ラップトップで数ギガバイトのデータを処理することは、RAMが多くなく、処理能力が十分でない場合にのみ、困難な作業になる可能性があります。
それにもかかわらず、データ科学者はこの問題の代替解決策を見つける必要があります。巨大なデータセットを処理するようにパンダを設定するオプション、GPUを購入するオプション、またはクラウドコンピューティングパワーを購入するオプションがあります。この記事では、ローカルマシン上の大規模なデータセットにDaskを使用する方法を見ていきます。
DaskとPython
Daskは、Python用の柔軟な並列コンピューティングライブラリです。NumPy、Pandas、scikit-learnなどの他のオープンソースプロジェクトでうまく機能します。DASKを有するアレイ構造numpyの配列に相当する、DASKのデータフレームは、パンダのと同様であるデータフレーム、およびDASK-MLはscikit学習です。
これらの類似点により、Daskを作業に簡単に統合できます。Daskを使用する利点は、コンピューター上の複数のコアに計算をスケーリングできることです。そのため、メモリに収まらない大量のデータを処理する機会が得られます。また、通常は多くのスペースを占める計算を高速化することもできます。
ソース
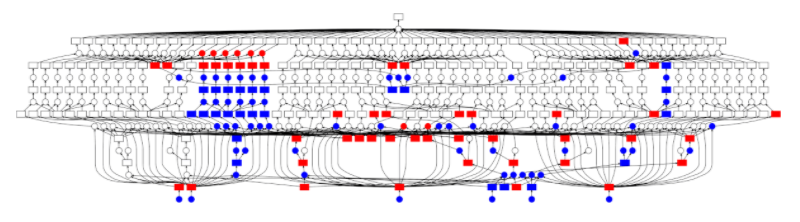
Dask DataFrame
大量のデータをロードする場合、Daskは通常、データタイプを認識するためにデータのサンプルを読み取ります。同じ列に異なるデータタイプが存在する可能性があるため、これはほとんどの場合エラーにつながります。エラーを回避するために、事前に型を宣言することをお勧めします。Daskは、パラメータで定義されたブロックにそれらをスライスすることにより、巨大なファイルをダウンロードできます
blocksize。
data_types ={'column1': str,'column2': float}
df = dd.read_csv(“data,csv”,dtype = data_types,blocksize=64000000 )
Dask DataFrameのソースコマンドは、Pandasコマンドに似ています。たとえば、取得
headとtail データフレームは似ています。
df.head()
df.tail()DataFrameの関数は怠惰です。つまり、関数が呼び出されるまで評価されません
compute。
df.isnull().sum().compute()データはチャンクでロードされるため、などの一部のPandas機能
sort_values()は失敗します。しかし、あなたは機能を使うことができますnlargest().
Daskのクラスター
並列コンピューティングは、複数のコアで同時に読み取ることができるため、Daskの鍵となります。 Daskは
machine scheduler、単一のマシンで実行することを提供します。スケーリングしません。distributed scheduler複数のマシンに拡張できるものもあります。
使用に
dask.distributedはクライアント構成が必要です。これは、dask.distributed 分析で使用する場合に最初に行うことです。低遅延、データの局所性、ワーカー間の通信を提供し、構成が簡単です。
from dask.distributed import Client
client = Client()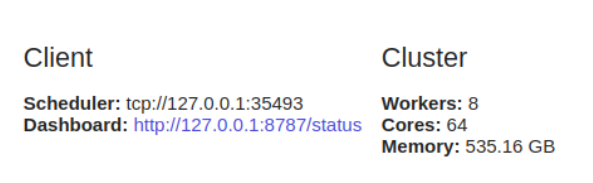
dask.distributedダッシュボードを介して診断機能を提供するため、単一のマシンでも
使用すると便利です。
を構成しない場合
Client、デフォルトでは、1台のマシンにマシンスケジューラを使用します。プロセスとスレッドを使用して、単一のコンピューターで同時実行性を提供します。
Dask ML
Daskは、並列モデルのトレーニングと予測も可能にします。目標
dask-mlは、スケーラブルな機械学習を提供することです。を宣言するとn_jobs = -1 scikit-learn、計算を並行して実行できます。Daskはこの機能を使用して、クラスター内で計算を実行できるようにします。これは、Pythonでの並列処理とパイプライン化を可能にするjoblibパッケージを使用して実行できます。Dask MLを使用すると、scikit-learnモデルやXGboostなどの他のライブラリを使用できます。
単純な実装は次のようになります。
まず、インポート
train_test_splitしてデータをトレーニングケースとテストケースに分割します。
from dask_ml.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)次に、使用するモデルをインポートしてインスタンス化します。
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(verbose=1)次に
joblib、並列コンピューティングを有効にするためにインポートする必要があります。
import joblib次に、並列バックエンドを使用してトレーニングと予測を開始します。
from sklearn.externals.joblib import parallel_backend
with parallel_backend(‘dask’):
model.fit(X_train,y_train)
predictions = model.predict(X_test)制限とメモリ使用量
Daskの個々のタスクを並行して実行することはできません。ワーカーは、Python計算の長所と短所を継承するPythonプロセスです。さらに、分散環境で作業する場合は、データのセキュリティとプライバシーを確保するように注意する必要があります。
Daskには、ワーカーノードとクラスター内のデータを監視する中央スケジューラがあります。また、クラスターからのデータの解放も管理します。タスクが完了すると、すぐにメモリから削除され、他のタスク用のスペースが確保されます。ただし、特定のクライアントで何かが必要な場合、または現在の計算で重要な場合は、メモリに保存されます。
Daskのもう1つの制限は、Pandasのすべての機能を実装しているわけではないことです。Pandasインターフェースは非常に大きいため、Daskはそれを完全にはカバーしていません。つまり、Daskでこれらの操作の一部を実行するのは難しい場合があります。さらに、パンダからの遅い操作もダスクで遅くなります。
DaskDataFrameが必要ない場合
次の状況では、Daskが適切なオプションではない可能性があります。
- Pandasに必要な機能があるが、Daskがそれらを実装していない場合。
- データがコンピュータのメモリに完全に収まるとき。
- データが表形式でない場合。その場合は、dask.bagまたはdisk.arrayを試してください。
最終的な考え
この記事では、Daskを使用して、ローカルコンピューター上の巨大なデータセットを分散して操作する方法について説明しました。Daskの構文はすでによく知られているので、Daskを使用できることがわかりました。また、Daskは数千のコアに拡張できます。
また、予測やトレーニングのための機械学習にも使用できることもわかりました。詳細を知りたい場合は、ドキュメントのこれらの資料を確認してください。
