_classes)
モデルをトレーニングします。
エポックの数と「バッチ」のサイズのパラメーターを経験的に選択します。
model = mnist_make_model(10,10)
model.fit(train_data, train_labels_cat, epochs=20, batch_size=32, verbose=1, validation_data=(test_data, test_labels_cat))
重みを節約します。
model.save_weights("model.h5")
11番目のエポックでの精度は優れていることが判明しました:精度= 1.0000。満足して、私は19:00に家に帰って休憩します。明日は、CECWebサイトから情報を収集するためのパーサーを作成する必要があります。
翌日の朝。
問題は小さいままで、CEC Webサイトのすべてのページを調べて、データを取得する必要があります。
トレーニング済みモデルの重みをロードします。
model = mnist_make_model(10,10)
model.load_weights('model.h5')
captchaを保存する関数を記述します。
def get_captcha(driver):
with open('snt.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
im2 = Image.open('path/snt.png')
return im2
captcha予測のための関数を書いてみましょう:
def crop_predict(im):
list_cap = []
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
inletter = False
foundletter=False
start = 0
end = 0
count = 0
letters = []
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter=False
for letter in letters:
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
for y in range(im3.size[0]):
for x in range(im3.size[1]):
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
img_arr = np.array(resized_img)/255
img_arr = img_arr.reshape((1, 10*10))
list_cap.append(model.predict_classes([img_arr])[0])
return ''.join([str(elem) for elem in list_cap])
テーブルをダウンロードする関数を追加します。
def get_table(driver):
html = driver.page_source #
soup = BeautifulSoup(html, 'html.parser') # " "
table_result = [] #
tbody = soup.find_all('tbody') #
list_tr = tbody[1].find_all('tr') #
ful_name = list_tr[0].text #
for table in list_tr[3].find_all('table'): #
if len(table.find_all('tr'))>5: #
for tr in table.find_all('tr'): #
snt_tr = []#
for td in tr.find_all('td'):
snt_tr.append(td.text.strip())#
table_result.append(snt_tr)#
return (ful_name, pd.DataFrame(table_result, columns = ['index', 'name','count']))
9月13日のすべてのリンクを収集します。
df_table = []
driver.get('http://www.vybory.izbirkom.ru')
driver.find_element_by_xpath('/html/body/table[2]/tbody/tr[2]/td/center/table/tbody/tr[2]/td/div/table/tbody/tr[3]/td[3]').click()
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
list_a = soup.find_all('table')[1].find_all('a')
for a in list_a:
name = a.text
link = a['href']
df_table.append([name,link])
df_table = pd.DataFrame(df_table, columns = ['name','link'])
13:00までに、すべてのページをトラバースしてコードの記述を終了します。
result_df = []
for index, line in df_table.iterrows():#
driver.get(line['link'])#
time.sleep(0.6)
try:#
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:#
pass
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
if soup.find('select') is None:#
time.sleep(0.6)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
for i in range(len(soup.find_all('tr'))):#
if '\n \n' == soup.find_all('tr')[i].text:# ,
rez_link = soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
time.sleep(0.6)
try:
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)#
head_name = line['name']
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
else:# ,
options = soup.find('select').find_all('option')
for option in options:
if option.text == '---':#
continue
else:
link = option['value']
head_name = option.text
driver.get(link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html2 = driver.page_source
second_soup = BeautifulSoup(html2, 'html.parser')
for i in range(len(second_soup.find_all('tr'))):
if '\n \n' == second_soup.find_all('tr')[i].text:
rez_link = second_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
if second_soup.find('select') is None:
continue
else:
options_2 = second_soup.find('select').find_all('option')
for option_2 in options_2:
if option_2.text == '---':
continue
else:
link_2 = option_2['value']
child_name = option_2.text
driver.get(link_2)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html3 = driver.page_source
thrid_soup = BeautifulSoup(html3, 'html.parser')
for i in range(len(thrid_soup.find_all('tr'))):
if '\n \n' == thrid_soup.find_all('tr')[i].text:
rez_link = thrid_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
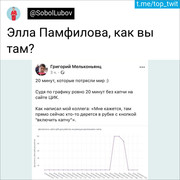
そして、私の人生を変えたツイートが来る