例を始める
以下では、javaで簡単なアプリケーションを作成し(作成者はjava 14を使用しましたが、java 8でも問題ありません)、アプリケーション内のカウンターを使用してそのパフォーマンスを測定し、いくつかのスレッドでコードを実行して結果を改善しようとします。例を再現するために必要なのは、任意のjava開発環境、または発生した問題の診断に役立つjdkとvisualvmユーティリティだけです。この例では、パフォーマンスやその他の高度なツールを測定するためにさまざまなベンチマークを意図的に使用していません。この場合、それらは不要です。テストケースは、4つの物理コアと8つの論理コアを備えたIntel Corei7プロセッサ上のWindowsで実行されました。
それでは、ループ内で、プロセッサに負担をかける計算タスク、つまり因数分解の計算を実行する単純なアプリケーションを作成しましょう。さらに、ループ内の各タスクは、1から25の範囲の数値の因数分解も計算します。浮動範囲は、例を現実に近づけるために採用されています。以下は、work()関数のコードです。
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(RandomUtils.nextInt(1, 25));
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
この関数は、定数で指定された因数分解を計算するためのサイクル数を入力として受け取ります。
private static final int POWER_BASE = 1000000;変数で指定された特定の数のタスクを完了した後
private static final int LOG_STEP = 10;完了したタスクの数とそれらの実行の合計時間がログに記録されます。work
()関数は以下も使用します。
//
private long startTime;
//
private AtomicLong counter = new AtomicLong();
//
private long factorial(int power) {
if (power == 1) return power;
else return power * factorial(power - 1);
}
1つのスレッドでのwork()関数の1回の実行には約20ミリ秒かかることに注意してください。したがって、ボトルネックになる可能性のある最後の共有カウンター変数への同期呼び出しは、各スレッドで20回以下しか発生しないため、問題は発生しません。 ms。counter.incrementAndGet()の実行時間を大幅に超えています。言い換えると、同期されたカウンターへのアクセスに関連するスレッド間の競合は、実験の結果に大きな影響を与えるべきではなく、無視することができます。
次のコードを1つのスレッドで実行して、結果を確認してみましょう。
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
work(POWER_BASE);
}
コンソールには、次の出力が表示されます
。10タスクが0秒で完了
...
100タスクが2秒で 完了
...
500タスクが10秒で完了
したがって、1つのスレッドで、50タスク/秒または20ミリ秒/タスクに等しいパフォーマンスが得られました。
コードの並列化
1つのスレッドでパフォーマンスXを取得した場合、4つのプロセッサで、追加の負荷がない場合、パフォーマンスは約4 * X、つまり4倍になると予想できます。それはかなり論理的なようです。さあ、やってみましょう!
スレッド数が固定された単純なプールを紹介しましょう。
private ExecutorService executorService = Executors.newFixedThreadPool(POOL_SIZE);
絶え間ない:
private static final int POOL_SIZE = 1;1から16の範囲で変更し、結果を修正します。
起動コードの再設計:
startTime = System.currentTimeMillis();
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executorService.execute(() -> work(POWER_BASE));
}
デフォルトでは、スレッドプール内のタスクキューのサイズはInteger.MAX_VALUEです。スレッドプールに追加するタスクはInteger.MAX_VALUE以下であるため、タスクキューがオーバーフローすることはありません。
行く!
まず、POOL_SIZE定数を8スレッドに設定しましょう。
private static final int POOL_SIZE = 8;アプリケーションを実行し、コンソールを確認します
。10タスクが3秒で
完了20タスクが6秒で
完了30タスクが8秒で
完了40タスクが10秒で
完了50タスクが14秒で
完了60タスクが16秒で
完了70タスクが19秒で完了
80 20秒で完了したタスク
23秒で完了し90個のタスク
24秒で完了100のタスク
26秒で完了110のタスク
28秒で完了120のタスク
29秒で完了130のタスク
31秒で完了140のタスク
33秒で完了150個のタスク
完了160のタスク36秒で
170タスクが46秒で完了
何が見えますか?予想されるパフォーマンスの向上ではなく、タスクあたり20ミリ秒から270ミリ秒に10倍以上低下しました。しかし、それだけではありません! 170の完了したタスクに関するメッセージは、ログの最後です。その後、アプリケーションは完全に停止したように見えました。
プログラムのこの奇妙な動作の理由を扱う前に、ダイナミクスを理解し、POOL_SIZE定数を適切な値に設定して、4スレッドと16スレッドのログを順番に削除しましょう。
4スレッドのログ:
10タスクが2秒で
完了20タスクが4秒で
完了30タスクが6秒で
完了40タスクが8秒で
完了50タスクが10秒で
完了60タスクが13秒で
完了70タスクが15秒で完了
80タスクが18秒で完了しました
90タスクが21秒で完了しました
100タスクが33秒で完了しました
最初の90タスクは8スレッドの場合とほぼ同じ時間で完了し、次の10タスクを完了するにはさらに12秒が必要で、アプリケーションがハングしました。
16スレッドのログ:
10タスクが2秒で
完了20タスクが3秒で
完了30タスクが6秒で
完了40タスクが8秒で 完了
...
290タスクが51秒で
完了300タスクが52秒で
完了310タスクが63秒で
完了310タスクの場合、アプリケーションがフリーズし、前の場合と同様に、最後の10タスクが完了するまでに10秒以上かかりました。
要約しましょう:
タスクの実行を並列化すると、パフォーマンスが10倍以上低下します
。すべての場合において、アプリケーションはハングし、スレッドが少ないほどハングが速くなります(この事実に戻ります)。
問題を探す
明らかに、コードに問題があります。しかし、どうやってその理由を見つけますか?これを行うには、visualvmユーティリティを使用します。そして、アプリケーションを実行する前に起動し、アプリケーションを起動した後、visualvmインターフェイスで必要なjavaプロセスに切り替えます。アプリケーションは、開発環境から直接起動できます。もちろん、これは一般的に間違っていますが、この例では結果に影響しません。
まず、[モニター]タブを見て、メモリに問題があることを確認します。
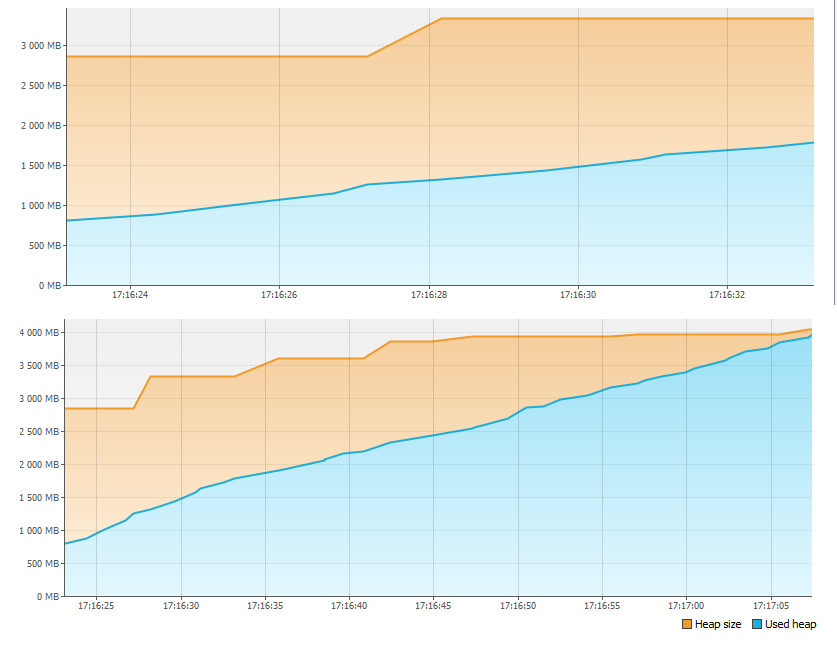
1分もかからずに、4GBのメモリが不足しました。そのため、アプリケーションは停止しました。しかし、記憶はどこに行きましたか?
アプリケーションを再起動し、[モニター]タブの[ヒープダンプ]ボタンを押します。メモリダンプを削除して開くと、次のように表示されます。

[インスタンスのサイズ別のクラス]セクションでは、1GBを超えるものがLinkedBlockingQueue $ノードクラスによって占有されています。これは、スレッドプールタスクキューの1つのトップにすぎません。 2番目に大きいクラスは、スレッドプールに追加されるタスク自体です。これをサポートするために、[インスタンス数によるクラス]セクションで、第1クラスと第2クラスのインスタンス数の対応を確認します(最初にタスクが作成され、次にキューの新しいトップのみが作成され、時差があるため、一致は完全に正確ではありません。スレッドの数を掛けると、インスタンスの数にわずかな不一致があります)。
それでは数えましょう。ループ内に約20億のタスク(Integer.MAX_VALUE)、つまり約2GBのタスクを作成します。タスクは作成されるよりも実行が遅いため、キューサイズは増え続けます。各タスクに必要なメモリが8バイトしかない場合でも、最大キューサイズは次のようになります
。8* 2GB = 16GB
合計ヒープサイズが4GBの場合、十分なメモリがなかったのは当然です。実際、ログが停止したアプリケーションの実行を中断しなかった場合、しばらくすると、有名なOutOfMemoryErrorが表示され、visualvmがなくても、コードを見るだけで、メモリの行き先を推測できます。
タスクを実行するスレッドの数が少ないほど、アプリケーションの停止が速くなることを覚えておいてください。これを説明してみましょう。スレッドの数が少ないほど、アプリケーションの実行速度が速くなり(理由はまだわかりません)、タスクキューがいっぱいになり、メモリがいっぱいになるのが速くなります。
さて、メモリオーバーフローの問題を修正するのは非常に簡単です。Integer.MaxValueの代わりに定数を作成しましょう:
private static final int MAX_TASKS = 1024 * 1024;
そして、次のようにコードを変更しましょう。
startTime = System.currentTimeMillis();
for (int i = 0; i < MAX_TASKS; i++) {
executorService.execute(() -> work(POWER_BASE));
}
これで、アプリケーションを実行し、すべてがメモリと正常に機能していることを確認する必要があります。

分析を続けます
アプリケーションを再度起動し、スレッド数を順次増やして結果を修正します。
1スレッド-10秒で500タスク
2スレッド-21秒で
500タスク4スレッド-37秒で
500タスク8スレッド-49秒で
500タスク16スレッド-57秒で500タスク
ご覧のとおり、増加した場合の500タスクの実行時間スレッドの数は減少しませんが増加しますが、10個のタスクの各部分の実行速度は均一であり、スレッドがフリーズすることはありません。
もう一度visualvmユーティリティを使用して、アプリケーションの実行中にスレッドダンプを取得してみましょう。最も正確な画像を得るには、16スレッドで作業するときにダンプを取ることをお勧めします。スレッドダンプを分析するためのさまざまなユーティリティがありますが、この場合、visualvmインターフェイスで「pool-1-thread-1」、「pool-1-thread-2」などの名前のすべてのスレッドをスクロールするだけで、次のことがわかります。

ダンプの時点で、ほとんどのスレッドは、因数分解を計算するために次のランダムな数値を生成します。これが最も時間のかかる機能であることがわかりました。なぜですか?それを理解するために、Random.next()のソースコードに行き、以下を見てみましょう:
private final AtomicLong seed;
protected int next(int bits) {
long oldseed, nextseed;
AtomicLong seed = this.seed;
do {
oldseed = seed.get();
nextseed = (oldseed * multiplier + addend) & mask;
} while (!seed.compareAndSet(oldseed, nextseed));
return (int)(nextseed >>> (48 - bits));
}
すべてのスレッドはシード変数の単一のインスタンスを共有し、そのインスタンスへのアクセスはAtomicLongクラスを使用して同期されます。これは、各ランダム番号が生成されると、スレッドは並行して実行されるのではなく、この変数にアクセスするためにキューに入れられることを意味します。したがって、生産性は向上しません。しかし、なぜ彼女は落ちるのですか?答えは簡単です。実行を並列化する場合、並列処理のサポート、特にスレッド間のプロセッサコンテキストの切り替えに追加のリソースが費やされます。シード変数の値へのアクセスをめぐって競合し、seed.compareAndSet()が呼び出されるとキューに入れられるため、追加のコストが発生し、スレッドはまだ並行して機能しないことがわかりました。限られたリソースをめぐるスレッド間の競争、おそらく計算を並列化するときのパフォーマンス低下の最も一般的な原因。
work()関数のコードを次のように変更してみましょう。
void work(int power) {
for (int i = 0; i < power; i++) {
long result = factorial(20);
}
if (counter.incrementAndGet() % LOG_STEP == 0) {
System.out.printf("%d %d %n", counter.longValue(), (long) ((System.currentTimeMillis() - startTime) / 1000));
}
}
もう一度、異なる数のスレッドでパフォーマンスを確認します
。1スレッド-17秒で1000タスク
2スレッド-10秒で
1000タスク4スレッド-5秒で
1000タスク8スレッド-4秒で
1000タスク16スレッド-4秒で1000タスク
今結果は私たちの期待に近いです。4スレッドでのパフォーマンスが約4倍に向上しました。さらに、並列化はプロセッサリソースによって制限されるため、パフォーマンスの向上は実質的に停止しました。4スレッドと8スレッドで作業しているときにvisualvmを介してキャプチャされたプロセッサ負荷のグラフを見てみましょう。

グラフからわかるように、4つのスレッドでは、プロセッサリソースの50%以上が空いており、8つのスレッドでは、プロセッサはほぼ100%使用されています。これは、この例では8スレッドが制限であり、それ以上のパフォーマンスは低下するだけであることを意味します。この例では、パフォーマンスの向上は4つのスレッドですでに停止していますが、スレッドが因数分解を計算する代わりに同期I / Oを実行した場合、パフォーマンスが向上する並列化の制限が大幅に増加する可能性があります。読者は自分でこれを確認し、記事へのコメントに結果を書く
ことができます。練習について話す場合、2つの重要な点に注意することができます。
並列化は通常、スレッドの数がプロセッサコアの数の最大2倍である場合に効果的です(もちろん、他のプロセッサの負荷
がない場合)。障害耐性を確保するために、実際のCPU使用率は80%を超えてはなりません。
スレッド間の競合を減らす
パフォーマンスについての話に夢中になって、私たちは1つの重要なことを忘れました。コード内のRandomUtils.nextInt()の呼び出しを定数に変更することで、アプリケーションのビジネスロジックを変更しました。パフォーマンスの問題を回避しながら、古いアルゴリズムに戻りましょう。RandomUtils.nextInt()を呼び出すと、各スレッドが同じシード変数を使用してランダムな番号を生成することがわかりました。一方、これは完全にオプションです。この例では、代わりにを使用します
RandomUtils.nextInt(1, 25)ThreadLocalRandomクラス:
ThreadLocalRandom.current().nextInt(1, 25)競争の問題を解決します。これで、各スレッドは、次のランダム番号を生成するために必要な内部変数の独自のインスタンスを使用します。
スレッド間で共有されるクラスの単一インスタンスへの同期アクセスの代わりに、スレッドごとに個別の変数を使用することは、スレッド間の競合を減らすことによってパフォーマンスを向上させるための一般的な手法です。 java.lang.ThreadLocalクラスを使用して、変数の値をスレッドのコンテキストに格納できますが、マップされた診断コンテキストなどのより高度なツールがあります。
結論として、スレッド間の競合を減らすことは、技術的な作業であるだけでなく、論理的な作業でもあることに注意してください。この例では、各スレッドは問題なく独自の変数インスタンスを使用できますが、たとえば、共通のカウンターなど、すべてに1つのインスタンスが必要な場合はどうでしょうか。この場合、アルゴリズム自体をリファクタリングする必要があります。たとえば、各ストリームのコンテキストでカウンターを保存し、定期的またはオンデマンドで、各ストリームのカウンターの値に基づいて合計カウンター値を計算します。
結論
したがって、並列処理のパフォーマンスに影響を与える3つのポイントがあります。
- CPUリソース
- スレッド間の競争
- 全体的な結果に間接的に影響を与える他の要因