
データはどのように見えますか?
まず、利用可能なテストおよびトレーニングデータ(kaggle.comプラットフォームでの有毒なコメント分類チャレンジからのデータ)を見てみましょう。トレーニングデータには、テストデータとは対照的に、分類用のラベルがあります。
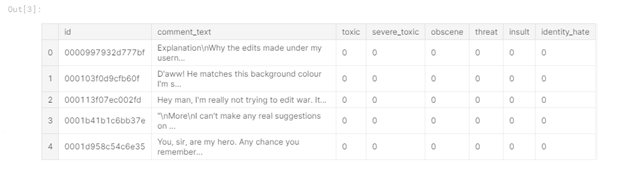
図1-
トレーニングデータヘッド表から、トレーニングデータに6つのラベル列( "toxic"、 "severe_toxic"、 "obscene"、 "threat")があることがわかります。 、 "Insult"、 "identity_hate")、値 "1"はコメントがクラスに属していることを示し、コメントを含む列 "comment_text"と列 "id"(コメント識別子)もあります。
テストデータには、ソリューションの送信に使用されるため、クラスラベルは含まれていません。

図2-テストデータヘッド
特徴抽出
次のステップは、コメントから特徴を抽出し、探索的データ分析(EDA)を実行することです。まず、トレーニングデータセット内のコメントタイプの分布を見てみましょう。このために、コメントが属するすべてのクラスを含む新しい列「toxic_type」が作成されました。

図3-有毒なコメントの上位10種類
表から、一般的なタイプはクラスラベルがなく、多くのコメントが複数に属していることがわかります。クラス。
各コメントのタイプの数がどのように分散されているかも見てみましょう。

図4-検出されたタイプの数
一般的な状況は、コメントが1つのタイプの毒性のみによって特徴付けられる場合であることに注意してください。また、コメントが3つのタイプの毒性によって特徴付けられることも多く、コメントがすべてのタイプに起因することはあまりありません。
次に、テキストから特徴を抽出する段階に移りましょう。これは、しばしば特徴抽出と呼ばれます。次の属性を抽出しました
。コメントの長さ。怒っているコメントは短いと思います。
大文字。攻撃的で感情的なコメントでは、大文字が言葉でより一般的になる可能性があります。
エモティコン。有毒なコメントを書くとき、ポジティブカラーのエモティコン(:)などが使用される可能性は低いですが、悲しいエモチコン(:(など)の存在も考慮します。
パンクチュエーション。おそらく、否定的なコメントの作成者は、句読点の規則に準拠しておらず、「!」をより多く使用しています。
サードパーティの文字の数。不快な言葉を書くときに、@、$などの記号をよく使用する人もいます。
機能は次のように追加されます。
train_data[‘total_length’] = train_data[‘comment_text’].apply(len)
train_data[‘uppercase’] = train_data[‘comment_text’].apply(lambda comment: sum(1 for c in comment if c.isupper()))
train_data[‘exclamation_punction’] = train_data[‘comment_text’].apply(lambda comment: comment.count(‘!’))
train_data[‘num_punctuation’] = train_data[‘comment_text’].apply(lambda comment: comment.count(w) for w in ‘.,;:?’))
train_data[‘num_symbols’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in ‘*&$%’))
train_data[‘num_words’] = train_data[‘comment_text’].apply(lambda comment: len(comment.split()))
train_data[‘num_happy_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-)’, ‘:)’, ‘;)’, ‘;-)’)))
train_data[‘num_sad_smilies’] = train_data[‘comment_text’].apply(lambda comment: sum(comment.count(w) for w in (‘:-(’, ‘:(’, ‘;(’, ‘;-(’)))探索的データ分析
次に、取得した機能を使用してデータを調べてみましょう。まず、機能間の相関関係、機能とクラスラベル間の相関関係、クラスラベル間の相関関係を見てみましょう。

図5-相関
関係相関関係は、機能間に線形関係が存在することを示します。弾性率の相関値が1に近いほど、要素間の線形依存性が顕著になります。
たとえば、単語の数とテキストの長さは互いに強く相関していることがわかります(値0.99)。つまり、いくつかの機能を削除できるので、単語の数を削除しました。さらにいくつかの結論を導き出すこともできます。選択した機能とクラスラベルの間に実質的な相関関係はなく、最も相関の少ない機能は文字数であり、テキストの長さは句読点の文字数と大文字に変換された文字数と相関関係があります。
次に、クラスラベルに対する機能の影響をより詳細に理解するために、いくつかの視覚化を構築します。まず、コメントの長さがどのように分布しているかを見てみましょう。

図6-コメントの長さの分布(グラフはインタラクティブですが、ここにスクリーンショットがあります)
予想どおり、分類されていない(つまり通常の)コメントは、タグ付けされたコメントよりも長さがはるかに長くなります。否定的なコメントのうち、最も短いものは脅威であり、最も長いものは有毒です。
それでは、句読点の観点からコメントを調べてみましょう。グラフをより解釈しやすくするために、平均値のグラフィック表現を作成します:

図7-平均句読点値(グラフはインタラクティブですが、ここにスクリーンショットがあります)
図から、3つのクラスターが得られたことがわかります。
1つ目は通常のコメントで、句読点の規則(たとえば、句読点の配置、「:」)と少数の感嘆符の順守が特徴です。
2つ目は、脅威(脅威)と非常に有毒なコメント(重度の有毒)で構成されます。このグループは、感嘆符が豊富に使用されていることを特徴とし、他の句読点は中間レベルで使用されます。
3番目のクラスター-有毒(有毒)、猥褻(猥褻)、侮辱(侮辱)、特定の人に対する憎悪(アイデンティティの憎悪)には、句読点と感嘆符の両方が少数あります。
わかりやすくするために3番目の軸を追加しましょう-大文字:

図8-3D画像(インタラクティブですが、これがスクリーンショットです)
ここでも同様の状況が見られます-3つのクラスターが強調表示されています。また、2番目のクラスターの要素間の距離は、3番目のクラスターの要素間の距離よりも大きいことに注意してください。これは、2Dグラフでも確認できます。

図9-大文字と句読点(インタラクティブ、
これがスクリーンショットです)次に、大文字とサードパーティの文字の数のコンテキストでコメントのタイプを見てみましょう:

図10-大文字とサードパーティの文字の数(インタラクティブ、ここにスクリーンショットがあり
ます)ご覧のとおり、非常に有毒なコメントが明確に強調表示されています-大文字とサードパーティの文字が多数あります。また、サードパーティのシンボルは、誰かを憎むコメントの作成者によって積極的に使用されています。
したがって、新しい機能を強調表示して視覚化することで、利用可能なデータをより適切に解釈できます。上記の視覚化は、次のように要約できます。
毒性の高いコメントは他のコメントから分離されます。
通常のコメントも目立ちます。
有毒で卑猥で不快なコメントは、考慮される特性の点で互いに非常に近いものです。
DataFrameMapperを
使用したテキスト機能と数値機能の組み合わせ次に、ロジスティック回帰でテキスト機能と数値機能を一緒に使用する方法を見てみましょう。
まず、機械学習アルゴリズムに適した形式でテキストを表すモデルを選択する必要があります。特定の単語を強調表示し、頻繁な単語の重要性を低くすることができるため、tf-idfモデルを使用しました(たとえば、前置詞)。
tvec = TfidfVectorizer(
sublinear_tf=True,
strip_accents=’unicode’,
analyzer=’word’,
token_pattern=r’\w{1,}’,
stop_words=’english’,
ngram_range=(1, 1),
max_features=10000
)したがって、Pandasライブラリによって提供されるデータフレームとSklearnライブラリのマシン学習アルゴリズムを使用する場合は、データフレームデータとSklearnメソッドの間の一種のバインダーとして機能するSklearn-pandasモジュールを使用できます。
mapper = DataFrameMapper([
([‘uppercase’], StandardScaler()),
([‘exclamation_punctuation’], StandardScaler()),
([‘num_punctuation’], StandardScaler()),
([‘num_symbols’], StandardScaler()),
([‘num_happy_smilies’], StandardScaler()),
([‘num_sad_smilies’], StandardScaler()),
([‘total_length’], StandardScaler())
], df_out=True)まず、上記のようにDataFrameMapperを作成する必要があります。これには、数値機能を持つ列の名前が含まれている必要があります。次に、機能のマトリックスを作成し、それをトレーニングのためにロジスティック回帰に転送します。
x_train = np.round(mapper.fit_transform(numeric_features_train.copy()), 2).values
x_train_features = sparse.hstack((csr_matrix(x_train), train_texts))同様の一連のアクションがテストデータセットでも実行されます。
計算実験
マルチラベル分類を実行するために、すべてのカテゴリを通過するループを構築し、パラメータcv = 3およびスコアリング= 'roc_auc'を使用した相互検証によって分類の品質を評価します。
scores = []
class_names = [‘toxic’, ‘severe_toxic’, ‘obscene’, ‘threat’, ‘identity_hate’]
for class_name in class_names:
train_target = train_data[class_name]
classifier = LogisticRegression(C=0.1, solver= ‘sag’)
cv_score = np.mean(cross_val_score(classifier, x_train_features, train_target, cv=3, scoring= ‘auc_roc’))
scores.append(cv_score)
print(‘CV score for class {} is {}’.format(class_name, cv_score))
classifier.fit(train_features, train_target)
print(‘Total CV score is {}’.format(np.mean(scores)))</source
<b> :</b>
<img src="https://habrastorage.org/webt/kt/a4/v6/kta4v6sqnr-tar_auhd6bxzo4dw.png" />
<i> 11 — </i>
, , , , , . , , , . - , “toxic”, , , ( 3). , , , .