こんにちは、私の名前はMaksimPlavchenokです。Bercutで働いています。統合テストを行っています。 9月、私のチームと私は重要なマイルストーンに合格しました。モバイルオペレーター向けの新しいバージョンの課金のリリースに関する統合テストの結果、エラーは発生しませんでした。私たちはこれに2年間行きました。今日は、どうやって目標を達成できたかをお話ししたいと思います。
統合テストの結果に基づくエラーゼロ-ここでは、オペレーター側のビジネス受け入れで新機能をテストすることについて話します。このテストがどのように機能するかについて一言。
課金ソフトウェアの新しいバージョンを年に6回、スケジュールどおりにリリースします。リリースの出荷日は事前にわかっています。この記事の執筆時点では、すでに来年全体のリリース日を予定しています。
この特異性は、市場投入までの時間に対する携帯電話事業者の競争に関連しています。主な原則:加入者は定期的に新しい課金機能を受け取る必要があります。スマートフォンを介した支払い、オペレーターの変更時に番号を節約、未使用のトラフィックを販売する機能-更新は異なる場合があります。
「1年以内に正確に何をリリースするかはわからないかもしれませんが、アップデートがリリースされる正確な日付はわかっています。」これにより、希望する更新リズムを維持することができます。
請求書作成の面では、約70人がリリースに関与しています。これらは5〜6のチームであり、それぞれが独自の専門分野を持っています:分析、開発(いくつかのチーム)、機能テスト、統合テスト。
はい、請求プロジェクトには滝があります。しかし、現在の話は、開発パラダイムを滝からアジャイルに、またはその逆に根本的に変更した方法についてではありません。それぞれの開発アプローチには独自の利点があり、適切な条件下で優れています。この議論はこの記事の範囲外にしたいと思います。今日は、進化的開発についてお話ししたいと思います。既存の開発アプローチのフレームワーク内で、リリースの受け入れ時にエラーをゼロにする方法について説明します。
不快ゾーン
説明された物語の冒頭、2年前、私たちは次の写真を持っていました:
- 開発チェーンの最後のチームは圧倒されました。「次のチームに渡す時が来ました、そして前のチームはちょうど仕事のその部分を始めました」;
- お客様は、テストサイクル後に約70のエラーを見つけることができました。
統合テストの結果に基づいて検出される可能性のあるエラーは、軽微(「メッセージの一部がダッシュで表示される」)または重大(「別の料金への移行がない」)である可能性があります。
この調整を変更することを決定しました。目標を設定しました。つまり、新しい機能のビジネス受け入れにおけるエラーはゼロです。
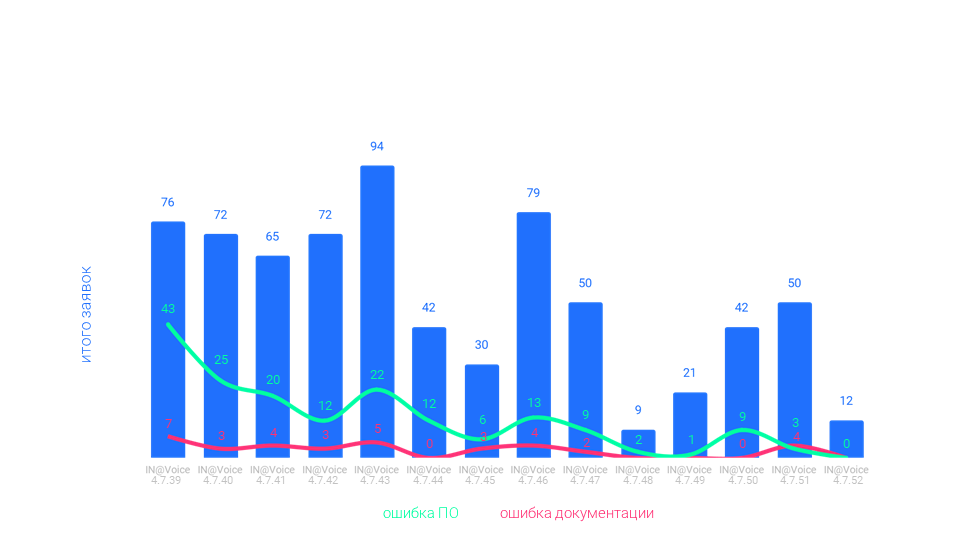
1年後、エラーの数を2020年半ばまでに10〜15に、2〜3に減らすことができました。そして9月には目標のゼロに到達することができました。
ツール、専門知識、ドキュメント、顧客との協力、チームなど、いくつかの分野での改善により成功しました。改善の重要性はさまざまです。顧客の詳細とプロセスを知ることは重要であり、タスクの複雑さを評価するための新しいスケールへの移行はオプションであり、チームのモチベーションを活用することは非常に重要です。しかし、まず最初に。
成長ポイント
主な統合テストツールはテストベンチです。そこで、サブスクライバーのアクティビティがエミュレートされます。
共有スタンド
生産からのダンプはテストベンチに転がされ、戦闘にできるだけ近い条件でテストできるようになります。
キャッチは、私たちのスタンドと顧客のスタンドのダンプが異なる可能性があるということです。オペレーターはダンプを作成して私たちに渡し、新しい機能をテストし、バグを見つけて修正します。完成した機能をお客様に提供し、反対側の同僚がテストを開始します。私たちとそのダンプは、関連性が異なる可能性があります。たとえば、オペレーターである7月にテストしました。
違いは重要ではありませんが、それでもありました。これは、顧客側でテストするときに、私たちが持っていなかったエラーが表示される可能性があるという事実につながりました。
私たちがしたこと:テストに使用されるデータスキーマは同じであり、一般的には共通の立場を持つことに同意しました。
ダンプラグは残りますが、このラグが最小になるインフラストラクチャを構成しました。これにより、テスト環境と実稼働環境の違いによるエラーの数を減らすことができました。
テスト前に設定を確認する
オペレーターに新しいバージョンのソフトウェアを提供する場合、顧客側でテストするために、設定を行う必要があります。新しい機能を構成し、場合によっては古い機能をさらにカスタマイズします。
必要な設定について説明するドキュメントを作成しました。ここでのみ、マニュアルは歪みのある情報を伝えることができました。文書は人々によって書かれ、人々によって読まれました、そして人々のコミュニケーションにおいて誤解があります。
これが当社のソフトウェアの特殊性です。柔軟性と可用性の観点から、設定に高い要求が課せられます。設定は複雑であり、追加の通信がなければ、文書だけで必要なすべての情報を伝えることが常に可能であるとは限りませんでした。
その結果、設定が常に正しく行われるとは限らず、オペレーター側でのテスト中にエラーが検出される可能性があります。分析したところ、これらはソフトウェアエラーではなく、設定であることがわかりました。そのような間違いは貴重な時間を無駄にします。
実施内容:オペレータースタンドでテストする前に、お客様側の設定を確認する手順を導入しました。
手順は次のとおりです。お客様は、構成されたスタンドに表示されるケースを選択します。テストを実行します。エラーが発生した場合は、すみやかに修正いたします。そうでない場合、テストは合格です。
このアプローチにより、統合テスト中の誤った設定に関連するエラーの数を減らすことができました。
ドキュメントに関する追加のコミュニケーション
マニュアルでこれらの設定を説明することに加えて、テストの前に設定を確認することは、ドキュメントに関する追加のコミュニケーションの一例です。他にもありました。
たとえば、私たちは常に私たちの側に専門家がいて、顧客がドキュメントとシステム全体について質問できるようにしました。高度な資格を持つスペシャリストによる専用のテクニカルサポートラインのようなものです。
当社のテクニカルライターは、新しい機能についてクライアントの従業員を教育するためのワークショップを開催しました。
ドキュメントを転送するプロセスは、より離散的ではなく、より継続的になりました。新しい情報、説明、推奨事項は、メインマニュアルの「出荷」後に部分的に送信できるようになりました。表示されたとおり、または必要に応じて。
これらすべてにより、新機能についてより適切に顧客に通知し、それによって統合テストのエラー数を減らすことができました。
サードパーティシステムの操作に関する専門知識
請求を作成するには、トラフィックを追跡できる必要があります。これには個別のPCRFシステムがあります。通話は1つのデータベースでカウントされ、SMSは同じ場所でカウントされ、トラフィックは別のデータベースでカウントされます。そして、これらすべてを同期させる特別なソフトウェアがあります。
同時に、PCRFシステムはサードパーティ独自のソフトウェアです。つまり、ブラックボックスです。そこでデータを送信し、見返りに何かを受け取りますが、内部で何が起こるかを制御することはできません。また、そこでは何も変更できません。
この調整により、トラフィック関連のバグをローカライズして修正する機能が制限されました。
実施内容:個別の内部PCRFナレッジベースを設定しました。すべてのインシデント、すべてのカスタマイズオプション、すべての洞察-すべてが記録され、チームによって共有されました。
その結果、私たちはPCRFシステムの優れたユーザーになり、それをカスタマイズして、それが何をすべきかを理解することができます。これにより、単純なインシデントの時間を節約できます。もちろん、複雑なケースでも、システム開発者に支援を求めます。
その他のスタンド
モバイルオペレーターの請求をテストするもう1つの機能は、カスタムスクリプトを時間の経過とともに拡張できることです。テストする完全なスクリプトには、数日から数週間かかる場合があります。
テスト段階で数日または数週間待つことは困難です。実際、このようなシナリオをテストするには、ほとんどの場合、データベースでくつろぐ時間です。
時間を巻き戻すには、自分のセッションを除くすべてのセッションを閉じる必要があります。条件付きで、20人のテスターが2つのテストベンチに申し込むことができ、誰もが時間を巻き戻したいという状況が発生します。これがキューです。そして、キューは、ソフトウェアの出荷の合意された日付までに、すべてを適切にチェックする時間がない可能性がある確率です。
私たちがしたこと:テスターごとに別々のスタンドを設置しました。
これにより、「スタンドに遅れて来た、時間がなかった」という理由で発生したエラーを取り除くことができました。
仮想化
ブースの準備は迅速なプロセスではありません。オペレーターのネットワークに接続してアクセスを要求する必要がありますが、それだけではありません。完全な手順には、最大で数週間かかる場合があります。スタンドの準備にかかる時間を短縮するための努力は、エラーゼロの目標に向かって進む上で重要な方向性でした。
私たちがしたこと:仮想化を有効にしました。
必要なすべての設定、プレインストールされたソフトウェアを使用して仮想マシンをコピーし、このプロセスを自動化することで、スタンドの準備にかかる時間を「1日以内」に短縮できました。
計画
統合テストのエラーは、リリース計画の誤算の結果でもあります。固定リリース日の時点で、すべてが間に合ったわけではありませんでした。
私たちがしたこと:各開発段階の暫定期限を導入します。「終了日を知っていれば、すべての中間体を知っています」-この原則は、リリース目標に向けた移動速度をより適切に制御するのに役立ちました。
並行してサポートとリリース
私たちの旅の初めに、最後のリリースの「負債」が次のリリースと競合する状況がありました。受け入れた後、バグが顧客側に到着し、全員がそれらを修正するために行きました。
同時に、リリーススケジュールは移動しませんでした。その結果、次のリリースに取り組む時期になったときでも、前のリリースで作業を続けることができました。
チームから2つのグループが分離されたため、状況を変えることができました。誰が受け入れからのエラーを修正し、誰が新しいリリースをスケジュールどおりに処理するかです。
分割は条件付きでした。必ずしも半分はありませんが、半分はここにあります。必要に応じて、グループ間で人を移動させることができます。外から見ると、何も変わっていないように見えるかもしれません。ここにチームの人がいます。スプリント中に、バグと新機能の両方を解決しました。しかし、実際には、個々のグループの選択は、「今、私たちは息を吐くことができる」というカテゴリーからの改善でした。各グループの焦点とグループ間の作業の並列化は、私たちに大いに役立ちました。
年代順に、これは私たちが死後に策定した最初の成長ポイントの1つでした。そして、ここで私の話は主要な楽器についての部分になります。
メインツール
私たちを最も助けた改善は、正直な事後分析です。
誰かがそれを回顧的、誰かと呼びます-結果の分析。私たちのチームでは、「死後」という言葉が詰まっています。この記事で説明されているすべての改善は、事後分析で考案されました。
原則は単純です。リリースがありました。集まって、すべてがどのように進んだかを正直に話し合う必要があります。単純に聞こえますが、実装には落とし穴があります。「失敗した」リリースの後、チームの人々は「言語をスクラッチする時間がないので、何かをする必要がある」という気分になります。誰かが死後に来て沈黙を保つかもしれません(したがって、潜在的に有用な情報のいくつかを提供しません)。
エラーゼロの目標に向けて2年間、私たちは事後分析を行う方法について多くの原則を開発してきました。
- 全体像を組み立てる
参加者の拡大リストを招待します。開発者、テスター、アナリスト、マネージャー、エグゼクティブ-発言したい人なら誰でも。組織的には、全員、全員を集めることが常に可能であるとは限りません。それは大丈夫です、それもそのように機能します。重要なのは、「ここで私たちのチームでは結果を要約している、あなたはあなたの結果を要約している」という言葉で同僚の参加を否定することではありません。スタンド、コード、プロセス、インタラクションを操作します。私たちは、あらゆる側面を見失わないように努めています。
- 一度にすべてをつかまないでください
さて、事後の結果として、私たちは30の成長ポイントを思いつきました。仕事にいくらかかりますか?次回まで解決できるのでは?「ピック2-3」フォーマットが最適でした。この状況では、焦点があり、チームの人々の努力は拡散されません。たくさんするよりも少なく、しかし完全に行う方が良いですが、頭に浮かばないでください。
- フォーマットを賢くしないでください
事後分析を実施するための多くのアプローチがあります。ファシリテーションプラクティス、デザイン思考とラテラル思考からのテクニック、ゴールドラットのテクニックと他の尊敬される専門家。私たちの経験では、常識から始めるだけで十分です。問題を書き留め、グループ化し、いくつかのクラスターを選択し、残りを押しのけて(前のポイントを参照)、議論し、計画を修正しました。共通の目標がある場合、共通の言語を見つけることはそれほど難しくありません。
- 仕事に行く
おそらく、このリストの主な原則です。事後の結果に基づく改善のリストがどれほど有望で説得力があるとしても、それが機能しなければ、すべてが無駄になります。私たちは同意し、それを実行しています。はい、他にも緊急の問題があります。しかし、私たちにも目標があり、それに近づきたいと思っています。
死後は非常に苦痛になる可能性があります。建設的な方法でさえ、失敗について話すことは容易ではありません。しかし、不快感と戦うことはそれだけの価値があります。事後分析がなければ、リリースでエラーをゼロにするという目標を達成するのに役立つすべてのものを考え出し、実装することはできなかったと確信しています。
最も重要なツール
事後分析では、目標を達成するための手段を見つけることができますが、それを見ると、より高いレベルの原則の結果と言えます。
最も重要なツールはチームの関与です。
関与には手段的な側面があります。例えば:
- 私たちが残業している場合、上司はチームの隣にいて、彼の手を手伝っています。
- 進捗状況を追跡してチームを元気づけると、視覚的な指標を見つけることができます(エラーの数については難しくありません)。
そしてさらに同じ精神で。
関与には、形式化するのが難しい側面もあります。成功したというあなたの信念をチームと共有する能力です。結局のところ、私のチームと私は、会社の価値観が記載されたパンフレットを調べただけでなく、そこで「より強く一緒に」見て、解決策が見つかったと判断しました。力を合わせることで、どのように挑戦的な目標を達成できるかの例を見てきました。私たちのチームには、成功を信じ、この信念を同僚に伝えようとした人々がいました。残りは技術の問題です。
人は最も重要なことです。
バグゼロの目標に向けて、リリースにはさらに多くのことがありました。ドキュメントの改善に取り組み、顧客の質問への回答の速度と品質を向上させることは異なります。今回はいくつかの例だけを共有し、基本的な原則について話そうとしました。
チームと私は、リリース品質と市場投入までの時間の最適化のための戦いでまだやるべきことがたくさんあります。統合テストでエラーが発生せずに結果を定期的に再現可能にし、回帰を自動化します。
これらの目標をどのように達成するかはまだ分からない。しかし、私たちが今確かに知っていることは、私たちは間違いなく事後分析を行い、動機に基づいて成長ポイントを実装することです。そして、関係するチームが持っている機会を利用しようとします。
これのいくつかがあなたにも役立つかもしれないことを願っています。