ロシア農業銀行の金融技術開発センターのサイトで、コンテンツのモデレートに関する一連の記事を続けています。前回の記事では、農家のエコシステムのサイトの1つである「OwnFarming」のテキストモデレーションの問題をどのように解決したかについて説明しました。サイト自体と、ここで得られた結果について少し読むことができます。
つまり、単純な分類子(辞書によるフィルター)とBERTのアンサンブルを使用しました。辞書フィルターを通過したテキストはBERTに入ることが許可され、そこでもチェックされました。
また、MIPTラボと協力して、サイトの改善を続け、グラフィック情報の事前モデレーションというより困難なタスクを設定しています。自然言語を処理する場合、ニューラルネットワークモデルを使用せずに実行できるため、このタスクは前のタスクよりも難しいことが判明しました。画像を使用すると、すべてがより複雑になります。ほとんどのタスクは、ニューラルネットワークとその正しいアーキテクチャの選択を使用して解決されます。しかし、このタスクで、私たちに思われるように、私たちはうまく対処しました!そして、これから得たものを読んでください。

私たちが欲しいもの?
じゃ、行こう!画像モデレートツールがどうあるべきかをすぐに定義しましょう。テキストモデレートツールと同様に、これは一種の「ブラックボックス」である必要があります。商品の販売者がサイトにアップロードした画像を入力として送信することにより、この画像がサイトでの公開にどのように受け入れられるかを理解したいと思います。したがって、タスクを取得します。画像がサイトでの公開に適しているかどうかを判断することです。
画像の事前モデレートのタスクは一般的ですが、解決策はサイトごとに異なることがよくあります。したがって、内臓の画像は医療フォーラムでは受け入れられるかもしれませんが、ソーシャルメディアには適していません。または、たとえば、カットされた動物の死骸の画像は、それらが販売されているWebサイトで受け入れられますが、オンラインでSmesharikovを見る子供たちに好かれることはほとんどありません。当サイトは農産物(野菜・果物、動物飼料、肥料等)の画像で構いません。一方、私たちの市場のテーマは、さまざまなわいせつまたは不快なコンテンツを含む画像の存在を意味するものではないことは明らかです。
まず、問題の既知の解決策に精通し、それらを私たちのサイトに適応させることにしました。原則として、グラフィカルコンテンツのモデレートの多くのタスクは、パブリックドメインにデータセットがあるNSFWクラスの問題を解決することになります。 NSFWの問題を解決するために、原則として、ResNetに基づく分類子が使用されます。これは93%を超える品質精度を示します。元のNSFW分類子のエラーマトリックス
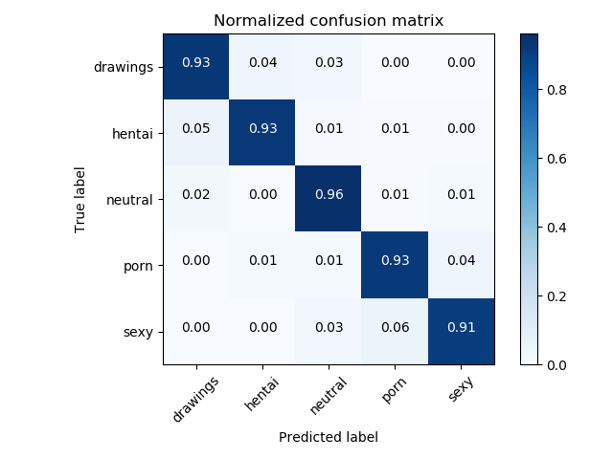
さて、NSFWの優れたモデルと既製のデータセットがあるとしましょう。しかし、これでサイトの画像の受容性を判断するのに十分でしょうか?それは判明しませんでした。NSFWモデルでこの最初のアプローチについてサイト所有者と話し合った後、もう少しカテゴリを定義する必要があることに気付きました。
- ( , )
- ( , , , . )
- ( )
つまり、独自のデータセットを作成し、他のどのモデルが役立つかを考える必要がありました。
ここで、一般的な機械学習の問題、つまりデータの不足に遭遇します。これは、私たちのサイトがそれほど前に作成されたものではなく、否定的な例がない、つまり許容できないとマークされているためです。それを解決するために、数ショットの学習方法が私たちの助けになります。この方法の本質は、たとえば、組み立てた小さなデータセットでResNetを再トレーニングし、小さなデータセットのみを使用して分類子を最初から作成した場合よりも高い精度を得ることができることです。
どうやってやったの?
以下は、入力画像から始まり、リンゴの画像が入力に供給された場合にさまざまなカテゴリを検出した結果で終わる、ソリューションの一般的なスキームです。

ソリューションの一般的なスキームスキームの
各部分をより詳細に検討してみましょう。
ステージ1:落書き検出器
パッケージにテキストが記載された商品が当サイトに読み込まれることを期待しており、それに応じて、碑文を検出し、その意味を特定するタスクが発生します。
最初の段階では、OpenCVテキスト検出ライブラリを使用してパッケージのラベルを検索しました。
OpenCVテキスト検出は、Python用の光学文字認識(OCR)ツールです。つまり、画像に埋め込まれたテキストを認識して「読み取り」ます。

EAST検出器の動作例
写真に碑文の検出例があります。バウンディングボックスを識別するために、EASTモデルを使用しましたが、このモデルは英語のテキストを認識するようにトレーニングされており、画像ではテキストがロシア語であるため、読者はキャッチを感じるかもしれません。そのため、さらに、データに必要な品質にトレーニングされたResNetに基づくバイナリ分類モデル(グラフフィティ/グラフィティではない)を使用します。このモデルがアーキテクチャを選択する際に最適であることが証明されたため、ResNet-18を採用しました。
私たちの仕事では、碑文が商品のパッケージの碑文である写真と落書きを区別したいと思います。そのため、テキスト付きのすべての写真をグラフィティと非グラフィティの2つのクラスに分割することにしました。
得られたモデルの精度は、事前に延期されたサンプルで95%でした。
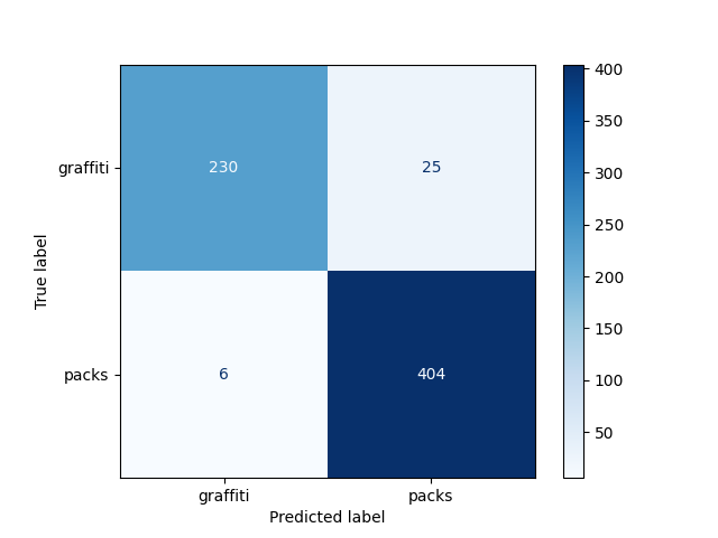
グラフィティディテクタのバグマトリックス
悪くない!これで、写真のテキストを分離し、公開に適しているかどうかを十分に理解できるようになりました。しかし、写真にテキストがない場合はどうなりますか?
ステージ2:NSFW検出器
写真にテキストが見つからない場合でも、それが受け入れられないという意味ではありません。したがって、さらに、画像のコンテンツがサイトのテーマにどのように対応しているかを評価したいと思います。
この段階でのタスクは、画像を次のカテゴリの1つに割り当てることです。
- 薬物
- ポルノ(ポルノ)
- 動物
- 拒否を引き起こす可能性のある写真(図面を含む)(gore / drawing_gore)
- 変態(変態)
- ニュートラル画像(ニュートラル)
モデルがカテゴリだけでなく、その中のアルゴリズムの信頼度も返すことが重要です。
NSFWベースのモデルが分類に使用されました。彼女は写真を7つのクラスに分け、そのうちの1つだけがサイトで見られるように訓練されています。したがって、ニュートラルな写真のみを残します。
このようなモデルの結果は、97%(精度の観点から)

NSFW検出器エラーマトリックスです。
ステージ3:人の検出器
しかし、NSFWをフィルタリングする方法を学んだ後でも、問題は解決されたとは見なされません。たとえば、人物の写真はNSFWカテゴリにもテキスト付きの写真にも分類されませんが、そのような画像をサイトに表示したくありません。次に、人間の検出モデルであるシングルショット検出器(以下、SSDと呼びます)をアーキテクチャに追加しました。
人やその他の既知のオブジェクトを選択することも、さまざまなアプリケーションで人気のあるタスクです。pytorchの既製のnvidia_ssdモデルを使用しました。

SSDアルゴリズムの例
モデルの結果は低くなります(精度-96%):

人間の検出器のエラーマトリックス
結果
加重F1、精度、リコールのメトリックを使用して、機器の品質を評価しました。結果を表に示します。
| 指標 | 得られた精度 |
| 加重F1 | 0.96 |
| 加重精度 | 0.96 |
| 加重リコール | 0.96 |
そしてここにその仕事のいくつかのより実例となる例があります:
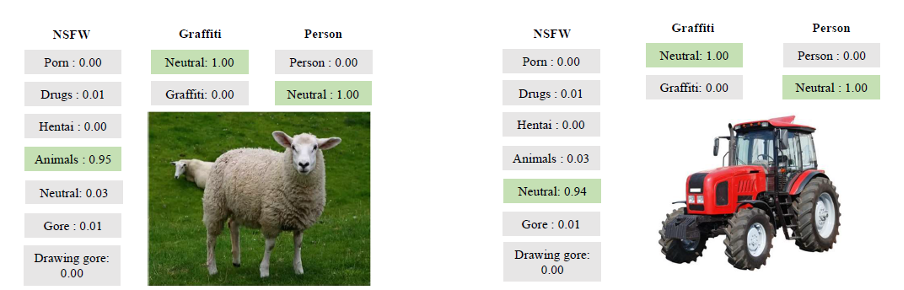
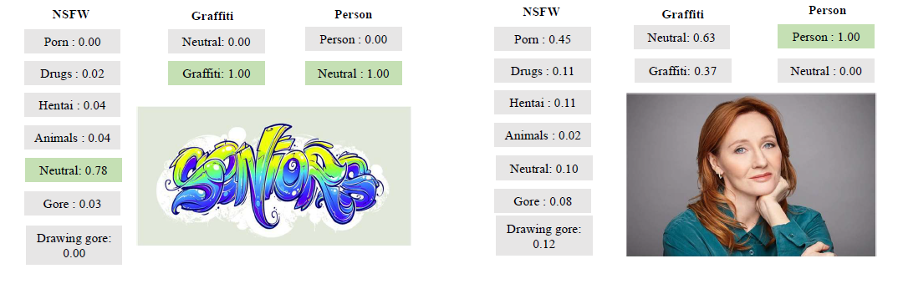
ツールの例
結論
解決の過程で、コンピュータビジョンタスクによく使用されるモデルの「動物園」全体を使用しました。写真からテキストを「読み」、人を見つけ、不適切なコンテンツを区別することを学びました。
最後に、検討された問題は、経験を積み、修正された古典的なモデルを使用するという観点から有用であることに注意したいと思います。これが私たちが得た洞察のいくつかです:
- 数ショットの学習方法を使用して、データ不足の問題を回避できます。大規模なモデルは、独自のデータで必要な精度にトレーニングできます。
- : ,
- , ,
- , , . , , ,
- 画像モデレートのタスクは非常に人気がありますが、テキストの場合と同様に、それぞれが異なるオーディエンス向けに設計されているため、そのソリューションはサイトごとに異なる場合があります。たとえば、私たちの場合、不適切なコンテンツに加えて、動物や人も検出しました
ご清聴ありがとうございました。次の記事でお会いしましょう!