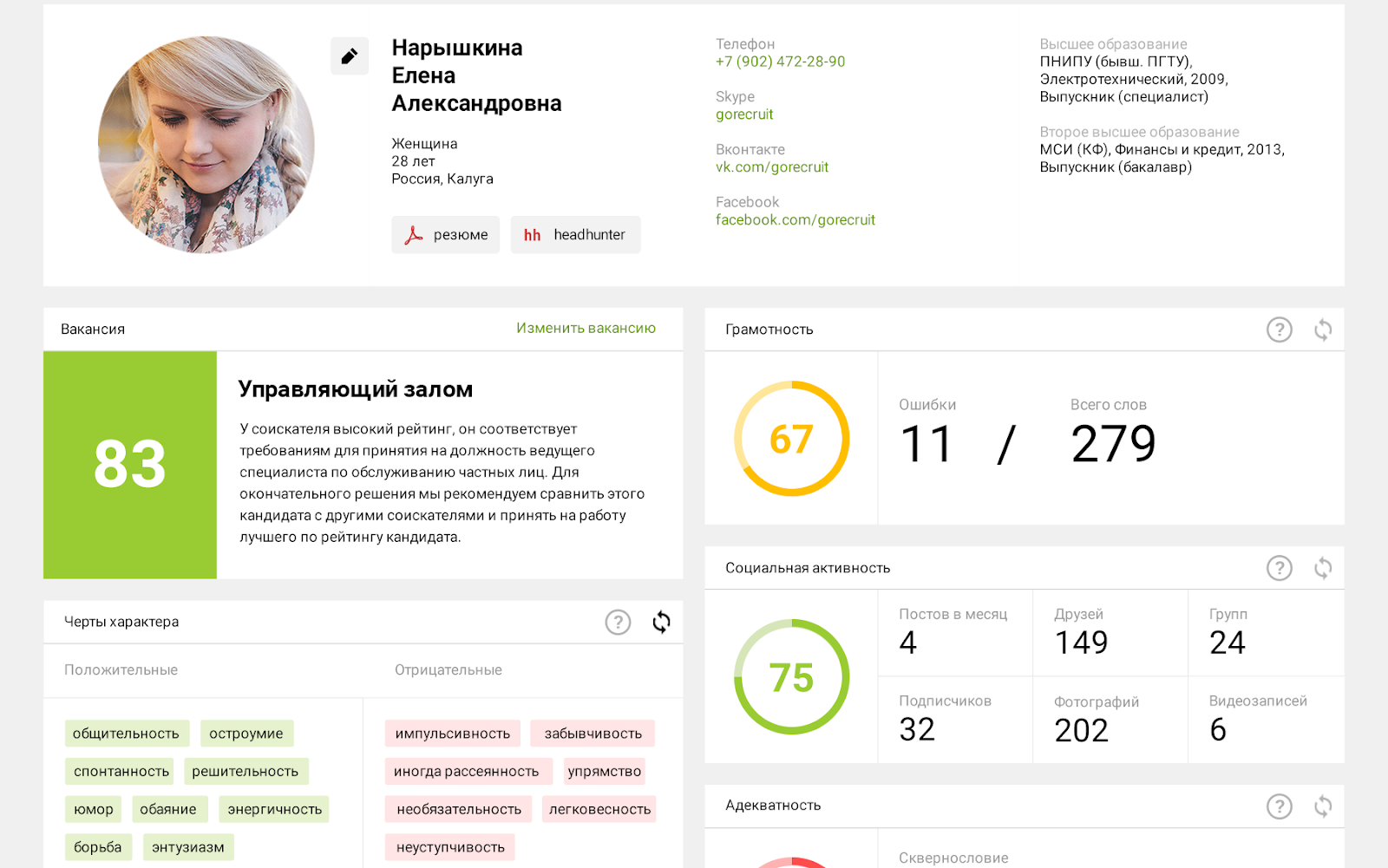
ITスペシャリストの検索では、この領域は特定のものであり、ここでは採用担当者が他のツールを使用するため、このようなスキームはまだ特に適用できません。残りの部分については、特に欠員に対する回答者が100人を超える場合は、非常に話題になります。
アレクサンダーバラバッシュは、サービスがどのように機能するか、そして人事担当者の論理は何であるかについて私たちに話しました。正式には、彼はGoRecruitのディレクターですが、同時に開発に直接関係しています。
REM AI-. Awtor (https://habr.com/ru/company/leader-id/blog/521378/), iPavlov (https://habr.com/ru/company/leader-id/blog/522624/) OpenTalks.AI (https://habr.com/ru/company/leader-id/blog/523448/).-GoRecruitとは何ですか、どのように機能しますか?
-これは、ソーシャルネットワークを含むレジュメやオープンソースからのデータの分析に基づいて人事決定をサポートするためのシステムです。特定の職業に応募する応募者の評価を計算し、採用担当者の人件費を削減します。
アナログとの根本的な違いは、評価に参加するために、申請者は欠員に対応し、独立して履歴書をアップロードするか、ソーシャルネットワークのプロファイルからログインする必要があることです。私の意見では、これは非常に重要な論理です。一部のサービスは、求職者向けのコールド検索ツールを提供します。これらのサービスは、疑いを持たない人々のプロファイルからオープンデータを取得します。これは、ソーシャルメディアポリシーと矛盾する場合があります。それは正しくありません。データは、承認(つまり、ユーザーの同意)後にのみ取得し、履歴書や、連邦保安局、内務省の拠点、税務署などのオープンソースからのデータで補足します。システムの最終的なタスクは、人事部門とセキュリティ担当者向けの詳細なレポートを生成することにより、申請者に関するデータを充実させることです。
他の情報の中でも、このレポートには、選択された欠員における特定の候補者の期待される成功を特徴付ける評価が含まれています。採用担当者は、この評価を次にどうするかを決定します。
-比較のために欠員をどのように説明しますか?そして、人工知能はどこにありますか?
-実際、今よく話題になっている人工知能は、統計データを外挿する方法です。しかし、何かを推定するには、十分な量の初期情報が必要です。人員の移動に関する統計データが存在する大企業の場合、ニューラルネットワークを使用してこのデータに基づいて空室モデルを構築します。
実際、特定のポジションで成功している会社の従業員に関する情報を分析します。その結果、レポートでの候補者の評価は、この会社の経験に基づいて計算されます(この会社で同様の役職に就いた他の人々との比較に基づいて)。
モデルを構築するのに統計データでは不十分な中小企業の場合、エキスパートシステムを使用します。このシステムの数学的モデルは、専門家の専門家の意見に基づいており、意思決定における人間の思考の過程に取って代わります。このアプローチは、ビジネスに独自の統計がない場合に正当化されます。時間の経過とともに、これらのモデルを開発します。必要に応じて調整します。
-ニューラルネットワークモデルについて話す場合、この位置またはその位置での人の「成功」はどのように評価されますか?
-そして、これは私たちの仕事の微妙な点の1つです。これらの基準は会社ごとに異なります。最も簡単なオプションは、一定期間後の雇用状況です。たとえば、就職後1年経ってもこの職に就いている場合、最終的な目標は会社で長く働く問題のない人を見つけることであるため、成功したと見なすことができます。
より高度な企業には、内部HRKPIがあります。私たちはそれらを基礎としてとらえます-たとえば、70%を超える指標を持つ成功した人々を考慮します。職員の動きに関するデータを適切に選択し、職業ごとに個別に数学モデルをトレーニングします。
-このアプローチの適用性の制限は何ですか?
-厳しい制限はありません。しかし、これは統計的な方法です。データが多いほど(サンプルが豊富なほど)、予測がより正確になることは明らかです。候補者がどれだけ成功するかをより正確に言います。したがって、このソリューションは一部の大衆専門職に最適です。高いポジションやユニークなポジションについては、まだ推奨する準備ができていません。
-システムは人を探す過程でどのような場所を取りますか?
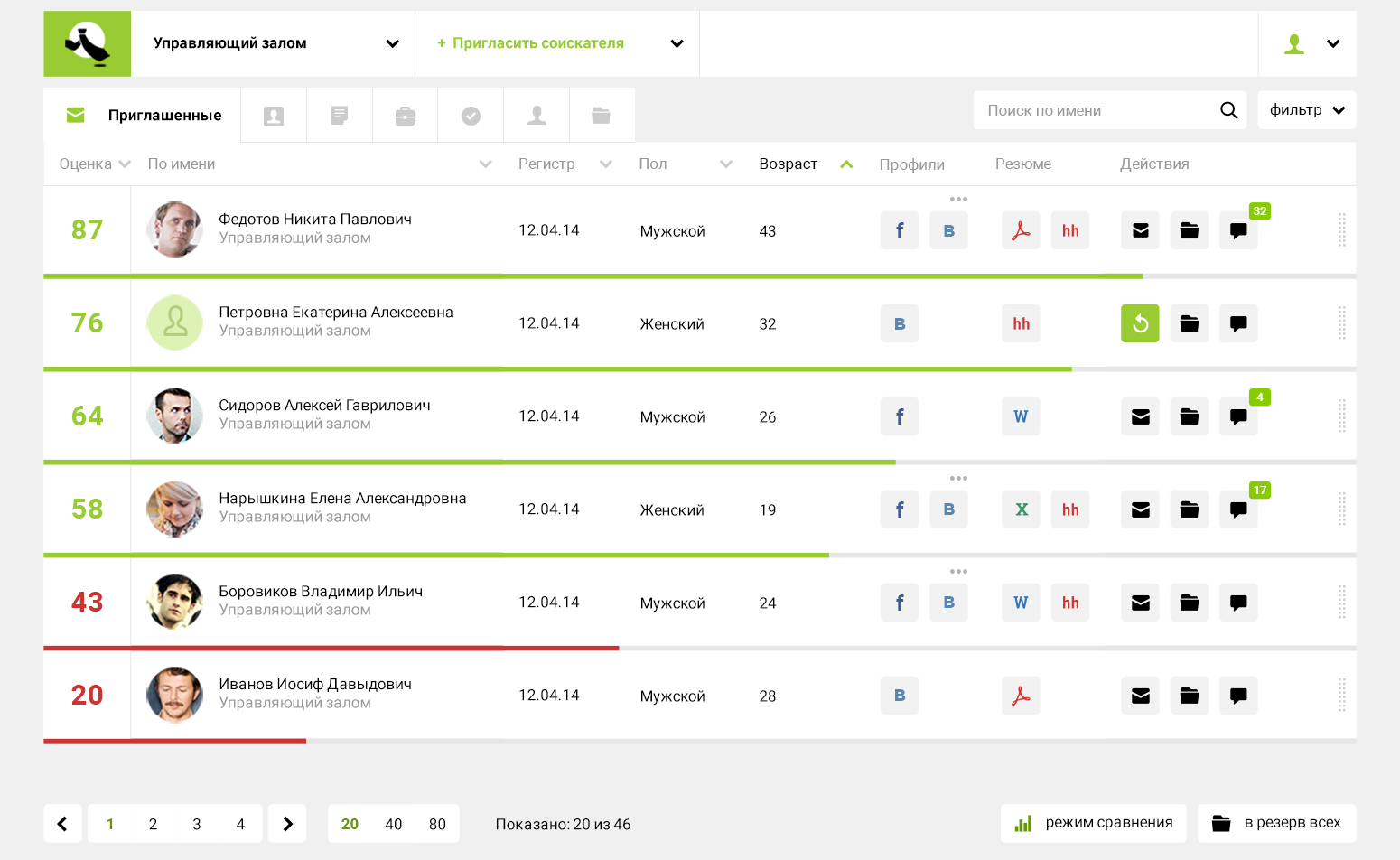
-検索は行っておりません。私たちは別のニッチを占めています。欠員について多くの回答を受け取り、誰に面接を依頼するかを決定する必要がある場合に、評価を提供します。
: . 600 . 5 , 50 , , , , .そして、私たちのシステムは5秒で答えを出します:それは評価を計算し、それによって600の再開をランク付けします。社内での人事決定の方法に応じて、すぐに次の段階に進むことができます。インタビューに招待するか、テストタスクを送信します。
実際、これは、人事の意思決定に関連する一連のアクションの中で最も時間のかかる初期フィルターです。 3人を比較するのは1つのことです。しかし、条件付き600の再開を覚えて比較することは不可能です。これは、人の身体能力を上回っています。十数を読んだ後、あなたはすでに最初に起こったことを忘れるでしょう。私たちの心理学者は、人間の脳が覚えていて、頭の中に約7〜10個のパラメーターをすばやく保存できることを繰り返すのが好きです。したがって、大きな問題は、採用担当者が1週間以内に600の再開を手動でどれだけうまく調査するかということです。
-この評価はどの程度正確に作成されていますか?履歴書からどのようなデータを取得しますか?
-私たちは組み合わせたアプローチを使用します-私たちはオントロジーエンジニアリング手法をニューラルネットワークと組み合わせます。システムは、その後の評価計算に必要な再開テキストから意味のある意味を抽出します。その人は以前どこで働いていたのか、どの役職、どの役職に就いたのか、仕事が中断したのか、どのような成功を収めたのか、どのような機能を果たしたのか、どのような教育を受けたのか、職業が教育のプロファイルに対応しているかどうかなどです。
また、重要な場合は、年齢、性別、その他の追加情報(通常の人事担当者が履歴書を読むときに見るすべてのもの)を強調します。これらの各項目はパラメーターです。通常、採用担当者はそれらを比較しますが、この比較をアルゴリズム化しただけです。
-どのような追加の情報源を使用していますか?
-内務省、FSSPなどの上記の拠点に加えて、現在、ソーシャルネットワークVKontakteを使用しています。 FacebookやTwitterの開発もありますが、VKontakteが主な情報源です。多機能センターのPCオペレーターの位置について人事決定を行うためのモデルを作成したところ、候補者の約97%がこのソーシャルネットワークにプロファイルを持っていることがわかりました。ちなみに、その時のクライアントは、VKontakteからのデータでプロファイルを充実させることが可能かどうか疑問に思っていましたが、97%の指標が彼を安心させました。
-あなたのシステムはあなたのソーシャルネットワークプロファイルに正確に何に興味がありますか?
-まず、心理的プロファイルを決定するために、人が自分のページに公開するテキストを取得します。

ペンシルベニア大学とケンブリッジの共同研究から心理型を評価するためのキーワードの例 これは一種のデータ前処理です。投稿で使用されている単語やフレーズによって個人の資質を評価します( Facebookで投稿を分析するために使用される同様の手法について詳しくは、こちら(pdf)およびこちらをご覧ください)。
Myers-Briggsの類型を使用して、16のサイコタイプの1つに人を帰します。この情報は、最終的な評価にも影響します。まったく異なる心理タイプの人々は、さまざまな職業に適しています。
さらに、もちろん、プロファイルからの情報にも関心があります。 VKontakteは、年齢、性別、教育、好み、子供など、約70のパラメーターを提供します。
-システムは人をいくつの投稿で評価できますか?猫の写真だけがソーシャルネットワークに投稿されたらどうなりますか?
-システムは奇跡を提供しません-それは通常のリクルーターのように動作します。
候補者が仕事に応募したが、履歴書に何も書かなかったとしましょう。私たちは(採用担当者のように)オープンデータを調べます-そこにも何もないとしましょう。ソーシャルネットワーク自体にプロファイルがないか、空です。
. , , .これは、人事上の決定を行うための一般的なロジックです。候補者に関する情報が表示されず、オープンソースで確認できない場合は、次の再開に進みます。
豊富な実績のある経験、優れた教育と知識、またはある種の無知を持った2人を比較するときは、おそらく自分がもっと知っている人を選ぶでしょう。
私たちのシステムはここで人間の論理を解釈します。データの欠如は、特定の方法で人を特徴付ける情報でもありますが、原則として、低い評価で使用されます。
-その結果、システムの観点から、理想的な候補者は、ソーシャルネットワーク上で公然と「彼の人生を広める」人ですか?
- 番号。ソーシャルメディアは単なるアドオンであり、基本的なデータは履歴書から取得されます。
--Habréの記事のテキストまたはGitHubのコードを分析して、プロファイルをさらに充実させていますか?
- 番号。これらは主にIT担当者向けのリソースであり、私たちはそのような焦点を持っていません。このセグメントには、ITスペシャリストの検索と評価に合わせて調整された他のツールがあります。
-システムの観点から、プラスまたはマイナスとして候補者に明確にクレジットされる要因はありますか?
-これはまさにGoRecruitのユニークな機能です。そのような要素はありません。収集されたすべてのデータは、最終決定に影響します。しかし、職業ごとに、会社ごとに、それぞれの要因の影響の程度は異なります。
数学モデルの意味は、トレーニングがどのように行われるか、つまりこれにどのデータが使用されるかによって、これらのパラメーターが変化するという事実にあります。
-モデルに取り組む過程で、何百ものレジュメが目の前を通過したに違いありません。世代の典型的な特徴を特定できますか?
-1つを除いて、おそらくそうではありません。年をとるほど、彼のバックグラウンドは豊かになります。原則として、年齢とともに、彼のキャリアパスは追跡され始め、一般的に彼についてのより多くの情報があります。
しかし、別の機能に注意することができます。フォーマットとしての再開は、一見したところよりもはるかに多様です。 HeadHunterのようなテンプレートが存在するにもかかわらず、人々は履歴書や非常に異なる表現で非常に異なるものを書きます。そしてここでは、すべてのアルゴリズムが部分的に履歴書の構造に基づいているため、意味の意味を識別する際に問題に直面しています。これは挑戦的で挑戦的な仕事です。 -Archipelago
アクセラレータ20.35を申請しました..。彼から何を得たいですか?
-これは、私たちの製品をあらゆる方向に開発するための興味深い機会だと思います。私が群島について読んだことから、それは多方向の機会を提供するので、私たちはイベントを一方的なものとして認識しません-投資家または何か他のものを探します。ここでは、開発の問題、新しい連絡先、製品のプロモーションの解決を待っており、クライアントも探します。一緒。
-あなたのチームには誰がいますか?採用担当者、開発者、数学者?
-私たちは数学者、プログラマー、心理学者のチームを持っています-技術科学と人道科学(心理学と数学)の交差点にいる人々、ビッグデータ、人工知能(機械学習)の分野の専門家。