特に目標が自動化されたインフラストラクチャをサービスとして活用することである場合、Kubernetesの内部エンドポイントとAPIの監視は問題になる可能性があります。私たちSmarketsはまだこの目標を達成していませんが、幸いなことに、私たちはすでに目標にかなり近づいています。この分野での私たちの経験が、他の人が同様のことを実装するのに役立つことを願っています。
開発者が箱から出してあらゆるアプリケーションやサービスを監視できるようになることを常に夢見てきました。 Kubernetesに移行する前に、このタスクはPrometheusメトリックを使用するか、statsdを使用して実行されました。statsdは、基盤となるホストに統計を送信し、そこでPrometheusメトリックに変換されました。 Kubernetesを引き続き活用するにつれて、クラスターの分離を開始し、開発者がサービスアノテーションを介してメトリックをPrometheusに直接エクスポートできるようにしたいと考えました。残念ながら、これらのメトリックはクラスター内でのみ利用可能でした。つまり、グローバルに収集することはできませんでした。
これらの制限は、Kubernetes以前の構成のボトルネックでした。最終的に、彼らはサービスを監視するアーキテクチャと方法を再考することを余儀なくされました。この旅については、以下で説明します。
出発点
Kubernetes関連のメトリックについては、メトリックを提供する2つのサービスを使用します。
-
kube-state-metricsK8sAPIサーバーからの情報に基づいてKubernetesオブジェクトのメトリックを生成します。 -
kube-eagleポッドのPrometheusメトリック(要求、制限、使用法)をエクスポートします。
クラスターの外部にメトリックを持つサービスを公開したり、APIへのプロキシ接続を開いたりすることは可能です(そしてしばらくの間これを行ってきました)が、作業が遅くなり、システムの必要な独立性とセキュリティが提供されなかったため、どちらのオプションも理想的ではありませんでした。
通常、監視ソリューションが展開されました。これは、Kubernetes内で実行され、プラットフォーム自体からメトリックを収集するPrometheusサーバーの中央クラスターと、このクラスターからの内部Kubernetesメトリックで構成されています。このアプローチが選択された主な理由は、Kubernetesへの移行中に、すべてのサービスを同じクラスターに収集したためです。Kubernetesクラスターを追加した後、アーキテクチャは次のようになりました。
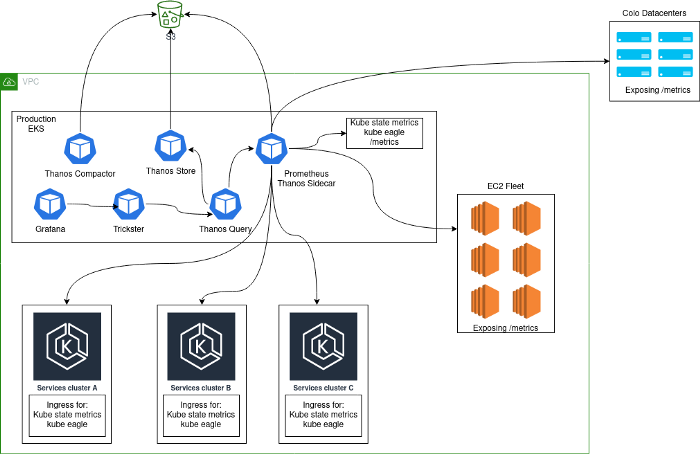
問題
このようなアーキテクチャは、安定、効率、または生産的とは言えません。結局のところ、ユーザーはstatsdメトリックをアプリケーションからエクスポートでき、その結果、一部のメトリックのカーディナリティが非常に高くなりました。次の順序でおなじみの場合は、このような問題に精通している可能性があります。
2時間のPrometheusブロックを分析する場合:
- 130万のメトリック。
- ラベルの383名。
- メトリックあたりの最大カーディナリティは662,000です(問題のほとんどはまさにこれが原因です)。
この高いカーディナリティは、主にHTTPパスを含むstatsdタイマーの公開によるものです。これは理想的ではないことはわかっていますが、これらのメトリックは、カナリア展開の重大なバグを追跡するために使用されます。
静かな時間帯には、1秒あたり約40,000のメトリックが収集されましたが、問題がなければ、その数は180,000に増える可能性があります。
カーディナリティの高いメトリックに対する特定のクエリにより、Prometheusは(予想どおりに)メモリを使い果たしました。これは、カナリア展開のパフォーマンスを警告および評価するためにPrometheusを使用すると、非常に苛立たしい状況になります。
もう1つの問題は、各Prometheusインスタンスに3か月のデータが保存されているため、起動時間(WALリプレイ)が非常に長く、通常、同じリクエストが2番目のPrometheusインスタンスにルーティングされて「すでに落としました。
これらの問題を修正するために、ThanosとTricksterを実装しました。
- Thanosは、Prometheusに保存できるデータを減らし、過度のメモリ使用によって引き起こされるインシデントの数を減らしました。コンテナの隣で、Prometheus ThanosはS3にデータのブロックを格納するサイドカーコンテナを起動し、thanos-compactがそれらを圧縮します。したがって、Thanosの助けを借りて、Prometheusの外部での長期データストレージが実装されました。
- Tricksterは、その一部として、時系列データベースの逆プロキシおよびキャッシュとして機能します。これにより、すべてのリクエストの最大99.53%をキャッシュできました。ほとんどのリクエストは、ワークステーション/ TVで実行されているダッシュボード、開いているコントロールパネルを持つユーザー、およびアラートから送信されます。時系列でデルタのみを出力できるプロキシは、この種のワークロードに最適です。
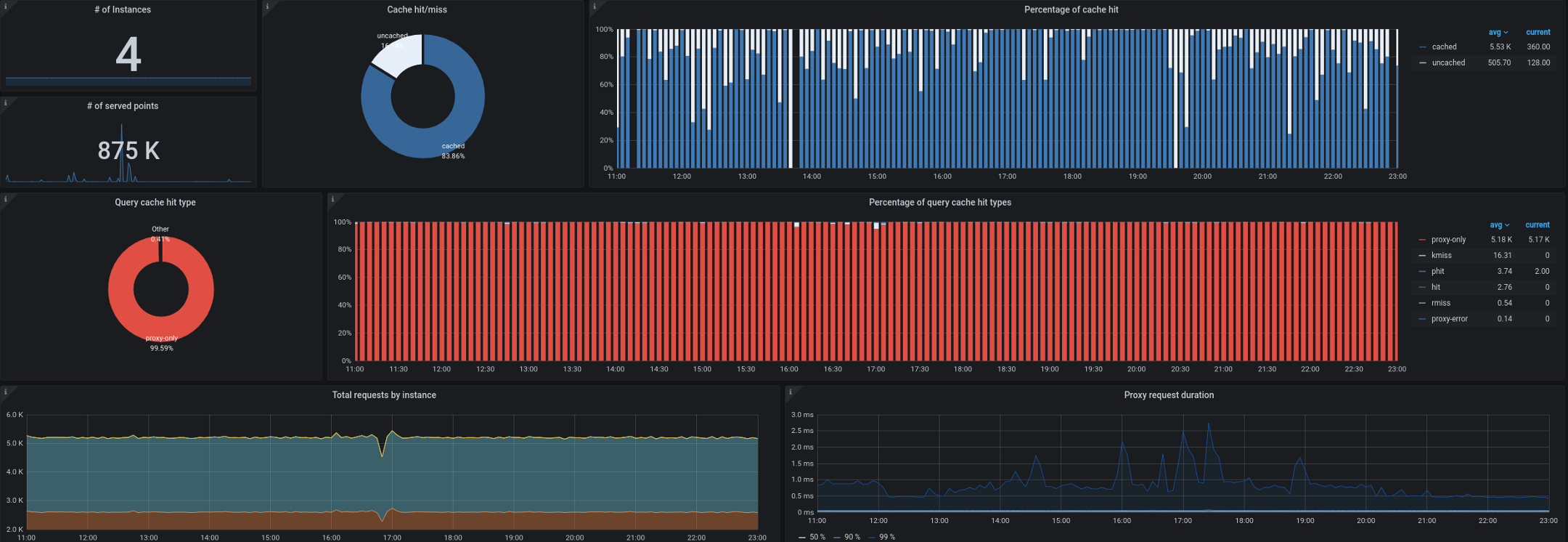
また、クラスターの外部からkube-state-metricsを収集する際に問題が発生し始めました。ご存知のように、1秒あたり最大180,000のメトリックを処理する必要があり、単一の入力kube-state-metricsに40,000のメトリックが設定されている場合でも、収集が遅くなりました。メトリックを収集するための目標10秒間隔があり、高負荷の期間中に、このSLAは、kube-state-metricsまたはkube-eagleのリモート収集によって違反されることがよくありました。
オプション
アーキテクチャを改善する方法を考えている間、3つの異なるオプションを検討しました。
- Prometheus + Cortex(https://github.com/cortexproject/cortex);
- Prometheus + Thanos受信(https://thanos.io);
- Prometheus + VictoriaMetrics(https://github.com/VictoriaMetrics/VictoriaMetrics)。
それらの詳細と特性の比較はインターネットで見つけることができます。私たちの特定のケースでは(そしてカーディナリティの高いデータでテストした後)、VictoriaMetricsが明らかに勝者でした。
決定
プロメテウス
上記のアーキテクチャを改善するために、各Kubernetesクラスターを個別のエンティティとして分離し、Prometheusをその一部にすることにしました。現在、新しいクラスターには、「すぐに使用できる」監視と、グローバルダッシュボード(Grafana)で利用可能なメトリックが付属しています。このために、kube-eagle、kube-state-metrics、およびPrometheusサービスがKubernetesクラスターに統合されました。次に、Prometheusは、クラスターを識別するための外部ラベルで構成
remote_writeされinsert、VictoriaMetricsでポイントされました(以下を参照)。
VictoriaMetrics
VictoriaMetrics Time Series Databaseは、Graphite、Prometheus、OpenTSDB、およびInfluxプロトコルを実装しています。PromQLをサポートするだけでなく、新しい機能とテンプレートを追加して、Grafanaクエリのリファクタリングを回避します。さらに、そのパフォーマンスは素晴らしいです。
VictoriaMetricsをクラスターモードで展開し、3つの別々のコンポーネントに分割しました。
1. VictoriaMetricsストレージ(vmstorage)
このコンポーネントは、インポートされ
vminsertたデータの保存を担当します。このコンポーネントの3つのレプリカに限定し、StatefulSetKubernetesに結合しました。
./vmstorage-prod \
-retentionPeriod 3 \
-storageDataPath /data \
-http.shutdownDelay 30s \
-dedup.minScrapeInterval 10s \
-http.maxGracefulShutdownDuration 30s
VictoriaMetrics挿入(vminsert)
このコンポーネントは、Prometheusを使用した展開からデータを受信し、に転送し
vmstorageます。このパラメーターreplicationFactor=2は、3つのサーバーのうちの2つにデータを複製します。したがって、インスタンスの1つでvmstorage問題が発生したり再起動したりした場合でも、使用可能なデータのコピーが1つあります。
./vminsert-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-replicationFactor=2
VictoriaMetrics select(vmselect)
Grafana(Trickster)からのPromQLリクエストを受け入れ、から生データをリクエストします
vmstorage。現在、search.disableCacheアーキテクチャにはキャッシュを担当するTricksterが含まれているため、キャッシュ()を無効にしています。したがって、vmselect常に最新の完全なデータをフェッチする必要があります。
/vmselect-prod \
-storageNode=vmstorage-0:8400 \
-storageNode=vmstorage-1:8400 \
-storageNode=vmstorage-2:8400 \
-dedup.minScrapeInterval=10s \
-search.disableCache \
-search.maxQueryDuration 30s
大きな絵
現在の実装は次のようになります。
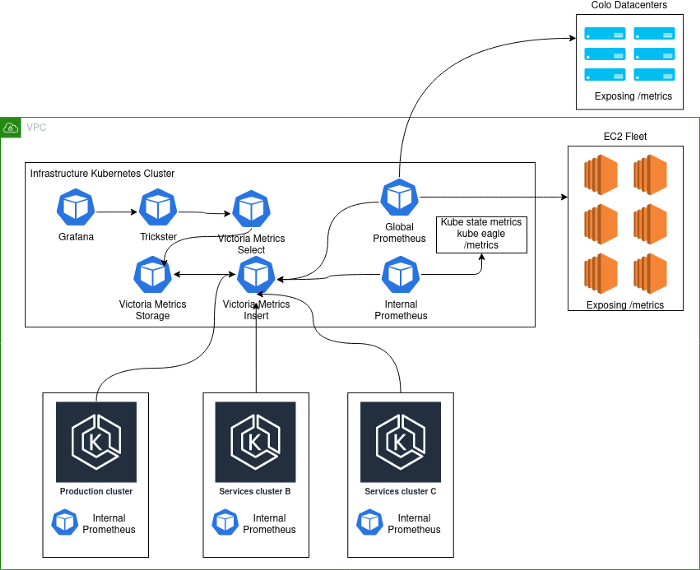
スキーマノート:
- Production- . , K8s . - , . .
- deployment K8s Prometheus', VictoriaMetrics insert Kubernetes.
- Kubernetes deployment' Prometheus, . , , Kubernetes , . Global Prometheus EC2, colocation- -Kubernetes-.
以下は、VictoriaMetricsによって現在処理されているメトリックです(合計2週間、グラフは2日間のギャップを示しています)。 新しいアーキテクチャは、本番環境に移行した後、良好に機能しました。古い構成では、数週間ごとに2、3回のカーディナリティの「爆発」があり、新しい構成では、その数はゼロになりました。 これは優れた指標ですが、今後数か月で改善する予定の点がいくつかあります。
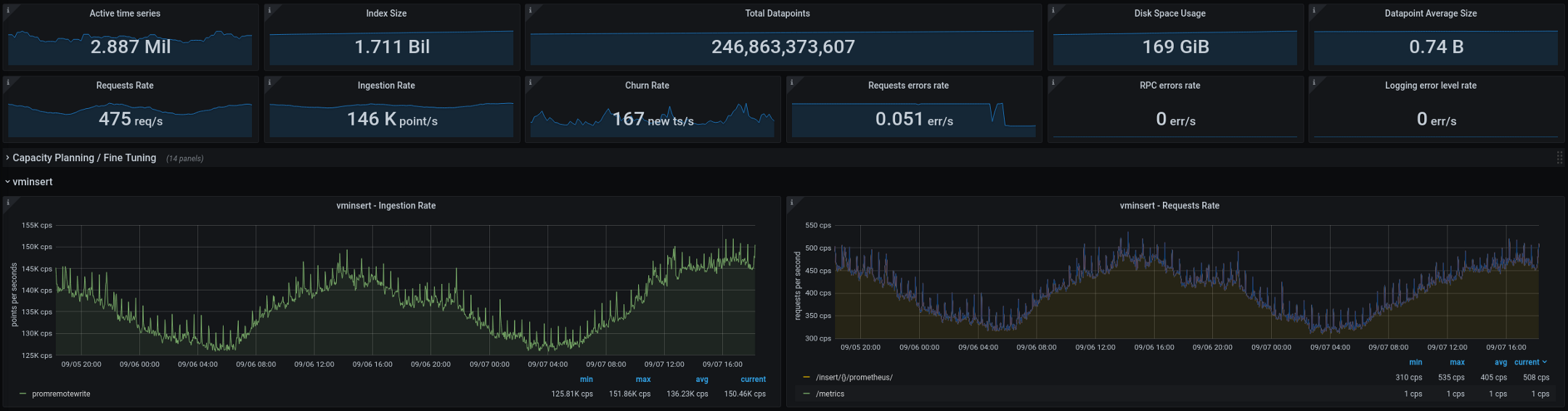
- statsd統合を改善することにより、メトリックのカーディナリティを減らします。
- TricksterとVictoriaMetricsのキャッシングを比較します。各ソリューションが効率とパフォーマンスに与える影響を評価する必要があります。トリックスターは何も失うことなく完全に放棄できるのではないかという疑いがあります。
- Prometheus stateless- — stateful, . , StatefulSet', ( pod disruption budgets).
-
vmagent— VictoriaMetrics Prometheus- exporter'. , Prometheus , .vmagentPrometheus ( !).
上記の改善に関する提案やアイデアがある場合は、お問い合わせください。Kubernetesの監視の改善に取り組んでいる場合は、私たちの困難な旅について説明したこの記事がお役に立てば幸いです。
翻訳者からのPS
私たちのブログも読んでください:
- "プロメテウスの未来とプロジェクトエコシステム(2020) ";
- 「監視とKubernetes」(レビューとビデオレポート);
- 「KubernetesのPrometheusオペレーターのデバイスとメカニズム。」