Tensorflowは、研究環境では地位を失いつつありますが、実際の開発では依然として人気があります。TFの長所の1つは、リソースが限られた環境での展開用にモデルを最適化できることです。このための特別なフレームワークがありますTensorflow Liteは、モバイルデバイスとのためTensorflowのサービング工業用。Web(およびHabré)での使用に関する十分なチュートリアルがあります。この記事では、これらのフレームワークを使用せずにモデルを最適化した経験を収集しました。タスクを実行するメソッドとライブラリのいくつかを見て、ディスク領域とRAMを節約する方法、各アプローチの長所と短所、および遭遇したいくつかの予期しない影響について説明します。
私たちはどのような条件で働いていますか
古典的なNLPタスクの1つは、短いテキストの主題分類です。分類子は、SVCのような古典的な方法から、BERTやその派生物のようなトランスフォーマーアーキテクチャで終わるまで、さまざまなアーキテクチャで表されます。CNN-畳み込みモデルを見ていきます。
私たちにとって重要な制限は、GPUのないマシンでモデルを(製品の一部として)トレーニングして使用する必要があることです。これは主に学習と推論の速度に影響します。
もう1つの条件は、分類用のモデルがトレーニングされ、いくつかのピースのセットで使用されることです。モデルのセットは、単純なモデルであっても、多くのリソース、特にRAMを使用できます。モデルの提供には独自のソリューションを使用していますが、モデルのセットを操作する必要がある場合は、TensorflowServingを参照してください。
TFバージョン1.xでモデルを最適化する必要に直面しましたが、現在は正式に廃止されていると見なされています。TF 2.xの場合、説明されている手法の多くは無関係であるか、標準APIに統合されているため、最適化プロセスは非常に単純です。
まず、モデルの構造を見てみましょう。
TFモデルのしくみ
いわゆる浅いCNNを考えてみましょう-1つの畳み込み層といくつかのフィルターを備えたネットワーク。このモデルは、ベクトルワード表現のテキスト分類に十分に機能しました。

簡単にするために、次元v x kのベクトル表現の固定の事前トレーニング済みセットを使用します。ここで、vは辞書のサイズ、kは埋め込みの次元です。
:
- Embedding-, .
- w x k. , (1, 1, 2, 3) 4 , 1 , 2 3 , .
- Max-pooling .
- , dropout- softmax- .
Adam, .
: .
, , 128 c w = 2 k = 300 () [filter_height, filter_width, in_channels, output_channels] — , 2*300*1*128 = 76800 float32, , 76800*(32/8) = 307200 .
? ( 220 . ) 300 265 . , .
TF . ( ), , , — ( ), . (). :
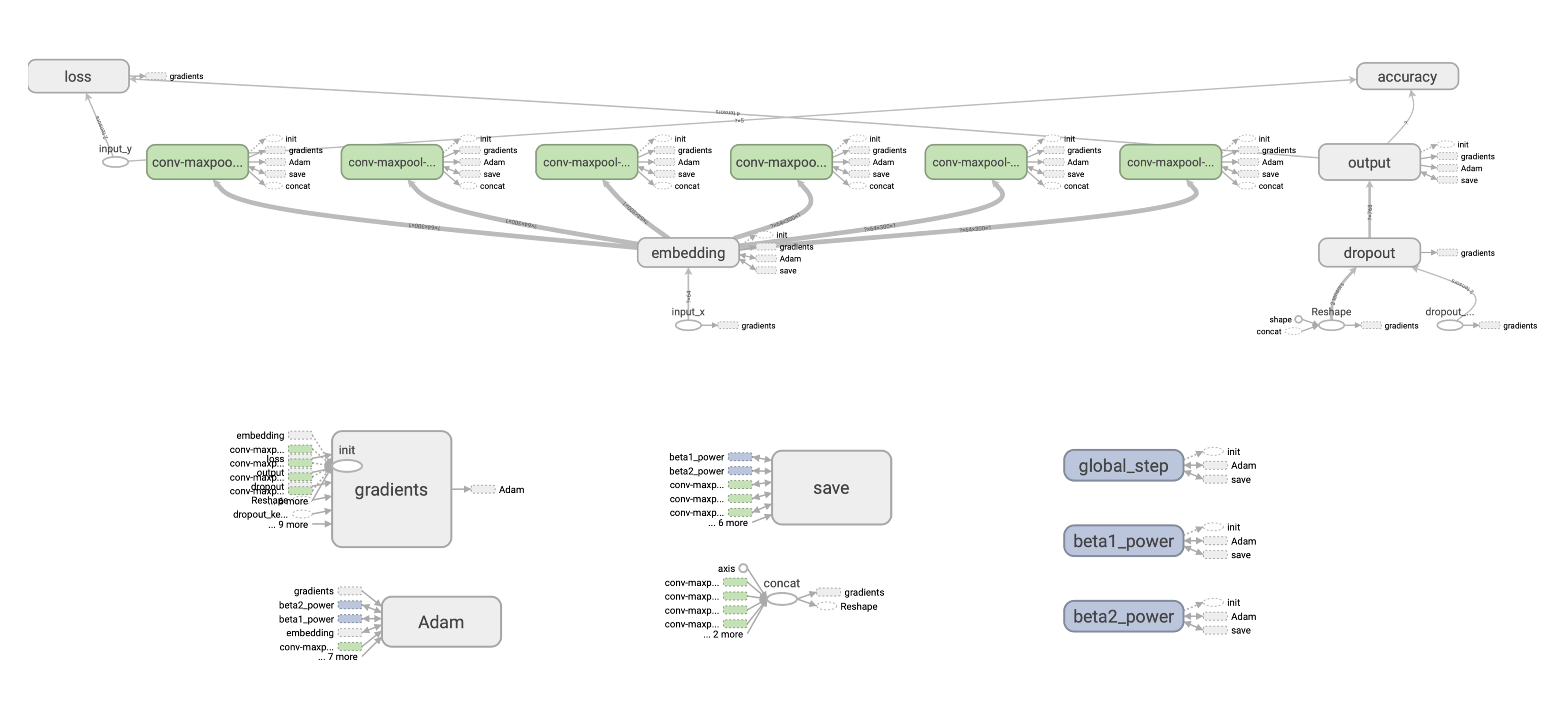
. , : SavedModel. , .
Checkpoint
, Saver API:
saver = tf.train.Saver(save_relative_paths=True)
ckpt_filepath = saver.save(sess, "cnn.ckpt"), global_step=0)global_step , , — cnn-ckpt-0.
<model_path>/cnn_ckpt :

checkpoint — . , TF . , .
.data , . , — 800 . , (≈265 ). ( ). , .
.index .
.meta — , (, , ), GraphDef, . , . — .meta , ? , TF - embedding-. , , , , , . , , :
with tf.Session() as sess:
saver = tf.train.import_meta_graph('models/ckpt_model/cnn_ckpt/cnn.ckpt-0.meta') # load meta
for n in tf.get_default_graph().as_graph_def().node:
print(n.name, n['attr'].shape)SavedModel
, . . API tf.saved_model. tf.saved_model, TF- (TFLite, TensorFlow.js, TensorFlow Serving, TensorFlow Hub).
:
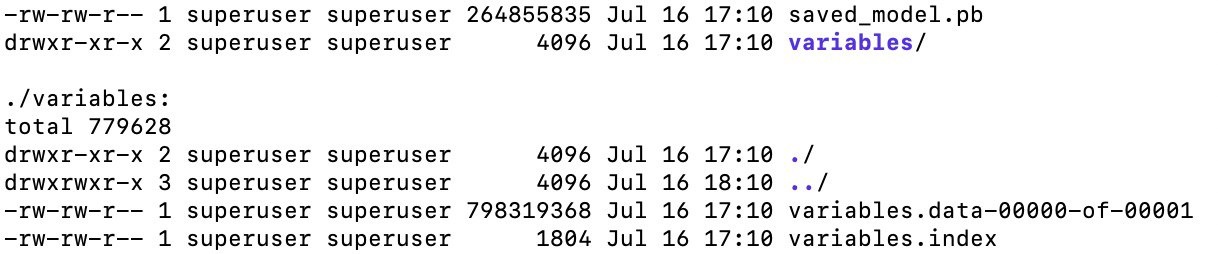
saved_model.pb, , , .meta , (, ), API, ( CLI, ).
SavedModel — , . “” . , , - — , .
, CNN-, TF 1.x, . .
, 1 , :
-
. , , ( tools.optimize_for_inference ). -
. , , — , tf.trainable_variables(). -
, . , (. BERT). -
. , . .
, , . , forward pass, . , . 1 265 .
TF 1.x , .
( ) GraphDef:
graph = tf.get_default_graph()
input_graph_def = graph.as_graph_def() . : tf.python.tools.freeze_graph tf.graph_util.convert_variables_to_constants. ( ) (, ['output/predictions']), , , . .
output_graph_def = graph_util.convert_variables_to_constants(self.sess, input_graph_def, output_node_names), .
freeze_graph() ( , , ). graph_util.convert_variables_to_constants() :
with tf.io.gfile.GFile('graph.pb', 'wb') as f:
f.write(output_graph_def.SerializeToString())266 , :
# GraphDef
with tf.io.gfile.GFile(graph_filepath, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
#
self.input_x = tf.placeholder(tf.int32, [None, self.properties.max_len], name="input_x")
self.dropout_keep_prob = tf.placeholder(tf.float32, name="dropout_keep_prob")
# graph_def
input_map = {'input_x': self.input_x, 'dropout_keep_prob': self.dropout_keep_prob}
tf.import_graph_def(graph_def, input_map), import:
predictions = graph.get_tensor_by_name('import/output/predictions:0'):
feed_dict = {self.input_x: encode_sentence(sentence), self.dropout_keep_prob: 1.}
sess.run(self.predictions, feed_dict), :
- . ,
sess.run(...). , CPU 20 ms, ~2700 ms. , . SavedModel . - RAM. RAM, . ~265 , . , TF GraphDef .
- – RAM TF . 1.15, TF 1.x, 118 MiB, 1.14 – 3 MiB.
, . ? / TF- tf.train.Saver. , , , :
- MetaGraph
tf.train.Saver . , :
saver = tf.train.Saver(var_list=tf.trainable_variables())MetaGraph . , meta . MetaGraph save:
ckpt_filepath = saver.save(self.sess, filepath, write_meta_graph=False)1014 M 265 M ( , ).
, TF 1.x:
- Grappler: c tensorflow
- Pruning API: google-research
- Graph Transform Tool:
, — tensorflow, Grappler. Grappler . , set_experimental_options. , zip . , zip , . Grappler .
google-research mask threshold, . . , , mask threshold, , , . .
Grappler, . : ? , ? , 0.99 . , mc, hex :

, , . . -, . -, , , , . , .
CNN. .
, . Graph transform tool.
quantize_weights 8 . , 8- . , , - .
quantize_nodes 8- . .
, - . quantize_weights - , 4 .
, , TensorFlow Lite, .
— , . 64 (32) , .
RAM Ubuntu ( numpy int64) . 220 , int32, int16. .

tf-. float16. , , ( 10%), ( 10 ). , , epsilon learning_rate . , , .
RAM
, . , .
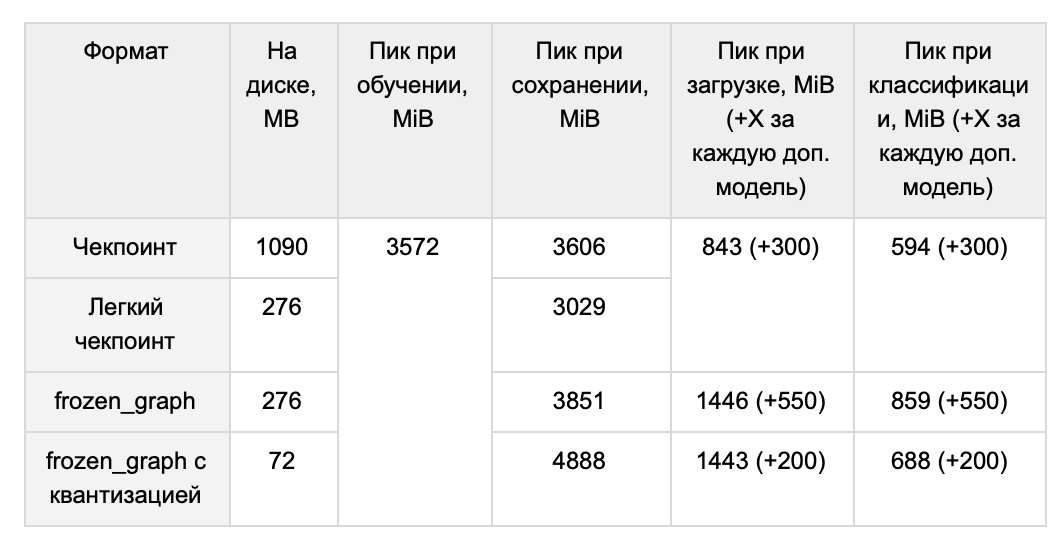
, . . .
QA-
Q: -, - ?
A: , . word2vec. ( , , min count, learning rate), 220 ( — 265 MB) CNN, 439 (510 MB).
- , , , - . , ( ). , . YouTokenToMe, , , .. , .., . . , , , . 30 (37 MB) , 3.7 CPU 2.6 GPU. ( ), OOV-.
Q: , , ?
A: , .
:
1. :
with tf.gfile.GFile(path_to_pb, 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
with tf.Graph().as_default() as graph:
tf.import_graph_def(graph_def, name='')
return graph2. "" :
sess.run(restored_variable_names) 3. , .
4. , , :
tf.Variable(tensors_to_restore["output/W:0"], name="W"), .
, , .
説明した残りの方法で圧縮されたモデルを再トレーニングしようとはしませんでしたが、理論的にはこれに問題はないはずです。
Q:考慮していない最適化を減らす他の方法はありますか?
A:実現できなかったアイデアがいくつかあります。まず、一定の折りたたみは、グラフノードのサブセットの「折りたたみ」であり、入力データに弱く依存しているグラフの部分の値の事前計算です。第二に、私たちのモデルでは、埋め込みのプルーニングを適用することは良い解決策のようです。