この記事では、もう少し複雑で興味深いトピック(少なくとも、検索チームの開発者である私にとって)に触れます。フルテキスト検索です。 Elasticsearchノードをコンテナ領域に追加し、インデックスを作成してコンテンツを検索する方法を学習し、TMDB5000ムービーデータセットの5000本のフィルムの説明をテストデータとして使用します。..。また、検索フィルターの作成方法と、ランキングに向けてかなり掘り下げる方法についても学びます。
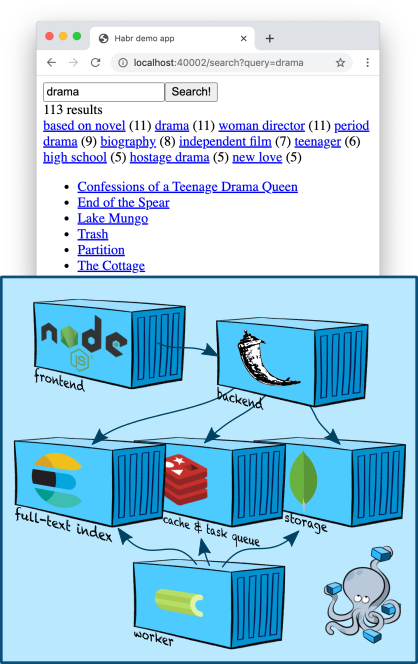
インフラストラクチャ:Elasticsearch
Elasticsearchは、フルテキストインデックスを作成できる人気のあるドキュメントストアであり、原則として、検索エンジンとして特に使用されます。Elasticsearchは、ベースとなるApache Luceneエンジン、シャーディング、レプリケーション、便利なJSON API、および最も人気のあるフルテキスト検索ソリューションの1つとなった100万以上の詳細を追加します。
Elasticsearchノードを1つ追加しましょう
docker-compose.yml:
services:
...
elasticsearch:
image: "elasticsearch:7.5.1"
environment:
- discovery.type=single-node
ports:
- "9200:9200"
...
環境変数
discovery.type=single-nodeは、Elasticsearchに、単独で作業の準備をし、他のノードを探してそれらをクラスターにマージしないように指示します(これがデフォルトの動作です)。
アプリケーションがdocker-composeによって作成されたネットワーク内をナビゲートしている場合でも、ポート9200を外部に公開していることに注意してください。これは純粋にデバッグ用です。この方法で、ターミナルから直接Elasticsearchにアクセスできます(よりスマートな方法が見つかるまで-以下で詳しく説明します)。
Elasticsearchクライアントを配線に追加することは難しくありません-良いことに、Elasticは最小限のPythonクライアントを提供します。
インデックス作成
前回の記事では、主要なエンティティである「カード」をMongoDBコレクションに配置しました。MongoDBが直接インデックスを作成したため、コレクションから識別子でコンテンツをすばやく取得できます。これには Bツリーを使用します。
今、私たちは逆のタスクに直面しています-カードの識別子を取得するためのコンテンツ(またはそのフラグメント)によって。したがって、逆インデックスが必要です。ここでElasticsearchが役に立ちます!
インデックスを作成するための一般的なスキームは、通常、次のようになります。
- 一意の名前で新しい空のインデックスを作成し、必要に応じて構成します。
- データベース内のすべてのエンティティを調べて、それらを新しいインデックスに配置します。
- すべてのクエリが新しいインデックスに移動し始めるように、プロダクションを切り替えます。
- 古いインデックスを削除します。ここでは、自由に、最後のいくつかのインデックスを保存することをお勧めします。たとえば、いくつかの問題をデバッグする方が便利です。
インデクサーのスケルトンを作成してから、各ステップでさらに詳しく見ていきましょう。
import datetime
from elasticsearch import Elasticsearch, NotFoundError
from backend.storage.card import Card, CardDAO
class Indexer(object):
def __init__(self, elasticsearch_client: Elasticsearch, card_dao: CardDAO, cards_index_alias: str):
self.elasticsearch_client = elasticsearch_client
self.card_dao = card_dao
self.cards_index_alias = cards_index_alias
def build_new_cards_index(self) -> str:
# .
# .
index_name = "cards-" + datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
# .
# .
self.create_empty_cards_index(index_name)
# .
#
# .
for card in self.card_dao.get_all():
self.put_card_into_index(card, index_name)
return index_name
def create_empty_cards_index(self, index_name):
...
def put_card_into_index(self, card: Card, index_name: str):
...
def switch_current_cards_index(self, new_index_name: str):
...
インデックス作成:インデックスの作成
Elasticsearchのインデックスは、への単純なPUTリクエストによって、
/-またはPythonクライアントを使用している場合(この場合)を呼び出すことによって作成されます。
elasticsearch_client.indices.create(index_name, {
...
})
リクエスト本文には3つのフィールドを含めることができます。
- エイリアスの説明(
"aliases": ...)。エイリアスシステムを使用すると、Elasticsearch側で現在どのインデックスが最新であるかを知ることができます。以下で説明します。 - 設定(
"settings": ...)。私たちが実際のプロダクションの大物である場合、ここでレプリケーション、シャーディング、およびその他のSREの喜びを構成することができます。 - データスキーマ(
"mappings": ...)。ここでは、インデックスを作成するドキュメント内のフィールドのタイプ、これらのフィールドのどれに対して逆インデックスが必要か、どの集計をサポートする必要があるかなどを指定できます。
今、私たちはスキームにのみ興味があり、それは非常に単純です:
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "english"
},
"text": {
"type": "text",
"analyzer": "english"
},
"tags": {
"type": "keyword",
"fields": {
"text": {
"type": "text",
"analyzer": "english"
}
}
}
}
}
}
フィールド
nameにマークを付け、text英語のテキストとしてマークしました。パーサーは、テキストをインデックスに保存する前に処理するElasticsearchのエンティティです。englishアナライザーの場合、テキストは単語の境界(詳細)に沿ってトークンに分割され、その後、個々のトークンは英語の規則に従ってレンマ化され(たとえば、単語treesはに簡略化されますtree)、あまりにも一般的なレンマ(のようなthe)は削除され、残りのレンマは逆のインデックスに入れられます。
フィールドは
tagsもう少し複雑です。タイプkeywordこのフィールドの値は、アナライザーで処理する必要のない文字列定数であると想定しています。逆インデックスは、トークン化やレンマ化なしで、「生の」値に基づいて構築されます。ただし、Elasticsearchは特別なデータ構造を作成して、このフィールドの値で集計を読み取ることができるようにします(たとえば、検索と同時に、検索クエリを満たすドキュメントで見つかったタグとその量を見つけることができます)。これは、本質的に列挙型のフィールドに最適です。この機能を使用して、いくつかのクールな検索フィルターを作成します。
ただし、タグのテキストをテキスト検索でも検索できるように、サブフィールドを追加し、との
"text"類推によって構成します。nametext上記-本質的に、これは、Elasticsearchが、そこtags.textに来るすべてのドキュメントの名前の下に別の「仮想」フィールドを作成し、そこにコンテンツをコピーしますがtags、異なるルールに従ってインデックスを作成することを意味します。
インデックス作成:インデックスへの入力
ドキュメントにインデックスを付けるには、PUTリクエストを行う
/-/_create/id-か、Pythonクライアントを使用している場合は、必要なメソッドを呼び出すだけで十分です。実装は次のようになります。
def put_card_into_index(self, card: Card, index_name: str):
self.elasticsearch_client.create(index_name, card.id, {
"name": card.name,
"text": card.markdown,
"tags": card.tags,
})
フィールドに注意してください
tags。キーワードを含むものとして説明しましたが、単一の文字列ではなく、文字列のリストを送信しています。Elasticsearchはこれをサポートしています。ドキュメントは任意の値に配置されます。
インデックス作成:インデックスの切り替え
検索を実装するには、最新の完全に構築されたインデックスの名前を知る必要があります。エイリアスメカニズムにより、Elasticsearch側でこの情報を保持できます。
エイリアスは、0個以上のインデックスへのポインタです。 Elasticsearch APIを使用すると、検索時にインデックス名の代わりにエイリアス名を使用できます(POSTの
/-/_search代わりにPOST /-/_search)。この場合、Elasticsearchはエイリアスが指すすべてのインデックスを検索します。
と呼ばれるエイリアスを作成し
cardsます。これは常に現在のインデックスを指します。したがって、建設完了後に実際のインデックスに切り替えると、次のようになります。
def switch_current_cards_index(self, new_index_name: str):
try:
# , .
remove_actions = [
{
"remove": {
"index": index_name,
"alias": self.cards_index_alias,
}
}
for index_name in self.elasticsearch_client.indices.get_alias(name=self.cards_index_alias)
]
except NotFoundError:
# , - .
# , .
remove_actions = []
#
# .
self.elasticsearch_client.indices.update_aliases({
"actions": remove_actions + [{
"add": {
"index": new_index_name,
"alias": self.cards_index_alias,
}
}]
})
エイリアスAPIについてはこれ以上詳しく説明しません。詳細はすべてドキュメントに記載されています。
ここで、実際の高負荷のサービスでは、このような切り替えは非常に面倒であり、事前のウォームアップを行うのが理にかなっている可能性があることに注意する必要があります。つまり、保存されたユーザークエリのプールを新しいインデックスにロードします。
インデックス作成を実装するすべてのコードは、このコミットにあります。
インデックス作成:コンテンツの追加
この記事のデモンストレーションでは、TMDB 5000 MovieDatasetのデータを使用しています。著作権の問題を回避するために、CSVファイルからそれらをインポートするユーティリティのコードのみを提供します。KaggleのWebサイトから自分でダウンロードすることをお勧めします。ダウンロード後、コマンドを実行するだけです
docker-compose exec -T backend python -m tools.add_movies < ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv
5000枚の映画カードとチームを作成する
docker-compose exec backend python -m tools.build_index
インデックスを作成します。最後のコマンドは実際にはインデックスを作成せず、タスクをタスクキューに入れるだけで、その後ワーカーで実行されることに注意してください。このアプローチについては、前回の記事で詳しく説明しました。
docker-compose logs worker労働者がどのように試みたかをあなたに見せてください!
実際、検索を開始する前に、Elasticsearchで何かが書かれているかどうか、もしそうなら、それがどのように見えるかを自分の目で確認したいと思います。
これを行う最も直接的で最速の方法は、Elasticsearch HTTPAPIを使用することです。まず、エイリアスがどこを指しているかを確認しましょう。
$ curl -s localhost:9200/_cat/aliases
cards cards-2020-09-20-16-14-18 - - - -
素晴らしい、インデックスが存在します!それを詳しく見てみましょう:
$ curl -s localhost:9200/cards-2020-09-20-16-14-18 | jq
{
"cards-2020-09-20-16-14-18": {
"aliases": {
"cards": {}
},
"mappings": {
...
},
"settings": {
"index": {
"creation_date": "1600618458522",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "iLX7A8WZQuCkRSOd7mjgMg",
"version": {
"created": "7050199"
},
"provided_name": "cards-2020-09-20-16-14-18"
}
}
}
}
最後に、その内容を見てみましょう。
$ curl -s localhost:9200/cards-2020-09-20-16-14-18/_search | jq
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4704,
"relation": "eq"
},
"max_score": 1,
"hits": [
...
]
}
}
合計で、インデックスは4704ドキュメントであり、フィールド
hits(大きすぎるためスキップしました)では、それらの一部の内容を確認することもできます。成功!
インデックスの内容を閲覧すると、一般的にElasticsearchを甘やかすのすべての種類を使用することですより便利な方法Kibanaを。コンテナを
docker-compose.yml次の場所に追加しましょう:
services:
...
kibana:
image: "kibana:7.5.1"
ports:
- "5601:5601"
depends_on:
- elasticsearch
...
2回目以降は、
docker-compose upそのアドレスのKibanaに移動しlocalhost:5601(サーバーがすぐに起動しない場合があります)、簡単なセットアップの後、インデックスの内容を素敵なWebインターフェイスで表示できます。
[開発ツール]タブを強くお勧めします。開発中は、Elasticsearchで特定のクエリを実行する必要があります。自動補完と自動フォーマットを使用するインタラクティブモードでは、はるかに便利です。
探す
信じられないほど退屈な準備がすべて終わったら、Webアプリケーションに検索機能を追加する時が来ました!
この重要なタスクを3つの段階に分けて、それぞれについて個別に説明しましょう。
Searcher検索ロジックを担当するコンポーネントをバックエンドに追加します。Elasticsearchへのクエリを形成し、結果をバックエンドにとってより消化しやすいものに変換します。- エンドポイントをAPIに追加します(ハンドル/ルート/会社では何と呼びますか?)
/cards/search検索を実行します。コンポーネントのメソッドを呼び出し、Searcher結果を処理して、クライアントに返します。 - フロントエンドに検索インターフェースを実装しましょう。
/cards/searchユーザーが何を検索するかを決定したときに連絡し、結果(および場合によってはいくつかの追加のコントロール)を表示します。
検索:実装します
検索マネージャーを作成するのは、設計するほど難しくありません。検索結果とマネージャーインターフェイスについて説明し、それがなぜこれで違いがないのかを説明しましょう。
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0) -> CardSearchResult:
pass
明らかなことがいくつかあります。たとえば、ページネーション。私たちは野心的な若い
あまり目立たないものもあります。たとえば、結果としてカードではなく、IDのリスト。 Elasticsearchはデフォルトでドキュメント全体を保存し、検索結果に返します。この動作をオフにして検索インデックスのサイズを節約することもできますが、これは明らかに時期尚早の最適化です。では、すぐにカードを返却してみませんか?回答:これは単一責任の原則に違反します。おそらくいつか、ユーザーの設定に応じてカードを他の言語に翻訳するカードマネージャーの複雑なロジックが完成するでしょう。まさにこの時点で、検索マネージャーに同じロジックを追加するのを忘れるため、カードページのデータと検索結果のデータは分散されます。などなど。
このインターフェースの実装はとても単純なので、私はこのセクションを書くのが面倒でした:-(
# backend/backend/search/searcher_impl.py
from typing import Any
from elasticsearch import Elasticsearch
from backend.search.searcher import CardSearchResult, Searcher
ElasticsearchQuery = Any #
class ElasticsearchSearcher(Searcher):
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query
})
total_count = result["hits"]["total"]["value"]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
)
def _make_text_query(self, query: str) -> ElasticsearchQuery:
return {
# Multi-match query
# ( match
# query, ).
"multi_match": {
"query": query,
# ^ – .
# , .
"fields": ["name^3", "tags.text", "text"],
}
}
_match_all_query: ElasticsearchQuery = {"match_all": {}}
実際、Elasticsearch APIにアクセスして、見つかったカードのIDを結果から慎重に抽出します。
エンドポイントの実装も非常に簡単です。
# backend/backend/server.py
...
def search_cards(self):
request = flask.request.json
search_result = self.wiring.searcher.search_cards(**request)
cards = self.wiring.card_dao.get_by_ids(search_result.card_ids)
return flask.jsonify({
"totalCount": search_result.total_count,
"cards": [
{
"id": card.id,
"slug": card.slug,
"name": card.name,
# ,
# ,
# .
} for card in cards
],
"nextCardOffset": search_result.next_card_offset,
})
...
このエンドポイントを使用したフロントエンドの実装は、膨大ですが、一般的に非常に簡単であり、この記事ではそれに焦点を当てたくありません。このコミットですべてのコードを見ることができます。

これまでのところ、先に進みましょう。
 検索:フィルターの追加
検索:フィルターの追加
テキスト検索はすばらしいですが、深刻なリソースを検索したことがあれば、フィルターなどのあらゆる種類の機能を見たことがあるでしょう。
TMDB 5000データベースのフィルムの説明には、タイトルと説明に加えてタグが付いているので、トレーニング用にタグによるフィルターを実装しましょう。私たちの目標はスクリーンショットにあります。タグをクリックすると、このタグが付いたフィルムのみが検索結果に表示されます(番号は横の括弧内に示されています)。

フィルタを実装するには、2つの問題を解決する必要があります。
- リクエストに応じて、どのフィルターセットが利用可能かを理解することを学びます。すべての画面に可能なすべてのフィルター値を表示する必要はありません。それらはたくさんあり、それらのほとんどは空の結果につながるためです。リクエストで見つかったドキュメントのタグを理解する必要があります。理想的には、Nを最も人気のあるものにしておきます。
- 実際、フィルターを適用することを学ぶために-検索結果にタグ付きのドキュメントのみを残すために、ユーザーが選択したフィルター。
Elasticsearchの2番目は、基本的にクエリAPI(クエリという用語を参照)を介して実装され、最初は、少し簡単ではない集計メカニズムを介して実装されます。
したがって、見つかったカードでどのタグが見つかったかを知り、必要なタグでカードをフィルタリングできるようにする必要があります。まず、検索マネージャーの設計を更新しましょう。
# backend/backend/search/searcher.py
import abc
from dataclasses import dataclass
from typing import Iterable, Optional
@dataclass
class TagStats:
tag: str
cards_count: int
@dataclass
class CardSearchResult:
total_count: int
card_ids: Iterable[str]
next_card_offset: Optional[int]
tag_stats: Iterable[TagStats]
class Searcher(metaclass=abc.ABCMeta):
@abc.abstractmethod
def search_cards(self, query: str = "",
count: int = 20, offset: int = 0,
tags: Optional[Iterable[str]] = None) -> CardSearchResult:
pass
それでは、実装に移りましょう。最初に行う必要があるのは、フィールドごとに集計を開始することです
tags。
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -10,6 +10,8 @@ ElasticsearchQuery = Any
class ElasticsearchSearcher(Searcher):
+ TAGS_AGGREGATION_NAME = "tags_aggregation"
+
def __init__(self, elasticsearch_client: Elasticsearch, cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
@@ -18,7 +20,12 @@ class ElasticsearchSearcher(Searcher):
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
"query": self._make_text_query(query) if query else self._match_all_query,
+ "aggregations": {
+ self.TAGS_AGGREGATION_NAME: {
+ "terms": {"field": "tags"}
+ }
+ }
})
これで、Elasticsearchの検索結果で
aggregations、キーを使用して、見つかったドキュメントのフィールドにある値とそれらが発生する頻度に関する情報を含むバケットをTAGS_AGGREGATION_NAME取得できるフィールドが取得されます。このデータを抽出して、上記のように返します。tags
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -28,10 +28,15 @@ class ElasticsearchSearcher(Searcher):
total_count = result["hits"]["total"]["value"]
+ tag_stats = [
+ TagStats(tag=bucket["key"], cards_count=bucket["doc_count"])
+ for bucket in result["aggregations"][self.TAGS_AGGREGATION_NAME]["buckets"]
+ ]
return CardSearchResult(
total_count=total_count,
card_ids=[hit["_id"] for hit in result["hits"]["hits"]],
next_card_offset=offset + count if offset + count < total_count else None,
+ tag_stats=tag_stats,
)
フィルタアプリケーションの追加は最も簡単な部分です。
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -16,11 +16,17 @@ class ElasticsearchSearcher(Searcher):
self.elasticsearch_client = elasticsearch_client
self.cards_index_name = cards_index_name
- def search_cards(self, query: str = "", count: int = 20, offset: int = 0) -> CardSearchResult:
+ def search_cards(self, query: str = "", count: int = 20, offset: int = 0,
+ tags: Optional[Iterable[str]] = None) -> CardSearchResult:
result = self.elasticsearch_client.search(index=self.cards_index_name, body={
"size": count,
"from": offset,
- "query": self._make_text_query(query) if query else self._match_all_query,
+ "query": {
+ "bool": {
+ "must": self._make_text_queries(query),
+ "filter": self._make_filter_queries(tags),
+ }
+ },
"aggregations": {
must-clauseに含まれるサブクエリは必須ですが、ドキュメントの速度を計算するときにも考慮され、それに応じてランク付けされます。テキストに条件を追加する場合は、ここに追加することをお勧めします。filter句のサブクエリは、速度とランキングに影響を与えずにフィルタリングするだけです。
実装する必要があります
_make_filter_queries():
def _make_filter_queries(self, tags: Optional[Iterable[str]] = None) -> List[ElasticsearchQuery]:
return [] if tags is None else [{
"term": {
"tags": {
"value": tag
}
}
} for tag in tags]
繰り返しになりますが、フロントエンドの部分については詳しく説明しません。すべてのコードはこのコミットに含まれています。
レンジング
そのため、検索ではカードを検索し、指定されたタグのリストに従ってカードをフィルタリングし、ある順序で表示します。しかし、どれですか?順序は実際の検索にとって非常に重要ですが、訴訟中に順序に関して行ったすべてのことは
^3、マルチマッチクエリで優先度を指定することにより、説明やタグよりもカードの見出しにある単語を見つける方が有益であるとElasticsearchに示唆されました。
デフォルトでは、ElasticsearchはかなりトリッキーなTF-IDFベースの式でドキュメントをランク付けするという事実にもかかわらず、私たちの想像上の野心的なスタートアップにとって、これはほとんど十分ではありません。私たちの文書が商品である場合、私たちはそれらの売上を説明できる必要があります。ユーザーが作成したコンテンツの場合は、その鮮度などを考慮に入れることができます。ただし、検索クエリとの関連性が考慮されないため、販売数/追加日で単純に並べ替えることはできません。
ランキングは、この記事の最後の1つのセクションではカバーできない、大きくて紛らわしいテクノロジーの領域です。だからここで私は大きなストロークに切り替えています。検索で工業用グレードのランキングをどのように配置できるかを最も一般的な用語で説明し、Elasticsearchでどのように実装できるかについていくつかの技術的な詳細を明らかにします。
ランク付けのタスクは非常に複雑であるため、それを解決するための主要な最新の方法の1つが機械学習であることは驚くべきことではありません。機械学習技術のランク付けへの適用は、まとめてランク付け学習と呼ばれます。
典型的なプロセスは次のようになります。
ランク付けする対象を決定します。関心のあるエンティティをインデックスに入れ、これらのエンティティの特定の検索クエリ(たとえば、単純な並べ替えや切り取り)に対して妥当なトップを取得する方法を学びます。次に、よりインテリジェントな方法でランク付けする方法を学びます。
ランク付けする方法を決定する..。サービスのビジネス目標に従って、結果をランク付けする特性を決定します。たとえば、エンティティが販売する製品である場合、購入の可能性の高い順に並べ替えることができます。ミームの場合-いいねや共有の可能性などによって。もちろん、これらの確率を計算する方法はわかりません-せいぜい推定できますが、それでも十分な統計がある古いエンティティについてのみです-しかし、間接的な符号に基づいてそれらを予測するようにモデルに教えようとします。
兆候の抽出..。検索クエリに対するエンティティの関連性を評価するのに役立つ、エンティティの一連の機能を考え出します。 Elasticsearchの計算方法をすでに知っている同じTF-IDFに加えて、典型的な例はCTR(クリックスルー率)です。エンティティと検索クエリのペアごとに、エンティティが検索結果に表示された回数をカウントし、サービスのログを常に取得します。このリクエストとクリックされた回数について、一方を他方で除算します。条件付きクリック確率の最も簡単な見積もりが用意されています。また、ランキングをパーソナライズするために、ユーザー固有の特性とユーザーエンティティのペアの特性を考え出すこともできます。サインを思いついたので、それらを計算し、ある種のストレージに入れ、特定の検索クエリ、ユーザー、およびエンティティのセットに対してリアルタイムでサインを与える方法を知っているコードを記述します。
トレーニングデータセットをまとめる。多くのオプションがありますが、原則として、それらはすべて、サービスの「良い」(クリックしてから購入など)イベントと「悪い」(クリックして問題に戻るなど)イベントのログから形成されます。データセットを作成すると、「製品XとクエリQの関連性の評価はPにほぼ等しい」というステートメントのリスト、「製品Xは製品YとクエリQの関連性が高い」というペアのリスト、または「クエリQ、製品P 1、P 2、...のリストのセットはこのように正しくランク付けされます。 -その "、それに表示されるすべての行に対応する記号を締めます。
モデルをトレーニングします。これがすべてのMLクラシックです:トレーニング/テスト、ハイパーパラメーター、再トレーニング、
モデルを埋め込みます。すでにランク付けされた結果がユーザーに届くように、トップ全体のモデルの計算をその場でどうにかしてねじ込む必要があります。多くのオプションがあります。説明のために、(再び)単純なElasticsearchプラグインLearning toRankに焦点を当てます。
ランキング:Elasticsearch Learning to RankPlugin
Elasticsearch Learning to Rankは、SERPでMLモデルを計算し、計算されたレートに従って結果を即座にランク付けする機能をElasticsearchに追加するプラグインです。また、Elasticsearchの機能(TF-IDFなど)を再利用しながら、リアルタイムで使用されるものと同じ機能を取得するのにも役立ちます。
まず、コンテナ内のプラグインをElasticsearchに接続する必要があります。単純なDockerfileが必要です
# elasticsearch/Dockerfile
FROM elasticsearch:7.5.1
RUN ./bin/elasticsearch-plugin install --batch http://es-learn-to-rank.labs.o19s.com/ltr-1.1.2-es7.5.1.zip
および関連する変更
docker-compose.yml:
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -5,7 +5,8 @@ services:
elasticsearch:
- image: "elasticsearch:7.5.1"
+ build:
+ context: elasticsearch
environment:
- discovery.type=single-node
Pythonクライアントでのプラグインサポートも必要です。Pythonのサポートがプラグインに含まれていないことに驚いたので、この記事のために特別に書き留めました。配線でクライアントに追加
elasticsearch_ltrしrequirements.txtてアップグレードします。
--- a/backend/backend/wiring.py
+++ b/backend/backend/wiring.py
@@ -1,5 +1,6 @@
import os
+from elasticsearch_ltr import LTRClient
from celery import Celery
from elasticsearch import Elasticsearch
from pymongo import MongoClient
@@ -39,5 +40,6 @@ class Wiring(object):
self.task_manager = TaskManager(self.celery_app)
self.elasticsearch_client = Elasticsearch(hosts=self.settings.ELASTICSEARCH_HOSTS)
+ LTRClient.infect_client(self.elasticsearch_client)
self.indexer = Indexer(self.elasticsearch_client, self.card_dao, self.settings.CARDS_INDEX_ALIAS)
self.searcher: Searcher = ElasticsearchSearcher(self.elasticsearch_client, self.settings.CARDS_INDEX_ALIAS)
ランキング:のこぎりの兆候
Elasticsearchの各リクエストは、見つかったドキュメントのIDのリストだけでなく、すぐにいくつかのIDも返します(スコアという単語をロシア語にどのように変換しますか?)。したがって、これが使用している一致または複数一致のクエリである場合、高速はTF-IDFを含む非常にトリッキーな式を計算した結果です。場合ブールクエリは、ネストされたクエリ速度の組み合わせです。関数スコアクエリの場合-特定の関数(たとえば、ドキュメント内の数値フィールドの値)を計算した結果など。 ELTRプラグインは、任意の要求の速度を記号として使用する機能を提供し、ドキュメントが要求とどの程度一致しているかに関するデータ(マルチマッチクエリを介して)と、事前にドキュメントに入力したいくつかの事前計算された統計(関数スコアクエリを介して)を簡単に組み合わせることができます。 ..。
TMDB 5000データベースが手元にあるので、映画の説明とその評価などが含まれているので、事前に計算された機能の例として評価を取り上げましょう。
で、このコミットWebアプリケーションのバックエンドに機能を保存するための基本的なインフラストラクチャをいくつか追加し、ムービーファイルからの評価の読み込みをサポートしました。別のコードを読まなくてはならないように、最も基本的なことを説明します。
- 機能を別のコレクションに保存し、別のマネージャーが取得します。すべてのデータを1つのエンティティにダンプすることは悪い習慣です。
- インデックス作成の段階でこのマネージャーに連絡し、利用可能なすべての機能をインデックス作成されたドキュメントに配置します。
- インデックススキーマを知るには、インデックスの作成を開始する前に、既存のすべての機能のリストを知る必要があります。今のところ、このリストをハードコーディングします。
- 属性値でドキュメントをフィルタリングするのではなく、モデルを計算するためにすでに見つかったドキュメントからそれらを抽出するだけな
index: falseので、スキーマのオプションを使用して新しいフィールドによる逆インデックスの作成をオフにし、これにより少しスペースを節約します。
ランキング:データセットの収集
第一に、私たちは生産を行っておらず、第二に、この記事の余白は、テレメトリー、Kafka、NiFi、Hadoop、Spark、およびETLプロセスの構築についての話には小さすぎるため、カードのランダムなビューとクリックを生成します。ある種の検索クエリ。その後、結果のカードとリクエストのペアの特性を計算する必要があります。
ELTRプラグインAPIをさらに深く掘り下げる時が来ました。特徴を計算するには、特徴ストアエンティティを作成する必要があります(私が理解している限り、これは実際にはプラグインがすべてのデータを格納するElasticsearchの単なるインデックスです)、次に特徴セット(各特徴の計算方法の説明を含む特徴のリスト)を作成します。その後、特別なリクエストでElasticsearchにアクセスして、見つかった各エンティティの特徴値のベクトルを取得するだけで十分です。
機能セットを作成することから始めましょう:
# backend/backend/search/ranking.py
from typing import Iterable, List, Mapping
from elasticsearch import Elasticsearch
from elasticsearch_ltr import LTRClient
from backend.search.features import CardFeaturesManager
class SearchRankingManager:
DEFAULT_FEATURE_SET_NAME = "card_features"
def __init__(self, elasticsearch_client: Elasticsearch,
card_features_manager: CardFeaturesManager,
cards_index_name: str):
self.elasticsearch_client = elasticsearch_client
self.card_features_manager = card_features_manager
self.cards_index_name = cards_index_name
def initialize_ranking(self, feature_set_name=DEFAULT_FEATURE_SET_NAME):
ltr: LTRClient = self.elasticsearch_client.ltr
try:
# feature store ,
# ¯\_(ツ)_/¯
ltr.create_feature_store()
except Exception as exc:
if "resource_already_exists_exception" not in str(exc):
raise
# feature set !
ltr.create_feature_set(feature_set_name, {
"featureset": {
"features": [
#
# ,
# ,
# .
self._make_feature("name_tf_idf", ["query"], {
"match": {
# ELTR
# , .
# , ,
# ,
# match query.
"name": "{{query}}"
}
}),
# , .
self._make_feature("combined_tf_idf", ["query"], {
"multi_match": {
"query": "{{query}}",
"fields": ["name^3", "tags.text", "text"]
}
}),
*(
#
# function score.
# -
# , 0.
# (
# !)
self._make_feature(feature_name, [], {
"function_score": {
"field_value_factor": {
"field": feature_name,
"missing": 0
}
}
})
for feature_name in sorted(self.card_features_manager.get_all_feature_names_set())
)
]
}
})
@staticmethod
def _make_feature(name, params, query):
return {
"name": name,
"params": params,
"template_language": "mustache",
"template": query,
}
Now-特定のクエリとカードの機能を計算する関数:
def compute_cards_features(self, query: str, card_ids: Iterable[str],
feature_set_name=DEFAULT_FEATURE_SET_NAME) -> Mapping[str, List[float]]:
card_ids = list(card_ids)
result = self.elasticsearch_client.search({
"query": {
"bool": {
# ,
# — ,
# .
# ID.
"filter": [
{
"terms": {
"_id": card_ids
}
},
# — ,
# SLTR.
#
# feature set.
# ( ,
# filter, .)
{
"sltr": {
"_name": "logged_featureset",
"featureset": feature_set_name,
"params": {
# .
# , ,
#
# {{query}}.
"query": query
}
}
}
]
}
},
#
# .
"ext": {
"ltr_log": {
"log_specs": {
"name": "log_entry1",
"named_query": "logged_featureset"
}
}
},
"size": len(card_ids),
})
# (
# ) .
# ( ,
# , Kibana.)
return {
hit["_id"]: [feature.get("value", float("nan")) for feature in hit["fields"]["_ltrlog"][0]["log_entry1"]]
for hit in result["hits"]["hits"]
}
リクエストとIDカードを入力としてCSVを受け入れ、次の機能を備えたCSVを出力する単純なスクリプト。
# backend/tools/compute_movie_features.py
import csv
import itertools
import sys
import tqdm
from backend.wiring import Wiring
if __name__ == "__main__":
wiring = Wiring()
reader = iter(csv.reader(sys.stdin))
header = next(reader)
feature_names = wiring.search_ranking_manager.get_feature_names()
writer = csv.writer(sys.stdout)
writer.writerow(["query", "card_id"] + feature_names)
query_index = header.index("query")
card_id_index = header.index("card_id")
chunks = itertools.groupby(reader, lambda row: row[query_index])
for query, rows in tqdm.tqdm(chunks):
card_ids = [row[card_id_index] for row in rows]
features = wiring.search_ranking_manager.compute_cards_features(query, card_ids)
for card_id in card_ids:
writer.writerow((query, card_id, *features[card_id]))
最後に、すべてを実行できます!
# feature set
docker-compose exec backend python -m tools.initialize_search_ranking
#
docker-compose exec -T backend \
python -m tools.generate_movie_events \
< ~/Downloads/tmdb-movie-metadata/tmdb_5000_movies.csv \
> ~/Downloads/habr-app-demo-dataset-events.csv
#
docker-compose exec -T backend \
python -m tools.compute_features \
< ~/Downloads/habr-app-demo-dataset-events.csv \
> ~/Downloads/habr-app-demo-dataset-features.csv
これで、イベントとサインを含む2つのファイルができ、トレーニングを開始できます。
ランキング:モデルのトレーニングと実装
データセットのロードの詳細をスキップして(このコミットで完全なスクリプトを確認できます)、要点を直接理解しましょう。
# backend/tools/train_model.py
...
if __name__ == "__main__":
args = parser.parse_args()
feature_names, features = read_features(args.features)
events = read_events(args.events)
# train test 4 1.
all_queries = set(events.keys())
train_queries = random.sample(all_queries, int(0.8 * len(all_queries)))
test_queries = all_queries - set(train_queries)
# DMatrix — , xgboost.
#
# . 1, ,
# 0, ( . ).
train_dmatrix = make_dmatrix(train_queries, events, feature_names, features)
test_dmatrix = make_dmatrix(test_queries, events, feature_names, features)
# !
#
# ML,
# XGBoost.
param = {
"max_depth": 2,
"eta": 0.3,
"objective": "binary:logistic",
"eval_metric": "auc",
}
num_round = 10
booster = xgboost.train(param, train_dmatrix, num_round, evals=((train_dmatrix, "train"), (test_dmatrix, "test")))
# .
booster.dump_model(args.output, dump_format="json")
# , :
# ROC-.
xgboost.plot_importance(booster)
plt.figure()
build_roc(test_dmatrix.get_label(), booster.predict(test_dmatrix))
plt.show()
ローンチ
python backend/tools/train_search_ranking_model.py \
--events ~/Downloads/habr-app-demo-dataset-events.csv \
--features ~/Downloads/habr-app-demo-dataset-features.csv \
-o ~/Downloads/habr-app-demo-model.xgb
してください私たちは、以前のスクリプトで必要なすべてのデータをエクスポートするので、このスクリプトはもはやニーズがドッキングウィンドウ内で実行されることに注意してください-それは、以前にインストールした、あなたのマシン上で実行する必要があります
xgboostとsklearn。同様に、実際の本番環境では、以前のスクリプトは本番環境にアクセスできる場所で実行する必要がありますが、これはそうではありません。
すべてが正しく行われると、モデルは正常にトレーニングされ、2つの美しい写真が表示されます。1つ目は、機能の重要性のグラフです。

イベントはランダムに生成されましたが、
combined_tf_idf以前の方法でランク付けされた、検索結果の下位にあるカードのクリックの可能性を人為的に低くしたため、他のカードよりもはるかに重要であることが判明しました。モデルがこれに気づいたという事実は良い兆候であり、学習プロセスで完全に愚かな間違いをしなかったことの兆候です。
2番目のグラフはROC曲線です。

青い線は赤い線の上にあります。これは、モデルがコイントスよりもラベルを少し良く予測していることを意味します。 (ママの友人のMLエンジニアカーブは、ほぼ左上隅に触れるはずです。)
問題は非常に小さいです-モデルを埋めるためのスクリプトを追加し、それを埋めて、検索クエリに小さな新しいアイテムを追加します-再スコアリング:
--- a/backend/backend/search/searcher_impl.py
+++ b/backend/backend/search/searcher_impl.py
@@ -27,6 +30,19 @@ class ElasticsearchSearcher(Searcher):
"filter": list(self._make_filter_queries(tags, ids)),
}
},
+ "rescore": {
+ "window_size": 1000,
+ "query": {
+ "rescore_query": {
+ "sltr": {
+ "params": {
+ "query": query
+ },
+ "model": self.ranking_manager.get_current_model_name()
+ }
+ }
+ }
+ },
"aggregations": {
self.TAGS_AGGREGATION_NAME: {
"terms": {"field": "tags"}
ここで、Elasticsearchが必要な検索を実行し、その(かなり速い)アルゴリズムで結果をランク付けした後、上位1000の結果を取得し、(比較的遅い)機械学習式を使用して再ランク付けします。成功!
結論
最小限のWebアプリケーションを採用し、検索機能自体がない状態から、多くの高度な機能を備えたスケーラブルなソリューションに移行しました。これはそれほど簡単ではありませんでした。しかし、それもそれほど難しいことではありません!最終的なアプリケーションは、控えめな名前のブランチのGithubのリポジトリにあり、実行するには、
feature/searchDockerとPython3とマシンラーニングライブラリが必要です。
Elasticsearchを使用して、これが一般的にどのように機能するか、どのような問題が発生し、どのように解決できるかを示しましたが、これが選択できる唯一のツールではありません。Solr、PostgreSQLフルテキストインデックス、およびその他のエンジンも、
そしてもちろん、このソリューションは完全で生産の準備ができているふりをするのではなく、すべてがどのように行われるかを純粋に示しています。あなたはそれをほぼ無限に改善することができます!
- インクリメンタルインデックス。カードを変更するとき
CardManagerは、インデックスですぐに更新するとよいでしょう。CardManagerサービス内にも検索があることを知らないために、そして循環的な依存関係なしで行うために、何らかの形で依存関係の反転をねじ込む必要があります。 - 特定のケースであるElasticsearchにバンドルされているMongoDBのインデックス作成には、mongo-connectorなどの既製のソリューションを使用できます。
- , — Elasticsearch .
- , , .
- , , . -, -, - … !
- ( , ), ( ). , .
- , , .
- シャーディングとレプリケーションを使用してノードのクラスターを調整することは、まったく別の楽しみです。
しかし、記事のサイズを読みやすくするために、ここでやめて、これらの課題に取り残します。ご清聴ありがとうございました!