
チャットボットは現在、さまざまなビジネス分野で広く使用されています。たとえば、銀行はそれらを使用してコンタクトセンターの作業を最適化し、顧客からの人気のある質問に即座に回答し、参照情報を提供できます。顧客にとって、チャットボットも便利なツールです。コンタクトセンターに電話して回答を待つよりも、チャットで質問を書く方がはるかに簡単です。
他の分野では、チャットボットもうまく機能しました。医学では、チャットボットは患者にインタビューし、専門家に症状を伝え、診断を確立するために医師との約束をすることができます。物流会社では、チャットボットが配達日の合意、住所の変更、便利なピックアップポイントの選択を支援します。大規模なオンラインストアでは、チャットボットが注文の保守を部分的に引き継いでおり、カーシェアリングサービスの分野では、チャットボットがオペレーターのタスクの最大90%を実行します。ただし、チャットボットはまだ苦情を解決することができません。否定的なフィードバックや物議を醸す状況は、依然としてオペレーターやスペシャリストの肩にかかっています。
したがって、ほとんどの成長企業はすでにチャットボットを積極的に使用して顧客と協力しています。ただし、チャットボットを実装するメリットはさまざまです。一部の企業では自動化レベルが90%に達し、他の企業では30〜40%にすぎません。それは何に依存していますか?この指標はビジネスにとってどの程度優れていますか?チャットボットの自動化のレベルを上げる方法はありますか?この記事では、これを理解するのに役立つ質問について説明します。
ベンチマーク
今日、ほぼすべての事業分野に独自の競争環境があります。多くの企業が同様のビジネスアプローチを採用しています。したがって、競合する企業が活動にチャットボットを使用している場合は、それらを比較することをお勧めします。ベンチマークは優れた比較ツールです。
私たちの場合、チャットボットのベンチマークには、競合他社のチャットボットの機能を独自のチャットボットの機能と比較するための秘密の調査が含まれます。例として銀行チャットボットを使用したケースを考えてみましょう。
銀行がコンタクトセンターの運用を最適化し、それを維持するためのコストを削減するためにチャットボットを開発したとします。ベンチマークを実施するには、他の銀行を分析し、競合他社の中で最も機能的なチャットボットを特定する必要があります。
検証のために質問のリストを作成する必要があります(少なくとも50の質問をいくつかのトピックに分割します)。
- 銀行サービスに関する質問。たとえば、「デポジットレートはいくらですか?」、「カードを再発行する方法は?」などです。等
- 参照情報、例:「現在の為替レートはいくらですか?」、「クレジット休暇を取得する方法は?」等
- クライアントの理解レベル。(タイプミス、エラー、口頭でのスピーチの認識に対するボットの抵抗)、たとえば、「マップをポップしています、何をしていますか?」、「モバイルを補充する」など。
- 抽象的トピックに関する会話。たとえば、「冗談を言う」、「自己隔離中に何をすべきか」など。等
注:これらの質問のトピックは例として示され、拡張または変更できます。
これらは、チャットボットと競合他社のチャットボットに尋ねる必要のある質問です。質問を書いた後、結果の3つのオプションが可能です(結果に応じて、対応するスコアが下に置かれます):
- ボットは顧客の質問を認識しませんでした(0ポイント)。
- ボットはクライアントの質問を認識しましたが、質問を明確にした後でのみ(0.5ポイント)。
- ボットは最初の試行で質問を認識しました(1ポイント)。
チャットボットがクライアントをオペレーターに転送した場合、質問も認識されていないと見なされます(0ポイント)。
次に、各チャットボットによって獲得されたポイント数が合計され、その後、各トピックで正しく認識された質問の割合が計算され(低-40%未満、中-40から80%、高-80%超)、最終的な評価がまとめられます。結果は、表の形式で表示できます。
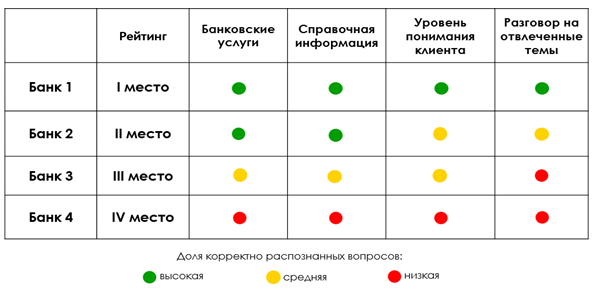
ベンチマークの結果によると、銀行のチャットボットが2位になったとします。どのような結論を導き出すことができますか?結果は最高ではありませんが、最悪でもありません。表に基づいて、その強みではない側面について言うことができます。まず、クライアントの質問を正しく認識するためにアルゴリズムを改善する必要があります(チャットボットは、エラーやタイプミスを含むクライアントの質問を常に理解するとは限りません)。また、抽象的なトピックに関する対話を常にサポートするとは限りません。 ..。そもそもチャットボットと比較すると、より詳細な違いが見られます。
3位になったチャットボットは、それ自体が悪化しました。第一に、銀行サービスと参照情報に関する知識ベースの大幅な改訂が必要であり、第二に、抽象的なトピックに関するクライアントとの対話のためのトレーニングが不十分です。このようなチャットボットの自動化のレベルが、IおよびIIの場所を獲得した競合他社と比較して低いレベルであることは明らかです。
したがって、ベンチマークの結果に基づいて、チャットボットの作業の長所と短所を特定し、競合するチャットボットを相互に比較しました。次のステップは、これらの問題領域を特定することです。これはどのように達成できますか?データ分析に基づくいくつかのアプローチを考えてみましょう:AutoML、プロセスマイニング、DEアプローチ。
AutoML
現在、人工知能はすでに浸透しており、ビジネスの多くの分野に浸透し続けています。これは必然的に、DataScienceの分野での能力に対する需要の増加を伴います。しかし、そのような専門家の需要は、彼らの資格のレベルよりも急速に成長しています。事実、機械学習モデルの開発には多くのリソースが必要であり、専門家からの大量の知識だけでなく、モデルの構築と比較にかなりの時間を費やす必要があります。不足によって生じるプレッシャーを軽減し、モデルの開発時間を短縮するために、多くの企業がDataScientistsの作業を自動化できるアルゴリズムの作成を開始しています。このようなアルゴリズムはAutoMLと呼ばれます。
自動機械学習とも呼ばれるAutoMLは、DataScientistが品質を維持しながら、機械学習モデルを開発するという時間のかかる反復的なタスクを自動化するのに役立ちます。 AutoMLモデルは時間を節約できますが、解決する問題が永続的で反復的な場合にのみ効果的です。これらの条件下では、AutoMLモデルは良好に機能し、許容できる結果を示します。
それでは、AutoMLを使用して問題を解決しましょう。チャットボットの作業で問題のある領域を特定します。上記のように、チャットボットはロボット、または特殊なプログラムです。彼女は、メッセージからキーワードを抽出し、データベースで適切な回答を検索する方法を知っています。正しい答えを探すことと、論理的な対話を維持し、実在の人物とのコミュニケーションを模倣することです。このプロセスは、チャットボットのスクリプトがどれだけ適切かによって異なります。
クライアントに質問があり、チャットボットが奇妙に、論理的ではなく、または一般的に別のトピックについて彼に答える状況を想像してみてください。その結果、クライアントはそのような答えに満足せず、せいぜい答えの誤解について書いています。最悪の場合、チャットボットの方向への否定的なメッセージです。したがって、AutoMLのタスクは、(データベースからアンロードされたチャットボットログに基づいて)総数から否定的なダイアログを特定することです。その後、これらのダイアログがどのシナリオに関連するかを特定する必要があります。得られた結果は、これらのシナリオの改良の基礎となります。
まず、チャットボットとのクライアントの対話をマークアップしましょう。各ダイアログでは、クライアントからのメッセージのみを残します。クライアントのメッセージでチャットボットの方向に否定的なものがある場合、または彼の回答を理解していない場合は、フラグ= 1を設定し、それ以外の場合は= 0を設定します。

クライアントからのメッセージのマーキング
次に、AutoMLモデルを宣言し、マークアップされたデータでトレーニングして保存します(必要なモデルパラメータもすべて渡されますが、以下の例には示されていません)。
automl = saa.AutoML
res_df, feat_imp = automl.train('test.csv', 'test_preds.csv', 'classification', cache_dir = 'tmp_dir', use_ids = False)
automl.save('prec')結果のモデルをロードした後、テストファイルのターゲット変数を予測します。
automl = saa.AutoML
automl.load('text_model.pkl')
preds_df, score, res_df = automl.predict('test.csv', 'test_preds.csv', cache_dir = 'tmp_dir')
preds_df.to_csv('preds.csv', sep=',', index=False)次に、結果のモデルを評価します。
test_df = pd.read_csv('test.csv')
threshold = 0.5
am_test = preds_df['prediction'].copy()
am_test.loc[am_test>=threshold] = 1
am_test.loc[am_test<threshold] = 0
clear_output()
print_result(test_df[target_col], am_test.apply(int))結果として得られるエラーのマトリックス:

モデルを作成する過程で、タイプ1のエラー(良いダイアログを悪いダイアログとして分類する)を最小化しようとしたため、結果の分類子では、0.66に等しいf1メジャーで停止しました。訓練されたモデルの助けを借りて、65,000の「悪い」セッションを特定することが可能であり、それにより、7つの不十分に効果的なシナリオを特定することが可能になりました。
プロセスマイニング
問題のあるシナリオを特定するために、プロセスマイニングに基づくツールを使用することもできます。これは、イベントログの調査に基づいて、情報システムまたはビジネスプロセスのプロセスを分析および改善するために設計された多くの方法とアプローチの総称です。
この方法を使用して、長くて効果のない対話に関係する7つのシナリオを特定することができました。対話の
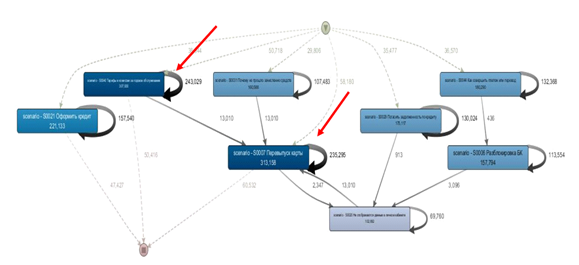
18%に、チャットボットからの4つ以上のメッセージ
があります。上のグラフの各要素はシナリオです。図からわかるように、スクリプトはループされており、太字のループ矢印は、クライアントとチャットボットの間のかなり長い対話を示しています。
さらに、悪いシナリオを見つけるために、別のデータセットを用意し、それに基づいてグラフを作成しました。これを行うために、オペレーターにアクセスできないダイアログのみが残され、その後、未解決の問題があるダイアログが除外されました。その結果、チャットボットがクライアントの質問を解決しない、改善のための5つのシナリオを特定しました。
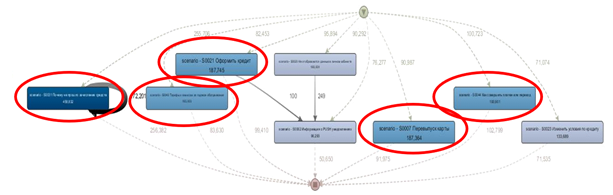
識別されたシナリオは、すべての対話の約15%に含まれます
DE(データエンジニアリング)アプローチ
問題のシナリオを検索するために、単純な分析アプローチも使用されました。ダイアログが特定され、(クライアント側からの)フィードバック評価が1〜7ポイントの範囲であり、このサンプルで最も一般的なシナリオが選択されました。
したがって、AutoML、Process Mining、およびDEに基づくアプローチを包括的に適用して、改善が必要な会社のチャットボットの問題領域を特定しました。
今、チャットボットは良くなっています!