Bob Steagallは最近、CppCon2020で「AdventuresinSIMD-thinking」というタイトルの講演を行いました。ここでは、特に、ウィンドウ7での中央値フィルタリングにAVX512を使用した経験について話しました。この講演は私に2つの感情を引き起こしました。 、そして最も愚かなSTL実装よりもほぼ20倍高速であると主張されています。一方、16個の入力サンプルからのアルゴリズムの1回のパスでは、入力データは10個で十分でしたが、出力は2個しかありませんでした。実装の詳細によって、それらを改善しようと思いました。私は考え、考え、そしてアイデアを思いついた後、別のアイデアを「ソフトウェアで」試してみて、共有するものがあることに気づきました:)それでこの記事が判明しました。
基本的な実装
ボブがそれをどのように行ったかについて簡単に説明します(実際、彼のストーリーの対応する部分の短い説明と、彼自身の写真)。彼はAVX512を使用して次のプリミティブを作成しました(単一のAVX512操作に直接対応する彼が説明したプリミティブのプリミティブは省略します)。
回転: AVX-512レジスタの要素を円で回転させます

キャリー付きシフト:レジスターからアイテムをシフトし、2番目のレジスターからアイテムを置き換えます
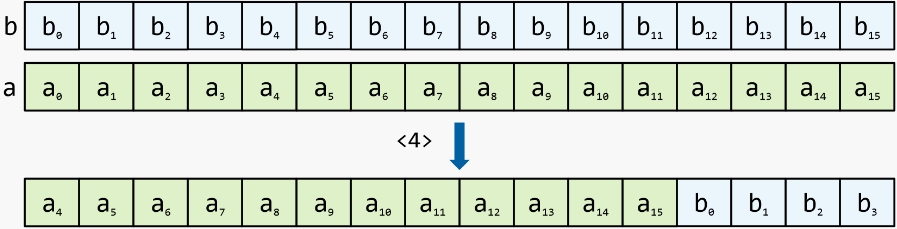
キャリー付きシフト:キャリー付きシフトと同様ですが、入力レジスタは参照によって渡され、シフトの結果はそれらに残ります。
交換との比較:レジスタ内の最大8ペアの要素の並列ソート

, , : perm 0..15, ; mask 1 «» . : , perm. vmin , vmax ́ . , .
, , . :
1) shift with carry, «» , «» (.. 0 0..6, 1 — 1..7 . .)
2) , 0 , 1 —
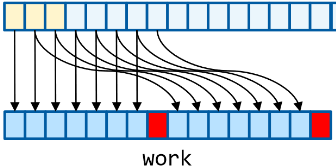
3) 7 , — 6 compare and exchange, . — — .
0
- , . , , ( , L2). , . AVX-512…
1
, — . 7 ; 6 !

, 6 r1-r6 , r0 r7? S[0..5], X, , S[3] .
X >= S[3], S[3] ,X <= S[2], S[2] S[3], S[2]S[2] < X < S[3], X S[3], , X. ,clamp(X, S[2], S[3])=>min(max(X, S[2]), S[3])!
:
«» 4 7- ( 0, 7, 2, 9) – X 4
6- 1..6 3..8 ( 0..7 8..15, )
6-
clamp 2 3 X[0] X[1], 2 3 X[2] X[3]
2x — 2 ( 6 5 , 7 — 6), clamp . : 1,86x . . ?
2
«» X . 6- ; 5 , 2 ( 3 ). — : S[0] <=> S[1], S[2] <=> S[3], S[4] <=> S[5]
2, . . , , !

— 2 , 2 . , : 1.06x. , .
3
- , 1, 6- .

, 4 ( ), 6; , 4- ?
2 , 4- . 6- : 2- Y 4- S, 2 3 ( Z). , min(Y[0], S[0]) => Z[0], ; max(Y[0], S[0]) Z[1]..Z[5] – . max(Y[1], S[3]) , min(Y[1], S[3]).
4- S[1], S[2], min/max. , 4 , 1 2 — 2 3 6- . , «» 4- S[1] S[2], — . , 2 , Y.
:
r1-r2 . .
— Y, r1-2, r5-6, r7-8, r11-12; permute 4 , Y r0-1, r4-5 . .
( ) «» ; r3-r6 r7-r10
max min Y[0]/S[0], Y[1]/S[3]
mask_permute Y S, S[1] S[2] ,
4
1 2, min/max X 8
, , , 2. — 1.64x , 2, 3 , .
; ( - permute; , - ), .
, :)
benchmark:
512 : 3.1-3.2 ; 7.3 , memcpy avx-512
50 : 2.8-2.9 ; 1.8 , memcpy (!)
.
5? , (disclaimer: — ).
16- 12 .
- 3 ( …)
1 , 4 ( 6 ) 4- — , . . 4 , 5 ; 8 .
2 , — 2 ; , .
3 , . , — , 12 . , «» — 24 , 12 .
9? 8 .
—
1 — 2 8- 4 , 4 ( 7 6 )
2 — , -
3 — , — 6- 2, 6- ( , ) , 8-.
, - . , https://github.com/tea/avx-median/. « », , -. , .
- , — . .
UPDATE
AVX2 . , , , , ( , 16 , ). , : 1.64x , .
すべてが失われるわけではないことが判明しました-最初の最適化ステップもこのバリアントに適用できます!Xの32個のエッジを収集する必要があり、並べ替えのためにデータを混乱させる必要があり、並べ替えられたデータもミュートする必要があります。これらすべてのジェスチャにもかかわらず、1.27倍の加速が得られました。
手順2と3は明らかに遅くなるため、実行しようとはしませんでした。たとえば、ウィンドウ11の場合、プラスで機能する可能性は十分にあります(ただし、大きなウィンドウを備えた高速の1Dメディアンフィルターが必要かどうかはわかりません)。