一般的な信念によれば、PDFからテキストを抽出することはそれほど難しくないはずです。結局のところ、これが私たちの目の前にあるテキストであり、人々は絶えずそして大成功を収めてPDFのコンテンツを認識しています。自動テキスト抽出の難しさはどこから来るのですか?多くのエッジケースと誤った仮定のためにアルゴリズムで人の名前を操作するのが難しいのと
同じように、PDF形式の極端な柔軟性のためにPDFを操作するのは難しいことがわかりました。 主な問題は、PDFがデータ入力の形式として意図されていなかったことです。PDFは出力チャネルとして開発され、最終的なドキュメントの外観を微調整できるようになりました。
基本的に、PDF形式は、ページ上で画像がどのように作成されるかを説明する一連の指示で構成されます。特に、テキストデータは、段落(または単語)としてではなく、ページの特定の場所に描画された文字として保存されます。その結果、テキストまたはWordドキュメントをPDFに変換すると、コンテンツのセマンティクスのほとんどが失われます。テキストの内部構造全体が、ページに浮かぶ文字の無定形のスープに変わります。
FilingDBに入力することで、何万ものPDFドキュメントからテキストデータを抽出しました。その過程で、PDFファイルの構造に関するすべての仮定がどのように間違っているかを観察しました。私たちの使命は、まったく異なるスタイル、フォント、外観のさまざまなソースからのPDFドキュメントを処理する必要があったため、特に困難でした。
以下では、PDFファイルのどの機能が、PDFファイルからテキストを抽出することを困難または不可能にするかについて説明します。
PDF読み取り保護
テキストコンテンツのコピーを禁止しているPDFファイルに出くわしたことがあるかもしれません。たとえば、これは、コピーで保護されたドキュメントからテキストをコピーしようとしたときにSumatraPDFプログラムが生成するものです。

興味深いことに、テキストは表示されますが、視聴者は選択したテキストをクリップボードに転送することを拒否します。
これは、いくつかの「アクセス許可」フラグで実現され、そのうちの1つがコピー許可を制御します。PDFファイル自体がこれを強制しないことを理解することが重要です-その内容はこれから変更されず、その実装のタスクは完全にビューアにあります。
当然、これはPDFからのテキストの抽出を実際に防ぐものではありません。これは、PDFを操作するための十分に高度なライブラリを使用すると、ユーザーがこれらのフラグを変更するか無視することができるためです。
ページ外の文字
多くの場合、PDFには、ページに表示されているよりも多くのテキストデータが含まれています。Nestleの2010年年次報告書からこのページをご覧ください。
このページには、表示されているよりも多くのテキストが添付されています。特に、それに関連するコンテンツには次のものがあります。
KitKatは2010年に75周年を迎えましたが、250万人を超えるFacebookファンがいて、若くてトレンディなままです。その製品は70か国以上で販売されており、先進国や中東、インド、ロシアなどの新興市場で売上が伸びています。日本は同社の2番目に大きな市場です。
このテキストはページ外であるため、ほとんどのPDFビューアには表示されません。ただし、データはそこにあり、プログラムで取得できます。
これは、承認プロセス中にテキストを置換または削除する直前の決定が原因で発生する場合があります。
小さい文字または見えない文字
場合によっては、非常に小さい文字や見えない文字がPDFページに表示されることがあります。たとえば、これは2012Nestleレポートのページです。

このページには、白い背景に次のような小さな白いテキストがあります。
WyethNutritionロゴ市場へのアイデンティティガイダンス
VeveyOctobre 2012 RCC / CI&D
これは、HTMLのaltタグと同じ目的で、アクセシビリティを向上させるために行われることがあります。
スペースが多すぎます
PDFの単語の文字の間に追加のスペースが挿入されることがあります。これはおそらくカーニングの目的で行われます(文字間の間隔を変更する)。
たとえば、2013 Hikma Pharmaレポートには、次のテキストが含まれています。

コピーすると、次のようになります。
ch a i r m a n ' s s tat em en t一般に、元のテキストの再構築の問題を解決することは困難です。私たちの最も成功したアプローチは、光学的文字認識、OCRを使用することです。
スペースが足りません
PDFにスペースがないか、別の文字に置き換えられている場合があります。
例1:次の抜粋はSEB Annual Report 2017から

抜粋したものです。抜粋したテキスト:
Tenyearsafterthefinancialcrisisstarted例2:Eurobank 2013レポートには、次のものが含まれています。

抽出されたテキスト:
On_April_7,_2013,_the_competent_authorities繰り返しますが、OCRはこれらのページに最適です。
組み込みフォント
PDFは、穏やかに言えば、複雑な方法でフォントを処理します。テキストデータがPDFにどのように保存されるかを理解するには、最初にグリフ、グリフ名、およびフォントを理解する必要があります。
- グリフは、文字や文字の描き方を説明する一連の指示です。
- – , . , « » ™ «» «».
- – . , , , «», .
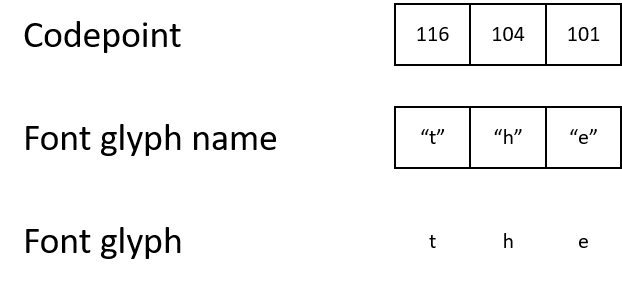
PDFでは、文字は数字、文字コード[コードポイント]として保存されます。画面に何を表示する必要があるかを理解するには、レンダラーは文字コードからグリフの名前、そしてグリフ自体までのチェーンをたどる必要があります。
たとえば、PDFには文字コード116が含まれている場合があります。このコードは、グリフ「t」の名前にマップされ、グリフ「t」の表示方法を説明するグリフにマップされます。
ほとんどのPDFは標準の文字エンコーディングを使用します。文字エンコーディングは、文字コード自体に意味を割り当てる一連のルールです。例えば:
- ASCIIおよびUnicodeは、文字コード116を使用して文字「t」を表します。
- Unicodeは、文字コード9786を☺として表示されるグリフ「whitesmiley」にマップしますが、ASCIIはそのようなコードを定義していません。
ただし、PDFドキュメントでは、独自の文字エンコーディングと特殊なフォントが使用される場合があります。奇妙に聞こえるかもしれませんが、ドキュメントは文字コード1で文字「t」を示している場合があります。文字コード1をグリフ名「c1」にマップします。グリフ名は文字「t」の表示方法を説明するグリフにマップされます。
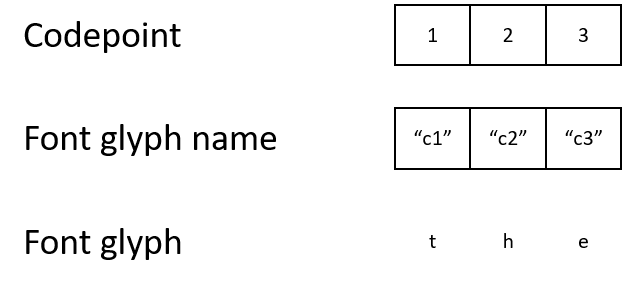
最終結果は人間と同じですが、マシンはこれらの文字コードによって混乱します。文字コードが標準のエンコーディングと一致しない場合、コード1、2、または3の意味をプログラムで理解することはほとんど不可能です
が、PDFに非標準のフォントとエンコーディングが含まれるのはなぜですか?
- 1つの理由は、テキストの抽出を困難にすることです。
- – . , PDF . PDF , .
これを回避する1つの方法は、ドキュメントからフォントグリフを抽出し、それらをOCRで実行して、フォントをUnicodeにマップすることです。これにより、フォント関連のエンコーディングをUnicodeに変換できます。たとえば、文字コード1は名前「c1」に対応します。グリフによれば、これは「t」を意味し、Unicodeコード116に対応し
ます。完了(番号1と116に一致するもの)は、PDF標準ではToUnicodeカードと呼ばれます。PDFドキュメントには独自のToUnicodeカードを含めることができますが、これは必須ではありません。
単語や段落の認識
PDFの無定形の象徴的なスープから段落や単語さえも再構築することは困難な作業です。
PDFドキュメントには、ページ上の文字のリストが含まれており、単語や段落を認識するのは消費者の責任です。読書は一般的なスキルであるため、人間はこれで自然に効果的です。
最も一般的に使用されるグループ化アルゴリズムは、文字のサイズ、位置、および配置を比較して、単語または段落が何であるかを判別することです。
このようなアルゴリズムの最も単純な実装では、O(n²)の複雑さに簡単に達する可能性があり、密集したページの処理に長い時間がかかる可能性があります。
テキストと段落の順序
テキストと段落の順序を認識することは、2つの理由で困難です。
まず、正しい答えがない場合があります。 1列の通常の活字セットを持つドキュメントは自然な読み取りシーケンスを持ちますが、要素のより大胆な配置を持つドキュメントは決定するのがより困難です。たとえば、次の挿入が、それが配置されている記事の前、後、または途中にあるべきかどうかは完全には明確ではありません。

第2に、答えが人に明らかな場合でも、コンピューターは、AIを使用しても、段落の正確な順序を決定するのが非常に難しい場合があります。この声明は少し大胆に感じるかもしれませんが、場合によっては、正しい段落の順序は、テキストの内容を理解することによってのみ決定できます。
野菜サラダの準備を説明する2つの列のコンポーネントのこの配置を検討してください。

西洋の世界では、読書は左から右へ、そして上から下へと仮定するのが合理的です。したがって、テキストの内容を調べなくても、すべてのオプションをABCDとACB Dの2つに減らすことができます。
内容を調べて内容を理解し、スライスする前に野菜が洗浄されることを知った後、正しい順序はACBDであることがわかります。これをアルゴリズムで決定することは非常に困難です。
この場合、「ほとんどの場合」、テキストがPDFドキュメント内に格納される順序に依存するアプローチが機能します。通常、作成時にテキストが挿入される順序に従います。テキストの大きなチャンクに多くの段落が含まれている場合、それらは通常、作成者が意図した順序に従います。
埋め込まれた画像
多くの場合、ドキュメントのコンテンツの一部(またはドキュメント全体)がスキャンされた画像であることが判明します。このような場合、テキストデータは含まれないため、OCRを使用する必要があります。
たとえば、2011 Yell AnnualReportはスキャンとしてのみ利用できます。

なぜすべてを認識しないのですか?
OCRは、説明されている問題のいくつかに役立ちますが、欠点もあります。
- 処理時間が長い。PDFからのスキャンでOCRを実行すると、通常、PDFから直接テキストを抽出するよりも1桁長く(またはさらに長く)かかります。
- 非標準の文字とグリフの問題。OCRアルゴリズムが新しい文字(絵文字、アスタリスク、円、正方形(リスト内)、上付き文字、複雑な数学記号など)を処理することは困難です。
- . , PDF-, , . .
これまでのところ、テキストが正しくまたは期待どおりに抽出されたことを確認することがどれほど難しいかについてはまだ触れていません。基本的な指標(テキストの長さ、ページの長さ、単語とスペースの比率)とより複雑な指標(英語の単語の割合、認識されない単語の割合、数字の割合)の両方を調査し、監視する一連の広範なテストを実行するのが最善であることがわかりました。疑わしい文字や予期しない文字などの警告。
PDFからテキストを抽出するために何をお勧めできますか?まず、テキストにもっと便利なソースがないことを確認してください。
関心のあるデータがPDF形式のみである場合、この問題は一見単純に見えるだけであり、100%の精度で解決できない可能性があることを理解することが重要です。