Libra(THIS IS ME!)が最後の場所にあることに悲しみを込めて注意します...データによると、異常があるように思われますが。どういうわけか疑わしい小さなLibra!
パート1。初期データの解析と取得
ウィキペディア
出力にあるリストのリストのリストには、フルネーム+生年月日+(m / f、国など、他の記号がある場合)のベースが必要です。APIがあります。
このサイトは、Python Scrapyライブラリを使用してスクレイプ(Webリソースから取得したデータの収集/取得/抽出(抽出)/収集)サイトであることが判明しました。
詳細な手順は、
最初に取得したリンク(Wikipediaのユーザーとのシート、次にデータ)です。
他の場合では、彼らはこのようにうまく解析しました。
結果:BDファイルwiki.zip
パート2。前処理について(Stanislav Kostenkovによる-以下の連絡先)
多くの人々は、入力データの処理の複雑さに直面しています。したがって、このタスクでは、42,000を超える記事から出生データを引き出し、可能であれば、出生国を決定する必要がありました。一方では、これは単純なアルゴリズムタスクですが、他方では、ExcelおよびBIシステムのツールでは、「正面から」実行することはできません。
そのような瞬間に、プログラミング言語(Python、R)が助けになり、その立ち上げはほとんどのBIシステムで提供されています。たとえば、Power BIでは、Pythonでスクリプト(プログラム)を実行するのに30分の制限があることに注意してください。したがって、多くの「重い」処理は、たとえばデータレイクで、BIシステムの起動前に実行されます。
問題がどのように解決されたか
ダウンロードして間違った値をチェックした後、最初にしたことは、各記事を単語のリストに変換することでした。
このタスクでは、私は英語という言語で幸運でした。この言語は、文の厳密な構成が特徴であり、生年月日の検索が非常に容易になりました。ここでのキーワードは「生まれた」であり、その後の内容を調べて分析します。
一方、すべての記事は1つのソースから取得されたため、タスクも簡単になりました。すべての記事はほぼ同じ構造と速度でした。
さらに、すべての年は4文字の長さで、すべての日付は1〜2文字の長さで、月はテキストでした。生年月日の綴りには3〜4のバリエーションしかなく、単純な論理で解決されました。また、通常の式を使用して解析することもできます。
実際のコードは最適化されていません(そのようなタスクは設定されていません。変数の名前に欠陥がある可能性があります)。
国の予想通り、国や国籍の対応表を見つけてラッキーでした。通常、記事は国ではなく、国に属することを説明しています。たとえば、ロシア-ロシア語。そのため、国籍の出現を検索しましたが、1つの記事に5つ以上の異なる国籍が含まれる可能性があるため、目的の単語がキーワード「burn」に可能な限り最も近いと仮定しました。したがって、基準は、記事内の必要な単語間の最小インデックス距離でした。その後、1行が国籍から国に名前が変更されました。
行われなかったこと
記事では、多くの単語がゴミでした。つまり、コードの一部が単語に接続されているか、2つの単語がマージされていました。したがって、そのような単語で目的の値を見つける可能性はチェックされませんでした。類似性アルゴリズムを使用して、これらの単語をクリーンアップできます。
「burn」キーワードが属するエンティティは分析されませんでした。キーワードが親戚の誕生に関連しているいくつかの例がありました。これらの例はごくわずかでした。これらの例は、キーワードが記事の冒頭から遠く離れているという事実にまでさかのぼることができます。キーワードを見つけるための百分位数を計算し、クリッピング基準を定義できます。
データをクリーニングする際の前処理の有用性について一言
ギャップの代わりに何をすべきかを正確に推測できる場合があります。ただし、店舗購入者の性別による記載漏れや購入データなどの場合もあります。BIシステムでこの問題を解決するための標準的な手法はありませんが、同時に、前処理レベルで「軽い」モデルを作成し、ギャップを埋めるためのさまざまなオプションを確認できます。単純な機械学習アルゴリズムに基づく塗りつぶしオプションがあります。そして、それは使用する価値があります。難しいことではありません。
ソースコード(Python)はリンクから入手できます。
結果:ファイルout_data_fin.xls
Stanislav Kostenkov / CBS Consulting(Izhevsk、ロシア)staskostenkov@gmail.com
パート3。QlikSenseアプリ
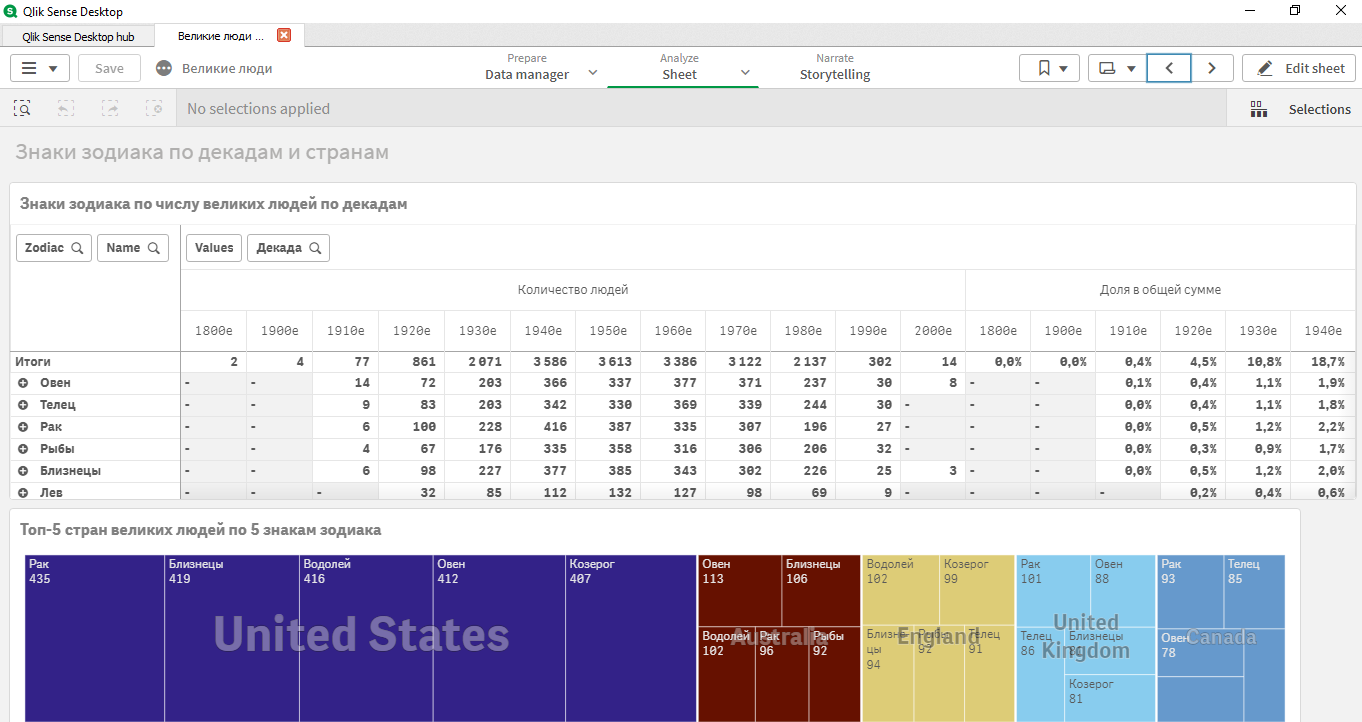
次に、古典的なアプリケーションが作成され、データセットのいくつかの異常が明らかになりました。
- 1920年から1980年までの数十年だけを選択することは理にかなっています。
- さまざまな国で、星占いの兆候に応じてさまざまな指導者がいました。
- トップサイン:Cancer、Aries、Gemini、Taurus、Capricorn。
すべてのデータ(データセット、生データ、データ分析のためにQlik Senseアプリによって受信されたもの)は、参照によって検索されます。