
あなたの会社は、プライバシーを犠牲にすることなく傾向を研究するためにデータを収集して分析したいと思っていますか?または、おそらく、すでにさまざまなツールを使用して保存し、知識を深めたり、経験を共有したりしたいですか?いずれにせよ、この資料はあなたのためです。
このシリーズの記事を始めたきっかけは何ですか?NIST(国立標準技術研究所)は昨年、プライバシーエンジニアリングコラボレーションスペースを立ち上げました-オープンソースツール、およびシステムの機密性の設計とリスク管理に必要なプロセスのソリューションと説明を含む、協力のためのプラットフォーム。このスペースのモデレーターとして、NISTが匿名化の分野で利用可能な差別化プライバシーツールを収集するのを支援します。 NISTは、プライバシーフレームワーク:エンタープライズリスク管理を通じてプライバシーを改善するためのツールと、匿名化を含むさまざまなプライバシーの懸念を概説するアクションプランも公開しました。ここで、Collaboration Spaceが匿名化(匿名化)の計画で設定された目標を達成できるように支援したいと思います。最終的には、NISTがこの一連の出版物を、プライバシーの違いに関するより詳細なガイドに発展させるのを支援してください。
各記事は、ビジネスプロセスの所有者やデータプライバシー担当者などの専門家が危険になるのに十分なことを学ぶのに役立つ基本的な概念とアプリケーションの例から始まります(冗談です)。基本を確認した後、利用可能なツールとそれらで使用されるアプローチを分析します。これは、特定の実装に取り組んでいる人にとってすでに役立ちます。
最初の記事は、次の記事で使用する差分プライバシーの主要な概念と概念を説明することから始めます。
問題の定式化
人口の特定のメンバーに影響を与えることなく、どのようにして人口データを研究できますか?2つの質問に答えてみましょう。
- バーモントには何人住んでいますか?
- ジョーニアという名前の人は何人バーモントに住んでいますか?
最初の質問は全人口の特性に関するものであり、2番目の質問は特定の人に関する情報を明らかにします。特定の個人に関する情報を許可せずに、人口全体の傾向を把握できる必要があります。
しかし、「バーモントには何人の人が住んでいるのか」という質問にどのように答えることができますか? -これをさらに「問い合わせ」と呼びます-「ジョー・ニールという名前の人はバーモントに何人住んでいますか?」という2番目の質問には答えません。最も一般的な解決策は、匿名化(または匿名化)です。これは、データセットからすべての識別情報を削除することで構成されます(以下、データセットには特定の人物に関する情報が含まれていると考えられます)。もう1つのアプローチは、たとえば平均を使用した集計クエリのみを許可することです。残念ながら、どのアプローチも必要なプライバシー保護を提供していないことはすでにわかっています。匿名化されたデータは、他のデータベースとのリンクを確立する攻撃のターゲットです。集約は、サンプリンググループのサイズが次の場合にのみプライバシーを保護します十分な大きさ。しかし、そのような場合でも、攻撃は成功する可能性があります[1、2、3、4]。
プライバシーの違い
差別的プライバシー[5、6]は、「プライバシーを持つ」という概念の数学的な定義です。これは特定のプロセスではなく、プロセスが所有できるプロパティです。たとえば、特定のプロセスが差別的プライバシーの原則を満たしていることを計算(証明)できます。
簡単に言えば、データが分析対象のデータセットにある人ごとに、差分プライバシーにより、データがデータセットにあるかどうかに関係なく、差分プライバシー分析の結果を実質的に区別できなくなります。差分プライバシー分析はしばしばメカニズムと呼ばれ、これを次のように呼びます。..。
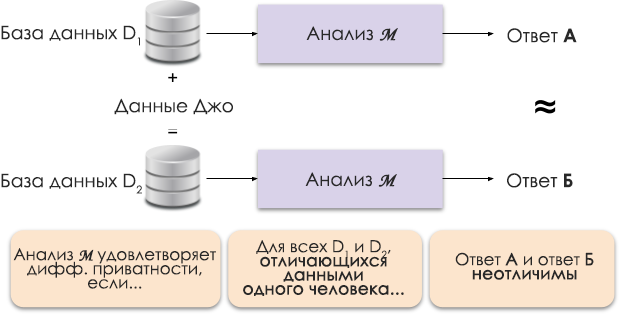
図1:差別化されたプライバシーの概略図。
差分プライバシーの原理を図1に示します。回答Aはジョーのデータなしで計算され、回答Bは彼のデータを使用して計算されます。そして、両方の答えが区別できないだろうと主張されています。つまり、結果を見た人は誰でも、ジョーのデータが使用されたのか、使用されなかったのかを知ることができません。プライバシーパラメータεを変更すること
により、必要なプライバシーレベルを制御します。これは、プライバシー損失またはプライバシー予算とも呼ばれます。 ε値が小さいほど、結果の識別が難しくなり、個人のデータの安全性が高まります。
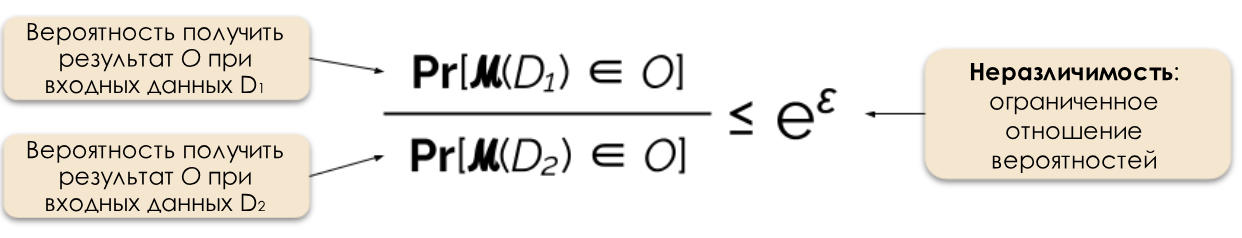
図2:差分プライバシーの正式な定義。
多くの場合、応答にランダムノイズを追加することで、プライバシーの違いで要求に応答できます。難しいのは、追加するノイズの場所と量を正確に決定することです。最も一般的なノイズ汚染メカニズムの1つは、ラプラスメカニズムです[5、7]。
プライバシー要求の増加は、差動プライバシーの特定のイプシロン値を満たすためにより多くのノイズを必要とします。そして、この追加のノイズは、結果の有用性を低下させる可能性があります。今後の記事では、プライバシーと、プライバシーとユーティリティの間のトレードオフについて詳しく説明します。
異なるプライバシーの利点
プライバシーの違いには、以前の手法に比べていくつかの重要な利点があります。
- , , ( ) .
- , .
- : , . , . , .
これらの利点のために、実際には差分プライバシー方式の適用が他のいくつかの方式よりも好ましい。コインの裏側は、この方法論がまったく新しいことであり、学術研究コミュニティの外で実証済みのツール、標準、および実証済みのアプローチを見つけることは容易ではありません。ただし、データのプライバシーを保護するための信頼性の高いシンプルなソリューションに対する需要が高まっているため、近い将来、状況は改善すると考えています。
次は何ですか?
私たちのブログを購読してください。まもなく次の記事の翻訳を投稿します。この記事では、差別化プライバシーのシステムを構築する際に考慮しなければならない脅威モデルについて説明し、中央とローカルの差別化プライバシーモデルの違いについて説明します。
ソース
[1]ガーフィンケル、シムソン、ジョンM.アボウド、クリスチャンマーティンデール。「公開データに対するデータベース再構築攻撃を理解する。」ACM 62.3(2019)の通信:46-53。
[2] Gadotti、Andrea、他。「信号がノイズの中にあるとき:diffixのスティッキーノイズを利用します。」第28回USENIXセキュリティシンポジウム(USENIXセキュリティ19)。2019.
[3] Dinur、Irit、およびKobbiNissim。「プライバシーを守りながら情報を公開する」データベースシステムの原則に関する第22回ACMSIGMOD-SIGACT-SIGARTシンポジウムの議事録。2003.
[4]スウィーニー、ラターニャ。「単純な人口統計は、多くの場合、人々を一意に識別します。」健康(サンフランシスコ)671(2000):1-34。
[5] Dwork、Cynthia、他。「プライベートデータ分析における感度に対するノイズの較正」。暗号会議の理論。Springer、Berlin、Heidelberg、2006年。
[6] Wood、Alexandra、Micah Altman、Aaron Bembenek、Mark Bun、Marco Gaboardi、James Honaker、Kobbi Nissim、David R. O'Brien、Thomas Steinke、SalilVadhan。«差別化されたプライバシー:技術者以外の聴衆のための入門書。»ヴァンド。J.Ent。&Tech。L. 21(2018):209。
[7] Dwork、Cynthia、およびAaronRoth。「差別的プライバシーのアルゴリズム的基盤。」理論的コンピュータサイエンスの基礎と動向9、no。3-4(2014):211-407