LightGBMは、自動オブジェクト選択のタイプを追加するだけでなく、大きな勾配でのブーストの例に焦点を当てることにより、勾配ブーストアルゴリズムを拡張します。これにより、学習が劇的に加速し、予測パフォーマンスが向上します。したがって、LightGBMは、回帰および分類予測モデリングの問題について表形式のデータを処理する場合の機械学習競争の事実上のアルゴリズムになりました。このチュートリアルでは、分類と回帰のためにLight GradientBoostedマシンアンサンブルを設計する方法を示します。このチュートリアルを完了すると、次のことがわかります。
- Light Gradient Boosted Machine(LightGBM)は、確率的勾配ブーストアンサンブルの効率的なオープンソース実装です。
- scikit-learnAPIを使用して分類と回帰のためのLightGBMアンサンブルを開発する方法。
- LightGBM .

- LightBLM.
- Scikit-Learn API LightGBM.
— LightGBM .
— LightGBM . - LightGBM.
— .
— .
— .
— .
LightBLM
勾配ブーストは、分類問題または予測回帰モデリングに使用できるアンサンブルマシン学習アルゴリズムのクラスに属しています。
アンサンブルは、意思決定ツリーモデルに基づいて構築されます。ツリーは一度に1つずつアンサンブルに追加され、以前のモデルによって作成された予測エラーを修正するようにトレーニングされます。これは、ブースティングと呼ばれるアンサンブルマシン学習モデルの一種です。
モデルは、任意の微分可能な損失関数と勾配降下最適化アルゴリズムを使用してトレーニングされます。これは、ニューラルネットワークのようにモデルがトレーニングされるときに損失勾配が最小化されるため、メソッドに「勾配ブースティング」という名前を付けます。勾配ブーストの詳細については、チュートリアルを参照してください。「ML勾配ブーストアルゴリズムの穏やかな紹介。」
LightGBMは、効率的で、場合によっては他の実装よりも効率的になるように設計された、勾配ブーストのオープンソース実装です。
そのため、LightGBMは、オープンソースプロジェクト、ソフトウェアライブラリ、およびマシン学習アルゴリズムです。つまり、このプロジェクトはExtreme GradientBoostingまたはXGBoostテクニックと非常によく似ています。
LightGBMは、Golin、K.、etal。によって説明されています。詳細については、「LightGBM:A Highly Efficient Gradient BoostingDecisionTree」というタイトルの2017年の記事を参照してください。この実装では、GOSSとEFBという2つの重要なアイデアが導入されています。
Gradient One-Way Sampling(GOSS)は、Gradient Boostingの修正版であり、より大きな勾配をもたらすチュートリアルに焦点を当てています。これにより、学習がスピードアップし、メソッドの計算の複雑さが軽減されます。
GOSSを使用すると、勾配が小さいデータインスタンスの大部分を除外し、残りのデータインスタンスのみを使用して情報の増加を推定します。大きな勾配を持つデータインスタンスが情報ゲインの計算においてより重要な役割を果たすため、GOSSははるかに小さいデータサイズで情報ゲインのかなり正確な推定値を取得できると主張します。
Exclusive Feature Bundling(EFB)は、単一のエンコーディングでエンコードされたカテゴリ入力変数など、スパース(ほとんどがnull)の相互に排他的な機能を組み合わせるアプローチです。したがって、これは一種の自動機能選択です。
...相互に排他的な機能をパッケージ化して(つまり、同時にゼロ以外の値を取ることはめったにありません)、機能の数を減らします。
これら2つの変更を合わせると、アルゴリズムのトレーニング時間を最大20倍まで高速化できます。したがって、LightGBMは、GOSSとEFBが追加されたGradient Boosted Decision Tree(GBDT)と考えることができます。
新しいGBDT実装をGOSSおよびEFBLightGBMと呼びます。いくつかの公開されているデータセットでの実験では、LightGBMが従来のGBDTの学習プロセスを20倍以上加速し、ほぼ同じ精度を達成していることが示されています。
Scikit-LightGBMのAPIを学ぶ
LightGBMはスタンドアロンライブラリとしてインストールでき、LightGBMモデルはscikit-learnAPIを使用して開発できます。
最初のステップは、LightGBMライブラリをインストールすることです。ほとんどのプラットフォームでは、pipパッケージマネージャーを使用して実行できます。例えば:
sudo pip install lightgbm次のようにインストールとバージョンを確認できます。
# check lightgbm version
import lightgbm
print(lightgbm.__version__)スクリプトは、インストールされているLightGBMのバージョンを表示します。あなたのバージョンは同じかそれ以上でなければなりません。そうでない場合は、LightGBMを更新します。開発環境に固有の手順が必要な場合は、チュートリアル「LightGBMインストールガイド」を参照してください。
LightGBMライブラリには独自のAPIがありますが、scikit-learnラッパークラス(LGBMRegressorおよびLGBMClassifier)を介したメソッドを使用しています。これにより、scikit-learnマシン学習ライブラリ全体をデータの準備とモデルの評価に使用できるようになります。
どちらのモデルも同じように機能し、同じ引数を使用して、決定ツリーを作成してアンサンブルに追加する方法に影響を与えます。モデルはランダム性を使用します。これは、アルゴリズムが同じデータで実行されるたびに、わずかに異なるモデルが作成されることを意味します。
確率的学習アルゴリズムで機械学習アルゴリズムを使用する場合は、相互検証の数回の実行または繰り返しにわたってパフォーマンスを平均することによってそれらを評価することをお勧めします。最終モデルをフィッティングするときは、推定を繰り返してモデルの分散が減少するまでツリーの数を増やすか、いくつかの最終モデルをトレーニングしてそれらの予測を平均することが望ましい場合があります。分類と回帰の両方のためのLightGBMアンサンブルの設計を見てみましょう。
分類のためのLightGBMアンサンブル
このセクションでは、分類タスクにLightGBMを使用する方法について説明します。まず、make_classification()関数を使用して、1000の例と20の入力機能を持つ合成バイナリ分類問題を作成できます。以下の例全体を参照してください。
# test classification dataset
from sklearn.datasets import make_classification
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# summarize the dataset例を実行すると、データセットが作成され、入力コンポーネントと出力コンポーネントの形状が要約されます。
(1000, 20) (1000,)次に、このデータセットでLightGBMアルゴリズムを評価できます。3回の繰り返しと10のkで繰り返される階層化kフォールド相互検証を使用してモデルを評価します。すべての繰り返しとフォールドにわたるモデル精度の平均と標準偏差を報告します。
# evaluate lightgbm algorithm for classification
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# evaluate the model
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
# report performance
print('Accuracy: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))例を実行すると、モデルの平均と標準偏差の精度がわかります。
注:アルゴリズムや推定手順の確率的な性質、または数値の精度の違いにより、結果が異なる場合があります。例を数回試して、平均結果を比較してください。
この場合、デフォルトのハイパーパラメータを使用したLightGBMアンサンブルは、このテストデータセットで約92.5%の分類精度を達成していることがわかります。
Accuracy: 0.925 (0.031)LightGBMモデルを最終モデルとして使用し、分類の予測を行うこともできます。まず、LightGBMアンサンブルは利用可能なすべてのデータに適合し、次に、predict ()関数を呼び出して新しいデータを予測できます。以下の例は、バイナリ分類データセットでこれを示しています。
# make predictions using lightgbm for classification
from sklearn.datasets import make_classification
from lightgbm import LGBMClassifier
# define dataset
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
# define the model
model = LGBMClassifier()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.2929949,-4.21223056,-1.288332,-2.17849815,-0.64527665,2.58097719,0.28422388,-7.1827928,-1.91211104,2.73729512,0.81395695,3.96973717,-2.66939799,3.34692332,4.19791821,0.99990998,-0.30201875,-4.43170633,-2.82646737,0.44916808]
yhat = model.predict([row])
print('Predicted Class: %d' % yhat[0])この例を実行すると、データセット全体のLightGBMアンサンブルモデルがトレーニングされ、モデルがアプリケーションで使用されている場合と同様に、それを使用して新しいデータ行が予測されます。
Predicted Class: 1分類にLightGBMを使用することに慣れたので、回帰APIを見てみましょう。
回帰用のLightGBMアンサンブル
このセクションでは、回帰問題にLightGBMを使用する方法について説明します。まず、make_regression()関数
を使用して、1000の例と20の入力機能を使用して合成回帰問題を作成できます。以下の例全体を参照してください。
# test regression dataset
from sklearn.datasets import make_regression
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# summarize the dataset
print(X.shape, y.shape)例を実行すると、データセットが作成され、入力コンポーネントと出力コンポーネントが要約されます。
(1000, 20) (1000,)次に、このデータセットでLightGBMアルゴリズムを評価できます。
前のセクションと同様に、3回の繰り返しとkが10に等しいk回の相互検証を繰り返してモデルを評価します。すべての繰り返しと相互検証グループにわたるモデルの平均絶対誤差(MAE)を報告します。 scikit-learnライブラリは、MAEを負にするため、最小化されるのではなく最大化されます。これは、大きな負のMAEの方が優れており、理想的なモデルのMAEが0であることを意味します。完全な例を以下に示します。
# evaluate lightgbm ensemble for regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedKFold
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
n_scores = cross_val_score(model, X, y, scoring='neg_mean_absolute_error', cv=cv, n_jobs=-1, error_score='raise')
# report performance
print('MAE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)))例を実行すると、モデルの平均と標準偏差が報告されます。
注:アルゴリズムや推定手順の確率的な性質、または数値の精度の違いにより、結果が異なる場合があります。例を数回実行し、平均結果を比較することを検討してください。この場合、デフォルトのハイパーパラメータを持つLightGBMアンサンブルが約60のMAEに達することがわかります。
MAE: -60.004 (2.887)LightGBMモデルを最終モデルとして使用し、回帰の予測を行うこともできます。最初に、LightGBMアンサンブルが利用可能なすべてのデータでトレーニングされ、次にpredict ()関数を呼び出して新しいデータを予測できます。以下の例は、回帰データセットでこれを示しています。
# gradient lightgbm for making predictions for regression
from sklearn.datasets import make_regression
from lightgbm import LGBMRegressor
# define dataset
X, y = make_regression(n_samples=1000, n_features=20, n_informative=15, noise=0.1, random_state=7)
# define the model
model = LGBMRegressor()
# fit the model on the whole dataset
model.fit(X, y)
# make a single prediction
row = [0.20543991,-0.97049844,-0.81403429,-0.23842689,-0.60704084,-0.48541492,0.53113006,2.01834338,-0.90745243,-1.85859731,-1.02334791,-0.6877744,0.60984819,-0.70630121,-1.29161497,1.32385441,1.42150747,1.26567231,2.56569098,-0.11154792]
yhat = model.predict([row])
print('Prediction: %d' % yhat[0]) この例を実行すると、データセット全体でLightGBMアンサンブルモデルがトレーニングされ、アプリケーションでモデルを使用する場合と同様に、それを使用して新しいデータ行が予測されます。
Prediction: 52scikit-learn APIを使用してLightGBMアンサンブルを評価および適用する方法に慣れてきたので、モデルの設定を見てみましょう。
LightGBMハイパーパラメータ
このセクションでは、LightGBMアンサンブルにとって重要ないくつかのハイパーパラメーターと、それらがモデルのパフォーマンスに与える影響について詳しく見ていきます。LightGBMには、確認すべきハイパーパラメーターがたくさんあります。ここでは、ツリーの数とその深さ、学習率、およびブーストのタイプを確認します。LightGBMハイパーパラメータの調整に関する一般的なヒントについては、ドキュメント「LightGBMパラメータの調整」を参照してください。
木の数を調べる
LightGBMアンサンブルアルゴリズムの重要なハイパーパラメータは、アンサンブルで使用される決定ツリーの数です。以前のツリーによって行われた予測を修正および改善するために、決定ツリーがモデルに順次追加されることを思い出してください。ルールはよく機能します。木が多いほど良いです。ツリーの数は、n_estimators引数(デフォルトは100)を使用して指定できます。以下の例では、10から5000までのツリー数の影響を調べます。
# explore lightgbm number of trees effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
trees = [10, 50, 100, 500, 1000, 5000]
for n in trees:
models[str(n)] = LGBMClassifier(n_estimators=n)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()最初に例を実行すると、決定ツリーの数ごとの平均精度が表示されます。
注:アルゴリズムや推定手順の確率的な性質、または数値の精度の違いにより、結果が異なる場合があります。例を複数回実行し、平均を比較することを検討してください。
ここでは、このデータセットのパフォーマンスが約500ツリーに向上し、その後は横ばいになっているように見えます。
>10 0.857 (0.033)
>50 0.916 (0.032)
>100 0.925 (0.031)
>500 0.938 (0.026)
>1000 0.938 (0.028)
>5000 0.937 (0.028)ボックスとウィスカーのプロットが作成され、構成されたツリーの数ごとに精度スコアが分散されます。モデルのパフォーマンスとアンサンブルのサイズが増加する傾向があります。
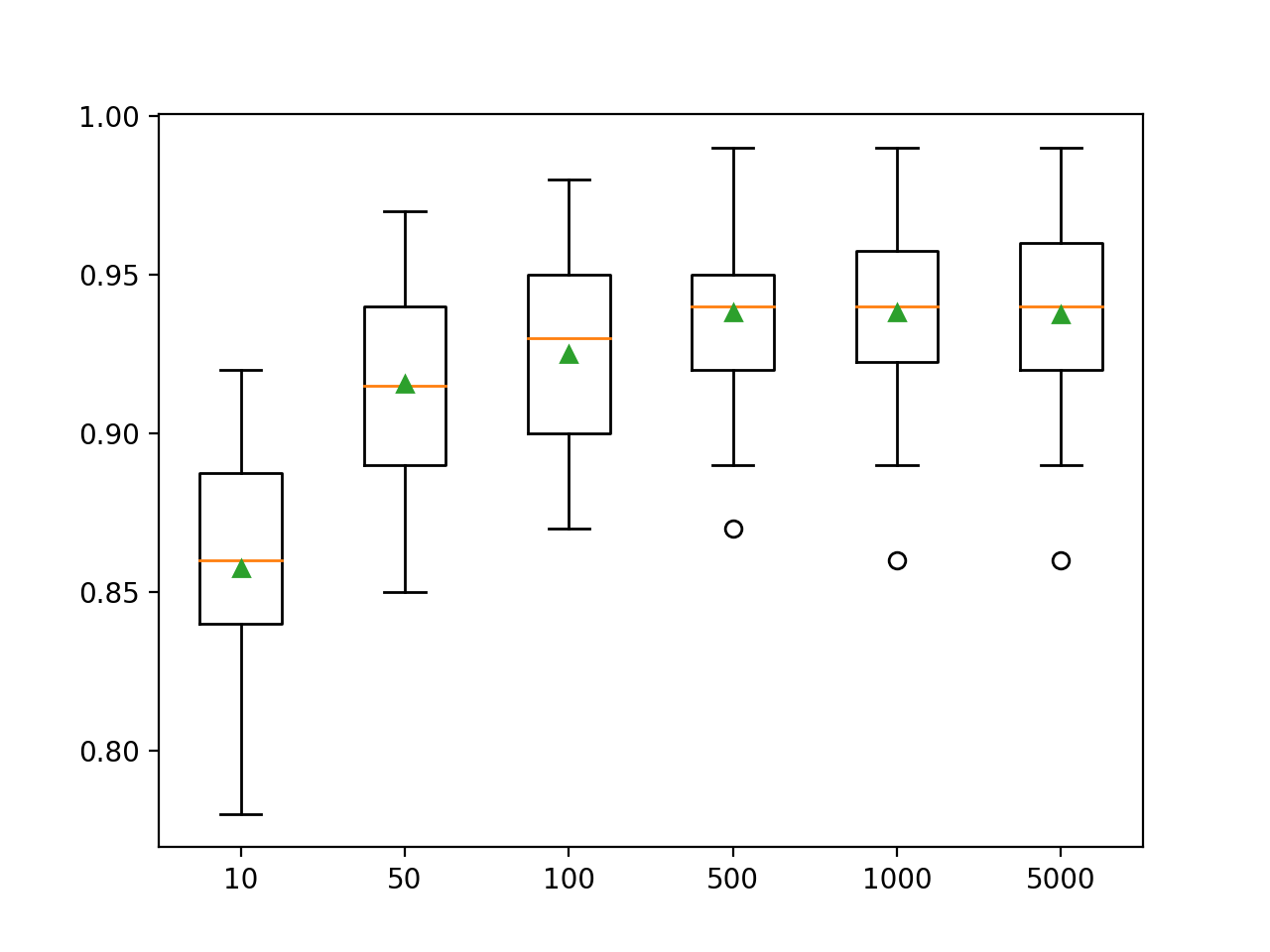
木の深さを調べる
アンサンブルに追加された各ツリーの深さを変更することは、勾配ブーストのもう1つの重要なハイパーパラメーターです。ツリーの深さによって、各ツリーがトレーニングデータセットにどの程度特化しているか、つまり、どの程度一般的またはトレーニング済みであるかが決まります。浅すぎて一般的であってはならず(AdaBoostなど)、深すぎて特殊化されてはならない(ブートストラップ集約など)ツリーが推奨されます。
勾配ブーストは通常、適度な深さの樹木でうまく機能し、トレーニングと一般性のバランスを取ります。ツリーの深さは、max_depth引数によって制御されますツリーの複雑さを管理するためのデフォルトのメカニズムは有限数のノードを使用することであるため、デフォルトは未定義の値です。
ツリーの複雑さを制御するには、主に2つの方法があります。ツリーの最大深度とツリーのターミナルノード(リーフ)の最大数です。ここでは葉の数を調べているので、num_leaves引数を指定して、より深いツリーをサポートするために数を増やす必要があります。以下では、1から10までのツリーの深さと、モデルのパフォーマンスへの影響を調べます。
# explore lightgbm tree depth effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
for i in range(1,11):
models[str(i)] = LGBMClassifier(max_depth=i, num_leaves=2**i)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()最初に例を実行すると、調整された各ツリー深度の平均精度が表示されます。
注:アルゴリズムや推定手順の確率的な性質、または数値の精度の違いにより、結果が異なる場合があります。例を数回実行し、平均結果を比較することを検討してください。
ここでは、ツリーの深さが10レベルまで増えると、パフォーマンスが向上することがわかります。さらに深い木を探索するのは興味深いでしょう。
>1 0.833 (0.028)
>2 0.870 (0.033)
>3 0.899 (0.032)
>4 0.912 (0.026)
>5 0.925 (0.031)
>6 0.924 (0.029)
>7 0.922 (0.027)
>8 0.926 (0.027)
>9 0.925 (0.028)
>10 0.928 (0.029)構成されたツリーの深さごとに精度スコアを分散するために、長方形とウィスカーのプロットが生成されます。モデルのパフォーマンスは、ツリーの深さが最大5レベルになると増加する一般的な傾向があり、その後はパフォーマンスはかなりフラットなままです。
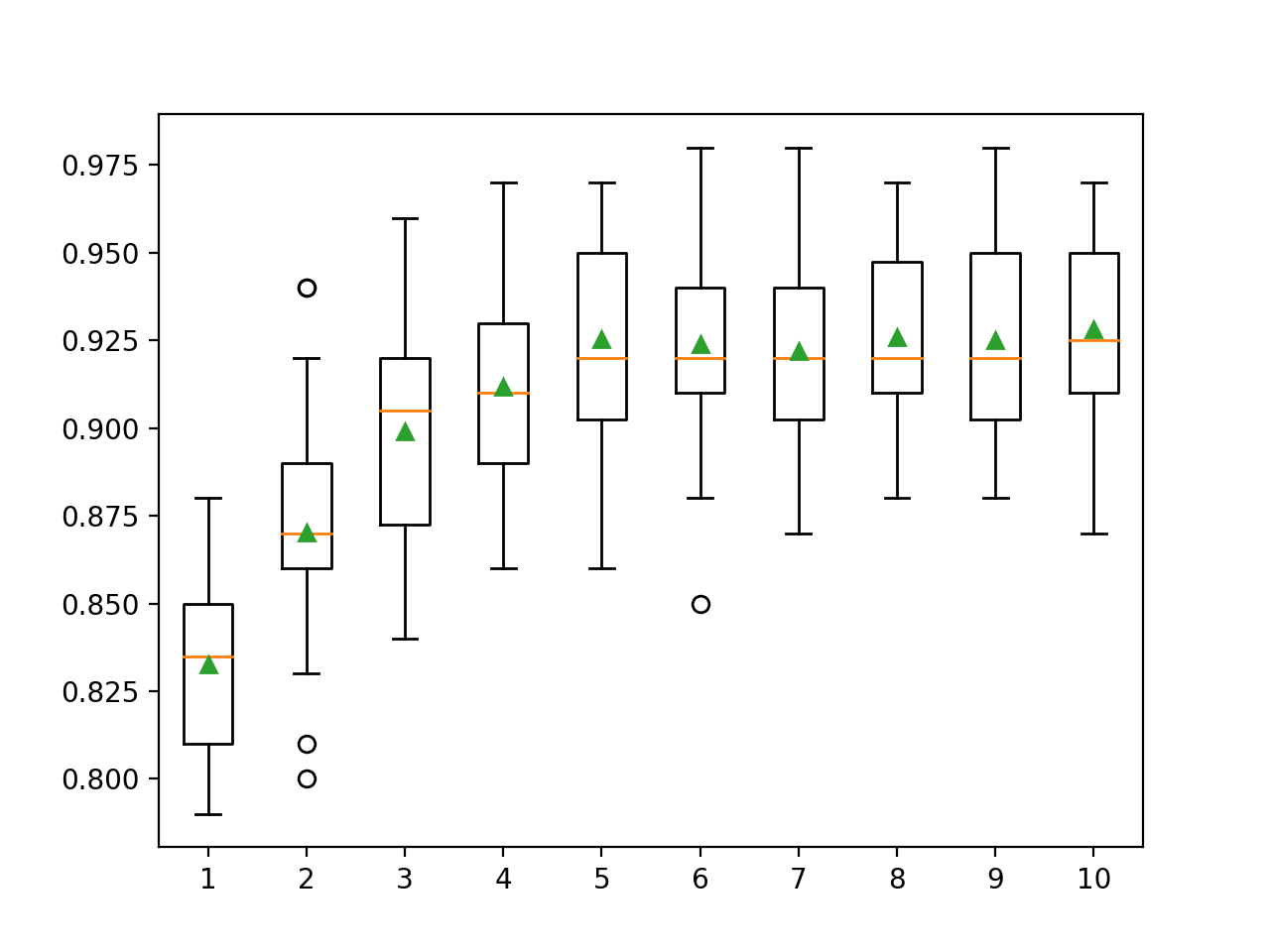
学習率調査
学習率は、各モデルがアンサンブル予測に寄与する度合いを制御します。速度が遅いと、アンサンブルでより多くの決定ツリーが必要になる場合があります。学習率はlearning_rate引数で制御できます。デフォルトでは0.1です。以下は、学習率を調べ、0.0001から1.0までの値の効果を比較します。
# explore lightgbm learning rate effect on performance
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
rates = [0.0001, 0.001, 0.01, 0.1, 1.0]
for r in rates:
key = '%.4f' % r
models[key] = LGBMClassifier(learning_rate=r)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()最初に例を実行すると、構成された各学習率の平均精度が表示されます。
注:アルゴリズムや推定手順の確率的な性質、または数値の精度の違いにより、結果が異なる場合があります。例を数回実行し、平均結果を比較することを検討してください。
ここでは、学習率が高いほど、このデータセットのパフォーマンスが向上することがわかります。アンサンブルにツリーを追加して学習率を下げると、パフォーマンスがさらに向上することが期待されます。
>0.0001 0.800 (0.038)
>0.0010 0.811 (0.035)
>0.0100 0.859 (0.035)
>0.1000 0.925 (0.031)
>1.0000 0.928 (0.025)設定された各学習率の精度スコアを配布するために、口ひげボックスが作成されます。学習率が1.0まで上がると、モデルのパフォーマンスが上がるという一般的な傾向があります。

ブースティングタイプの研究
LightGBMの特徴は、ブーストタイプと呼ばれる多くのブーストアルゴリズムをサポートしていることです。ブースティングタイプは、boosting_type引数を使用して指定され、タイプを決定するために文字列を取ります。可能な値:
- 'gbdt':Gradient Boosted Decision Tree(GDBT);
- 'dart':ドロップアウトの概念がMARTに入力され、DARTが取得されます。
- ' goss ':勾配一方向フェッチ(GOSS)。
デフォルトは、古典的な勾配ブーストアルゴリズムであるGDBTです。
DARTは、「DART:ドロップアウトが複数の加法回帰ツリーに出会う」というタイトルの2015年の記事で説明されており、その名前が示すように、勾配ブースト決定ツリーの前身である複数加法回帰ツリー(MART)アルゴリズムにディープラーニングドロップアウトの概念を追加します。
このアルゴリズムは、Gradient TreeBoost、Boosted Trees、Multiple Additive Regression Trees and Trees(MART)など、多くの名前で知られています。後者の名前を使用してアルゴリズムを参照します。
GOSSには、LightGBMとlightbgmライブラリに関する作業が表示されます。このアプローチは、大きなエラー勾配が発生するインスタンスのみを使用してモデルを更新し、残りのインスタンスを削除することを目的としています。
...勾配が小さいデータインスタンスの大部分を除外し、残りの部分のみを使用して情報の増加を推定します。
以下のLightGBMは、3つの主要なブースト方法を使用した合成分類データセットでトレーニングされています。
# explore lightgbm boosting type effect on performance
from numpy import arange
from numpy import mean
from numpy import std
from sklearn.datasets import make_classification
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import RepeatedStratifiedKFold
from lightgbm import LGBMClassifier
from matplotlib import pyplot
# get the dataset
def get_dataset():
X, y = make_classification(n_samples=1000, n_features=20, n_informative=15, n_redundant=5, random_state=7)
return X, y
# get a list of models to evaluate
def get_models():
models = dict()
types = ['gbdt', 'dart', 'goss']
for t in types:
models[t] = LGBMClassifier(boosting_type=t)
return models
# evaluate a give model using cross-validation
def evaluate_model(model):
cv = RepeatedStratifiedKFold(n_splits=10, n_repeats=3, random_state=1)
scores = cross_val_score(model, X, y, scoring='accuracy', cv=cv, n_jobs=-1)
return scores
# define dataset
X, y = get_dataset()
# get the models to evaluate
models = get_models()
# evaluate the models and store results
results, names = list(), list()
for name, model in models.items():
scores = evaluate_model(model)
results.append(scores)
names.append(name)
print('>%s %.3f (%.3f)' % (name, mean(scores), std(scores)))
# plot model performance for comparison
pyplot.boxplot(results, labels=names, showmeans=True)
pyplot.show()最初に例を実行すると、構成された各ブーストタイプの平均精度が表示されます。
注:アルゴリズムや推定手順の確率的な性質、または数値の精度の違いにより、結果が異なる場合があります。例を複数回実行し、平均を比較することを検討してください。
デフォルトのブースト方法は、他の2つの評価された方法よりもパフォーマンスが優れていることがわかります。
>gbdt 0.925 (0.031)
>dart 0.912 (0.028)
>goss 0.918 (0.027)ボックスアンドウィスカー図を作成して、構成された各増幅方法の精度推定値を配布し、方法を直接比較できるようにします。
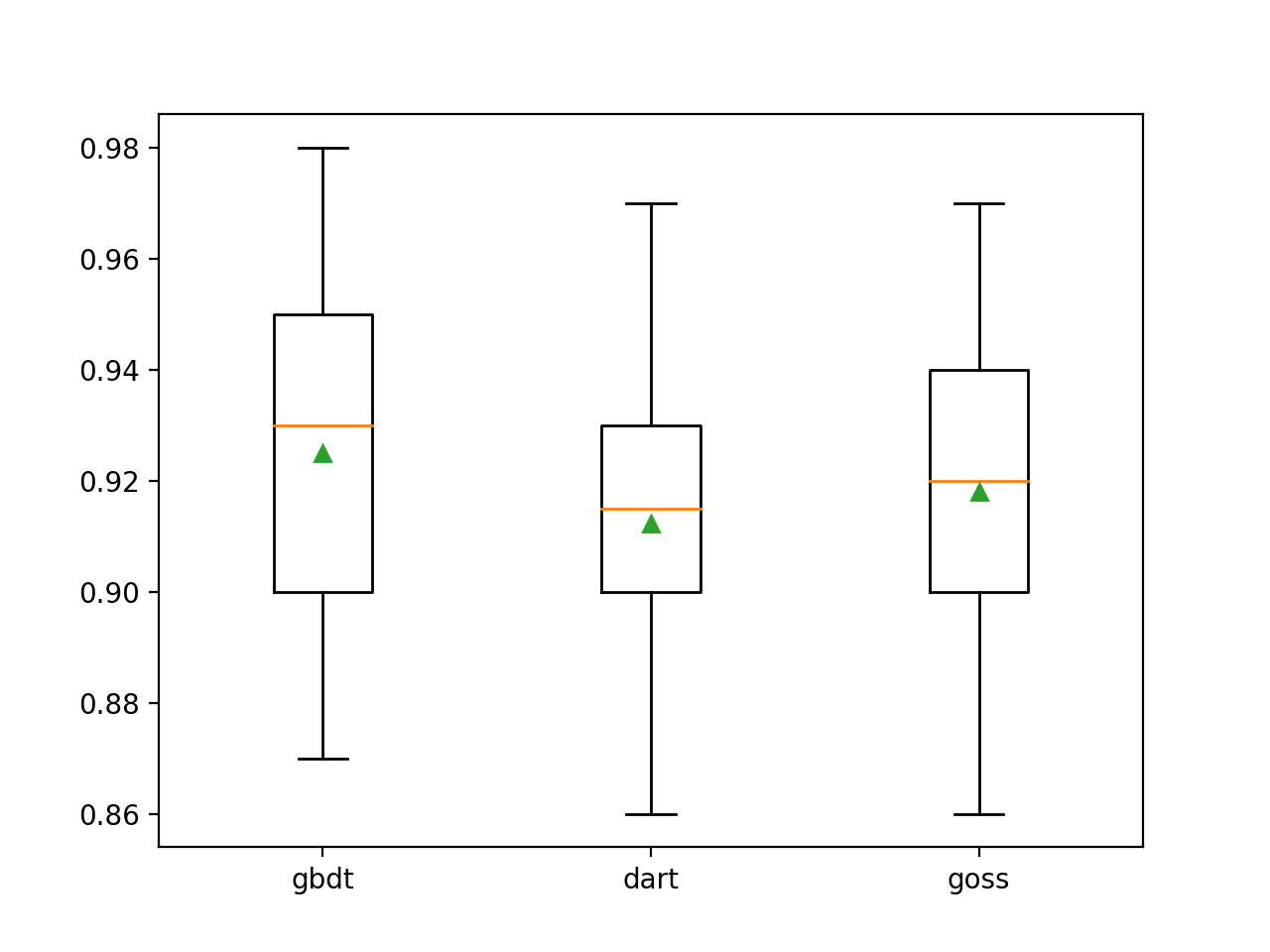

その他のコース