長い間記事を書いていませんでしたが、YandexとMIPTの有名な専門分野である「機械学習とデータ分析」のトレーニング中に得られたデータサイエンスの知識がどのように役立ったかについて書く時が来たと思います。確かに、公平を期すために、知識が完全に得られていないことに注意する必要があります-専門分野は完了していません:)しかし、単純な実際のビジネス上の問題を解決することはすでに可能です。それとも必要ですか?この質問は、ほんの数段落で答えられます。
それで、今日この記事で私はオープンコンペティションに参加した私の最初の経験について親愛なる読者に話します。コンテストの私の目標は賞品を獲得することではなかったことをすぐに指摘したいと思います。唯一の望みは、現実の世界で私の手を試すことでした:)はい、それに加えて、競争のトピックが、通過したコースの資料と実質的に交差しなかったことが起こりました。これはいくつかの複雑さを追加しましたが、それによって競争はさらに面白くなり、そこから得られた経験は貴重になりました。
伝統的に、私は誰がその記事に興味を持っているのかを指定します。まず、上記の専門分野の最初の2つのコースをすでに完了していて、実際の問題に挑戦したいが、うまくいかない可能性があり、笑われるなど、恥ずかしがり屋で心配している場合。記事を読んだ後、そのような恐れは払拭されることを願っています。第二に、おそらくあなたは同様の問題を解決していて、どこに入るのか全くわからないでしょう。そして、実際のデータインターンが言うように、これは既製の気取らないベースラインです:)
ここで研究計画の概要を説明することは価値がありますが、少し逸脱して、最初の段落からの質問に答えようとします-データシンティングの初心者がそのような大会で彼の手を試す必要があるかどうか。このスコアについては意見が異なります。個人的には私の意見が必要です!その理由を説明させてください。多くの理由があります、私はすべてをリストするわけではありません、私は最も重要なものを示します。第一に、そのような競争は実際の理論的知識を統合するのに役立ちます。第二に、私の実践では、ほとんどの場合、戦闘に近い状況で得られた経験は、さらなる偉業への非常に強い動機付けとなります。第三に、これは最も重要なことです-競争中にあなたは特別なチャットで他の参加者とコミュニケーションする機会があります、あなたはコミュニケーションする必要さえありません、あなたは人々が書いたものを読むことができますそしてこれはしばしば興味深い考えにつながります調査で他にどのような変更を加えるか。b)特にチャットで表現されている場合は、自分のアイデアを検証する自信があります。これらの利点は、全能性の感覚がないように、一定の慎重さをもって取り組む必要があります...
さて、私がどのように参加することに決めたかについて少し説明します。大会が始まるほんの数日前にそのことを知りました。最初の考えは、「まあ、1か月前に競争について知っていれば、自分で準備しただろうが、研究を行うのに役立つ可能性のあるいくつかの追加資料を研究しただろう。そうでなければ、準備なしでは期限に間に合わない...」、2番目の考えは「実際には、目標が賞品でなければうまくいかないかもしれませんが、参加は、特に95%のケースの参加者がロシア語を話すため、さらにディスカッションのための特別なチャットがあるため、主催者からの何らかのウェビナーがあります。最終的には、すべてのストライプとサイズのライブデータサイエンティストを見ることができるようになります... "。ご想像のとおり、2番目の考えが勝ちましたが、無駄ではありませんでした。ほんの数日間のハードワークで、単純なものではありますが、貴重な経験を得ることができました。しかし、かなりのビジネスタスクです。したがって、データサイエンスの高みを征服し、次の競争を見る場合は、母国語で、チャットのサポートがあり、自由な時間があります-長い間躊躇しないでください-試してみてください。力があなたと一緒に来るかもしれません!ポジティブなことに、私たちはタスクと研究計画に移ります。
一致する名前
私たちは自分自身を苦しめたり、問題の説明を思いついたりはしませんが、コンテスト主催者のウェブサイトから原文を提供します。
仕事
新しいクライアントを探すとき、SIBURはさまざまなソースからの何百万もの新しい会社に関する情報を処理する必要があります。同時に、会社の名前は、スペルが異なっていたり、略語や誤りが含まれていたり、SIBURにすでに知られている会社と提携している場合があります。
潜在的な顧客に関する情報をより効率的に処理するために、SIBURは、2つの名前が関連しているかどうか(つまり、同じ会社または関連会社に属しているかどうか)を知る必要があります。
この場合、SIBURは、会社自体または関連会社に関する既知の情報を使用でき、会社への重複した呼び出しや、無関係な会社または競合他社の子会社に時間を浪費することはありません。
トレーニングサンプルには、さまざまなソース(カスタムのものを含む)からの名前のペアとマークアップが含まれています。
マークアップは、一部は手作業で、一部はアルゴリズムによって取得されました。さらに、マークアップにエラーが含まれている可能性があります。2つの名前が関連しているかどうかを予測するバイナリモデルを構築します。このタスクで使用されるメトリックはF1です。
このタスクでは、オープンデータソースを使用してデータセットを充実させたり、関連会社を特定するために重要な追加情報を見つけたりすることが可能であり、必要ですらあります。
タスクに関する追加情報
詳細については私を明らかにしてください
, . , : , , Sibur Digital, , Sibur international GMBH , “ International GMBH” .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source , . — . .
, - – . , , - , , , .
: , .
, , , .
(50%) (50%) .
. , , .
1 1 000 000 .
( ). , .
24:00 6 2020 # .
, , , .
, , - , .
.
, , .
10 .
API , , 2.
, , , .. crowdsource
“” crowdsource . , :)
, .
legel entities, , .. , Industries .
. .
, . , “” .
, , , . , , .
, , .
open source
open source , . — . .
, - – . , , - , , , .
データ
train.csv-トレーニングセット
test.csv-テストセット
sample_submission.csv-正しい形式のソリューションの例
ネーミングbaseline.ipynb-コード
baseline_submission.csv-基本的なソリューション
コンテストの主催者が若い世代の面倒を見て、問題の基本的な解決策を投稿したことに注意してください。これにより、f1の品質は約0.1になります。コンテストに参加するのはこれが初めてで、これを見るのは初めてです:)
それで、問題自体とその解決策の要件に精通したので、解決策の計画に移りましょう。
問題解決計画
技術機器のセットアップ
ライブラリをロードし
ましょう補助関数を書いてみましょう
データの前処理
… -. !
50 & Drop it smart.
レベンシュテイン距離を
計算しましょう正規化されたレベンシュテイン距離を計算し
ます特徴を視覚化します
各ペアのテキスト内の単語を比較し、多数の特徴を生成
しますテキストからの単語を石油化学および建設業界の上位50の保有ブランドの名前からの単語と比較します。機能の2番目の大きな山を取得しましょう。2番目のCHIT
モデルにフィードするためのデータの準備
モデルの設定とトレーニング
大会結果
情報源
研究計画に慣れてきたので、その実施に移りましょう。
技術機器のセットアップ
ライブラリの読み込み
実際、ここではすべてが単純です。まず、不足しているライブラリをインストールします
ライブラリをインストールして国のリストを確認し、テキストから削除します
pip install pycountry
テキストからの単語間のレベンシュテイン距離を決定するためのライブラリをインストールします。
pip install strsimpy
ライブラリをインストールし、その助けを借りてロシア語のテキストをラテン語に翻訳します
pip install cyrtranslit
ライブラリをプルアップ
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import pycountry
import re
from tqdm import tqdm
tqdm.pandas()
from strsimpy.levenshtein import Levenshtein
from strsimpy.normalized_levenshtein import NormalizedLevenshtein
import matplotlib.pyplot as plt
from matplotlib.pyplot import figure
import seaborn as sns
sns.set()
sns.set_style("whitegrid")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import StratifiedShuffleSplit
from scipy.sparse import csr_matrix
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
from sklearn.metrics import recall_score
from sklearn.metrics import precision_score
from sklearn.metrics import roc_auc_score
from sklearn.metrics import classification_report, f1_score
# import googletrans
# from googletrans import Translator
import cyrtranslit補助関数を書いてみましょう
大きなコードをコピーするのではなく、1行で関数を指定することをお勧めします。ほとんどの場合、そうします。
関数内のコードの品質が優れているとは言いません。確実に最適化する必要がある場所もありますが、迅速な調査を行うには、計算の精度だけで十分です。
したがって、最初の関数はテキストを小文字に変換します
コード
# convert text to lowercase
def lower_str(data,column):
data[column] = data[column].str.lower()次の4つの関数は、調査中のフィーチャのスペースと、ターゲットラベル(0または1)でオブジェクトを分離する機能を視覚化するのに役立ちます。
コード
# statistic table for analyse float values (it needs to make histogramms and boxplots)
def data_statistics(data,analyse,title_print):
data0 = data[data['target']==0][analyse]
data1 = data[data['target']==1][analyse]
data_describe = pd.DataFrame()
data_describe['target_0'] = data0.describe()
data_describe['target_1'] = data1.describe()
data_describe = data_describe.T
if title_print == 'yes':
print ('\033[1m' + ' ',analyse,'\033[m')
elif title_print == 'no':
None
return data_describe
# histogramms for float values
def hist_fz(data,data_describe,analyse,size):
print ()
print ('\033[1m' + 'Information about',analyse,'\033[m')
print ()
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
min_data = data_describe['min'].min()
max_data = data_describe['max'].max()
data0_mean = data_describe.loc['target_0']['mean']
data0_median = data_describe.loc['target_0']['50%']
data0_min = data_describe.loc['target_0']['min']
data0_max = data_describe.loc['target_0']['max']
data0_count = data_describe.loc['target_0']['count']
data1_mean = data_describe.loc['target_1']['mean']
data1_median = data_describe.loc['target_1']['50%']
data1_min = data_describe.loc['target_1']['min']
data1_max = data_describe.loc['target_1']['max']
data1_count = data_describe.loc['target_1']['count']
print ('\033[4m' + 'Analyse'+ '\033[m','No duplicates')
figure(figsize=size)
sns.distplot(data_0,color='darkgreen',kde = False)
plt.scatter(data0_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data0_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data0_count,
' Min:', round(data0_min,2),
' Max:', round(data0_max,2),
' Mean:', round(data0_mean,2),
' Median:', round(data0_median,2))
print ()
print ('\033[4m' + 'Analyse'+ '\033[m','Duplicates')
figure(figsize=size)
sns.distplot(data_1,color='darkred',kde = False)
plt.scatter(data1_mean,0,s=200,marker='o',c='dimgray',label='Mean')
plt.scatter(data1_median,0,s=250,marker='|',c='black',label='Median')
plt.legend(scatterpoints=1,
loc='upper right',
ncol=3,
fontsize=16)
plt.xlim(min_data, max_data)
plt.show()
print ('Quantity:', data_1.count(),
' Min:', round(data1_min,2),
' Max:', round(data1_max,2),
' Mean:', round(data1_mean,2),
' Median:', round(data1_median,2))
# draw boxplot
def boxplot(data,analyse,size):
print ('\033[4m' + 'Analyse'+ '\033[m','All pairs')
data_0 = data[data['target'] == 0][analyse]
data_1 = data[data['target'] == 1][analyse]
figure(figsize=size)
sns.boxplot(x=analyse,y='target',data=data,orient='h',
showmeans=True,
meanprops={"marker":"o",
"markerfacecolor":"dimgray",
"markeredgecolor":"black",
"markersize":"14"},
palette=['palegreen', 'salmon'])
plt.ylabel('target', size=14)
plt.xlabel(analyse, size=14)
plt.show()
# draw graph for analyse two choosing features for predict traget label
def two_features(data,analyse1,analyse2,size):
fig = plt.subplots(figsize=size)
x0 = data[data['target']==0][analyse1]
y0 = data[data['target']==0][analyse2]
x1 = data[data['target']==1][analyse1]
y1 = data[data['target']==1][analyse2]
plt.scatter(x0,y0,c='green',marker='.')
plt.scatter(x1,y1,c='black',marker='+')
plt.xlabel(analyse1)
plt.ylabel(analyse2)
title = [analyse1,analyse2]
plt.title(title)
plt.show()5番目の関数は、共役テーブルとしてよく知られている、アルゴリズムの推測とエラーのテーブルを生成するように設計されています。
言い換えれば、予測のベクトルの形成後、予測をターゲットラベルと比較する必要があります。このような比較の結果は、トレーニングサンプルからの企業の各ペアの共役表になるはずです。各ペアの共役表で、トレーニングサンプルからのクラスに予測を一致させた結果が決定されます。一致する分類は、「真陽性」、「偽陽性」、「真陰性」、または「偽陰性」として受け入れられます。これらのデータは、アルゴリズムの動作を分析し、モデルと機能空間の改善を決定するために非常に重要です。
コード
def contingency_table(X,features,probability_level,tridx,cvidx,model):
tr_predict_proba = model.predict_proba(X.iloc[tridx][features].values)
cv_predict_proba = model.predict_proba(X.iloc[cvidx][features].values)
tr_predict_target = (tr_predict_proba[:, 1] > probability_level).astype(np.int)
cv_predict_target = (cv_predict_proba[:, 1] > probability_level).astype(np.int)
X_tr = X.iloc[tridx]
X_cv = X.iloc[cvidx]
X_tr['predict_proba'] = tr_predict_proba[:,1]
X_cv['predict_proba'] = cv_predict_proba[:,1]
X_tr['predict_target'] = tr_predict_target
X_cv['predict_target'] = cv_predict_target
# make true positive column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==1]['pair_id'])
data['True_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false positive column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==1]['pair_id'])
data['False_Positive'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make true negative column
data = pd.DataFrame(X_tr[X_tr['target']==0][X_tr['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==0][X_cv['predict_target']==0]['pair_id'])
data['True_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
# make false negative column
data = pd.DataFrame(X_tr[X_tr['target']==1][X_tr['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_tr = X_tr.merge(data,on='pair_id',how='left')
data = pd.DataFrame(X_cv[X_cv['target']==1][X_cv['predict_target']==0]['pair_id'])
data['False_Negative'] = 1
X_cv = X_cv.merge(data,on='pair_id',how='left')
return X_tr,X_cv6番目の関数は、共役行列を形成するために使用されます。カップリングテーブルと混同しないでください。一方が他方から続くが。あなた自身がさらにすべてを見るでしょう
コード
def matrix_confusion(X):
list_matrix = ['True_Positive','False_Positive','True_Negative','False_Negative']
tr_pos = X[list_matrix].sum().loc['True_Positive']
f_pos = X[list_matrix].sum().loc['False_Positive']
tr_neg = X[list_matrix].sum().loc['True_Negative']
f_neg = X[list_matrix].sum().loc['False_Negative']
matrix_confusion = pd.DataFrame()
matrix_confusion['0_algorythm'] = np.array([tr_neg,f_neg]).T
matrix_confusion['1_algorythm'] = np.array([f_pos,tr_pos]).T
matrix_confusion = matrix_confusion.rename(index={0: '0_target', 1: '1_target'})
return matrix_confusion7番目の関数は、アルゴリズムの操作に関するレポートを視覚化するように設計されています。これには、共役行列、メトリックの精度の値、リコール、f1が含まれます。
コード
def report_score(tr_matrix_confusion,
cv_matrix_confusion,
data,tridx,cvidx,
X_tr,X_cv):
# print some imporatant information
print ('\033[1m'+'Matrix confusion on train data'+'\033[m')
display(tr_matrix_confusion)
print ()
print(classification_report(data.iloc[tridx]["target"].values, X_tr['predict_target']))
print ('******************************************************')
print ()
print ()
print ('\033[1m'+'Matrix confusion on test(cv) data'+'\033[m')
display(cv_matrix_confusion)
print ()
print(classification_report(data.iloc[cvidx]["target"].values, X_cv['predict_target']))
print ('******************************************************')8番目と9番目の関数を使用して、調査対象の各機能の係数「情報ゲイン」の値の観点から、LightGBMの使用モデルの機能の有用性を分析します。
コード
def table_gain_coef(model,features,start,stop):
data_gain = pd.DataFrame()
data_gain['Features'] = features
data_gain['Gain'] = model.booster_.feature_importance(importance_type='gain')
return data_gain.sort_values('Gain', ascending=False)[start:stop]
def gain_hist(df,size,start,stop):
fig, ax = plt.subplots(figsize=(size))
x = (df.sort_values('Gain', ascending=False)['Features'][start:stop])
y = (df.sort_values('Gain', ascending=False)['Gain'][start:stop])
plt.bar(x,y)
plt.xlabel('Features')
plt.ylabel('Gain')
plt.xticks(rotation=90)
plt.show()10番目の関数は、企業の各ペアの一致する単語の数の配列を形成するために必要です。
この関数を使用して、一致しない単語の配列を形成することもできます。
コード
def compair_metrics(data):
duplicate_count = []
duplicate_sum = []
for i in range(len(data)):
count=len(data[i])
duplicate_count.append(count)
if count <= 0:
duplicate_sum.append(0)
elif count > 0:
temp_sum = 0
for j in range(len(data[i])):
temp_sum +=len(data[i][j])
duplicate_sum.append(temp_sum)
return duplicate_count,duplicate_sum 11番目の関数は、ロシア語のテキストをラテン語のアルファベットに変換します
コード
def transliterate(data):
text_transliterate = []
for i in range(data.shape[0]):
temp_list = list(data[i:i+1])
temp_str = ''.join(temp_list)
result = cyrtranslit.to_latin(temp_str,'ru')
text_transliterate.append(result)
.
, , , . , ,
<spoiler title="">
<source lang="python">def rename_agg_columns(id_client,data,rename):
columns = [id_client]
for lev_0 in data.columns.levels[0]:
if lev_0 != id_client:
for lev_1 in data.columns.levels[1][:-1]:
columns.append(rename % (lev_0, lev_1))
data.columns = columns
return datareturn text_transliterate
13番目と14番目の関数は、Levenshtein距離テーブルとその他の重要なインジケーターを表示および生成するために必要です。
これは一般的にどのような種類のテーブルであり、その中のメトリックは何であり、どのように形成されますか?テーブルがどのように形成されるかを段階的に見てみましょう。
- ステップ1.必要なデータを定義しましょう。ペアID、テキスト仕上げ-両方の列、保持名リスト(石油化学および建設会社のトップ50)。
- ステップ2.列1で、各単語の各ペアで、保持名のリストから各単語までのレベンシュテイン距離、各単語の長さ、および長さに対する距離の比率を測定します。
- 3. , 0.4, id , .
- 4. , 0.4, .
- 5. , ID , — . id ( id ). .
- ステップ6.結果のテーブルをリサーチテーブルに接着します。
重要な機能:
急いで書かれたコードのため、計算に時間がかかる
コード
def dist_name_to_top_list_view(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
words1 = []
words2 = []
top_words = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist1
df['levenstein_dist_w2_top_w'] = dist2
df['length_w1_top_w'] = len(word1)
df['length_w2_top_w'] = len(word2)
df['length_top_w'] = len(top_word)
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
display(data)
print ('Words:', word1,word2,top_word)
print ('Levenstein distance:',dist1,dist2)
print ('Length of word:',len(word1),len(word2),len(top_word))
print ('Ratio (distance/length word):',ratio1,ratio2)
def dist_name_to_top_list_make(data,column1,column2,list_top_companies):
id_pair = []
r1 = []
r2 = []
dist_w1 = []
dist_w2 = []
length_w1 = []
length_w2 = []
length_top_w = []
for n in range(0, data.shape[0], 1):
for line1 in data[column1][n:n+1]:
line1 = line1.split()
for word1 in line1:
if len(word1) >=3:
for top_word in list_top_companies:
dist1 = levenshtein.distance(word1, top_word)
ratio = max(dist1/float(len(top_word)),dist1/float(len(word1)))
if ratio <= 0.4:
ratio1 = ratio
break
if ratio <= 0.4:
for line2 in data[column2][n:n+1]:
line2 = line2.split()
for word2 in line2:
dist2 = levenshtein.distance(word2, top_word)
ratio = max(dist2/float(len(top_word)),dist2/float(len(word2)))
if ratio <= 0.4:
ratio2 = ratio
id_pair.append(int(data['pair_id'][n:n+1].values))
r1.append(ratio1)
r2.append(ratio2)
dist_w1.append(dist1)
dist_w2.append(dist2)
length_w1.append(float(len(word1)))
length_w2.append(float(len(word2)))
length_top_w.append(float(len(top_word)))
break
df = pd.DataFrame()
df['pair_id'] = id_pair
df['levenstein_dist_w1_top_w'] = dist_w1
df['levenstein_dist_w2_top_w'] = dist_w2
df['length_w1_top_w'] = length_w1
df['length_w2_top_w'] = length_w2
df['length_top_w'] = length_top_w
df['ratio_dist_w1_to_top_w'] = r1
df['ratio_dist_w2_to_top_w'] = r2
feature = df.groupby(['pair_id']).agg([min]).reset_index()
feature = rename_agg_columns(id_client='pair_id',data=feature,rename='%s_%s')
data = data.merge(feature,on='pair_id',how='left')
return dataデータの前処理
私の小さな経験から、この表現の広い意味でのデータの前処理がより時間がかかります。順番に行きましょう。
データを読み込む
ここではすべてが非常に簡単です。データをロードし、列の名前をターゲットラベル「is_duplicate」に置き換えて「target」に置き換えましょう。これは、関数を使いやすくするためです。一部の関数は以前の調査の一部として作成されており、ターゲットラベルが「ターゲット」である列の名前を使用しています。
コード
# DOWNLOAD DATA
text_train = pd.read_csv('train.csv')
text_test = pd.read_csv('test.csv')
# RENAME DATA
text_train = text_train.rename(columns={"is_duplicate": "target"})データを見てみましょう
データがロードされました。合計でいくつのオブジェクトがあり、それらがどの程度バランスが取れているかを見てみましょう。
コード
# ANALYSE BALANCE OF DATA
target_1 = text_train[text_train['target']==1]['target'].count()
target_0 = text_train[text_train['target']==0]['target'].count()
print ('There are', text_train.shape[0], 'objects')
print ('There are', target_1, 'objects with target 1')
print ('There are', target_0, 'objects with target 0')
print ('Balance is', round(100*target_1/target_0,2),'%')表№1「マークのバランス」

オブジェクトはたくさんあり、50万近くあり、バランスがまったく取れていません。つまり、約50万個のオブジェクトのうち、合計で4,000個未満のターゲットラベルが1(1%未満)に
なっています。テーブル自体を見てみましょう。0というラベルの付いた最初の5つのオブジェクトと1というラベルの付いた最初の5つのオブジェクトを見てみましょう。
コード
display(text_train[text_train['target']==0].head(5))
display(text_train[text_train['target']==1].head(5))表2「クラス0の最初の5つのオブジェクト」、表3「クラス1の最初の5つのオブジェクト」
いくつかの簡単な手順ですぐにわかります。テキストを1つのレジスタに移動し、「ltd」などのストップワードを削除し、国を削除し、同時に地理的な名前を削除します。オブジェクト。
実際、このタスクではこのような問題を解決できます。前処理を行い、正常に機能することを確認し、モデルを実行し、品質を確認して、モデルが間違っているオブジェクトを選択的に分析します。これが私の研究のやり方です。しかし、記事自体では、最終的な解決策が示され、各前処理後のアルゴリズムの品質が理解されていないため、記事の最後に最終的な分析を行います。そうでなければ、記事は何とも言えないサイズになります:)
コピーを作ろう
正直なところ、なぜそうするのかわかりませんが、なぜかいつもそうしています。今回もやります
コード
baseline_train = text_train.copy()
baseline_test = text_test.copy()すべての文字をテキストから小文字に変換する
コード
# convert text to lowercase
columns = ['name_1','name_2']
for column in columns:
lower_str(baseline_train,column)
for column in columns:
lower_str(baseline_test,column)国名を削除する
コンテストの主催者は素晴らしい仲間であることに注意してください!割り当てとともに、彼らは非常に単純なベースラインを備えたラップトップを提供しました。そのベースラインには、以下のコードが含まれています。
コード
# drop any names of countries
countries = [country.name.lower() for country in pycountry.countries]
for country in tqdm(countries):
baseline_train.replace(re.compile(country), "", inplace=True)
baseline_test.replace(re.compile(country), "", inplace=True)標識や特殊文字を削除する
コード
# drop punctuation marks
baseline_train.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_test.replace(re.compile(r"\s+\(.*\)"), "", inplace=True)
baseline_train.replace(re.compile(r"[^\w\s]"), "", inplace=True)
baseline_test.replace(re.compile(r"[^\w\s]"), "", inplace=True)番号を削除する
最初の試みで、額のテキストから直接数字を削除すると、モデルの品質が大幅に低下しました。ここにコードを示しますが、実際には使用されていません。
また、これまで、与えられた列に対して直接変換を実行してきたことにも注意してください。前処理ごとに新しい列を作成してみましょう。より多くの列がありますが、前処理のある段階で障害が発生した場合は、前処理の各段階の列があるため、最初からすべてを行う必要はありません。
品質を損なうコード。あなたはもっと繊細である必要があります
# # first: make dictionary of frequency every word
# list_words = baseline_train['name_1'].to_string(index=False).split() +\
# baseline_train['name_2'].to_string(index=False).split()
# freq_words = {}
# for w in list_words:
# freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame of frequency words
# df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
# df_freq.columns = ['word','frequency']
# df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
# df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
# df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
# # third: make drop list of digits
# string = df_freq_agg['word'].to_string(index=False)
# digits = [int(digit) for digit in string.split() if digit.isdigit()]
# digits = set(digits)
# digits = list(digits)
# # drop the digits
# baseline_train['name_1_no_digits'] =\
# baseline_train['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_train['name_2_no_digits'] =\
# baseline_train['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_1_no_digits'] =\
# baseline_test['name_1'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
# baseline_test['name_2_no_digits'] =\
# baseline_test['name_2'].apply(
# lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))最初のストップワードリストを削除しましょう。手動で!
ここで、会社名の単語リストからストップワードを定義して削除することをお勧めします。
トレーニングサンプルの手動レビューに基づいてリストを作成しました。論理的には、このようなリストは、次のアプローチを使用して自動的にコンパイルする必要があります。
- まず、上位10(20,50,100)の一般的な単語を使用します。
- 次に、さまざまな言語で標準のストップワードライブラリを使用します。たとえば、さまざまな言語(LLC、PJSC、CJSC、ltd、gmbh、incなど)での組織の組織的および法的形態の指定
- 第三に、異なる言語で地名のリストを編集することは理にかなっています
頻繁に発生する上位の単語のリストを自動的にコンパイルする最初のオプションに戻りますが、今のところは手動の前処理を検討しています。
コード
# drop some stop-words
drop_list = ["ltd.", "co.", "inc.", "b.v.", "s.c.r.l.", "gmbh", "pvt.",
'retail','usa','asia','ceska republika','limited','tradig','llc','group',
'international','plc','retail','tire','mills','chemical','korea','brasil',
'holding','vietnam','tyre','venezuela','polska','americas','industrial','taiwan',
'europe','america','north','czech republic','retailers','retails',
'mexicana','corporation','corp','ltd','co','toronto','nederland','shanghai','gmb','pacific',
'industries','industrias',
'inc', 'ltda', '', '', '', '', '', '', '', '', 'ceska republika', 'ltda',
'sibur', 'enterprises', 'electronics', 'products', 'distribution', 'logistics', 'development',
'technologies', 'pvt', 'technologies', 'comercio', 'industria', 'trading', 'internacionais',
'bank', 'sports',
'express','east', 'west', 'south', 'north', 'factory', 'transportes', 'trade', 'banco',
'management', 'engineering', 'investments', 'enterprise', 'city', 'national', 'express', 'tech',
'auto', 'transporte', 'technology', 'and', 'central', 'american',
'logistica','global','exportacao', 'ceska republika', 'vancouver', 'deutschland',
'sro','rus','chemicals','private','distributors','tyres','industry','services','italia','beijing',
'','company','the','und']
baseline_train['name_1_non_stop_words'] =\
baseline_train['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_non_stop_words'] =\
baseline_train['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_non_stop_words'] =\
baseline_test['name_1'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_non_stop_words'] =\
baseline_test['name_2'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))ストップワードが実際にテキストから削除されていることを選択的に確認しましょう。
コード
baseline_train[baseline_train.name_1_non_stop_words.str.contains("factory")].head(3)表4「ストップワードを削除するためのコードの選択的チェック」

すべてが機能しているようです。スペースで区切られているすべてのストップワードを削除しました。私たちが欲しかったもの。先に進みます。
ロシア語のテキストをラテン語のアルファベットに変換しましょう
これには、自分で作成した関数とcyrtranslitライブラリを使用します。うまくいくようです。手動で確認。
コード
# transliteration to latin
baseline_train['name_1_transliterated'] = transliterate(baseline_train['name_1_non_stop_words'])
baseline_train['name_2_transliterated'] = transliterate(baseline_train['name_2_non_stop_words'])
baseline_test['name_1_transliterated'] = transliterate(baseline_test['name_1_non_stop_words'])
baseline_test['name_2_transliterated'] = transliterate(baseline_test['name_2_non_stop_words'])ID 353150のペアを見てみましょう。その中で、2番目の列( "name_2")には "Michelin"という単語があります。前処理後、単語はすでにこの "mishlen"のように書き込まれています(列 "name_2_transliterated"を参照)。完全に正しいわけではありませんが、明らかに優れています。
コード
pair_id = 353150
baseline_train[baseline_train['pair_id']==353150]表番号5「文字変換のためのコードの選択的検証」

最も頻繁に発生する上位50の単語のリストの自動コンパイルを開始し、スマートにドロップしましょう。最初のCHIT
少しトリッキーなタイトル。ここで何をするのか見てみましょう。
まず、1列目と2列目のテキストを1つの配列に結合し、一意の単語ごとに出現回数をカウントします。
次に、これらの単語の上位50を選びましょう。そして、それらを削除できるように見えますが、できません。これらの単語には、保有物の名前( 'total'、 'knauf'、 'shell'、...)が含まれている場合がありますが、これは非常に重要な情報であり、さらに使用するため、失われることはありません。したがって、私たちは不正行為(禁止)のトリックに行きます。まず、トレーニングサンプルの慎重かつ選択的な調査に基づいて、頻繁に遭遇する保有物の名前のリストを作成します。リストは完全ではありません、さもなければそれはまったく公平ではありません:)しかし、私たちは賞を追いかけていないので、なぜそうではありません。次に、頻繁に発生する上位50の単語の配列を保持名のリストと比較し、保持の名前に一致する単語をリストから削除します。
これで、2番目のストップワードリストが完成しました。テキストから単語を削除できます。
しかしその前に、保持名の不正リストについて少しコメントを挿入したいと思います。観察に基づいて保有物の名前のリストをまとめたという事実は、私たちの生活をはるかに楽にしてくれました。しかし実際には、そのようなリストを別の方法で編集することもできます。たとえば、石油化学、建設、自動車、その他の業界の最大の企業の評価を取得し、それらを組み合わせて、そこから保有物の名前を取得することができます。しかし、私たちの研究の目的のために、私たちは単純なアプローチに自分自身を制限します。このアプローチは、コンテスト内では禁止されています。さらに、大会の主催者、入賞場所の候補者の作品に禁止されているテクニックがないかチェックされます。注意してください!
コード
list_top_companies = ['arlanxeo', 'basf', 'bayer', 'bdp', 'bosch', 'brenntag', 'contitech',
'daewoo', 'dow', 'dupont', 'evonik', 'exxon', 'exxonmobil', 'freudenberg',
'goodyear', 'goter', 'henkel', 'hp', 'hyundai', 'isover', 'itochu', 'kia', 'knauf',
'kraton', 'kumho', 'lusocopla', 'michelin', 'paul bauder', 'pirelli', 'ravago',
'rehau', 'reliance', 'sabic', 'sanyo', 'shell', 'sherwinwilliams', 'sojitz',
'soprema', 'steico', 'strabag', 'sumitomo', 'synthomer', 'synthos',
'total', 'trelleborg', 'trinseo', 'yokohama']
# drop top 50 common words (NAME 1 & NAME 2) exept names of top companies
# first: make dictionary of frequency every word
list_words = baseline_train['name_1_transliterated'].to_string(index=False).split() +\
baseline_train['name_2_transliterated'].to_string(index=False).split()
freq_words = {}
for w in list_words:
freq_words[w] = freq_words.get(w, 0) + 1
# # second: make data frame
df_freq = pd.DataFrame.from_dict(freq_words,orient='index').reset_index()
df_freq.columns = ['word','frequency']
df_freq_agg = df_freq.groupby(['word']).agg([sum]).reset_index()
df_freq_agg = rename_agg_columns(id_client='word',data=df_freq_agg,rename='%s_%s')
df_freq_agg = df_freq_agg.sort_values(by=['frequency_sum'], ascending=False)
drop_list = list(set(df_freq_agg[0:50]['word'].to_string(index=False).split()) - set(list_top_companies))
# # check list of top 50 common words
# print (drop_list)
# drop the top 50 words
baseline_train['name_1_finish'] =\
baseline_train['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_train['name_2_finish'] =\
baseline_train['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_1_finish'] =\
baseline_test['name_1_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
baseline_test['name_2_finish'] =\
baseline_test['name_2_transliterated'].apply(
lambda x: ' '.join([word for word in x.split() if word not in (drop_list)]))
ここで、データの前処理が完了します。新しい機能の生成を開始し、オブジェクトを0または1で区切る機能について視覚的に評価してみましょう。
特徴の生成と分析
レベンシュテイン距離を計算してみましょう
strsimpyライブラリを使用して、各ペアで(すべての前処理の後)、最初の列の会社名から2番目の列の会社名までのLevenshtein距離を計算します。
コード
# create feature with LEVENSTAIN DISTANCE
levenshtein = Levenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["levenstein"] = baseline_train.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)
baseline_test["levenstein"] = baseline_test.progress_apply(
lambda r: levenshtein.distance(r[column_1], r[column_2]), axis=1)正規化されたレベンシュテイン距離を計算してみましょう
すべてが上記と同じですが、正規化された距離をカウントするだけです。
スポイラーヘッダー
# create feature with NORMALIZATION LEVENSTAIN DISTANCE
normalized_levenshtein = NormalizedLevenshtein()
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
baseline_train["norm_levenstein"] = baseline_train.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)
baseline_test["norm_levenstein"] = baseline_test.progress_apply(
lambda r: normalized_levenshtein.distance(r[column_1], r[column_2]),axis=1)私たちは数えました、そして今私たちは視覚化します
機能の視覚化
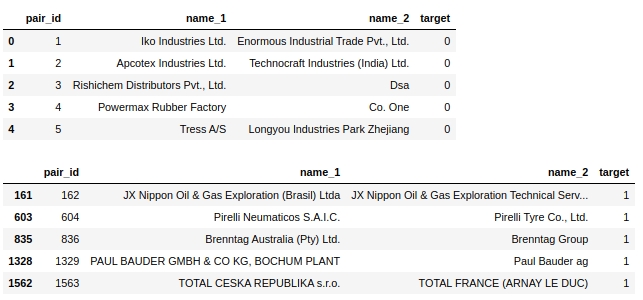
特性「levenstein」の分布を見てみましょう
コード
data = baseline_train
analyse = 'levenstein'
size = (12,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)グラフ#1「特徴の重要性を評価するための口ひげのあるヒストグラムとボックス」
一見したところ、メトリックはデータをマークアップできます。明らかにあまり良くありませんが、使用することができます。
特性「norm_levenstein」の分布を見てみましょう
スポイラーヘッダー
data = baseline_train
analyse = 'norm_levenstein'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)グラフ№2「サインの重要性を評価するための口ひげのあるヒストグラムとボックス」

すでに良くなっています。ここで、2つの組み合わされた機能がスペースをオブジェクト0と1に分割する方法を見てみましょう。
コード
data = baseline_train
analyse1 = 'levenstein'
analyse2 = 'norm_levenstein'
size = (14,6)
two_features(data,analyse1,analyse2,size)グラフ#3「散布図」
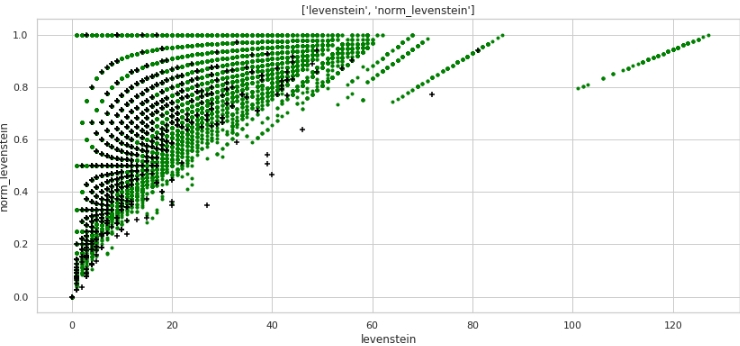
非常に良いマークアップが得られます。したがって、データをそれほど前処理したことは何の意味もありません:)
水平方向(メトリック「levenstein」の値)と垂直方向(メトリック「norm_levenstein」の値)、および緑と黒の点がオブジェクト0と1であることを誰もが理解しています。次に進みます。
各ペアのテキスト内の単語を比較して、多数の機能を生成してみましょう
以下では、会社名の単語を比較します。次の機能を作成しましょう。
- 各ペアの#1と#2の列に重複している単語のリスト
- 重複していない単語のリスト
これらの単語のリストに基づいて、トレーニング済みモデルにフィードする機能を作成します。
- 重複する単語の数
- 重複していない単語の数
- 文字の合計、重複する単語
- 文字の合計、重複する単語ではありません
- 重複する単語の平均の長さ
- 重複していない単語の平均の長さ
- NOT重複の数に対する重複の数の比率
ここでも、急いで書かれたので、ここのコードはおそらくあまり友好的ではありません。しかし、それは機能しますが、それは迅速な研究に行きます。
コード
# make some information about duplicates and differences for TRAIN
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_train.shape[0]):
list1 = list(baseline_train[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_train[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TRAIN
baseline_train['duplicate'] = duplicates
baseline_train['difference'] = difference
baseline_train['duplicate_count'] = duplicate_count
baseline_train['duplicate_sum'] = duplicate_sum
baseline_train['duplicate_mean'] = baseline_train['duplicate_sum'] / baseline_train['duplicate_count']
baseline_train['duplicate_mean'] = baseline_train['duplicate_mean'].fillna(0)
baseline_train['dif_count'] = dif_count
baseline_train['dif_sum'] = dif_sum
baseline_train['dif_mean'] = baseline_train['dif_sum'] / baseline_train['dif_count']
baseline_train['dif_mean'] = baseline_train['dif_mean'].fillna(0)
baseline_train['ratio_duplicate/dif_count'] = baseline_train['duplicate_count'] / baseline_train['dif_count']
# make some information about duplicates and differences for TEST
column_1 = 'name_1_finish'
column_2 = 'name_2_finish'
duplicates = []
difference = []
for i in range(baseline_test.shape[0]):
list1 = list(baseline_test[i:i+1][column_1])
str1 = ''.join(list1).split()
list2 = list(baseline_test[i:i+1][column_2])
str2 = ''.join(list2).split()
duplicates.append(list(set(str1) & set(str2)))
difference.append(list(set(str1).symmetric_difference(set(str2))))
# continue make information about duplicates
duplicate_count,duplicate_sum = compair_metrics(duplicates)
dif_count,dif_sum = compair_metrics(difference)
# create features have information about duplicates and differences for TEST
baseline_test['duplicate'] = duplicates
baseline_test['difference'] = difference
baseline_test['duplicate_count'] = duplicate_count
baseline_test['duplicate_sum'] = duplicate_sum
baseline_test['duplicate_mean'] = baseline_test['duplicate_sum'] / baseline_test['duplicate_count']
baseline_test['duplicate_mean'] = baseline_test['duplicate_mean'].fillna(0)
baseline_test['dif_count'] = dif_count
baseline_test['dif_sum'] = dif_sum
baseline_test['dif_mean'] = baseline_test['dif_sum'] / baseline_test['dif_count']
baseline_test['dif_mean'] = baseline_test['dif_mean'].fillna(0)
baseline_test['ratio_duplicate/dif_count'] = baseline_test['duplicate_count'] / baseline_test['dif_count']
いくつかの兆候を視覚化します。
コード
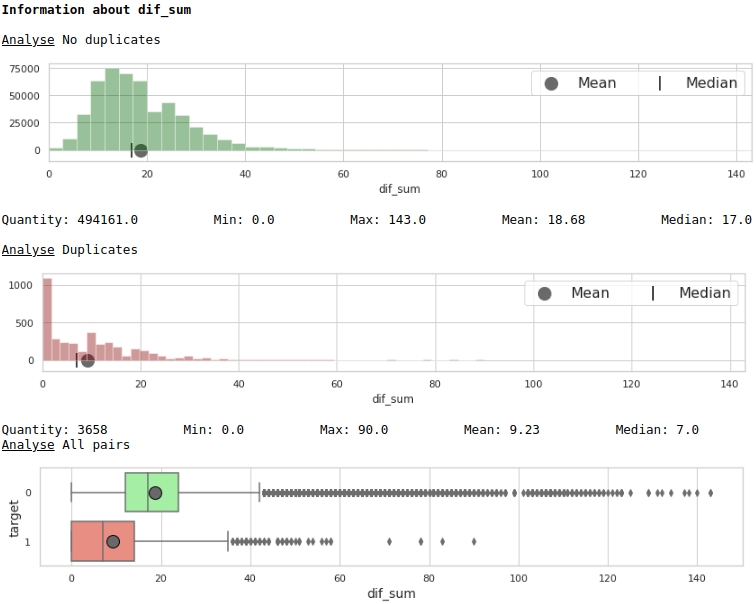
data = baseline_train
analyse = 'dif_sum'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)グラフNo.4「サインの重要性を評価するためのヒストグラムと口ひげのある箱」
コード
data = baseline_train
analyse1 = 'duplicate_mean'
analyse2 = 'dif_mean'
size = (14,6)
two_features(data,analyse1,analyse2,size)グラフ№5「スキャッターダイアグラム」
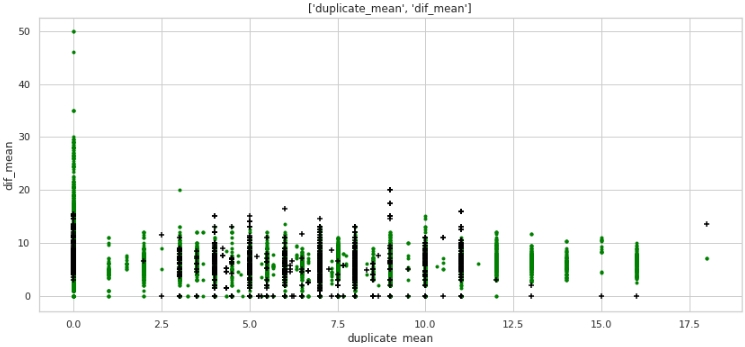
なんてことじゃないけど、マークアップ。ターゲットラベルが1の企業の多くは、テキストの重複がゼロであり、名前の重複が平均12ワードを超える企業の多くは、ターゲットラベルが0の企業に属していることに注意してください。
表形式のデータを見て、クエリを準備します。最初のケース:会社の名前に重複はありませんが、会社は同じです。
コード
baseline_train[
baseline_train['duplicate_mean']==0][
baseline_train['target']==1].drop(
['duplicate', 'difference',
'name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated'],axis=1)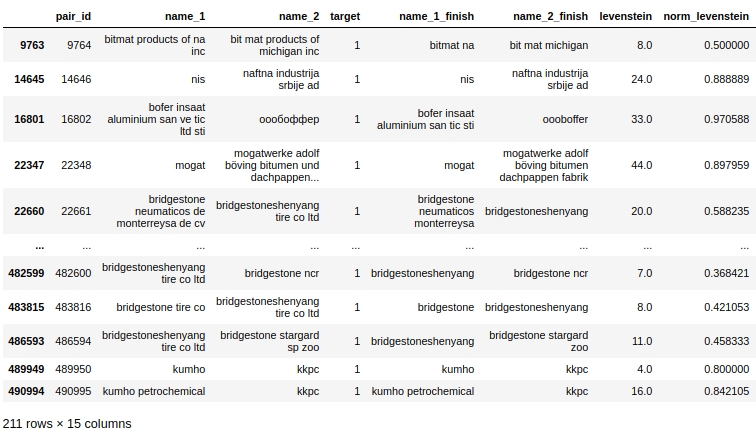
明らかに、処理中にシステムエラーがあります。私たちは、単語がエラーで綴られるだけでなく、単に一緒に、または逆に、これが必要とされない場合は別々に綴られる可能性があることを考慮しませんでした。たとえば、ペア#9764です。最初の列の「ビットマット」の2番目の「ビットマット」で、これはダブルではありませんが、会社は同じです。または別の例として、ペア#482600「bridgestoneshenyang」と「bridgestone」。
何ができるか。私が最初に思いついたのは、直接正面からではなく、Levenshteinメトリックを使用して比較することでした。しかし、ここでも待ち伏せが待っています。「bridgestoneshenyang」と「bridgestone」の間の距離は小さくありません。おそらく、レンマ化が助けになるでしょうが、企業の名前をどのようにレンマ化できるかはすぐには明らかではありません。または、タミモト係数を使用することもできますが、この瞬間をより経験豊富な仲間に任せて先に進みましょう。
テキストの単語を、石油化学、建設、その他の業界の上位50の保有ブランドの名前の単語と比較してみましょう。機能の2番目の大きな山を取得しましょう。セカンドチット
実際、コンテストへの参加に関する規則には2つの違反があります。
- -, , «duplicate_name_company»
- -, . , .
どちらのテクニックも競争ルールで禁止されています。あなたは禁止を回避することができます。これを行うには、トレーニングサンプルの選択的なレビューに基づいて手動でではなく、外部ソースから自動的に保持名のリストを編集する必要があります。しかし、最初に、保有物のリストが大きくなり、作品で提案された単語の比較に非常に時間がかかります。次に、このリストを編集する必要があります:)したがって、研究を簡単にするために、モデルの品質がどの程度向上するかを確認します。これらの兆候。今後の展望-品質は驚くほど成長しています!
最初の方法ではすべてが明確に見えますが、2番目の方法では説明が必要です。
それでは、会社名の最初の列の各行の各単語から、(だけでなく)上位の石油化学会社のリストの各単語までのレベンシュテイン距離を決定しましょう。
単語の長さに対するレベンシュテイン距離の比率が0.4以下の場合、上位企業のリストから選択した単語に対するレベンシュテイン距離の比率を、2番目の列(2番目の会社の名前)の各単語に対して決定します。
2番目の係数(トップ企業のリストからの単語の長さに対する距離の比率)が0.4以下であることが判明した場合、次の値を表に固定します:
- ナンバーワン企業リストの単語からトップ企業リストの単語までのレベンシュテイン距離
- 2位企業リストの単語から上位企業リストの単語までのレベンシュテイン距離
- リスト#1の単語の長さ
- リスト#2の単語の長さ
- トップ企業のリストからの単語の長さ
- リスト#1からの単語の長さと距離の比率
- リストNo.2の単語の長さと距離の比率
1行に複数の一致が存在する可能性があるので、それらの最小値を選択しましょう(集計関数)。
提案された特徴を生成する方法は非常に多くのリソースを消費し、外部ソースからリストを取得する場合、メトリックをコンパイルするためのコードの変更が必要になるという事実にもう一度注意を向けたいと思います。
コード
# create information about duplicate name of petrochemical companies from top list
list_top_companies = list_top_companies
dp_train = []
for i in list(baseline_train['duplicate']):
dp_train.append(''.join(list(set(i) & set(list_top_companies))))
dp_test = []
for i in list(baseline_test['duplicate']):
dp_test.append(''.join(list(set(i) & set(list_top_companies))))
baseline_train['duplicate_name_company'] = dp_train
baseline_test['duplicate_name_company'] = dp_test
# replace name duplicate to number
baseline_train['duplicate_name_company'] =\
baseline_train['duplicate_name_company'].replace('',0,regex=True)
baseline_train.loc[baseline_train['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
baseline_test['duplicate_name_company'] =\
baseline_test['duplicate_name_company'].replace('',0,regex=True)
baseline_test.loc[baseline_test['duplicate_name_company'] != 0, 'duplicate_name_company'] = 1
# create some important feature about similar words in the data and names of top companies for TRAIN
# (levenstein distance, length of word, ratio distance to length)
baseline_train = dist_name_to_top_list_make(baseline_train,
'name_1_finish','name_2_finish',list_top_companies)
# create some important feature about similar words in the data and names of top companies for TEST
# (levenstein distance, length of word, ratio distance to length)
baseline_test = dist_name_to_top_list_make(baseline_test,
'name_1_finish','name_2_finish',list_top_companies)
チャートのプリズムを通して特徴の有用性を見てみましょう
コード
data = baseline_train
analyse = 'levenstein_dist_w1_top_w_min'
size = (14,2)
dd = data_statistics(data,analyse,title_print='no')
hist_fz(data,dd,analyse,size)
boxplot(data,analyse,size)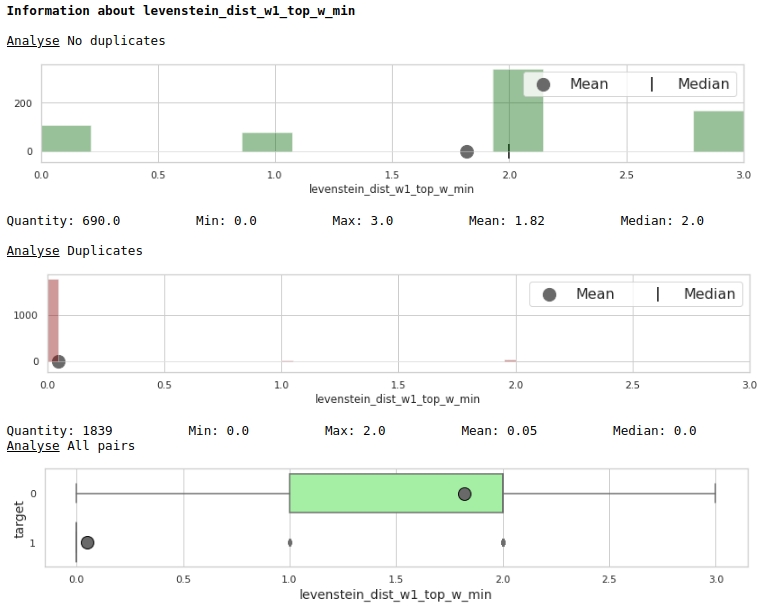
とても良い。
モデルに提出するためのデータの準備
大きなテーブルがあり、分析にすべてのデータが必要なわけではありません。テーブルの列の名前を見てみましょう。
コード
baseline_train.columns
分析する列を選択しましょう。
結果の再現性のためにシードを修正しましょう。
コード
# fix some parameters
features = ['levenstein','norm_levenstein',
'duplicate_count','duplicate_sum','duplicate_mean',
'dif_count','dif_sum','dif_mean','ratio_duplicate/dif_count',
'duplicate_name_company',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min'
]
seed = 42最終的に利用可能なすべてのデータでモデルをトレーニングし、検証のためにソリューションを送信する前に、モデルをテストすることは理にかなっています。これを行うために、トレーニングサンプルを条件付きトレーニングと条件付きテストに分割します。その品質を測定し、それが私たちに合っている場合は、ソリューションをコンテストに送信します。
コード
# provides train/test indices to split data in train/test sets
split = StratifiedShuffleSplit(n_splits=1, train_size=0.8, random_state=seed)
tridx, cvidx = list(split.split(baseline_train[features],
baseline_train["target"]))[0]
print ('Split baseline data train',baseline_train.shape[0])
print (' - new train data:',tridx.shape[0])
print (' - new test data:',cvidx.shape[0])モデルの設定とトレーニング
LightGBMライブラリの決定ツリーをモデルとして使用します。
パラメータを大きくしすぎても意味がありません。コードを見てみましょう。
コード
# learning Light GBM Classificier
seed = 50
params = {'n_estimators': 1,
'objective': 'binary',
'max_depth': 40,
'min_child_samples': 5,
'learning_rate': 1,
# 'reg_lambda': 0.75,
# 'subsample': 0.75,
# 'colsample_bytree': 0.4,
# 'min_split_gain': 0.02,
# 'min_child_weight': 40,
'random_state': seed}
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train.iloc[tridx][features].values,
baseline_train.iloc[tridx]["target"].values)モデルは調整され、訓練されました。それでは、結果を見てみましょう。
コード
# make predict proba and predict target
probability_level = 0.99
X = baseline_train
tridx = tridx
cvidx = cvidx
model = model
X_tr, X_cv = contingency_table(X,features,probability_level,tridx,cvidx,model)
train_matrix_confusion = matrix_confusion(X_tr)
cv_matrix_confusion = matrix_confusion(X_cv)
report_score(train_matrix_confusion,
cv_matrix_confusion,
baseline_train,
tridx,cvidx,
X_tr,X_cv)
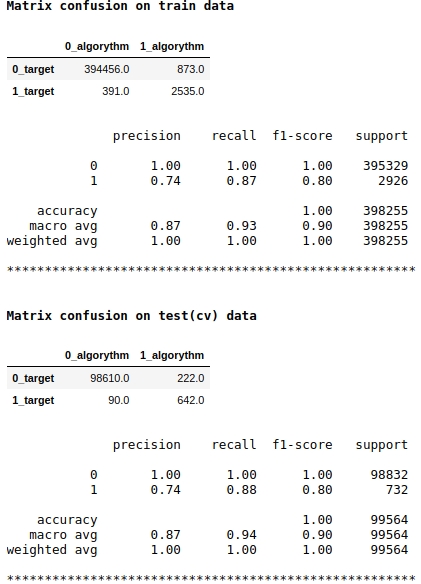
モデルスコアとしてf1品質メトリックを使用していることに注意してください。これは、オブジェクトをクラス1または0に割り当てる確率のレベルを調整することが理にかなっていることを意味します。0.99のレベルを選択しました。つまり、確率が0.99以上の場合、オブジェクトはクラス1、0.99未満、つまりクラス0に割り当てられます。これは重要なポイントです。速度を大幅に向上させることができます。トリッキーではなく、そのような単純なトリック。
品質は悪くないようです。条件付きテストサンプルでは、アルゴリズムはクラス0の222個のオブジェクトを定義するときにミスを犯し、クラス0に属する90個のオブジェクトではミスを犯し、それらをクラス1に割り当てました(テスト(cv)データのマトリックスの混乱を参照)。
どの兆候が最も重要で、どれがそうでなかったかを見てみましょう。
コード
start = 0
stop = 50
size = (12,6)
tg = table_gain_coef(model,features,start,stop)
gain_hist(tg,size,start,stop)
display(tg)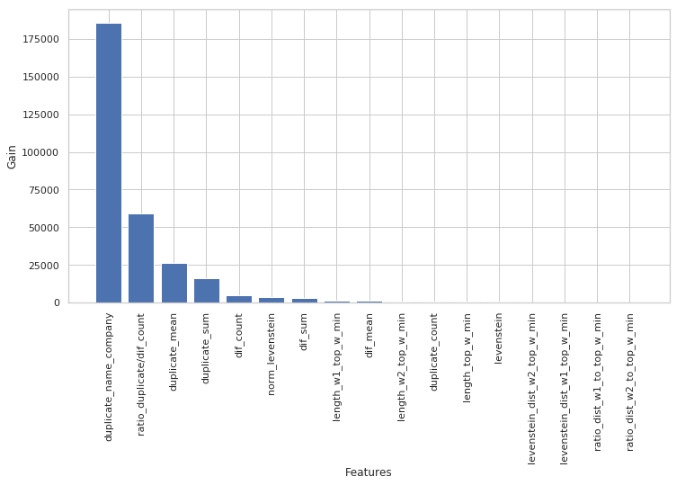
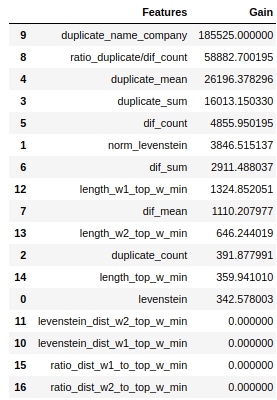
機能の重要性を評価するために、「split」パラメーターではなく「gain」パラメーターを使用したことに注意してください。非常に簡略化されたバージョンでは、最初のパラメーターはエントロピーの減少に対するフィーチャーの寄与を意味し、2番目のパラメーターは、スペースをマークするためにフィーチャーが使用された回数を示すため、これは重要です。
一見したところ、私たちが非常に長い間行ってきた機能「levenstein_dist_w1_top_w_min」は、まったく有益ではないことがわかりました。その寄与は0です。しかし、これは一見しただけです。 「duplicate_name_company」属性を使用すると、意味がほぼ完全に複製されます。 「duplicate_name_company」を削除して「levenstein_dist_w1_top_w_min」のままにすると、最初の属性の代わりに2番目の属性が使用され、品質は変わりません。チェックしました!
一般に、このような記号は、特に数百の機能と、ベルとホイッスルがたくさんあり、5000回の繰り返しがあるモデルがある場合に便利です。機能をバッチで削除し、この狡猾でないアクションから品質がどのように向上するかを確認できます。私たちの場合、機能を削除しても品質には影響しません。
メイトテーブルを見てみましょう。まず、オブジェクト「False Positive」、つまり、アルゴリズムが同じであると判断してクラス1に割り当てたオブジェクトを見てみましょう。ただし、実際には、これらはクラス0に属しています。
コード
X_cv[X_cv['False_Positive']==1][0:50].drop(['name_1_non_stop_words',
'name_2_non_stop_words', 'name_1_transliterated',
'name_2_transliterated', 'duplicate', 'difference',
'levenstein',
'levenstein_dist_w1_top_w_min', 'levenstein_dist_w2_top_w_min',
'length_w1_top_w_min', 'length_w2_top_w_min', 'length_top_w_min',
'ratio_dist_w1_to_top_w_min', 'ratio_dist_w2_to_top_w_min',
'True_Positive','True_Negative','False_Negative'],axis=1)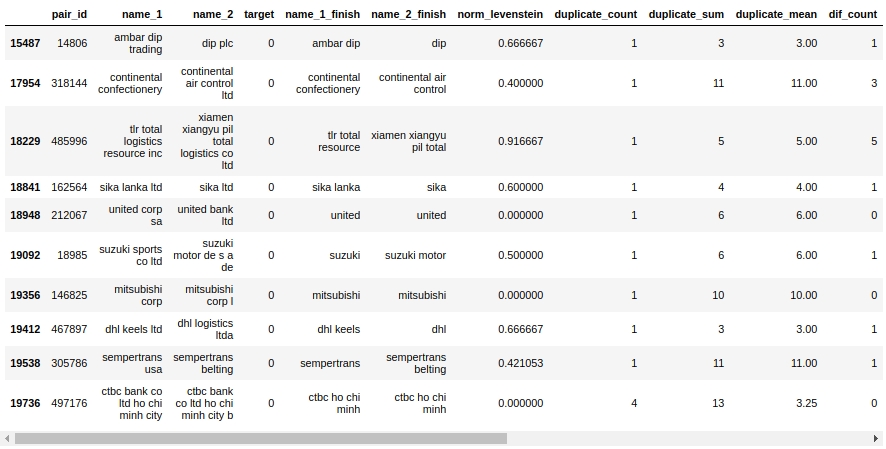
ええ ここでは、人が0または1をすぐに決定することはありません。たとえば、ペア#146825「mitsubishicorp」と「mitsubishicorpl」。目は同じことだと言っていますが、サンプルは別の会社だと言っています。誰を信じますか?
すぐに絞り出すことができたとだけ言っておきましょう-私たちは絞り出しました。残りの作業は経験豊富な仲間に任せます:)
主催者のウェブサイトにデータをアップロードして、作業の質の評価を調べましょう。
大会結果
コード
model = lgb.LGBMClassifier(**params)
model.fit(baseline_train[features].values,
baseline_train["target"].values)
sample_sub = pd.read_csv('sample_submission.csv', index_col="pair_id")
sample_sub['is_duplicate'] = (model.predict_proba(
baseline_test[features].values)[:, 1] > probability_level).astype(np.int)
sample_sub.to_csv('baseline_submission.csv')
したがって、禁止されている方法を考慮した場合の速度:0.5999
それがないと、品質は0.3から0.4の間のどこかになりました。正確にするためにモデルを再起動する必要がありますが、私は少し怠惰です:)
経験をよりよく要約しましょう。
まず、ご覧のとおり、非常に再現性の高いコードとかなり適切なファイル構造があります。私の経験が少ないため、私はかつて、多少の快適なスピードを得るために、急いで仕事を埋めていたという理由だけで、たくさんのバンプを埋めました。その結果、ファイルは1週間後に開くのがすでに怖かったようなものであることが判明しましたが、それほど明確なものはありません。したがって、私のメッセージは、すぐにコードを記述してファイルを読み取り可能にすることです。これにより、1年以内にデータに戻り、最初に構造を確認し、実行された手順を理解してから、各手順を簡単に分解できるようになります。もちろん、初心者の場合、最初の試行ではファイルが美しくなく、コードが壊れ、問題が発生しますが、調査プロセス中に定期的にコードを書き直すと、その後、5〜7回の書き換えで、コードがどれほどクリーンであるかに驚かれることでしょう。エラーを見つけて速度を向上させることさえできます。関数を忘れないでください、それはファイルを非常に読みやすくします。
次に、データを処理するたびに、すべてが計画どおりに進んだかどうかを確認します。これを行うには、パンダのテーブルをフィルタリングできる必要があります。この作品にはたくさんのフィルタリングがあります、健康のためにそれを使用してください:)
第三に、分類タスクでは、常に、まったく常に、テーブルと共役マトリックスの両方を形成します。表から、アルゴリズムが間違っているオブジェクトを簡単に見つけることができます。まず、システムエラーと呼ばれるエラーに注意してください。修正に必要な作業が少なくて済み、より多くの結果が得られます。次に、システムエラーを整理するときに、特別な場合に進みます。エラーのマトリックスによって、アルゴリズムがより多くの間違いを犯す場所がわかります。クラス0または1です。ここからエラーを掘り下げます。たとえば、私のツリーはクラス1を適切に定義していることに気付きましたが、クラス0で多くの間違いを犯します。つまり、実際には0であるのに、このオブジェクトはクラス1であるとツリーが「言う」ことがよくあります。オブジェクトを0または1に分類する確率のレベルに関連付けられています。私のレベルは0.9に固定されました。オブジェクトをクラス1に割り当てる確率のレベルが0.99に上がると、クラス1のオブジェクトの選択が難しくなり、出来上がりになりました。速度が大幅に向上しました。
繰り返しになりますが、コンテストに参加する目的は、賞品を獲得することではなく、経験を積むことでした。コンテストが始まる前は、機械学習でテキストをどのように扱うかがわからなかったことを考えると、最終的には、数日でシンプルでありながら機能するモデルが得られ、目標は達成されたと言えます。また、データサイエンスの世界の初心者サムライにとって、賞ではなく経験を積むことが重要だと思います。むしろ、経験が賞です。したがって、競争に参加することを恐れないでください、それのために行ってください、誰もがビーバーです!
記事の公開時点では、競争はまだ終わっていません。コンテストの終了結果に基づいて、記事へのコメントで、モデルの品質を向上させるアプローチと機能について、最高のフェアスピードについて書きます。
そして、あなたは親愛なる読者です、あなたが今スピードを上げる方法についての考えを持っているならば、コメントに書いてください。善行をしなさい:)