指定された頻度で必要なレポートを生成するには、対応するカスタムレポートリソースを作成するだけで十分です。
使用シナリオ
たとえば、次の場合は、カスタムメータリングレポートが必要です。
- OpenShift, , (worker nodes) . . CPU , , -, , .
- OpenShift. Metering, , , , . , , , .
- さらに、パブリッククラスターがある状況では、運用部門は、ポッドの合計実行時間(または、ポッドに費やされたCPUまたはメモリリソースの量)によって、チームおよび部門のコンテキストで記録を保持できると便利です。言い換えれば、誰がこれまたはそのサブを所有しているかについての情報に再び興味があります。
クラスタ内のこれらの問題を解決するには、特定のカスタムリソースを作成するだけで十分です。これについては、次に行います。Meteringオペレーターのインストールはこの記事の範囲を超えているため、必要に応じてインストールドキュメントを参照してください。標準のメータリングレポートの使用方法について詳しくは、関連ドキュメントをご覧ください。
メータリングのしくみ
カスタムアセットを作成する前に、メータリングについて少し見てみましょう。インストールすると、6種類のカスタムリソースが作成されます。そのうち、以下に焦点を当てます。
- ReportDataSources(RDS) -このメカニズムを使用すると、使用可能なデータを定義し、ReportQueryまたはカスタムレポートリソースで使用できます。RDSでは、複数のソースからデータを抽出することもできます。OpenShiftでは、データはPrometheusおよびカスタムReportQuery(RQ)リソースから取得されます。
- ReportQuery (rq) – SQL- , RDS. RQ- Report, RQ- , . RQ- RDS-, RQ- Metering view Presto ( Metering) .
- Report – , , ReportQuery. , , , Metering. Report .
多くのRDSとRQが箱から出して利用できます。主にノードレベルのレポートに関心があるため、カスタムクエリの作成に役立つレポートを検討します。「openshift-metering」プロジェクトで次のコマンドを実行します。
$ oc project openshift-metering
$ oc get reportdatasources | grep node
node-allocatable-cpu-cores
node-allocatable-memory-bytes
node-capacity-cpu-cores
node-capacity-memory-bytes
node-cpu-allocatable-raw
node-cpu-capacity-raw
node-memory-allocatable-raw
node-memory-capacity-raw
ここでは、CPU消費に関するレポートを取得するため、node-capacity-cpu-coreとnode-capput-capacity --capacity-rawの2つのRDSに関心があります。node-capacity-cpu-coreから始めて、次のコマンドを実行して、Prometheusからデータを収集する方法を確認しましょう。
$ oc get reportdatasource/node-capacity-cpu-cores -o yaml
<showing only relevant snippet below>
spec:
prometheusMetricsImporter:
query: |
kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)
ここに、PrometheusからデータをフェッチしてPrestoに保存するPrometheusリクエストが表示されます。OpenShiftメトリックコンソールで同じリクエストを実行して、結果を確認してみましょう。2つのワーカーノード(それぞれ16コア)と3つのマスターノード(それぞれ8コア)を持つOpenShiftクラスターがあります。最後の列Valueには、ノードに割り当てられたコアの数が含まれています。

したがって、データは受信され、Prestoテーブルに格納されます。次に、reportquery(RQ)カスタムリソースを見てみましょう。
$ oc project openshift-metering
$ oc get reportqueries | grep node-cpu
node-cpu-allocatable
node-cpu-allocatable-raw
node-cpu-capacity
node-cpu-capacity-raw
node-cpu-utilization
ここでは、次のRQSに関心があります:node-cpu-capacityおよびnode-cpu-capacity-raw。名前が示すように、これらのメトリックには、記述データ(ノードの実行時間、割り当てられたプロセッサーの数など)と集約データの両方が含まれます。
関心のある2つのRDSと2つのRQSは、次のチェーンによって相互接続されています。
node-cpu-capacity (rq) <b>uses</b> node-cpu-capacity-raw (rds) <b>uses</b> node-cpu-capacity-raw (rq) <b>uses</b> node-capacity-cpu-cores (rds)
カスタマイズ可能なレポート
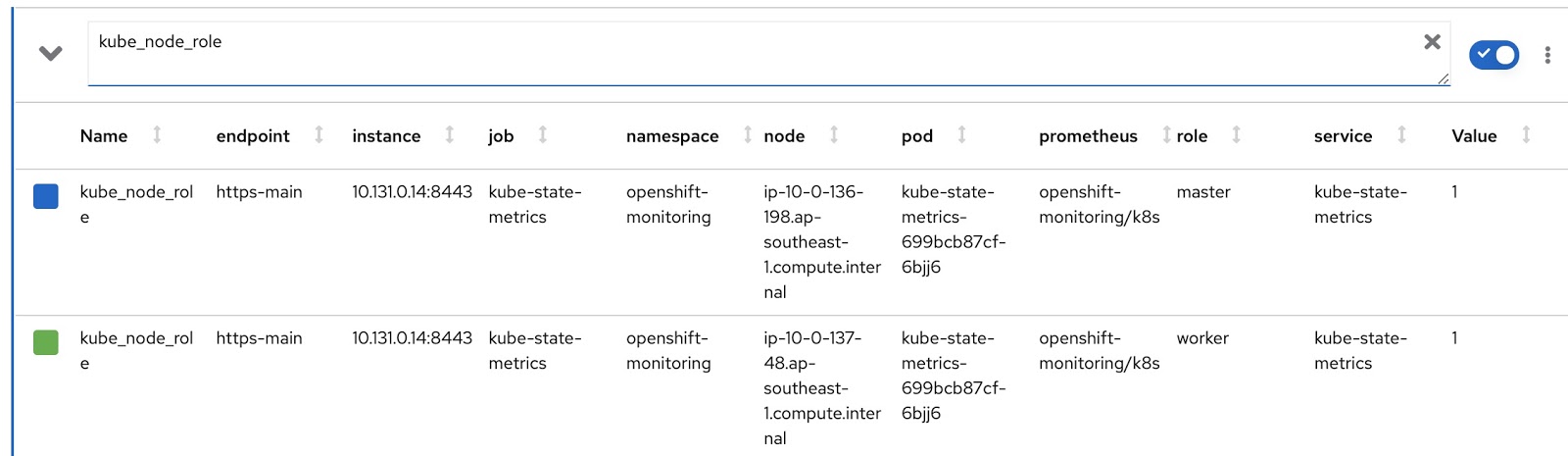
それでは、RDSとRQの独自のカスタマイズバージョンを作成しましょう。Prometheusリクエストを変更して、ノードのモード(マスター/ワーカー)と、このノードが属するチームを示す対応するノードラベルを表示するようにする必要があります。ノード操作モードは、kube_node_rolePrometheusメトリックに含まれています。役割の列を参照してください。
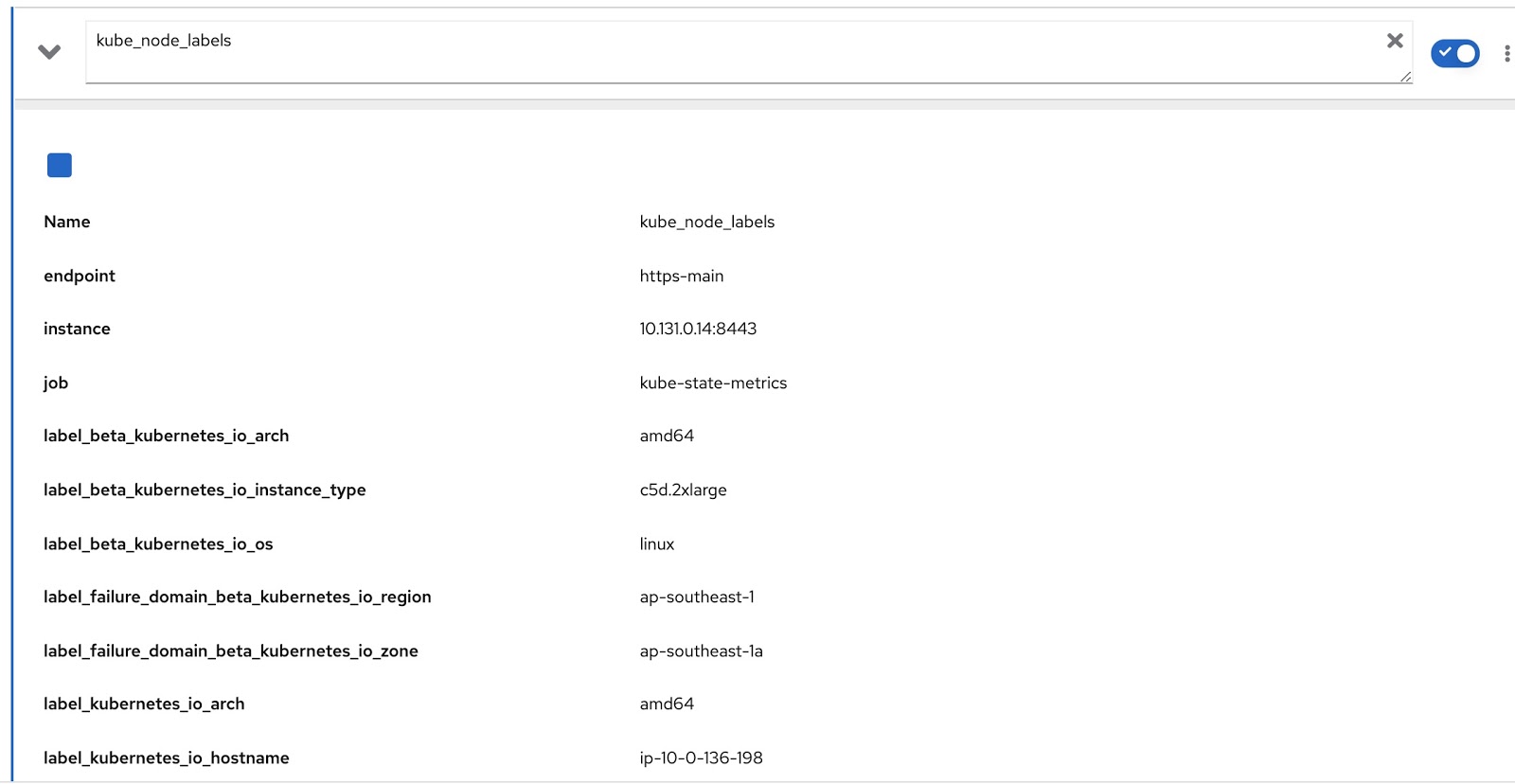
また、ノードに割り当てられたすべてのラベルは、Prometheusメトリックkube_node_labelsに含まれ、label_テンプレートを使用して形成されます。たとえば、ノードにラベルnode_lobがある場合、Prometheusメトリックにlabel_node_lobとして表示されます。
次に、次のように、これら2つのPrometheusクエリを使用して元のクエリを変更し、必要なデータを取得する必要があります。
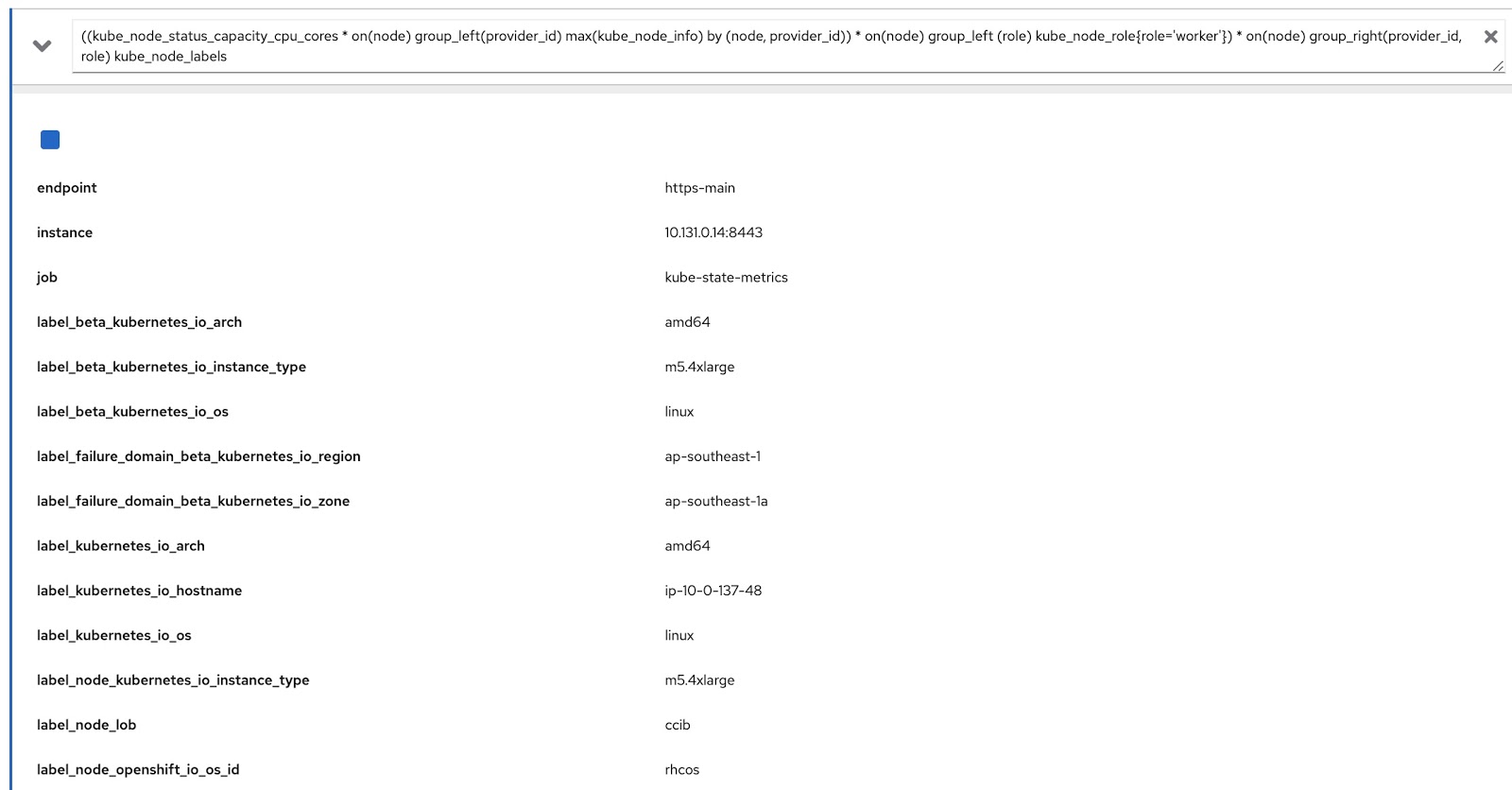
((kube_node_status_capacity_cpu_cores * on(node) group_left(provider_id) max(kube_node_info) by (node, provider_id)) * on(node) group_left (role) kube_node_role{role='worker'}) * on(node) group_right(provider_id, role) kube_node_labels
次に、OpenShiftメトリックコンソールでこのクエリを実行し、ラベル(node_lob)とロールの両方でデータが返されることを確認しましょう。下の図では、これはまず、label_node_lobと役割です(そこにあり、スクリーンショットには表示されませんでした)。
したがって、4つのカスタムリソースを作成する必要があります(以下のリストからダウンロードできます)。
- rds-custom-node-capacity-cpu-cores.yaml -Prometheusリクエストを指定します。
- rq-custom-node-cpu-capacity-raw.yaml-ステップ1からの要求を参照し、生データを出力します。
- rds-custom-node-cpu-capacity-raw.yaml-ステップ2のRQを参照し、Prestoでビューオブジェクトを作成します。
- rq-custom-node-cpu-capacity-with-cpus-labels.yaml-第3項のRDSを参照し、入力されたレポートの開始日と終了日を考慮してデータを出力します。さらに、役割列とラベル列が同じファイルに抽出されます。
これらの4つのyamlファイルを作成したら、openshift-meteringプロジェクトに移動し、次のコマンドを実行します。
$ oc project openshift-metering
$ oc create -f rds-custom-node-capacity-cpu-cores.yaml
$ oc create -f rq-custom-node-cpu-capacity-raw.yaml
$ oc create -f rds-custom-node-cpu-capacity-raw.yaml
$ oc create -f rq-custom-node-cpu-capacity-with-cpus-labels.yaml
これで、手順4のRQオブジェクトを参照するカスタムReportオブジェクトを作成するだけで済みます。たとえば、次のようにこれを行うと、レポートがすぐに実行され、9月15日から30日までのデータが返されます。
$ cat report_immediate.yaml
apiVersion: metering.openshift.io/v1
kind: Report
metadata:
name: custom-role-node-cpu-capacity-lables-immediate
namespace: openshift-metering
spec:
query: custom-role-node-cpu-capacity-labels
reportingStart: "2020-09-15T00:00:00Z"
reportingEnd: "2020-09-30T00:00:00Z"
runImmediately: true
$ oc create -f report-immediate.yaml
このレポートを実行した後、結果ファイル(csvまたはjson)を次のURLからダウンロードできます(DOMAIN_NAMEを独自のものに置き換えるだけです):
metering-openshift-metering.DOMAIN_NAME / api / v1 / reports / get?name = custom-role-node-cpu- capacity-hourly&namespace = openshift-metering&format = csv
CSVファイルのスクリーンショットに示されているように、ロールとnode_lobの両方が含まれています。ノードの稼働時間を秒単位で取得するには、node_capacity_cpu_core_secondsをnode_capacity_cpu_coresで割ります。

結論
Meteringオペレーターは、どこにでもデプロイされたOpenShiftクラスターにとって優れた機能です。拡張可能なフレームワークを提供することにより、カスタムリソースを作成して、必要なレポートを生成できます。この記事で使用されているすべてのソースコードは、ここからダウンロードできます。