
神話上のサイのユニコーン。 MS TECH / PIXABAY
1回未満の試行でのトレーニングは、モデルがトレーニングした例の数よりも多くのオブジェクトを識別するのに役立ちます。
通常、機械学習には多くの例が必要です。 AIモデルが馬を認識するためには、何千もの馬の画像を表示する必要があります。これが、テクノロジーが非常に計算コストが高く、人間の学習とは大きく異なる理由です。子供は、一生それを認識することを学ぶために、オブジェクトのほんの数例、あるいは1つを見る必要があることがよくあります。
実際、子供たちは何かを特定するために例を必要としないことがあります。馬とサイの写真を見せて、ユニコーンが間にあることを伝えてください。そうすれば、初めて見るとすぐに、絵本の中の神話上の生き物を認識します。

うーん...そうではない! MS TECH / PIXABAYオンタリオ州のウォータールー大学の
調査によると、AIモデルでもこれを実行できることが示唆されています。これは、研究者が「1回未満で」学習を試みると呼ぶプロセスです。言い換えれば、AIモデルは、トレーニングした例の数よりも多くのオブジェクトを明確に認識できます。これは、使用中のデータセットが増えるにつれてますます高価になり、アクセスできなくなる領域で重要になる可能性があります。
« »
研究者たちは、MNISTとして知られる人気のあるコンピュータービジョントレーニングデータセットを実験することによって、このアイデアを最初に実証しました。 MNISTには、0から9までの手書きの数字の60,000枚の画像が含まれており、このセットは、この領域で新しいアイデアをテストするためによく使用されます。
前回の記事で、マサチューセッツ工科大学の研究者は、巨大なデータセットを小さなデータセットに「蒸留」する方法を紹介しました。コンセプトの証明として、彼らはMNISTを10枚の画像に圧縮しました。画像は元のデータセットからサンプリングされていません。それらは、情報の完全なセットに相当するものを含むように注意深く設計および最適化されています。その結果、これらの10個の画像でトレーニングすると、AIモデルはMNISTセット全体でトレーニングした場合とほぼ同じ精度を達成します。

MNISTセットのサンプル画像。ウィキメディア

10は、94パーセント手書き数字認識精度を達成するためにAIモデルを訓練することができ、MNISTから「蒸留」、描写します。通州Wangら。
Wotrelu大学の研究者は、蒸留プロセスを継続したかったです。 60,000枚の画像を10枚に減らすことができるのなら、5枚に圧縮してみませんか?彼らが気付いた秘訣は、1つの画像に複数の数字を混ぜ合わせてから、いわゆるハイブリッドまたは「ソフト」ラベルを使用してAIモデルにフィードすることでした。 (ユニコーンの特徴を与えられた馬とサイを想像してみてください。)
「3番を考えてみてください。8番のように見えますが、7番ではありません」とWaterlooの大学院生で記事の主執筆者であるIlyaSukholutskyは言います。-ソフトマークは、これらの類似点を捉えようとします。したがって、車に「この画像は3番です」と言う代わりに、「この画像は60%が3番、30%が8番、10%が0番です」と言います。
新しい教授法の限界
研究者は、ソフトラベルを使用して、1回未満の試行で学習へのMNISTの適応を実現することに成功した後、アイデアがどこまで進むことができるのか疑問に思い始めました。少数の例からAIモデルが識別できるカテゴリの数に制限はありますか?
驚いたことに、制限はないようです。注意深く設計されたソフトラベルを使用すると、2つの例でも理論的には任意の数のカテゴリをエンコードできます。 「たった2つのドットで、1000のクラス、10,000のクラス、または100万のクラスを分割できます」とSukholutsky氏は言います。
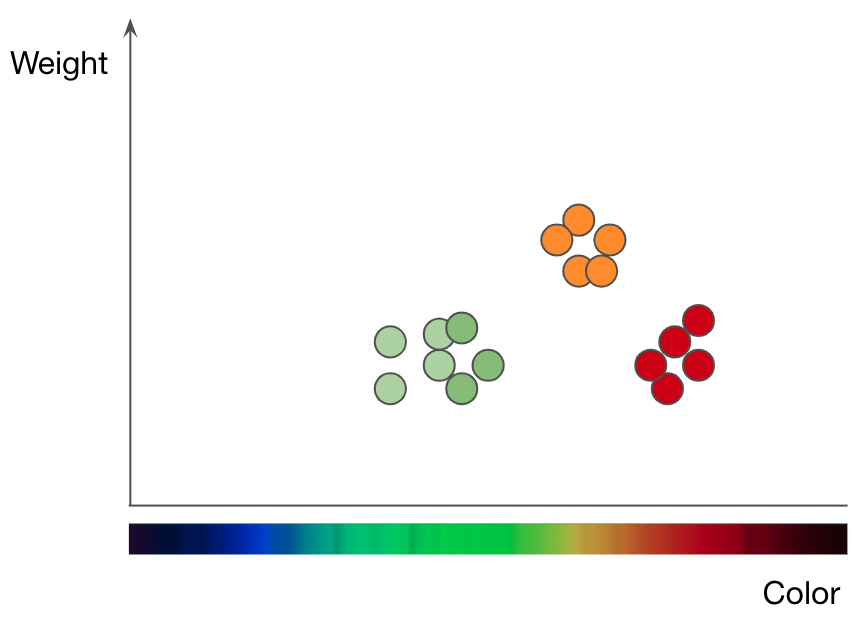
リンゴ(緑と赤の点)とオレンジ(オレンジの点)の重量と色による内訳。 JasonMaceのプレゼンテーションMachineLearning101から引用
これは、科学者が純粋に数学的な研究を通じて最新の記事で示したものです。彼らは、グラフィカルなアプローチを使用してオブジェクトを分類するk-nearest neighbors(kNN)として知られる最も単純な機械学習アルゴリズムの1つを使用して、この概念を実装しました。
kNN法がどのように機能するかを理解するために、例として果物分類問題を取り上げましょう。リンゴとオレンジの違いを理解するためにkNNモデルをトレーニングするには、まず、各果物を表すために使用する関数を選択する必要があります。色と重量を選択した場合、リンゴとオレンジごとに、フルーツの色をx値、重量をy値として1つのデータポイントを入力します。..。次に、kNNアルゴリズムは、すべてのデータポイントを2Dチャートにプロットし、リンゴとオレンジの中間に線を引きます。これで、グラフは2つのクラスにきちんと分割され、アルゴリズムは、新しいデータポイントがリンゴとオレンジのどちらを表すかを、ポイントが線のどちら側にあるかに応じて決定できます。
kNNアルゴリズムを使用して1回未満の試行で学習を研究するために、研究者は一連の小さな合成データセットを作成し、それらのソフトラベルについて慎重に検討しました。次に、kNNアルゴリズムが見た境界をプロットできるようにし、グラフをデータポイントよりも多くのクラスに正常に分割できることを発見しました。研究者はまた、国境がどこに走るかを大部分制御しました。ソフトラベルにさまざまな変更を加えて、kNNアルゴリズムに花の形で正確なパターンを描画させました。
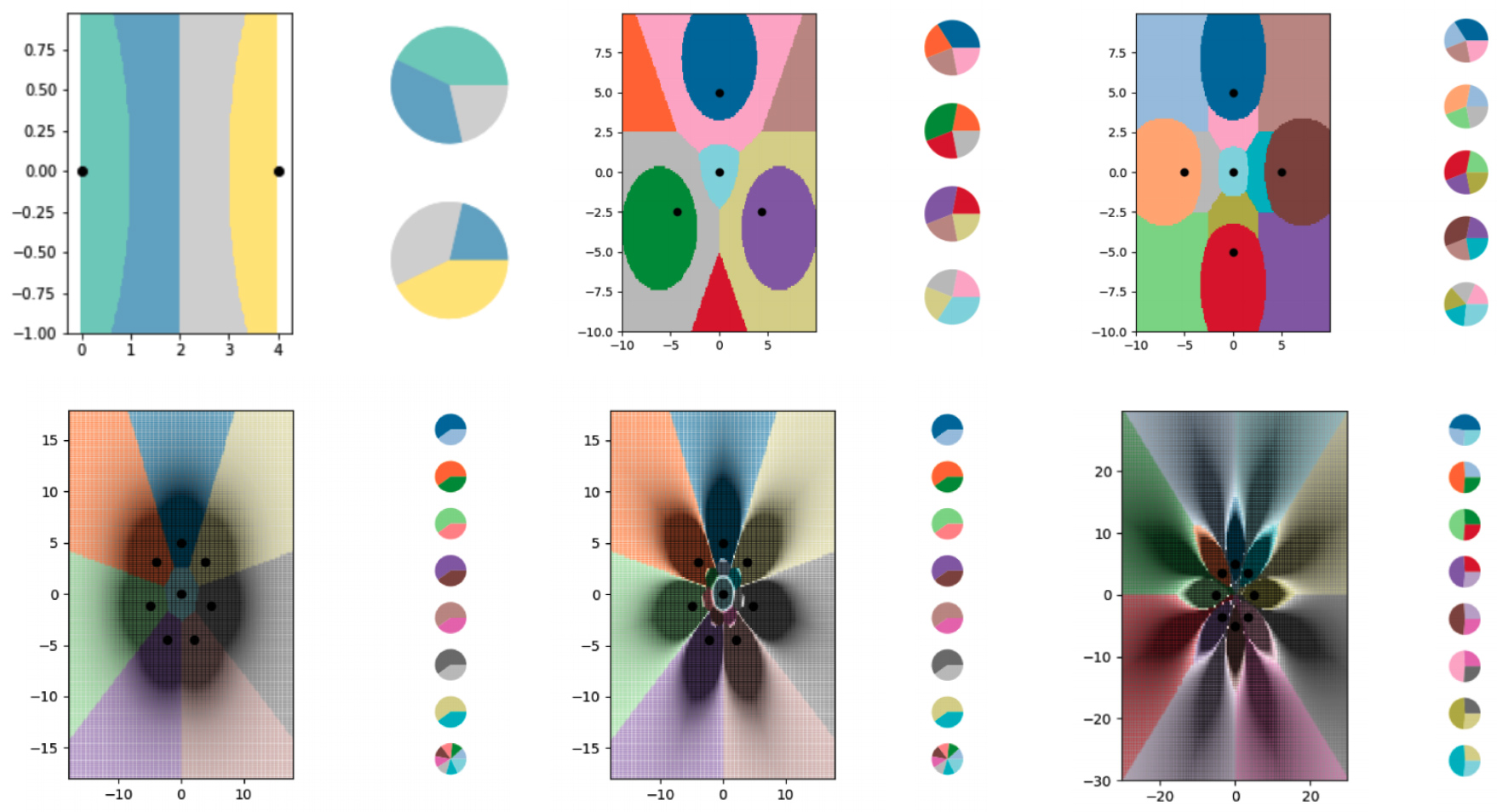
研究者は、ソフトラベルの例を使用して、kNNアルゴリズムをトレーニングし、ますます複雑になる境界をエンコードし、データポイントよりも多くのクラスに図を分割しました。色付きの各領域は個別のクラスを表し、各グラフの横の円グラフは、各データポイントのソフトラベルの分布を示しています。
Ilya Sukholutsky et al。
さまざまな図は、kNNアルゴリズムを使用して構築された境界を示しています。各チャートには、小さなデータセットにエンコードされた境界線がますます増えています。
もちろん、この理論的研究にはいくつかの制限があります。 「1つ未満」の試みから学習するという考えは、より複雑なアルゴリズムに引き継がれますが、「ソフト」ラベルを使用して例を開発するタスクは、はるかに複雑になります。 kNNアルゴリズムは解釈可能で視覚的であるため、人々はラベルを作成できます。ニューラルネットワークは複雑で侵入できないため、同じことが当てはまらない可能性があります。ニューラルネットワークのソフトラベルの例を開発するのに適したデータ蒸留にも、重大な欠点があります。巨大なデータセットから始めて、より効率的なものに縮小する必要があります。
Sukholutsky氏は、これらの小さな合成データセットを手動または別のアルゴリズムで作成する他の方法を見つけようとしていると述べています。これらの追加の研究の複雑さにもかかわらず、この記事は学習の理論的基礎を提示します。 「どのデータセットを使用していても、効率を大幅に向上させることができます」と彼は言います。
これは、マサチューセッツ工科大学の大学院生であるTongzhouWangが興味を持っていることです。彼は蒸留データに関する先行研究を指揮した。 「この記事は、非常に新しく重要な目標である小さなデータセットから強力なモデルをトレーニングすることに基づいています」と彼はSukholutskyの貢献について述べています。
Montreal Institute for the Ethics of ArtificialIntelligenceの研究者であるRyanHuranaは、次の見解を共有しています。「さらに重要なことは、1回未満の試行で学習することで、機能するモデルを構築するためのデータ要件が大幅に削減されることです。」これにより、これまでこの分野のデータ要件によって妨げられてきた企業や業界がAIにアクセスしやすくなる可能性があります。また、ユーティリティモデルのトレーニングに必要な情報が少なくなるため、データのプライバシーを向上させることもできます。
Sukholutskyは、研究は初期段階にあることを強調しています。それにもかかわらず、それはすでに想像力を刺激します。著者が仲間の研究者に自分の論文を発表し始めるときはいつでも、彼らの最初の反応は、その考えが可能性の領域を超えていると主張することです。彼らが突然自分たちが間違っていることに気づいたとき、まったく新しい世界が開かれます。

