前書き
機械学習技術は、過去1年間で信じられないほどのペースで進化してきました。ますます多くの企業がベストプラクティスを共有しているため、スマートデジタルアシスタントを作成するための新しい可能性が開かれています。
この記事の一部として、音声アシスタントの実装における私の経験を共有し、音声アシスタントをさらにスマートで便利にするためのいくつかのアイデアを提供したいと思います。

?
| offline- | ||
| pip install PyAudio ( )
pip install pyttsx3 ( ) :
|
||
| pip install pyowm (OpenWeatherMap) | ||
| Google ( ) | pip install google | |
| YouTube | - | |
| Wikipedia c | pip install wikipedia-api | |
| フレーズをターゲット言語からユーザーの母国語に、またはその逆に翻訳します。 | サポートされていません | pip install googletrans(Google Translate) |
| ソーシャルネットワークで姓名で人を検索する | サポートされていません | - |
| 「コインをはじく」 | サポートされています | - |
| 挨拶してさよならを言う(さようならの後、アプリケーションは終了します) | サポートされています | - |
| 外出先で言語認識と音声合成の設定を変更する | サポートされています | - |
| TODOはるかに..。 | ||
手順1.音声入力の処理
音声入力の処理方法を学ぶことから始めましょう。マイクといくつかのインストール済みライブラリが必要です:PyAudioとSpeechRecognition。
音声認識の基本的なツールを準備しましょう。
import speech_recognition
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
voice_input = record_and_recognize_audio()
print(voice_input)
それでは、音声を録音して認識するための関数を作成しましょう。オンラインでの認識には、多くの言語で高い認識品質を備えたGoogleが必要です。
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
except speech_recognition.RequestError:
print("Check your Internet Connection, please")
return recognized_data
インターネットにアクセスできない場合はどうなりますか?オフライン認識のソリューションを使用できます。私は個人的にVoskプロジェクトが本当に好きでした。
実際、オフラインオプションが必要ない場合は、実装する必要はありません。記事のフレームワーク内で両方の方法を示したかったのですが、システム要件に基づいてすでに選択しています(たとえば、Googleは間違いなく利用可能な認識言語の数のリーダーです)。オフラインソリューションを実装し、必要な言語モデルをプロジェクトに追加したので、ネットワークにアクセスできない場合は、自動的にオフライン認識に切り替えます。
同じフレーズを2回繰り返す必要がないように、マイクからの音声を一時的なwavファイルに録音することにしました。このファイルは、認識されるたびに削除されます。
したがって、結果のコードは次のようになります。
音声認識が機能するための完全なコード
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import wave # wav
import json # json- json-
import os #
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
「なぜオフライン機能をサポートするのか」と質問するかもしれません。
ユーザーがネットワークから切り離される可能性があることを常に考慮する価値があると思います。この場合、音声アシスタントは、会話型ボットとして使用したり、何かを数えたり、映画を推薦したり、キッチンを選んだり、ゲームをしたりするなど、いくつかの簡単なタスクを解決する場合に役立ちます。
手順2.音声アシスタントを構成する
私たちの音声アシスタントは、性別、スピーチの言語、そして古典によれば名前を持つことができるので、このデータ用に別のクラスを選択しましょう。これは将来使用する予定です。
アシスタントの音声を設定するために、pyttsx3オフライン音声合成ライブラリを使用します。オペレーティングシステムの設定に応じて、コンピュータで合成に使用できる音声が自動的に検出されます(したがって、他の音声を使用できる可能性があり、異なるインデックスが必要になる可能性があります)。
また、メイン機能に音声合成の初期化とそれを再生するための別の機能を追加します。すべてが機能することを確認するために、ユーザーが私たちに挨拶したことを少し確認し、アシスタントからの返信の挨拶をします。
音声アシスタントフレームワークの完全なコード(音声の合成と認識)
from vosk import Model, KaldiRecognizer # - Vosk
import speech_recognition # (Speech-To-Text)
import pyttsx3 # (Text-To-Speech)
import wave # wav
import json # json- json-
import os #
class VoiceAssistant:
"""
, , ,
"""
name = ""
sex = ""
speech_language = ""
recognition_language = ""
def setup_assistant_voice():
"""
(
)
"""
voices = ttsEngine.getProperty("voices")
if assistant.speech_language == "en":
assistant.recognition_language = "en-US"
if assistant.sex == "female":
# Microsoft Zira Desktop - English (United States)
ttsEngine.setProperty("voice", voices[1].id)
else:
# Microsoft David Desktop - English (United States)
ttsEngine.setProperty("voice", voices[2].id)
else:
assistant.recognition_language = "ru-RU"
# Microsoft Irina Desktop - Russian
ttsEngine.setProperty("voice", voices[0].id)
def play_voice_assistant_speech(text_to_speech):
"""
( )
:param text_to_speech: ,
"""
ttsEngine.say(str(text_to_speech))
ttsEngine.runAndWait()
def record_and_recognize_audio(*args: tuple):
"""
"""
with microphone:
recognized_data = ""
#
recognizer.adjust_for_ambient_noise(microphone, duration=2)
try:
print("Listening...")
audio = recognizer.listen(microphone, 5, 5)
with open("microphone-results.wav", "wb") as file:
file.write(audio.get_wav_data())
except speech_recognition.WaitTimeoutError:
print("Can you check if your microphone is on, please?")
return
# online- Google
# ( )
try:
print("Started recognition...")
recognized_data = recognizer.recognize_google(audio, language="ru").lower()
except speech_recognition.UnknownValueError:
pass
#
# offline- Vosk
except speech_recognition.RequestError:
print("Trying to use offline recognition...")
recognized_data = use_offline_recognition()
return recognized_data
def use_offline_recognition():
"""
-
:return:
"""
recognized_data = ""
try:
#
if not os.path.exists("models/vosk-model-small-ru-0.4"):
print("Please download the model from:\n"
"https://alphacephei.com/vosk/models and unpack as 'model' in the current folder.")
exit(1)
# ( )
wave_audio_file = wave.open("microphone-results.wav", "rb")
model = Model("models/vosk-model-small-ru-0.4")
offline_recognizer = KaldiRecognizer(model, wave_audio_file.getframerate())
data = wave_audio_file.readframes(wave_audio_file.getnframes())
if len(data) > 0:
if offline_recognizer.AcceptWaveform(data):
recognized_data = offline_recognizer.Result()
# JSON-
# ( )
recognized_data = json.loads(recognized_data)
recognized_data = recognized_data["text"]
except:
print("Sorry, speech service is unavailable. Try again later")
return recognized_data
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
#
ttsEngine = pyttsx3.init()
#
assistant = VoiceAssistant()
assistant.name = "Alice"
assistant.sex = "female"
assistant.speech_language = "ru"
#
setup_assistant_voice()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
if command == "":
play_voice_assistant_speech("")
実際、ここで私は自分でスピーチシンセサイザーを書く方法を学びたいのですが、ここでの私の知識は十分ではありません。このトピックを深く理解するのに役立つ優れた文献、コース、または興味深い文書化された解決策を提案できる場合は、コメントに書き込んでください。
ステップ3.コマンド処理
同僚の単純な神聖な発展の助けを借りて音声を認識して合成することを「学んだ」ので、ユーザーの音声コマンドを処理するためのホイールを再発明し始めることができます。D
私の場合、コマンドを保存するために多言語オプションを使用します。イベント、および私はこれまたはそのコマンドの定義の正確さに満足しています。ただし、大規模なプロジェクトの場合は、構成を言語ごとに分けることをお勧めします。
コマンドを保存する方法は2つあります。
片道
意図、開発シナリオ、試行が失敗した場合の応答を保存するための優れたJSONのようなオブジェクトを使用できます(これらはチャットボットによく使用されます)。これは次のようになります。
config = {
"intents": {
"greeting": {
"examples": ["", "", " ",
"hello", "good morning"],
"responses": play_greetings
},
"farewell": {
"examples": ["", " ", "", " ",
"goodbye", "bye", "see you soon"],
"responses": play_farewell_and_quit
},
"google_search": {
"examples": [" ",
"search on google", "google", "find on google"],
"responses": search_for_term_on_google
},
},
"failure_phrases": play_failure_phrase
}
このオプションは、難しいフレーズに応答するようにアシスタントをトレーニングしたい人に適しています。さらに、ここでは、NLUアプローチを適用し、すでに構成に含まれているものと照合することで、ユーザーの意図を予測する機能を作成できます。
この方法については、この記事のステップ5で詳しく説明します。それまでの間、より簡単なオプションに注意を向けます。
2ウェイ
ハッシュ可能なタイプのタプルをキーとして持つ簡略化された辞書を使用できます(辞書はハッシュを使用して要素をすばやく格納および取得するため)。実行される関数の名前は値の形式になります。短いコマンドの場合、次のオプションが適しています。
commands = {
("hello", "hi", "morning", ""): play_greetings,
("bye", "goodbye", "quit", "exit", "stop", ""): play_farewell_and_quit,
("search", "google", "find", ""): search_for_term_on_google,
("video", "youtube", "watch", ""): search_for_video_on_youtube,
("wikipedia", "definition", "about", "", ""): search_for_definition_on_wikipedia,
("translate", "interpretation", "translation", "", "", ""): get_translation,
("language", ""): change_language,
("weather", "forecast", "", ""): get_weather_forecast,
}
それを処理するには、次のようにコードを追加する必要があります。
def execute_command_with_name(command_name: str, *args: list):
"""
:param command_name:
:param args: ,
:return:
"""
for key in commands.keys():
if command_name in key:
commands[key](*args)
else:
pass # print("Command not found")
if __name__ == "__main__":
#
recognizer = speech_recognition.Recognizer()
microphone = speech_recognition.Microphone()
while True:
#
#
voice_input = record_and_recognize_audio()
os.remove("microphone-results.wav")
print(voice_input)
# ()
voice_input = voice_input.split(" ")
command = voice_input[0]
command_options = [str(input_part) for input_part in voice_input[1:len(voice_input)]]
execute_command_with_name(command, command_options)
コマンドワードの後に、追加の引数が関数に渡されます。それはあなたがフレーズ「と言うならば、ある動画はかわいい猫です」、コマンド「ビデオは」引数「とsearch_for_video_on_youtube()関数を呼び出しますかわいい猫:」と、次の結果得られます
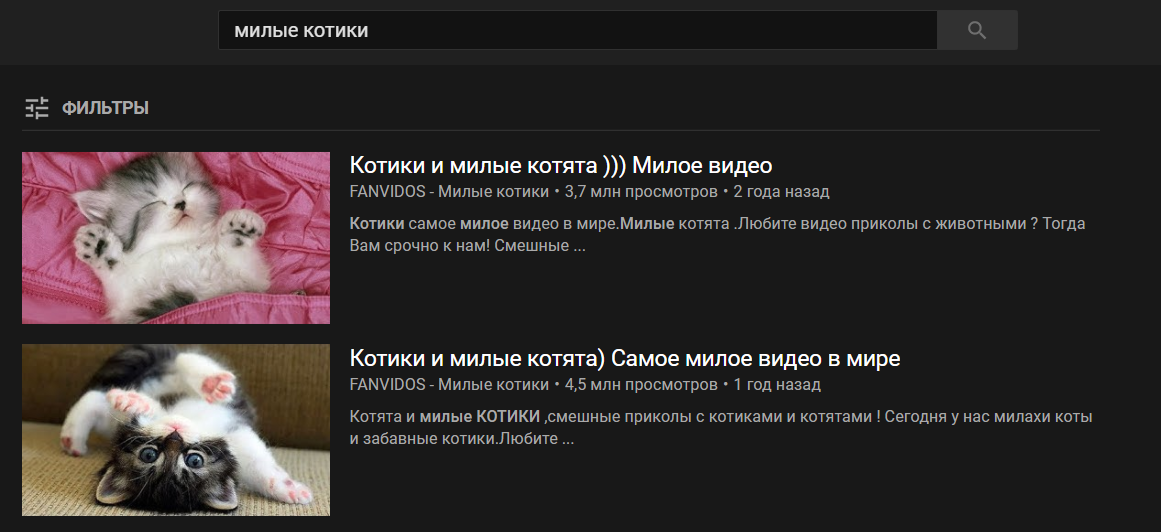
、着信引数を処理して、このような機能の例を:
def search_for_video_on_youtube(*args: tuple):
"""
YouTube
:param args:
"""
if not args[0]: return
search_term = " ".join(args[0])
url = "https://www.youtube.com/results?search_query=" + search_term
webbrowser.get().open(url)
#
# , JSON-
play_voice_assistant_speech("Here is what I found for " + search_term + "on youtube")
それでおしまい!ボットの主な機能は準備ができています。その後、さまざまな方法でそれを際限なく改善することができます。詳細なコメントを含む私の実装は、GitHubで入手できます。
以下では、アシスタントをさらにスマートにするためのいくつかの改善点について説明します。
ステップ4.多言語主義を追加する
アシスタントに複数の言語モデルを操作するように教えるには、単純な構造の小さなJSONファイルを整理するのが最も便利です。
{
"Can you check if your microphone is on, please?": {
"ru": ", , ",
"en": "Can you check if your microphone is on, please?"
},
"What did you say again?": {
"ru": ", ",
"en": "What did you say again?"
},
}
私の場合、音声認識のモデルと音声合成の音声を使用できるため、ロシア語と英語の切り替えを使用します。言語は、音声アシスタント自体のスピーチの言語に応じて選択されます。
翻訳を受け取るために、翻訳を含む文字列を返すメソッドを使用して、別のクラスを作成できます。
class Translation:
"""
"""
with open("translations.json", "r", encoding="UTF-8") as file:
translations = json.load(file)
def get(self, text: str):
"""
( )
:param text: ,
:return:
"""
if text in self.translations:
return self.translations[text][assistant.speech_language]
else:
#
#
print(colored("Not translated phrase: {}".format(text), "red"))
return text
main関数では、ループの前に、トランスレータを次のように宣言します。translator= Translation()
これで、アシスタントのスピーチを再生すると、次のようにトランスレーションを取得できます。
play_voice_assistant_speech(translator.get(
"Here is what I found for {} on Wikipedia").format(search_term))
上記の例からわかるように、これは、追加の引数を挿入する必要がある行でも機能します。したがって、アシスタントの「標準」のフレーズセットを翻訳できます。
ステップ5.少し機械学習
ここで、マルチワードコマンドを格納するためのJSONオブジェクトに戻りましょう。これは、パラグラフ3で説明した、ほとんどのチャットボットで一般的です。厳密なコマンドを使用したくない場合や、NLUを使用してユーザーの意図についての理解を深める予定の場合に適しています。 -メソッド。
大雑把に言えば、この場合には、語句「良い午後」、「良い夜」と「良い朝」と同等とみなされます。アシスタントは、3つのケースすべてで、ユーザーの意図が音声アシスタントに挨拶することであったことを理解します。
この方法を使用して、チャット用の会話型ボットまたは音声アシスタント用の会話型モードを作成することもできます(対話者が必要な場合)。
このような可能性を実装するには、いくつかの関数を追加する必要があります。
def prepare_corpus():
"""
"""
corpus = []
target_vector = []
for intent_name, intent_data in config["intents"].items():
for example in intent_data["examples"]:
corpus.append(example)
target_vector.append(intent_name)
training_vector = vectorizer.fit_transform(corpus)
classifier_probability.fit(training_vector, target_vector)
classifier.fit(training_vector, target_vector)
def get_intent(request):
"""
:param request:
:return:
"""
best_intent = classifier.predict(vectorizer.transform([request]))[0]
index_of_best_intent = list(classifier_probability.classes_).index(best_intent)
probabilities = classifier_probability.predict_proba(vectorizer.transform([request]))[0]
best_intent_probability = probabilities[index_of_best_intent]
#
if best_intent_probability > 0.57:
return best_intent
また、変数の初期化を追加してモデルを準備し、ループを新しい構成に対応するバージョンに変更することにより、main関数をわずかに変更します。
#
# ( )
vectorizer = TfidfVectorizer(analyzer="char", ngram_range=(2, 3))
classifier_probability = LogisticRegression()
classifier = LinearSVC()
prepare_corpus()
while True:
#
#
voice_input = record_and_recognize_audio()
if os.path.exists("microphone-results.wav"):
os.remove("microphone-results.wav")
print(colored(voice_input, "blue"))
# ()
if voice_input:
voice_input_parts = voice_input.split(" ")
# -
#
if len(voice_input_parts) == 1:
intent = get_intent(voice_input)
if intent:
config["intents"][intent]["responses"]()
else:
config["failure_phrases"]()
# -
# ,
#
if len(voice_input_parts) > 1:
for guess in range(len(voice_input_parts)):
intent = get_intent((" ".join(voice_input_parts[0:guess])).strip())
if intent:
command_options = [voice_input_parts[guess:len(voice_input_parts)]]
config["intents"][intent]["responses"](*command_options)
break
if not intent and guess == len(voice_input_parts)-1:
config["failure_phrases"]()
ただし、この方法は制御がより困難です。特定の意図の一部として、このフレーズまたはそのフレーズがシステムによって正しく識別されていることを常に確認する必要があります。したがって、この方法は注意して使用する必要があります(またはモデル自体を試してみてください)。
結論
これで私の小さなチュートリアルは終わりです。
このプロジェクトで実装できることがわかっているオープンソースソリューションのコメントと、他のオンラインおよびオフライン機能を実装できるかどうかについてのアイデアをコメントで共有していただければ幸いです。
2つのバージョンの私の音声アシスタントの文書化されたソースはここにあります。
PS:ソリューションはWindows、Linux、MacOSで動作しますが、PyAudioライブラリとGoogleライブラリをインストールする際のわずかな違いがあります。