
目標を探しています
テーマ別サイトminiclip.comにアクセスして、ターゲットを探します。選択は、パズルセクションのColoruid 2カラーパズルに当てはまりました。このパズルでは、与えられた回数の動きで、丸い競技場を1つの色で埋める必要があります。
画面下部で選択した色で任意の領域が塗りつぶされ、同じ色の隣接する領域が1つに統合されます。

トレーニング
Pythonを使用します。ボットは教育目的でのみ作成されました。この記事は、私自身がコンピュータビジョンの初心者を対象としています。
ゲームはここにあり
ますボットのGitHubはここにあります
ボットが機能するには、次のモジュールが必要です。
- opencv-python
- 枕
- セレン
ボットは、Ubuntu20.04.1上のPython3.8用に作成およびテストされています。必要なモジュールを仮想環境に、またはpipinstallを介してインストールします。さらに、Seleniumを機能させるには、FireFox用のgeckodriverが必要です。github.com/ mozilla / geckodriver / releasesからダウンロードできます。
ブラウザ制御
私たちはオンラインゲームを扱っているので、最初にブラウザとの相互作用を整理します。この目的のために、FireFoxを管理するためのAPIを提供するSeleniumを使用します。ゲームページのコードを調べる。パズルはキャンバスであり、iframe内に配置されています。
id = iframe-gameのフレームがロードされ、ドライバーコンテキストがそれに切り替わるのを待ちます。次に、キャンバスを待ちます。これはフレーム内で唯一のものであり、XPath / html / body / canvasから入手できます。
wait(self.__driver, 20).until(EC.frame_to_be_available_and_switch_to_it((By.ID, "iframe-game")))
self.__canvas = wait(self.__driver, 20).until(EC.visibility_of_element_located((By.XPATH, "/html/body/canvas")))次に、self .__ canvasプロパティを介してキャンバスを使用できるようになります。ブラウザを操作するためのすべてのロジックは、キャンバスのスクリーンショットを撮り、特定の座標でクリックすることです。
完全なBrowser.pyコード:
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait as wait
from selenium.webdriver.common.by import By
class Browser:
def __init__(self, game_url):
self.__driver = webdriver.Firefox()
self.__driver.get(game_url)
wait(self.__driver, 20).until(EC.frame_to_be_available_and_switch_to_it((By.ID, "iframe-game")))
self.__canvas = wait(self.__driver, 20).until(EC.visibility_of_element_located((By.XPATH, "/html/body/canvas")))
def screenshot(self):
return self.__canvas.screenshot_as_png
def quit(self):
self.__driver.quit()
def click(self, click_point):
action = webdriver.common.action_chains.ActionChains(self.__driver)
action.move_to_element_with_offset(self.__canvas, click_point[0], click_point[1]).click().perform()ゲームの状態
ゲーム自体に取り掛かりましょう。すべてのボットロジックはRobotクラスに実装されます。ゲームプレイを7つの状態に分割し、それらを処理するためのメソッドを割り当てましょう。トレーニングレベルを個別に強調してみましょう。クリックする場所を示す大きな白いカーソルが含まれているため、ゲームが正しく認識されません。
- ようこそ画面
- レベル選択画面
- チュートリアルレベルでの色の選択
- 教育レベルでの領域の選択
- 色の選択
- 地域の選択
- 移転の結果
class Robot:
STATE_START = 0x01
STATE_SELECT_LEVEL = 0x02
STATE_TRAINING_SELECT_COLOR = 0x03
STATE_TRAINING_SELECT_AREA = 0x04
STATE_GAME_SELECT_COLOR = 0x05
STATE_GAME_SELECT_AREA = 0x06
STATE_GAME_RESULT = 0x07
def __init__(self):
self.states = {
self.STATE_START: self.state_start,
self.STATE_SELECT_LEVEL: self.state_select_level,
self.STATE_TRAINING_SELECT_COLOR: self.state_training_select_color,
self.STATE_TRAINING_SELECT_AREA: self.state_training_select_area,
self.STATE_GAME_RESULT: self.state_game_result,
self.STATE_GAME_SELECT_COLOR: self.state_game_select_color,
self.STATE_GAME_SELECT_AREA: self.state_game_select_area,
}ボットの安定性を高めるために、ゲーム状態の変更が正常に行われたかどうかを確認します。self.state_timeout中にself.state_next_success_conditionがTrueを返さない場合は、現在の状態の処理を続行します。それ以外の場合は、self.state_nextに切り替えます。また、Seleniumから受け取ったスクリーンショットをOpenCVが理解できる形式に変換します。
import time
import cv2
import numpy
from PIL import Image
from io import BytesIO
class Robot:
def __init__(self):
# …
self.screenshot = []
self.state_next_success_condition = None
self.state_start_time = 0
self.state_timeout = 0
self.state_current = 0
self.state_next = 0
def run(self, screenshot):
self.screenshot = cv2.cvtColor(numpy.array(Image.open(BytesIO(screenshot))), cv2.COLOR_BGR2RGB)
if self.state_current != self.state_next:
if self.state_next_success_condition():
self.set_state_current()
elif time.time() - self.state_start_time >= self.state_timeout
self.state_next = self.state_current
return False
else:
try:
return self.states[self.state_current]()
except KeyError:
self.__del__()
def set_state_current(self):
self.state_current = self.state_next
def set_state_next(self, state_next, state_next_success_condition, state_timeout):
self.state_next_success_condition = state_next_success_condition
self.state_start_time = time.time()
self.state_timeout = state_timeout
self.state_next = state_next
状態処理メソッドにチェックを実装しましょう。スタート画面の「再生」ボタンを待ってクリックします。10秒以内にレベル選択画面が表示されない場合は、前のステージself.STATE_STARTに戻ります。それ以外の場合は、self.STATE_SELECT_LEVELの処理に進みます。
# …
class Robot:
DEFAULT_STATE_TIMEOUT = 10
# …
def state_start(self):
# Play
# …
if button_play is False:
return False
self.set_state_next(self.STATE_SELECT_LEVEL, self.state_select_level_condition, self.DEFAULT_STATE_TIMEOUT)
return button_play
def state_select_level_condition(self):
#
# …
ボットビジョン
画像のしきい値
ゲームで使用される色を定義しましょう。これらは、5つの再生可能な色と、チュートリアルレベルのカーソルの色です。色に関係なく、すべてのオブジェクトを検索する必要がある場合は、COLOR_ALLを使用します。まず、このケースを検討します。
COLOR_BLUE = 0x01
COLOR_ORANGE = 0x02
COLOR_RED = 0x03
COLOR_GREEN = 0x04
COLOR_YELLOW = 0x05
COLOR_WHITE = 0x06
COLOR_ALL = 0x07
オブジェクトを見つけるには、最初に画像を単純化する必要があります。たとえば、記号「0」を取得してしきい値を適用します。つまり、オブジェクトを背景から分離します。この段階では、シンボルの色は関係ありません。まず、画像を白黒に変換して、1チャンネルにします。グレースケール変換を担当する2番目の引数cv2.COLOR_BGR2GRAYを持つcv2.cvtColor関数は、これに役立ちます。次に、cv2.thresholdを使用してしきい値を実行します。特定のしきい値を下回る画像のすべてのピクセルは0に設定され、それを超えるものはすべて-から255に設定されます。cv2.threshold関数の2番目の引数は、しきい値を担当します。この場合、cv2.THRESH_OTSUを使用するため、任意の数を指定できます。 そして、関数自体が、画像ヒストグラムに基づいて大津法を使用して最適なしきい値を決定します。
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(image, 0, 255, cv2.THRESH_OTSU)

色分け
さらに興味深い。タスクを複雑にして、レベル選択画面ですべての赤い記号を見つけましょう。

デフォルトでは、すべてのOpenCVイメージはBGR形式で保存されます。HSV(色相、彩度、値-色相、彩度、値)は、色のセグメンテーションに適しています。RGBに対するその利点は、HSVが彩度と明るさから色を分離することです。色相は、1つの色相チャネルによってエンコードされます。薄緑色の長方形を例にとり、徐々に明るさを下げていきましょう。
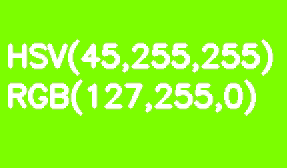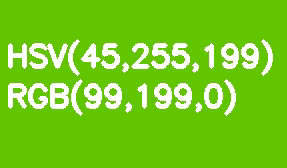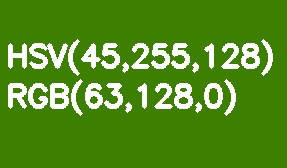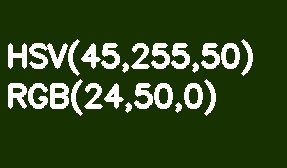
RGBとは異なり、この変換はHSVでは直感的に見えます。ValueまたはBrightnessチャネルの値を減らすだけです。ここで、参照モデルでは、色相シェードスケールが0〜360°の範囲で変化することに注意してください。私たちの薄緑色は90°に対応します。この値を8ビットチャネルに合わせるには、2で割る必要があります。
色のセグメンテーションは、単一の色ではなく、範囲で機能します。範囲は経験的に決定できますが、小さなスクリプトを作成する方が簡単です。
import cv2
import numpy as numpy
image_path = "tests_data/SELECT_LEVEL.png"
hsv_max_upper = 0, 0, 0
hsv_min_lower = 255, 255, 255
def bite_range(value):
value = 255 if value > 255 else value
return 0 if value < 0 else value
def pick_color(event, x, y, flags, param):
if event == cv2.EVENT_LBUTTONDOWN:
global hsv_max_upper
global hsv_min_lower
global image_hsv
hsv_pixel = image_hsv[y, x]
hsv_max_upper = bite_range(max(hsv_max_upper[0], hsv_pixel[0]) + 1), \
bite_range(max(hsv_max_upper[1], hsv_pixel[1]) + 1), \
bite_range(max(hsv_max_upper[2], hsv_pixel[2]) + 1)
hsv_min_lower = bite_range(min(hsv_min_lower[0], hsv_pixel[0]) - 1), \
bite_range(min(hsv_min_lower[1], hsv_pixel[1]) - 1), \
bite_range(min(hsv_min_lower[2], hsv_pixel[2]) - 1)
print('HSV range: ', (hsv_min_lower, hsv_max_upper))
hsv_mask = cv2.inRange(image_hsv, numpy.array(hsv_min_lower), numpy.array(hsv_max_upper))
cv2.imshow("HSV Mask", hsv_mask)
image = cv2.imread(image_path)
cv2.namedWindow('Original')
cv2.setMouseCallback('Original', pick_color)
image_hsv = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
cv2.imshow("Original", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
スクリーンショットで起動しましょう。

赤い色をクリックして、結果のマスクを確認します。出力が私たちに合わない場合は、赤の色合いを選択して、マスクの範囲と面積を増やします。このスクリプトは、cv2.inRange関数に基づいています。この関数は、カラーフィルターとして機能し、指定された色範囲のしきい値画像を返します。
次の範囲について詳しく見ていきましょう。
COLOR_HSV_RANGE = {
COLOR_BLUE: ((112, 151, 216), (128, 167, 255)),
COLOR_ORANGE: ((8, 251, 93), (14, 255, 255)),
COLOR_RED: ((167, 252, 223), (171, 255, 255)),
COLOR_GREEN: ((71, 251, 98), (77, 255, 211)),
COLOR_YELLOW: ((27, 252, 51), (33, 255, 211)),
COLOR_WHITE: ((0, 0, 159), (7, 7, 255)),
}輪郭を見つける
レベル選択画面に戻りましょう。定義したばかりの赤の範囲のカラーフィルターを適用し、見つかったしきい値をcv2.findContoursに渡します。この関数は、赤い要素の輪郭を見つけます。2番目の引数としてcv2.RETR_EXTERNALを指定します-外側の輪郭のみが必要で、 3番目の引数としてcv2.CHAIN_APPROX_SIMPLE-直線の輪郭に関心があり、メモリを節約し、それらの頂点のみを保存します。
thresh = cv2.inRange(image, self.COLOR_HSV_RANGE[self.COLOR_RED][0], self.COLOR_HSV_RANGE[self.COLOR_RED][1])
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
ノイズの除去
結果として得られる輪郭には、多くのバックグラウンドノイズが含まれています。それを削除するには、numbersのプロパティを使用します。それらは、座標軸に平行な長方形で構成されています。すべてのパスを繰り返し、cv2.minAreaRectを使用してそれぞれを最小の長方形に合わせます。長方形は4点で定義されます。長方形が軸に平行である場合、ポイントの各ペアの座標の1つが一致する必要があります。これは、長方形の座標を1次元配列として表す場合、最大4つの一意の値を持つことを意味します。さらに、アスペクト比が3対1より大きい長すぎる長方形を除外します。これを行うには、cv2.boundingRectを使用して幅と長さを見つけます。
squares = []
for cnt in contours:
rect = cv2.minAreaRect(cnt)
square = cv2.boxPoints(rect)
square = numpy.int0(square)
(_, _, w, h) = cv2.boundingRect(square)
a = max(w, h)
b = min(w, h)
if numpy.unique(square).shape[0] <= 4 and a <= b * 3:
squares.append(numpy.array([[square[0]], [square[1]], [square[2]], [square[3]]]))

輪郭を組み合わせる
今はまし。次に、見つかった長方形を組み合わせて、シンボルの共通のアウトラインにする必要があります。中間画像が必要です。numpy.zeros_likeで作成しましょう。この関数は、形状とサイズを維持しながらマトリックスイメージのコピーを作成し、それをゼロで埋めます。つまり、元の画像のコピーを黒の背景で塗りつぶしました。これを1チャンネルに変換し、cv2.drawContoursを使用して見つかった輪郭を適用し、白で塗りつぶします。cv2.dilateを適用できるバイナリしきい値を取得します。この関数は、5ピクセル以内の距離にある別々の長方形を接続することにより、白い領域を拡張します。もう一度cv2.findContoursを呼び出して、赤い数字の輪郭を取得します。
image_zero = numpy.zeros_like(image)
image_zero = cv2.cvtColor(image_zero, cv2.COLOR_BGR2RGB)
cv2.drawContours(image_zero, contours_of_squares, -1, (255, 255, 255), -1)
_, thresh = cv2.threshold(image_zero, 0, 255, cv2.THRESH_OTSU)
kernel = numpy.ones((5, 5), numpy.uint8)
thresh = cv2.dilate(thresh, kernel, iterations=1)
dilate_contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)

残りのノイズは、cv2.contourAreaを使用して輪郭領域によってフィルタリングされます。500ピクセル²未満のすべてを削除します。
digit_contours = [cnt for cnt in digit_contours if cv2.contourArea(cnt) > 500]
今では素晴らしいです。上記のすべてをRobotクラスに実装しましょう。
# ...
class Robot:
# ...
def get_dilate_contours(self, image, color_inx, distance):
thresh = self.get_color_thresh(image, color_inx)
if thresh is False:
return []
kernel = numpy.ones((distance, distance), numpy.uint8)
thresh = cv2.dilate(thresh, kernel, iterations=1)
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
return contours
def get_color_thresh(self, image, color_inx):
if color_inx == self.COLOR_ALL:
image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
_, thresh = cv2.threshold(image, 0, 255, cv2.THRESH_OTSU)
else:
image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
thresh = cv2.inRange(image, self.COLOR_HSV_RANGE[color_inx][0], self.COLOR_HSV_RANGE[color_inx][1])
return thresh
def filter_contours_of_rectangles(self, contours):
squares = []
for cnt in contours:
rect = cv2.minAreaRect(cnt)
square = cv2.boxPoints(rect)
square = numpy.int0(square)
(_, _, w, h) = cv2.boundingRect(square)
a = max(w, h)
b = min(w, h)
if numpy.unique(square).shape[0] <= 4 and a <= b * 3:
squares.append(numpy.array([[square[0]], [square[1]], [square[2]], [square[3]]]))
return squares
def get_contours_of_squares(self, image, color_inx, square_inx):
thresh = self.get_color_thresh(image, color_inx)
if thresh is False:
return False
contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
contours_of_squares = self.filter_contours_of_rectangles(contours)
if len(contours_of_squares) < 1:
return False
image_zero = numpy.zeros_like(image)
image_zero = cv2.cvtColor(image_zero, cv2.COLOR_BGR2RGB)
cv2.drawContours(image_zero, contours_of_squares, -1, (255, 255, 255), -1)
dilate_contours = self.get_dilate_contours(image_zero, self.COLOR_ALL, 5)
dilate_contours = [cnt for cnt in dilate_contours if cv2.contourArea(cnt) > 500]
if len(dilate_contours) < 1:
return False
else:
return dilate_contours
数字の認識
数字を認識する機能を追加しましょう。なぜ私たちはこれが必要なのですか?
# …
class Robot:
# ...
SQUARE_BIG_SYMBOL = 0x01
SQUARE_SIZES = {
SQUARE_BIG_SYMBOL: 9,
}
IMAGE_DATA_PATH = "data/"
def __init__(self):
# ...
self.dilate_contours_bi_data = {}
for image_file in os.listdir(self.IMAGE_DATA_PATH):
image = cv2.imread(self.IMAGE_DATA_PATH + image_file)
contour_inx = os.path.splitext(image_file)[0]
color_inx = self.COLOR_RED
dilate_contours = self.get_dilate_contours_by_square_inx(image, color_inx, self.SQUARE_BIG_SYMBOL)
self.dilate_contours_bi_data[contour_inx] = dilate_contours[0]
def get_dilate_contours_by_square_inx(self, image, color_inx, square_inx):
distance = math.ceil(self.SQUARE_SIZES[square_inx] / 2)
return self.get_dilate_contours(image, color_inx, distance)OpenCVは、cv2.matchShapes関数を使用して、Huモーメントに基づいて輪郭を比較します。2つのパスを入力として受け取り、比較結果を数値として返すことにより、実装の詳細を非表示にします。小さいほど、輪郭は似ています。
cv2.matchShapes(dilate_contour, self.dilate_contours_bi_data['digit_' + str(digit)], cv2.CONTOURS_MATCH_I1, 0)現在の輪郭digit_contourをすべての標準と比較し、cv2.matchShapesの最小値を見つけます。最小値が0.15未満の場合、その桁は認識されたと見なされます。最小値のしきい値は経験的に見つかりました。また、間隔の狭い文字を1つの数字にまとめましょう。
# …
class Robot:
# …
def scan_digits(self, image, color_inx, square_inx):
result = []
contours_of_squares = self.get_contours_of_squares(image, color_inx, square_inx)
before_digit_x, before_digit_y = (-100, -100)
if contours_of_squares is False:
return result
for contour_of_square in reversed(contours_of_squares):
crop_image = self.crop_image_by_contour(image, contour_of_square)
dilate_contours = self.get_dilate_contours_by_square_inx(crop_image, self.COLOR_ALL, square_inx)
if (len(dilate_contours) < 1):
continue
dilate_contour = dilate_contours[0]
match_shapes = {}
for digit in range(0, 10):
match_shapes[digit] = cv2.matchShapes(dilate_contour, self.dilate_contours_bi_data['digit_' + str(digit)], cv2.CONTOURS_MATCH_I1, 0)
min_match_shape = min(match_shapes.items(), key=lambda x: x[1])
if len(min_match_shape) > 0 and (min_match_shape[1] < self.MAX_MATCH_SHAPES_DIGITS):
digit = min_match_shape[0]
rect = cv2.minAreaRect(contour_of_square)
box = cv2.boxPoints(rect)
box = numpy.int0(box)
(digit_x, digit_y, digit_w, digit_h) = cv2.boundingRect(box)
if abs(digit_y - before_digit_y) < digit_y * 0.3 and abs(
digit_x - before_digit_x) < digit_w + digit_w * 0.5:
result[len(result) - 1][0] = int(str(result[len(result) - 1][0]) + str(digit))
else:
result.append([digit, self.get_contour_centroid(contour_of_square)])
before_digit_x, before_digit_y = digit_x + (digit_w / 2), digit_y
return result出力で、self.scan_digitsメソッドは、認識された桁とそのクリックの座標を含む配列を返します。クリックポイントは、そのアウトラインの中心になります。
# …
class Robot:
# …
def get_contour_centroid(self, contour):
moments = cv2.moments(contour)
return int(moments["m10"] / moments["m00"]), int(moments["m01"] / moments["m00"])私たちは受け取った数字認識ツールを喜んでいますが、長くはありません。Huモーメントは、スケールは別として、回転と鏡面反射性に対しても不変です。したがって、ボットは番号6と9/2と5を混同します。これらのシンボルの頂点チェックを追加しましょう。6と9は右上の点で区別されます。水平方向の中心より下にある場合は、反対の場合は6と9です。ペア2と5の場合、右上の点がシンボルの右の境界にあるかどうかを確認します。
if digit == 6 or digit == 9:
extreme_bottom_point = digit_contour[digit_contour[:, :, 1].argmax()].flatten()
x_points = digit_contour[:, :, 0].flatten()
extreme_right_points_args = numpy.argwhere(x_points == numpy.amax(x_points))
extreme_right_points = digit_contour[extreme_right_points_args]
extreme_top_right_point = extreme_right_points[extreme_right_points[:, :, :, 1].argmin()].flatten()
if extreme_top_right_point[1] > round(extreme_bottom_point[1] / 2):
digit = 6
else:
digit = 9
if digit == 2 or digit == 5:
extreme_right_point = digit_contour[digit_contour[:, :, 0].argmax()].flatten()
y_points = digit_contour[:, :, 1].flatten()
extreme_top_points_args = numpy.argwhere(y_points == numpy.amin(y_points))
extreme_top_points = digit_contour[extreme_top_points_args]
extreme_top_right_point = extreme_top_points[extreme_top_points[:, :, :, 0].argmax()].flatten()
if abs(extreme_right_point[0] - extreme_top_right_point[0]) > 0.05 * extreme_right_point[0]:
digit = 2
else:
digit = 5

競技場の分析
トレーニングレベルをスキップしましょう。白いカーソルをクリックしてスクリプトを作成し、再生を開始します。
競技場をネットワークとして想像してみましょう。色の各領域は、隣接するネイバーにリンクされているノードになります。カラーエリア/ノードを記述するクラスself.ColorAreaを作成しましょう。
class ColorArea:
def __init__(self, color_inx, click_point, contour):
self.color_inx = color_inx #
self.click_point = click_point #
self.contour = contour #
self.neighbors = [] # self.color_areas ノードのリストと、プレイフィールドself.color_areas_color_countに色が表示される頻度のリストを定義しましょう。キャンバスのスクリーンショットからプレイフィールドを切り取ります。
image[pt1[1]:pt2[1], pt1[0]:pt2[0]]ここで、pt1、pt2はフレームの極値です。ゲームのすべての色を繰り返し、それぞれにself.get_dilate_contoursメソッドを適用します。ノードの輪郭を見つけることは、シンボルの一般的な輪郭を探す方法と似ていますが、競技場にノイズがないという違いがあります。ノードの形状は凹状または穴がある可能性があるため、セントロイドは形状から外れ、クリックの座標としては適していません。これを行うには、最上位のポイントを見つけて20ピクセルドロップします。この方法は普遍的ではありませんが、私たちの場合は機能します。
self.color_areas = []
self.color_areas_color_count = [0] * self.SELECT_COLOR_COUNT
image = self.crop_image_by_rectangle(self.screenshot, numpy.array(self.GAME_MAIN_AREA))
for color_inx in range(1, self.SELECT_COLOR_COUNT + 1):
dilate_contours = self.get_dilate_contours(image, color_inx, 10)
for dilate_contour in dilate_contours:
click_point = tuple(
dilate_contour[dilate_contour[:, :, 1].argmin()].flatten() + [0, int(self.CLICK_AREA)])
self.color_areas_color_count[color_inx - 1] += 1
color_area = self.ColorArea(color_inx, click_point, dilate_contour)
self.color_areas.append(color_area)
リンクエリア
輪郭間の距離が15ピクセル以内の場合、その領域を隣接領域と見なします。各ノードをそれぞれで繰り返し、色が一致する場合は比較をスキップします。
blank_image = numpy.zeros_like(image)
blank_image = cv2.cvtColor(blank_image, cv2.COLOR_BGR2GRAY)
for color_area_inx_1 in range(0, len(self.color_areas)):
for color_area_inx_2 in range(color_area_inx_1 + 1, len(self.color_areas)):
color_area_1 = self.color_areas[color_area_inx_1]
color_area_2 = self.color_areas[color_area_inx_2]
if color_area_1.color_inx == color_area_2.color_inx:
continue
common_image = cv2.drawContours(blank_image.copy(), [color_area_1.contour, color_area_2.contour], -1, (255, 255, 255), cv2.FILLED)
kernel = numpy.ones((15, 15), numpy.uint8)
common_image = cv2.dilate(common_image, kernel, iterations=1)
common_contour, _ = cv2.findContours(common_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if len(common_contour) == 1:
self.color_areas[color_area_inx_1].neighbors.append(color_area_inx_2)
self.color_areas[color_area_inx_2].neighbors.append(color_area_inx_1)
最適な動きを探しています
競技場に関するすべての情報があります。動きを選び始めましょう。このためには、ノードインデックスと色が必要です。移動オプションの数は、次の式で決定できます。
移動オプション=ノードの数*色の数-1
前のプレイフィールドには、7 *(5-1)= 28のオプションがあります。それらの数は少ないので、すべての動きを繰り返して最適なものを選択できます。オプションをマトリックス
select_color_weightsとして定義しましょう。この行は、ノードインデックス、カラーインデックス列、および移動ウェイトセルになります。ノードの数を1つに減らす必要があるため、ボード上で固有の色を持ち、移動すると消える領域を優先します。一意の色を持つすべてのノード行の重みに+10を与えましょう。色が競技場に現れる頻度は、以前に収集したものです。self.color_areas_color_count
if self.color_areas_color_count[color_area.color_inx - 1] == 1:
select_color_weight = [x + 10 for x in select_color_weight]
次に、隣接する領域の色を見てみましょう。ノードにcolor_inxのネイバーがあり、それらの数が競技場でのこの色の総数と等しい場合は、セルの重みに+10を割り当てます。これにより、color_inxカラーもフィールドから削除されます。
for color_inx in range(0, len(select_color_weight)):
color_count = select_color_weight[color_inx]
if color_count != 0 and self.color_areas_color_count[color_inx] == color_count:
select_color_weight[color_inx] += 10同じ色の隣人ごとにセルの重みに+1を与えましょう。つまり、3つの赤い隣人がある場合、赤いセルはその重みに対して+3を受け取ります。
for select_color_weight_inx in color_area.neighbors:
neighbor_color_area = self.color_areas[select_color_weight_inx]
select_color_weight[neighbor_color_area.color_inx - 1] += 1すべての重みを収集した後、最大の重みを持つ動きを見つけます。どのノードとどの色に属するかを定義しましょう。
max_index = select_color_weights.argmax()
self.color_area_inx_next = max_index // self.SELECT_COLOR_COUNT
select_color_next = (max_index % self.SELECT_COLOR_COUNT) + 1
self.set_select_color_next(select_color_next)最適な動きを決定するための完全なコード。
# …
class Robot:
# …
def scan_color_areas(self):
self.color_areas = []
self.color_areas_color_count = [0] * self.SELECT_COLOR_COUNT
image = self.crop_image_by_rectangle(self.screenshot, numpy.array(self.GAME_MAIN_AREA))
for color_inx in range(1, self.SELECT_COLOR_COUNT + 1):
dilate_contours = self.get_dilate_contours(image, color_inx, 10)
for dilate_contour in dilate_contours:
click_point = tuple(
dilate_contour[dilate_contour[:, :, 1].argmin()].flatten() + [0, int(self.CLICK_AREA)])
self.color_areas_color_count[color_inx - 1] += 1
color_area = self.ColorArea(color_inx, click_point, dilate_contour, [0] * self.SELECT_COLOR_COUNT)
self.color_areas.append(color_area)
blank_image = numpy.zeros_like(image)
blank_image = cv2.cvtColor(blank_image, cv2.COLOR_BGR2GRAY)
for color_area_inx_1 in range(0, len(self.color_areas)):
for color_area_inx_2 in range(color_area_inx_1 + 1, len(self.color_areas)):
color_area_1 = self.color_areas[color_area_inx_1]
color_area_2 = self.color_areas[color_area_inx_2]
if color_area_1.color_inx == color_area_2.color_inx:
continue
common_image = cv2.drawContours(blank_image.copy(), [color_area_1.contour, color_area_2.contour],
-1, (255, 255, 255), cv2.FILLED)
kernel = numpy.ones((15, 15), numpy.uint8)
common_image = cv2.dilate(common_image, kernel, iterations=1)
common_contour, _ = cv2.findContours(common_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if len(common_contour) == 1:
self.color_areas[color_area_inx_1].neighbors.append(color_area_inx_2)
self.color_areas[color_area_inx_2].neighbors.append(color_area_inx_1)
def analysis_color_areas(self):
select_color_weights = []
for color_area_inx in range(0, len(self.color_areas)):
color_area = self.color_areas[color_area_inx]
select_color_weight = numpy.array([0] * self.SELECT_COLOR_COUNT)
for select_color_weight_inx in color_area.neighbors:
neighbor_color_area = self.color_areas[select_color_weight_inx]
select_color_weight[neighbor_color_area.color_inx - 1] += 1
for color_inx in range(0, len(select_color_weight)):
color_count = select_color_weight[color_inx]
if color_count != 0 and self.color_areas_color_count[color_inx] == color_count:
select_color_weight[color_inx] += 10
if self.color_areas_color_count[color_area.color_inx - 1] == 1:
select_color_weight = [x + 10 for x in select_color_weight]
color_area.set_select_color_weights(select_color_weight)
select_color_weights.append(select_color_weight)
select_color_weights = numpy.array(select_color_weights)
max_index = select_color_weights.argmax()
self.color_area_inx_next = max_index // self.SELECT_COLOR_COUNT
select_color_next = (max_index % self.SELECT_COLOR_COUNT) + 1
self.set_select_color_next(select_color_next)
レベル間を移動して結果を楽しむ機能を追加しましょう。ボットは安定して動作し、1回のセッションでゲームを完了します。
出力
作成されたボットは実用的ではありません。しかし、記事の著者は、OpenCVの基本原則の詳細な説明が、初心者が初期段階でこのライブラリを扱うのに役立つことを心から望んでいます。