
今日、人工神経ネットワークは多くの「人工知能」技術の中核となっています。同時に、新しいニューラルネットワークモデルをトレーニングするプロセスは非常に順調に進んでいるため(膨大な数の分散フレームワーク、データセット、その他の「空白」のおかげで)、世界中の研究者は、新しい「効果的な」「安全な」アルゴリズムを簡単に構築できます。それが結果です。場合によっては、これは、トレーニングされたアルゴリズムを使用するプロセスの次のステップで不可逆的な結果につながる可能性があります。今日の記事では、人工知能に対する多くの攻撃、それらがどのように機能し、どのような結果につながる可能性があるかを分析します。
ご存知のように、で我々のスマートエンジンは、データ準備(参照から、不安を持つニューラルネットワークモデル学習プロセスの各ステップを扱うここ、こことここでは、ネットワーク・アーキテクチャの開発に)(参照ここでは、こことここ)。人工知能と認識システムを使用したソリューションの市場では、私たちは責任ある技術開発のためのアイデアのガイドとプロモーターです。一ヶ月前、私たちも国連グローバルコンパクトに参加しました。
では、なぜ「不注意に」ニューラルネットワークを学ぶのがとても怖いのでしょうか。悪いメッシュ(単にうまく認識されない)は本当に深刻な害を及ぼす可能性がありますか?重要なのは、得られたアルゴリズムの認識の質ではなく、結果として得られるシステム全体の質にあることがわかります。
単純でわかりやすい例として、オペレーティングシステムがどれほど悪いか想像してみましょう。確かに、昔ながらのユーザーインターフェイスではなく、適切なレベルのセキュリティを提供しないという事実によって、ハッカーからの外部攻撃をまったく阻止しません。
同様の考慮事項は、人工知能システムにも当てはまります。今日は、ターゲットシステムの深刻な誤動作につながるニューラルネットワークへの攻撃について話しましょう。
データ中毒
最初の最も危険な攻撃はデータポイズニングです。この攻撃では、エラーはトレーニング段階で埋め込まれ、攻撃者はネットワークをだます方法を事前に知っています。人との類似性を描く場合、外国語を学んでいて、いくつかの単語を間違って学んでいると想像してください。たとえば、馬は家の同義語であると思います。そうすれば、ほとんどの場合、落ち着いて話すことができますが、まれに、重大な間違いを犯すことになります。同様のトリックは、ニューラルネットワークでも実行できます。たとえば、[1]では、ネットワークがだまされて道路標識を認識します。ネットワークを教えるとき、彼らは停止標識を示し、これは本当に停止、正しいラベルの付いた速度制限標識、およびステッカーが貼り付けられた停止標識と速度制限ラベルであると言います。完成したネットワークは、テストサンプルの兆候を高精度で認識しますが、実際には爆弾が仕掛けられています。このようなネットワークが実際の自動操縦システムで使用されている場合、ステッカー付きの停止標識が表示されると、速度制限が適用され、運転が続行されます。
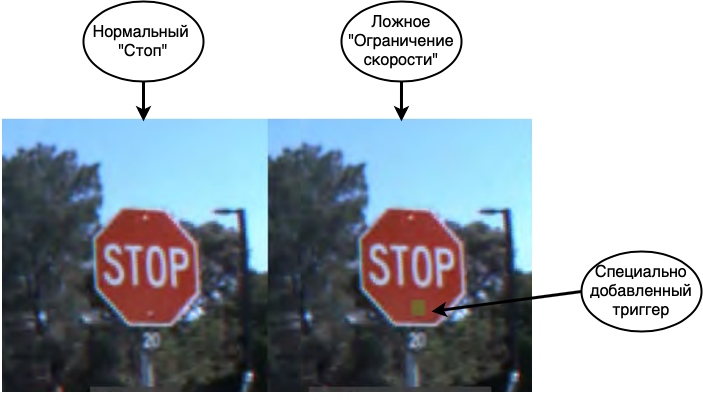
ご覧のとおり、データポイズニングは非常に危険なタイプの攻撃であり、その使用は、とりわけ、データへの直接アクセスが必要であるという1つの重要な機能によって深刻に制限されています。従業員による企業のスパイやデータの破損のケースを除外すると、これが発生する可能性がある場合、次のシナリオが残ります。
- クラウドソーシングプラットフォームでのデータの破損。 , ( ?...), , - , . , , . , «» . , . (, ). , , , , «» . .
- . , – . « » - . , . , , [1].
- クラウドでトレーニングするときのデータの破損。人気のある重いニューラルネットワークアーキテクチャは、通常のコンピュータでトレーニングすることはほとんど不可能です。結果を追求するために、多くの開発者がクラウドでモデルを教え始めています。このようなトレーニングにより、攻撃者は開発者の通知なしにトレーニングデータにアクセスし、それを台無しにする可能性があります。
回避攻撃
次に検討するタイプの攻撃は回避攻撃です。このような攻撃は、ニューラルネットワークを使用する段階で発生します。同時に、目標は同じままです。特定の状況でネットワークに誤った回答を強制することです。
当初、回避エラーはタイプIIエラーを意味していましたが、現在はこれが動作中のネットワークの欺瞞の名前です[8]。実際、攻撃者はネットワーク上に光学的(聴覚的、意味的)な錯覚を作り出そうとしています。ネットワークによる画像(音、意味)の認識は、人による認識とは大きく異なることを理解する必要があります。したがって、2つの非常に類似した画像(人にとって区別がつかない)の認識が異なる場合の例をよく見ることができます。そのような最初の例は[4]に示され、[5]にはパンダの人気のある例が現れました(この記事のタイトル図を参照)。
通常、回避攻撃には敵対的な例が使用されます。これらの例には、多くのシステムを危険にさらすいくつかの特性があります。
- , , [4]. « », [7]. « » , . , , . , [14], « » .

- 敵対的な例は、現実の世界に完全に引き継がれます。まず、人に知られているオブジェクトの特徴に基づいて、誤って認識される例を慎重に選択できます。たとえば、[6]では、著者は洗濯機をさまざまな角度から撮影し、「安全」または「オーディオスピーカー」という回答を受け取ることがあります。第二に、敵対的な例を図から現実の世界にドラッグすることができます。[6]で、彼らは、デジタル画像を変更することによって神経ネットワークの欺瞞を達成し(上記のパンダに似たトリック)、簡単な印刷によって結果のデジタル画像を素材の形に「変換」し、すでに現実世界にあるネットワークを欺き続けることができる方法を示しました。
回避攻撃は、目的の応答、モデルの可用性、および干渉選択の方法に応じて、さまざまなグループに分けることができます。
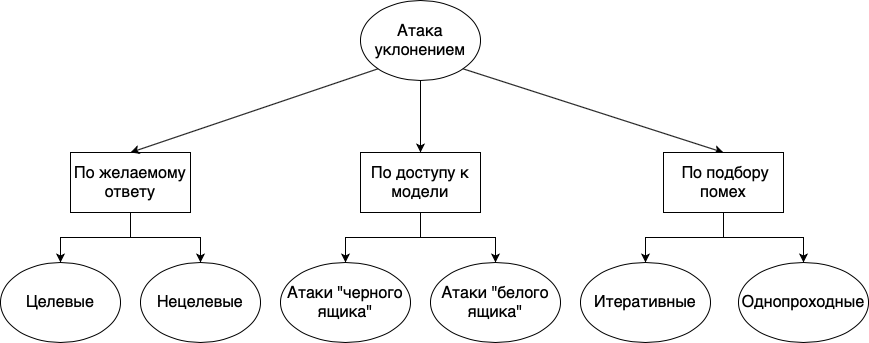
- . , , . , . , «», «», «», , , , . . , , , , .
- . , , , , . , , - , . , , . « », , , . . « » , , . , , . , , . , , , , .
- . , . , , , . : . , . . , , . « ».
もちろん、回避攻撃の対象となる動物や物体を分類するのはネットワークだけではありません。次の図は、コンピュータビジョンとパターン認識に関するIEEE / CVF会議で発表された2020年の論文[12]から抜粋したもので、OCRの反復ネットワークをいかにうまくスプーフィングできるかを示しています。
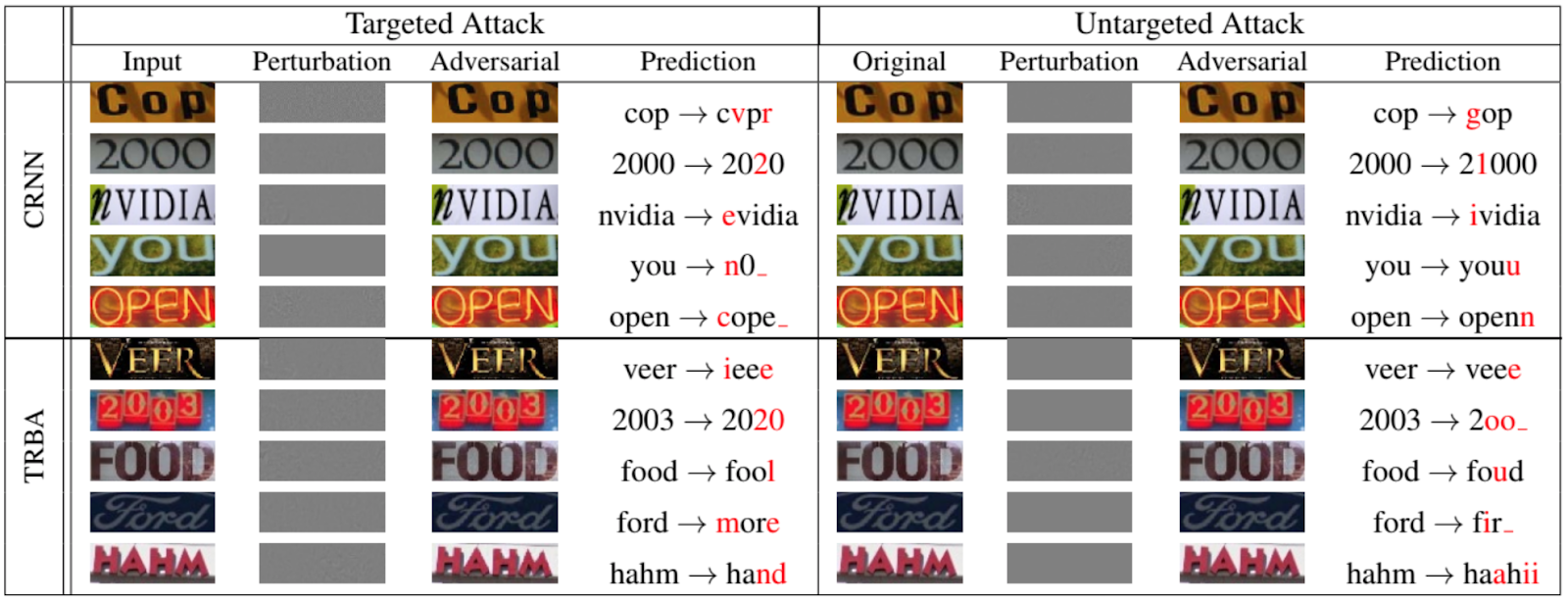
ネットワークに対する他の攻撃について
私たちの話の中で、トレーニングサンプルについて何度か言及しましたが、攻撃者のターゲットは、トレーニングされたモデルではなく、トレーニングされたモデルではない場合があることを示しています。
ほとんどの研究は、認識モデルは実際の代表的なデータで最もよく教えられることを示しています。つまり、モデルは多くの貴重な情報を持っていることがよくあります。猫の写真を盗むことに誰もが興味を持っている可能性は低いです。しかし、認識アルゴリズムは、医療目的、個人情報および生体情報を処理するためのシステムなどにも使用され、「トレーニング」の例(ライブの個人情報または生体情報の形式)が非常に価値があります。
それでは、所有権の確立に対する攻撃とモデル反転による攻撃の2種類の攻撃について考えてみましょう。
アフィリエーションアタック
この攻撃では、攻撃者は特定のデータがモデルのトレーニングに使用されたかどうかを判断しようとします。一見、これには何の問題もないように見えますが、前述のように、いくつかのプライバシー違反があります。
まず、人に関するデータの一部がトレーニングで使用されたことを知っているので、モデルから人に関する他のデータをプルすることを試みることができます(場合によっては成功することさえあります)。たとえば、人の個人データも保存する顔認識システムがある場合は、その人の写真を名前で再現してみることができます。
第二に、医療秘密の直接開示が可能です。たとえば、アルツハイマーの人の動きを追跡するモデルがあり、特定の人に関するデータがトレーニングに使用されていることがわかっている場合、その人が病気であることはすでにわかっています[9]。
モデル反転攻撃
モデルの反転とは、トレーニングされたモデルからトレーニングデータを取得する機能を指します。自然言語処理、そして最近では画像認識では、シーケンス処理ネットワークがよく使用されます。確かに、検索クエリを入力するときに、誰もがGoogleまたはYandexで自動補完に遭遇しました。このようなシステムでのフレーズの継続は、利用可能なトレーニングサンプルに基づいて構築されています。その結果、トレーニングセットに個人データが含まれていると、それらが突然オートコンプリートに表示される可能性があります[10、11]。
結論の代わりに
毎日、さまざまな規模の人工知能システムが私たちの日常生活にますます「定着」しています。日常のプロセスを自動化し、一般的な安全性を高め、別の明るい未来を約束するという美しい約束の下で、私たちは人工知能システムに次々と人間の生活のさまざまな領域を提供します:90年代のテキスト入力、2000年代のドライバー支援システム、2010年のバイオメトリクス処理- xなど。これまでのところ、これらすべての分野で、人工知能システムにはアシスタントの役割しか与えられていませんが、人間の性質のいくつかの特性(まず第一に、怠惰と無責任)のために、コンピューターの心はしばしば指揮官として機能し、時には不可逆的な結果につながります。オートパイロットが
どのようにクラッシュするかについての話を誰もが聞いたことがある、銀行部門の人工知能システムが誤っている、バイオメトリクス処理の問題が発生します。最近では、顔認識システムのエラーにより、ロシア人はほぼ8年間投獄されていました。
これまでのところ、これらはすべて花であり、孤立したケースで表されています。
ベリーは先にあります。我ら。すぐに。
書誌
[1] T. Gu, K. Liu, B. Dolan-Gavitt, and S. Garg, «BadNets: Evaluating backdooring attacks on deep neural networks», 2019, IEEE Access.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.
[2] G. Xu, H. Li, H. Ren, K. Yang, and R.H. Deng, «Data security issues in deep learning: attacks, countermeasures, and opportunities», 2019, IEEE Communications magazine.
[3] N. Akhtar, and A. Mian, «Threat of adversarial attacks on deep learning in computer vision: a survey», 2018, IEEE Access.
[4] C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, «Intriguing properties of neural networks», 2014.
[5] I.J. Goodfellow, J. Shlens, and C. Szegedy, «Explaining and harnessing adversarial examples», 2015, ICLR.
[6] A. Kurakin, I.J. Goodfellow, and S. Bengio, «Adversarial examples in real world», 2017, ICLR Workshop track
[7] S.-M. Moosavi-Dezfooli, A. Fawzi, O. Fawzi, and P. Frossard, «Universal adversarial perturbations», 2017, CVPR.
[8] X. Yuan, P. He, Q. Zhu, and X. Li, «Adversarial examples: attacks and defenses for deep learning», 2019, IEEE Transactions on neural networks and learning systems.
[9] A. Pyrgelis, C. Troncoso, and E. De Cristofaro, «Knock, knock, who's there? Membership inference on aggregate location data», 2017, arXiv.
[10] N. Carlini, C. Liu, U. Erlingsson, J. Kos, and D. Song, «The secret sharer: evaluating and testing unintended memorization in neural networks», 2019, arXiv.
[11] C. Song, and V. Shmatikov, «Auditing data provenance in text-generation models», 2019, arXiv.
[12] X. Xu, J. Chen, J. Xiao, L. Gao, F. Shen, and H.T. Shen, «What machines see is not what they get: fooling scene text recognition models with adversarial text images», 2020, CVPR.
[13] M. Fredrikson, S. Jha, and T. Ristenpart, «Model Inversion Attacks that Exploit Confidence Information and Basic Countermeasures», 2015, ACM Conference on Computer and Communications Security.
[14] Engstrom, Logan, et al. «Exploring the landscape of spatial robustness.» International Conference on Machine Learning. 2019.