
URALCHEMは肥料を作ります。ロシアで第1位-たとえば硝酸アンモニウムの生産では、アンモニア、尿素、窒素肥料の国内生産者のトップ3に入っています。硫酸、2〜3成分の肥料、リン酸塩などが生産されます。これらすべてが、センサーが故障する攻撃的な環境を作り出します。
Data Lakeを構築すると同時に、フリーズ、障害、誤ったデータの提供を開始し、一般に情報ソースの動作とは異なる動作をするセンサーを探しました。そして「トリック」は、「悪い」データに基づいて数学モデルとデジタルツインを構築することは不可能であるということです。それらは単に問題を正しく解決せず、ビジネス効果をもたらしません。
しかし、現代の工場はデータ科学者のためにデータレイクを必要としています。 95%の場合、「生の」データはまったく収集されませんが、プロセス制御システムの集計のみが考慮され、2か月間保存され、インジケーターの「ダイナミクスの変化」のポイントが保存されます。これは、データ科学者にとってデータの品質を低下させる特別に定められたアルゴリズムによって計算されます。 。、おそらく、インジケーターの「バースト」を見逃す可能性があります...実際には、そのようなことがURALCHEMで発生しました。生産データの倉庫を作成し、店舗やMES / ERPシステムでソースを取得する必要がありました。まず第一に、これはデータサイエンスの履歴の収集を開始するために必要です。次に、データサイエンティストが計算用のプラットフォームと仮説をテストするためのサンドボックスを持ち、プロセス制御システムが回転している場所に同じものをロードしないようにします。データサイエンティストは利用可能なデータを分析しようとしましたが、これだけでは不十分でした。データは間引きされて保存され、損失が発生し、多くの場合センサーと矛盾していました。データセットをすばやく取得することはできず、データを操作する場所もありませんでした。
それでは、センサーが「駆動」した場合の対処方法に戻りましょう。
湖を建てるとき
そのようなものを構築するだけでは十分ではありません。
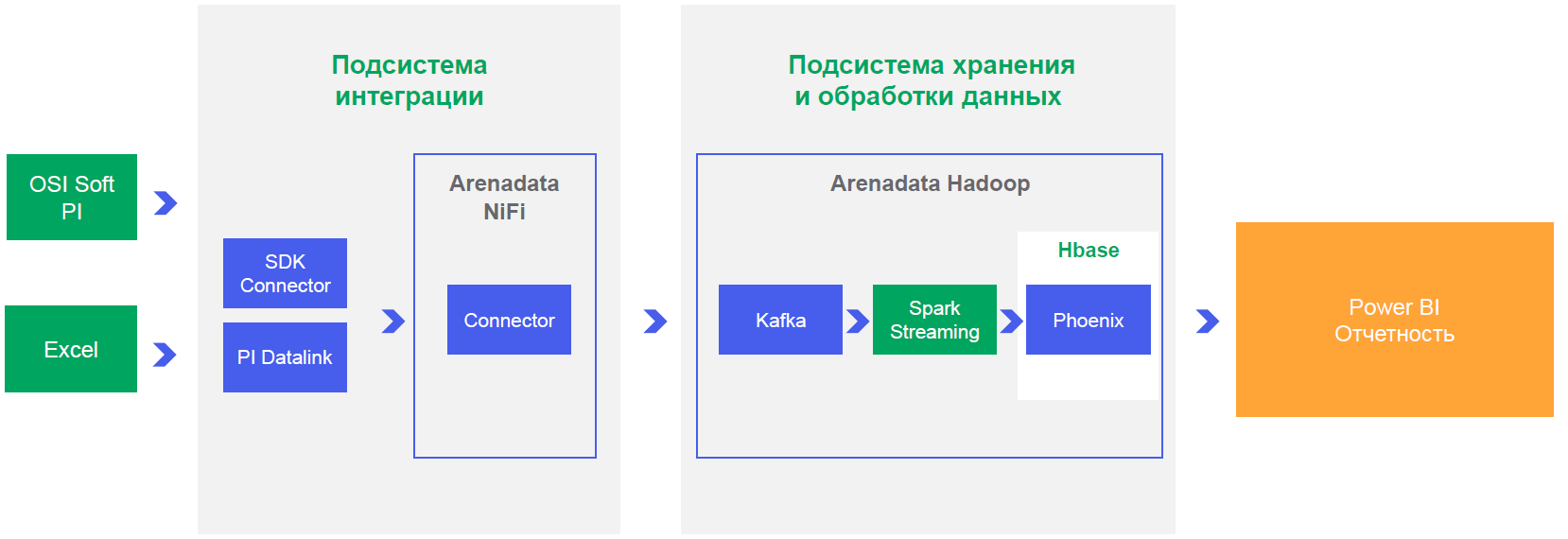
すべてが機能していることをビジネスに証明し、1つの完了したプロジェクトの例を示す必要もあります。そのようなコンバインで1つのプロジェクトを行うことは、単一の国で共産主義を構築する方法に関することであることは明らかですが、条件はまさにそれです。私たちは顕微鏡を取り、彼らが釘を打つことができることを証明します。
世界的に、URALCHEMは生産のデジタル化を任務としています。このすべてのアクションの一環として、まず、仮説をテストするためのサンドボックスを作成し、生産プロセスの効率を改善し、機器の故障の予測モデル、意思決定支援システムを開発して、ダウンタイムの数を減らし、生産プロセスの品質を向上させます。これは、何かが失敗しようとしていることを事前に知っているときであり、マシンがすべてを粉砕し始める1週間前にそれを修復できます。メリット-製造コストの削減と製品品質の向上。
これは、プラットフォームの基準とパイロットの基本要件がどのように現れたかです。大量の情報の保存、ビジネスインテリジェンスシステムからのデータへの迅速なアクセス、推奨事項や通知をできるだけ早く発行するためのほぼリアルタイムの計算です。
統合オプションを検討し、NRTモードでのパフォーマンスと操作を行うには、コネクタを介してのみ作業する必要があることに気付きました。これにより、Kafka(水平方向にスケーラブルなメッセージブローカーで、センサーの読み取り値を変更する「イベントにサブスクライブ」するだけで、計算を行い、通知を生成するために、その場でこのイベントのちなみに、URALCHEMJSCのOTSO支社である生産システム開発部長のArturKhismatullinさんには大変助かりました。
たとえば、機器の故障の予測モデルを作成するには何が必要ですか?
これには、各ノードからのリアルタイムまたはそれに近いスライスでのテレメトリーが必要です。つまり、1時間に1回の一般的なステータスではなく、毎秒のすべてのセンサーの直接的な特定の読み取り値です。
誰もこのデータを収集または保存しません。さらに、少なくとも6か月間の履歴データが必要であり、プロセス制御システムでは、前述したように、過去3か月までの履歴データが保存されます。つまり、データはどこかから収集され、どこかに書き込まれ、どこかに保存されるという事実から始める必要があります。ノードあたり年間約10GBのデータ。
さらに、このデータを何らかの方法で処理する必要があります。これには、通常はデータベースから選択できるインストールが必要です。そして、複雑な結合では、すべてが1日起きないことが望ましいです。特に後で、生産が結婚を予測するというより多くの問題を追加し始めるとき。まあ、予測修理についても、30分前に故障したときにマシンが故障する可能性があるという夕方の報告-まあまあの場合。
その結果、湖はデータ科学者にとって必要とされています。
他の同様のソリューションとは異なり、Hadoopではリアルタイムのタスクがまだありました。次の大きな課題は、材料組成、物質の品質の分析、生産の材料消費に関するデータであるためです。
実際、プラットフォーム自体を構築したとき、ビジネスが次に望んでいたのは、センサーの障害に関するデータを収集し、ワーカーを派遣してセンサーを変更したり、サービスを提供したりできるシステムを構築することでした。そして同時に、彼らからの証言を歴史上誤っているものとしてマークします。
センサー
実稼働環境(攻撃的な環境)では、センサーは困難な方法で機能し、多くの場合失敗します。理想的には、予測監視システムもセンサーに必要ですが、最初に、少なくともどれが存在し、どれが存在しないかの評価が必要です。
センサーに何があるかを決定する単純なモデルでさえ、もう1つのタスク(数学的バランスの構築)にとって重要であることが判明しました。プロセスの適切な計画-投入する必要のある量と量、加熱方法、処理方法:計画が間違っていると、必要な原材料の量が明確になりません。十分な製品が生産されません-企業は利益を上げません。必要以上にある場合-あなたが保存する必要があるので、再び損失。正しい材料バランスは、センサーからの正しい情報からのみ取得できます。
そのため、パイロットプロジェクトでは、生産データの品質監視が選択されました。
「生の」データについて技術者と話し合い、確認された機器の故障を調べました。最初の2つの理由は非常に単純です。
ここで、センサーは突然、原則として表示されるべきではないデータを表示し始めます。
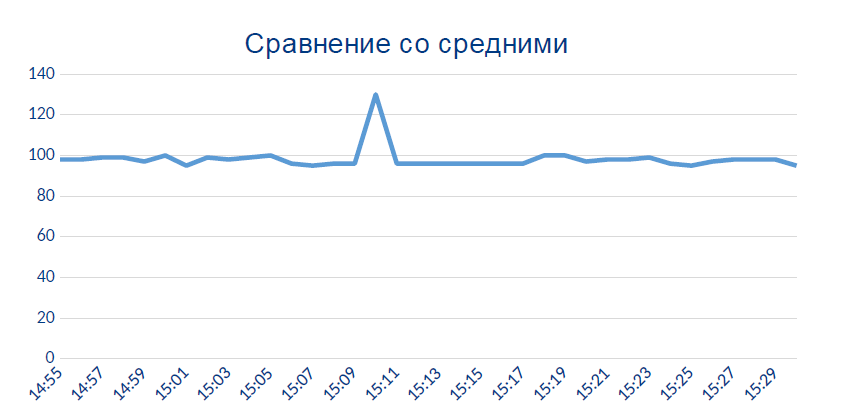
おそらく、この局所的なピークは、センサーが熱的または化学的に不良になった瞬間です。
また、許容測定限界を超えています(水の温度のような物理的な量が0〜100の場合)。ゼロでは、水はシステム内を移動せず、200では蒸気であり、ワークショップの上に屋根がないことからこの事実に気づいたでしょう。
2番目のケースもほとんど些細なことです。
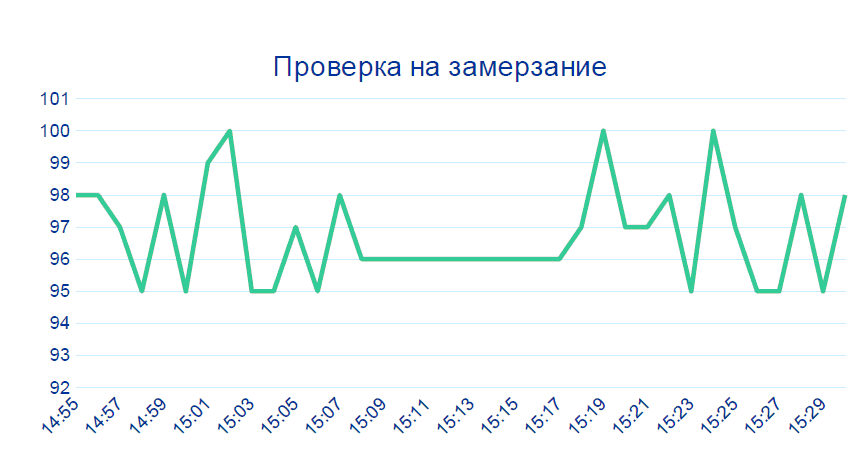
センサーからのデータは数分間連続して変化しません。これはライブプロダクションでは発生しません。ほとんどの場合、デバイスに何かがあります。
問題の80%は、ビッグデータ、相関関係、データ履歴なしでこれらのパターンを追跡することで解決されます。ただし、99%を超える精度を得るには、特に疑わしいテレメトリが発生するセクションの前後で、隣接ノードの他のセンサーとの別の比較を追加する必要があります。
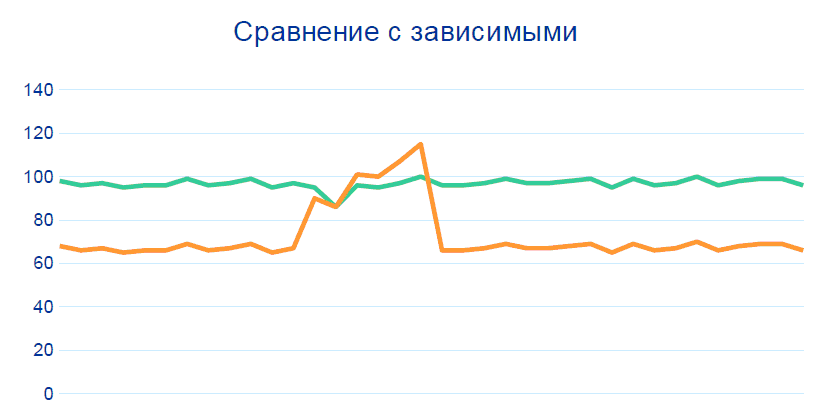
生産はバランスの取れたシステムです。一方のインジケーターが変更されると、もう一方も変更する必要があります。プロジェクトの枠組みの中で、指標の関係に関する規則が形成され、これらの関係は技術者によって「正規化」されました。これらのガイドラインに基づいて、Hadoopベースのシステムは潜在的に動作しないセンサーを識別できます。
プラントのオペレーターは、センサーが正しく検出されたことを喜んでいました。これは、修理業者を迅速に派遣したり、目的のセンサーを簡単に清掃したりできることを意味します。
実際、パイロットは、誤った情報を表示する、動作しない可能性のあるセンサーをショップにリストすることになりました。
緊急事態および緊急事態前の状況への対応が以前にどのように実施されたか、そしてプロジェクト後にどのようになったかを尋ねることができます。このような状況では、複数のセンサーが一度に問題を表示するため、事故への反応が遅くなることはありません。
技術者または部門の責任者のいずれかが、設置の効率(および事故の場合のアクション)に責任を負います。彼らは自分たちの機器で何がどのように起こっているかを完全に理解しており、いくつかのセンサーを無視することができます。インストールに伴うプロセス制御システムは、データの品質に責任があります。通常、センサーが損傷している場合、センサーは非動作モードにはなりません。技術者にとって、彼は労働者のままです;技術者は反応しなければなりません。技術者はイベントをチェックし、何も起こらなかったことを発見します。 「ダイナミクスのみを分析し、絶対値は調べません。それらが正しくないことがわかっているので、センサーを調整する必要があります。」自動プロセス制御システムの専門家に、センサーが間違っていることと、どこが間違っているかを「強調」します。現在、彼は計画された正式なラウンドの代わりに、最初に特定のデバイスを的を絞った方法で修理し、次にテクノロジーを信頼せずにラウンドを行います。
計画された歩行にかかる時間を明確にするために、各サイトに3〜5千のセンサーがあると簡単に言います。処理されたデータを提供する包括的な分析ツールを提供しました。これに基づいて、スペシャリストが検証を決定する必要があります。彼の経験に基づいて、私たちは必要なものを正確に「強調」します。各センサーを手動でチェックする必要がなくなり、何かが見落とされる可能性が低くなります。
結果は何ですか
スタックを使用して生産上の問題を解決できるというビジネス確認を受け取りました。サイトデータを保存および処理します。ビジネスは、データサイエンティストが運用するために、次のプロセスを選択する必要があります。彼らはデータ品質管理の責任者を任命しますが、彼のために規則を書き、これを彼らの生産プロセスに実装します。
このケースを実装した方法は次のとおりです。
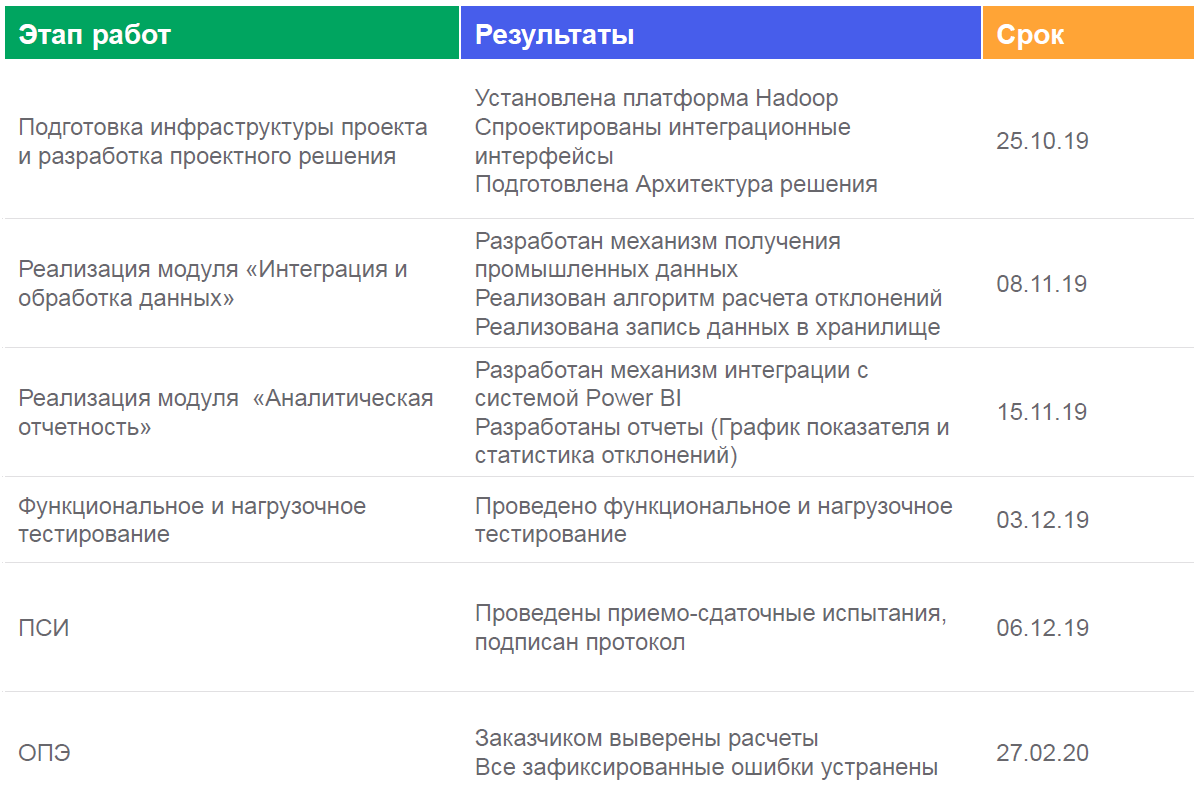
ダッシュボードは次のようになります。次のよう
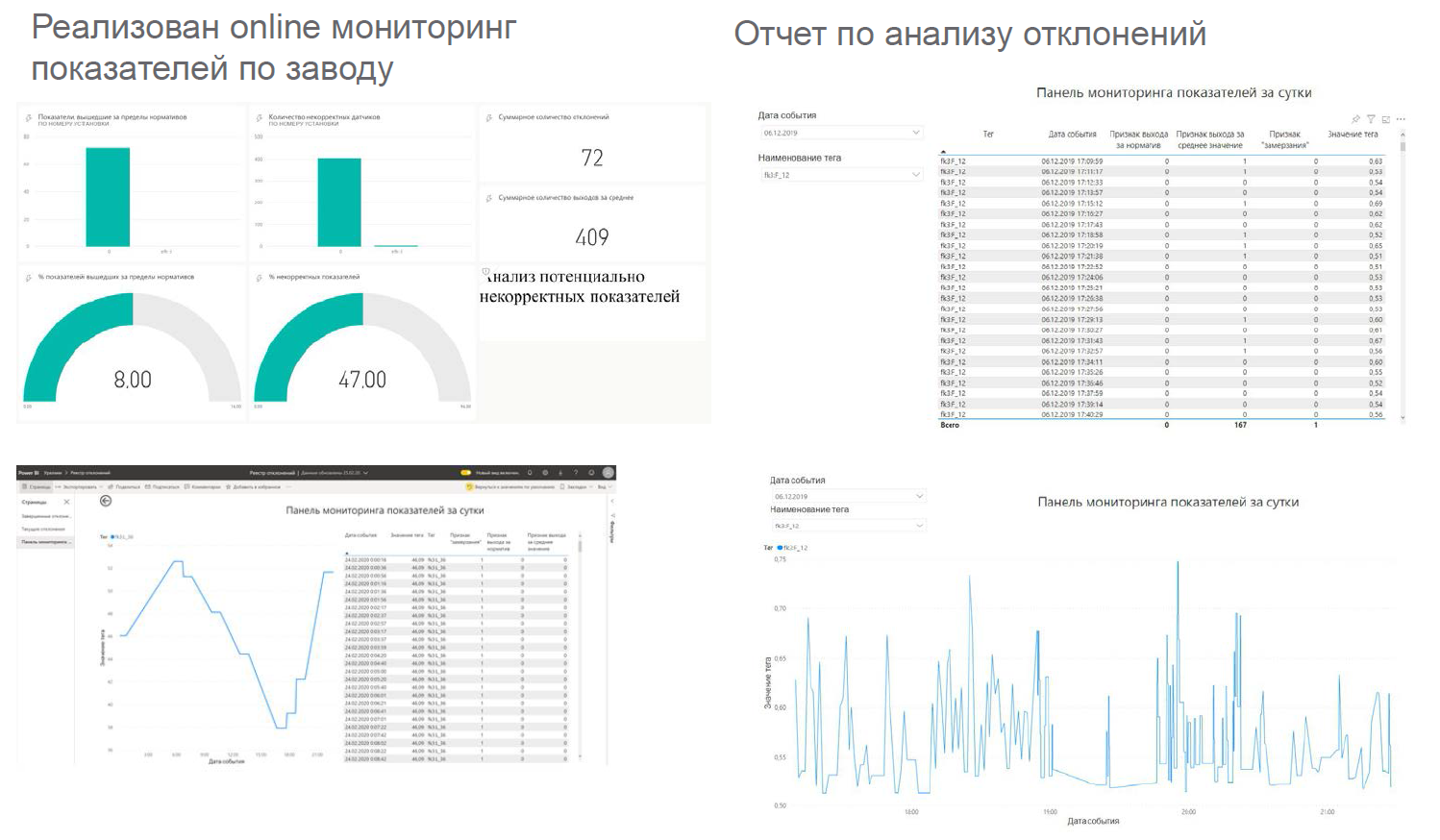
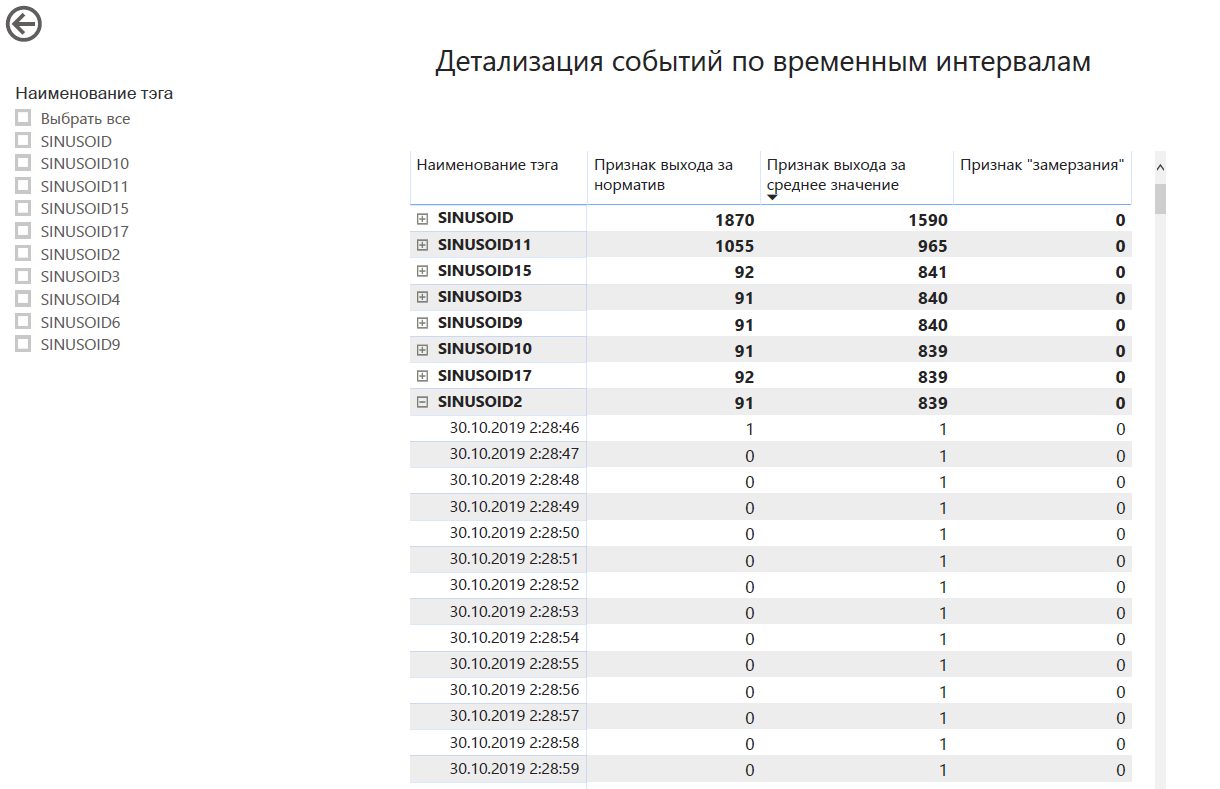
な場所に表示され

ます。
- 機器センサーからの読み取り値を処理するために、技術レベルで情報スペースが作成されました。
- ビッグデータテクノロジーに基づいてデータを保存および処理する機能を検証しました。
- Arenadata Hadoopプラットフォーム上に構築されたデータレイクと連携するビジネスインテリジェンスシステム(Power BIなど)の機能をテストしました。
- 機器センサーから生産情報を収集するために統合分析ストレージが導入され、情報を長期間保存できる可能性があります(1年間の累積データの計画量は約2テラバイトです)。
- ほぼリアルタイムモードでデータを取得するためのメカニズムと方法が開発されました。
- ほぼリアルタイムモード(計算-1分に1回)でのセンサーの偏差と誤った動作を決定するためのアルゴリズムが開発されました。
- システム動作のテストとBIツールでレポートを生成する機能が実行されました。
肝心なのは、生産上の問題を完全に解決したことです。つまり、日常的なプロセスを自動化しました。予測ツールを提供し、技術者がよりインテリジェントな問題を解決するための時間を解放しました。
それでもコメント以外の質問がある場合は、ここにメールがあります-chemistry@croc.ru