
これは、プライバシーの違いに関するシリーズの2番目の記事の翻訳です。
先週、このシリーズの最初の記事「差分プライバシー-機密性を維持しながらデータを分析する(シリーズの概要)」で、差分プライバシーの基本的な概念と使用法について説明しました。今日は、予想される脅威モデルに応じて、システムを構築するための可能なオプションを検討します。
差別的プライバシーの原則を満たすシステムを展開することは、簡単な作業ではありません。例として、次の投稿では、機密データを処理する関数にラプラスノイズの追加を直接実装する単純なPythonプログラムを見ていきます。ただし、これを機能させるには、必要なすべてのデータを1つのサーバーに収集する必要があります。
サーバーがハッキングされた場合はどうなりますか?この場合、差別化されたプライバシーは、プログラムの作業の結果として取得されたデータのみを保護するため、役に立ちません。
差別的プライバシーの原則に基づいてシステムを展開する場合、脅威モデルを考慮することが重要です。:どの対戦相手からシステムを保護したいのか。このモデルに機密データでサーバーを完全に危険にさらす可能性のある攻撃者が含まれている場合、そのような攻撃に抵抗するようにシステムを変更する必要があります。
つまり、差分プライバシーを尊重するシステムのアーキテクチャでは、プライバシーとセキュリティの両方を考慮する必要があります。プライバシーは、システムから返されるデータから何を取得できるかを制御します。また、セキュリティは反対のタスクと見なすことができます。データの一部へのアクセスを制御することですが、コンテンツに関する保証はありません。
中央差分プライバシーモデル
差分プライバシー作業で最も一般的に使用される脅威モデルは、中央差分プライバシーモデル(または単に「中央差分プライバシー」)です。
主要コンポーネント-信頼できるデータストア(信頼できるデータキュレーター)。各ソースは彼に機密データを送信し、それらを1か所(サーバーなど)に収集します。リポジトリは、機密データを独自に処理し、誰にも転送せず、誰にも侵害されないと想定される場合、信頼されます。言い換えれば、機密データを含むサーバーが危険にさらされることはないと考えています。
中央モデルの一部として、通常、クエリへの応答にノイズを追加します(次の記事でLaplaceの実装について説明します)。このモデルの利点は、可能な限り低いノイズ値を追加できることです。これにより、プライバシーの違いの原則によって許容される最大の精度が維持されます。以下はプロセスの図です。信頼できるデータストアとアナリストの間にプライバシーバリアを設定し、指定された異なるプライバシー基準を満たす結果のみが外部に出られるようにしました。したがって、アナリストは信頼される必要はありません。
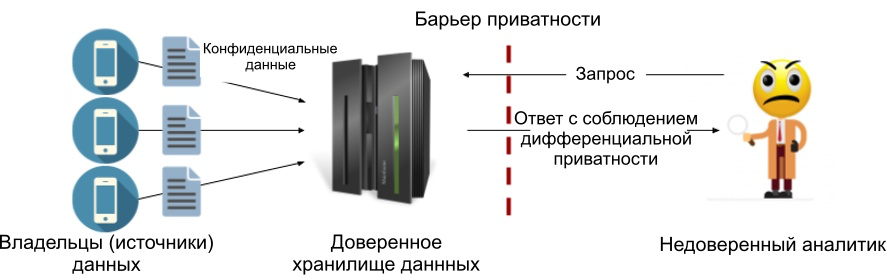
図1:中央の差分プライバシーモデル。
中央モデルの欠点は、信頼できるストアが必要であり、その多くは必要ないことです。実際、データの消費者に対する信頼の欠如は、通常、異なるプライバシー原則を使用する主な理由です。
ローカル差分プライバシーモデル
ローカル差分プライバシーモデルを使用すると、信頼できるデータストアを取り除くことができます。各データソース(またはデータ所有者)は、データをストアに転送する前に、データにノイズを追加します。これは、ストレージに機密情報が含まれることがないことを意味します。つまり、その弁護士の権限は必要ありません。次の図は、ローカルモデルのデバイスを示しています。このモデルでは、データの各所有者とストレージ(信頼されている場合とされていない場合があります)の間にプライバシーバリアがあります。
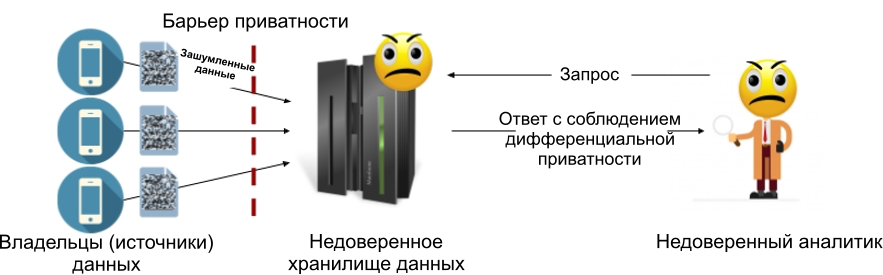
図2:ローカル差分プライバシーモデル。
差分プライバシーのローカルモデルは、中央モデルの主な問題を回避します。データウェアハウスが危険にさらされた場合、ハッカーは、差分プライバシーの要件をすでに満たしているノイズの多いデータにのみアクセスできます。これが、Google RAPPOR [1]やAppleのデータ収集システム[2]などのシステムにローカルモデルが選択された主な理由です。
しかし一方では?ローカルモデルは、中央モデルよりも精度が低くなります。ローカルモデルでは、各ソースが独立してノイズを追加し、独自の異なるプライバシー条件を満たすため、すべての参加者からの合計ノイズは、中央モデルのノイズよりもはるかに大きくなります。
最終的に、このアプローチは、非常に永続的な傾向(シグナル)を持つクエリに対してのみ正当化されます。たとえば、Appleはローカルモデルを使用して絵文字の人気を推定しますが、その結果は最も人気のある絵文字(傾向が最も顕著である)にのみ役立ちます。通常、このモデルは、米国国勢調査局[10]や機械学習で使用されるようなより複雑なクエリには使用されません。
ハイブリッドモデル
中央モデルとローカルモデルには長所と短所の両方があり、現在の主な取り組みはそれらを最大限に活用することです。
たとえば、Prochloシステムに実装されているシャッフリングモデルを使用できます[4]。これには、信頼できないデータストア、多くの個々のデータ所有者、およびいくつかの部分的に信頼できるシャッフラーが含まれています。..。各ソースは、最初にデータに少量のノイズを追加し、次にそれをアジテーターに送信します。アジテーターは、データウェアハウスに送信する前にさらにノイズを追加します。結論として、アジテーターがデータストアまたは相互に「衝突」する(または同時に危険にさらされる)可能性は低いため、ソースによって追加されたわずかなノイズでプライバシーを保証できます。各アジテーターは、中央モデルと同様に複数のソースを処理できるため、少量のノイズにより、結果のデータセットのプライバシーが保証されます。
アジテーターモデルは、ローカルモデルとセントラルモデルの間の妥協点です。ローカルモデルよりもノイズは少なくなりますが、セントラルモデルよりもノイズが多くなります。
安全なマルチパーティ計算(MPC)や完全同形暗号化(FHE)のように、差分プライバシーと暗号化を組み合わせることもできます。 FHEを使用すると、暗号化されたデータを最初に復号化せずに計算できます。MPCを使用すると、参加者のグループは、データを開示せずに分散ソースに対して安全にクエリを実行できます。差分プライベート関数の計算クリプトセーフ(または単にセキュア)コンピューティングを使用することは、ローカルのすべての利点を備えた中央モデルの精度を達成するための有望な方法です。さらに、この場合、安全なコンピューティングを使用すると、信頼できるストレージを用意する必要がなくなります。最近の研究[5]は、MPCと差別化されたプライバシーの組み合わせによる有望な結果を示しており、両方のアプローチの利点のほとんどを吸収しています。ただし、ほとんどの場合、安全な計算はローカルで実行される計算よりも数桁遅くなります。これは、大規模なデータセットや複雑なクエリでは特に重要です。セキュアコンピューティングは現在活発な開発段階にあるため、そのパフォーマンスは急速に向上しています。
そう?
次の記事では、差別化されたプライバシーの概念を実践するための最初のオープンソースツールを見ていきます。初心者が利用でき、米国国勢調査局のデータベースなどの非常に大規模なデータベースに適用できる他のツールを見てみましょう。プライバシーの違いの原則に従って、人口データの計算を試みます。
私たちのブログを購読して、次の記事の翻訳をお見逃しなく。すぐに。
ソース
[1] Erlingsson、Úlfar、Vasyl Pihur、およびAleksandraKorolova。 「ラッパー:ランダム化された集約可能なプライバシー保護の通常の応答。」コンピュータと通信のセキュリティに関する2014ACM SIGSAC会議の議事録、pp。 1054-1067。 2014.
[2] Apple Inc. 「AppleDifferentialPrivacyTechnicalOverview」。 2020年7月31日にアクセス。https://www.apple.com/privacy/docs/Differential_Privacy_Overview.pdf
[3] Garfinkel、Simson L.、John M. Abowd、およびSarahPowazek。 「差別化されたプライバシーの展開で発生した問題。」電子社会におけるプライバシーに関する2018年ワークショップの議事録、pp。 133-137。 2018年。
[4] Bittau、Andrea、ÚlfarErlingsson、Petros Maniatis、Ilya Mironov、Ananth Raghunathan、David Lie、Mitch Rudominer、Ushasree Kode、Julien Tinnes、BernhardSeefeld。「Prochlo:群衆の中の分析のための強力なプライバシー。」オペレーティングシステムの原則に関する第26回シンポジウムの議事録、pp。441-459。2017.
[5] Roy Chowdhury、Amrita、Chenghong Wang、Xi He、Ashwin Machanavajjhala、およびSomeshJha。「Cryptε:信頼できないサーバーでの暗号支援によるプライバシーの差異」データ管理に関する2020ACM SIGMOD国際会議の議事録、pp。603-619。2020年。