
この投稿は、私の友人や初心者のための深い学習を通して、修復資料を作り直したものと見なすことができます。ディープラーニングを使用した画像復元へのアプローチに関連する10以上の投稿を書きました。今こそ、これらの記事の読者が学んだことの概要を簡単に説明し、私たちと一緒に楽しみたい初心者のための簡単な紹介を書くときです。
用語

図:1.破損した入力画像(左)と復元結果(右)の例。作成者のGithubページから取得した画像
図1に示されている破損した入力は、通常、次のことを識別します。b)不足しているピクセルを埋めるために使用できる、正しい残りの実際のピクセル。正しいピクセルを取得して、対応する関連スペースを埋めることができることに注意してください。
前書き
不足している部分を埋める最も簡単な方法は、コピーして貼り付けることです。重要なアイデアは、最初に残りのピクセルから最も類似した画像スライスを検索するか、数百万の画像を含む大規模なデータセットでそれらを見つけてから、欠落している部分にスライスを直接挿入することです。ただし、検索アルゴリズムには時間がかかる可能性があり、手動で生成された距離測定メトリックが含まれます。アルゴリズムの一般化とその効率はまだ改善する必要があります。
ビッグデータの時代の深層学習アプローチでは、深層学習の復元に対するデータ駆動型のアプローチがあります。これらのアプローチでは、一貫性が高く、きめの細かいドロップピクセルを生成します。画像復元への10のよく知られた深層学習アプローチを見てみましょう。これらの10を理解すれば、他の記事も理解できると思います。始めましょう。
コンテキストエンコーダー(最初のGANベースの復元アルゴリズム、2016年)

図: 2.コンテキストエンコーダー(CE)のネットワークアーキテクチャ。
コンテキストエンコーダー(CE、2016)[1]は、GANベースの復元の最初の実装です。この作業は、復元タスクの有用な基本概念をカバーしています。 「コンテキスト」の概念は、画像自体の理解に関連しています。エンコーダのアイデアの本質は、チャネルごとに完全に接続されたレイヤーです(ネットワークの中間レイヤーを図2に示します)。標準の完全に接続されたレイヤーと同様に、重要な点は、前のレイヤーのすべてのアイテムの場所が、現在のレイヤーのすべてのアイテムの場所に寄与するということです。したがって、ネットワークは要素のすべての配置間の関係を学習し、画像全体のより深い意味表現を取得します。 CEはベースラインと見なされます。詳細については、私の投稿[ここ]を参照してください。
MSNPS ( )

. 3. ( CE) (VGG-19).
(MSNPS、2016)[3]は、CE [1]の拡張バージョンと見なすことができます。この記事の著者は、修正されたCEを使用して画像の欠落部分を予測し、テクスチャネットワークを使用して予測を装飾し、塗りつぶされたモデルの欠落部分の品質を向上させました。テクスチャネットワークのアイデアは、スタイルを転送するタスクから取られています。ローカルテクスチャの詳細を改善するために、生成されたピクセルに最も類似した既存のピクセルのスタイルを設定したかったのです。この作品は、2段階の粗いネットワーク構造から細かいネットワーク構造の初期バージョンであると言えます。最初のコンテンツネットワーク(ここではCE)は、欠落しているパーツの再構築/予測を担当し、2番目のネットワーク(つまり、テクスチャネットワーク)は、埋められたパーツの改良を担当します。
典型的なピクセル再構成損失(つまり、L1損失)と標準的な敵対的損失に加えて、この記事で提案されているテクスチャ損失の概念は、後の画像復元作業で重要な役割を果たします。実際、テクスチャの喪失は、知覚の喪失とスタイルの喪失に関連しており、ニューラルスタイルの転送などの多くの画像生成タスクで広く使用されています。この記事の詳細については、私の以前の投稿[ここ]を参照してください。
GLCIC(深層学習回復のマイルストーン、2017年)
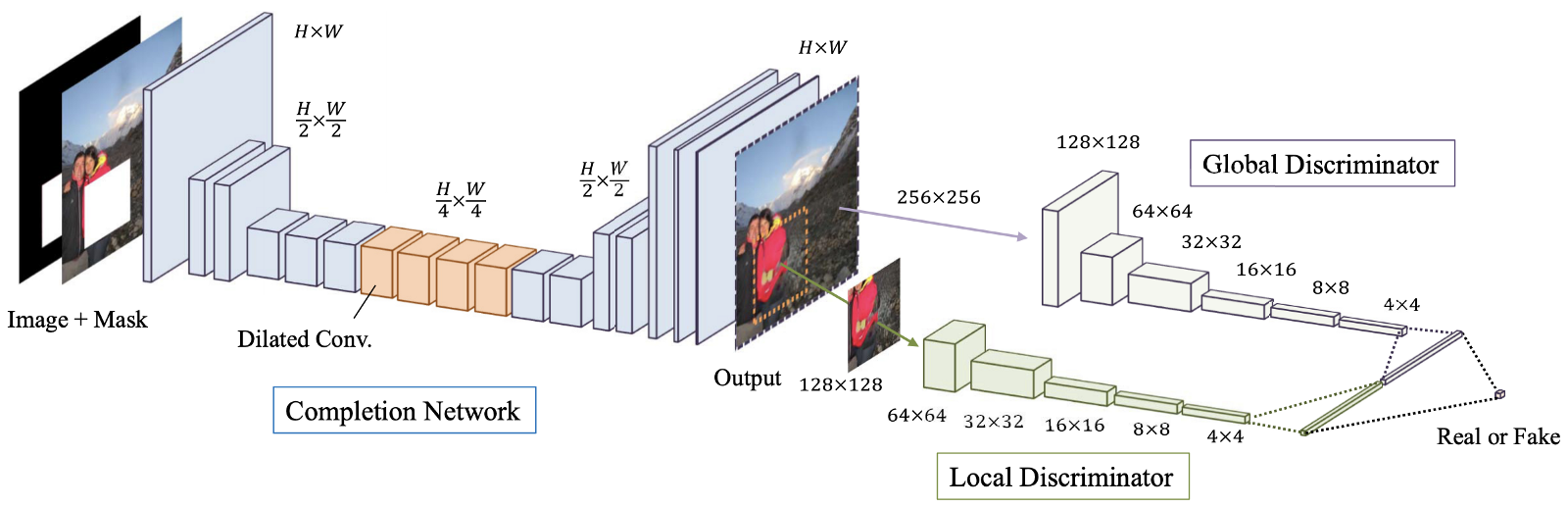
図: 4.ターミナルネットワーク(「ジェネレータ」ネットワーク)、およびグローバルおよびローカルのディスクリミネータで構成される、提案されたモデルの概要。
グローバルおよびローカルで一貫性のある画像補完(GLCIC、2017)[4]は、この領域の完全な畳み込み拡張畳み込みネットワークを定義し、実際には画像復元の典型的なネットワークアーキテクチャであるため、深層学習画像復元のマイルストーンです。高度なコンボリューションを使用すると、ネットワークは、高価な完全に接続されたレイヤーを使用せずに画像のコンテキストを理解できるため、さまざまなサイズの画像を処理できます。
拡張コンボリューションを備えた完全コンボリューションネットワークに加えて、2つのスケールの2つのディスクリミネーターもジェネレーターネットワークと一緒にトレーニングされました。グローバルディスクリミネーターは画像全体を確認し、ローカルディスクリミネーターは塗りつぶされた中央領域を確認します。グローバルとローカルの両方の識別子を使用すると、塗りつぶされた画像のグローバルとローカルの一貫性が向上します。画像復元に関する最近の記事の多くは、このマルチスケールディスクリミネーターの設計に従っていることに注意してください。興味のある方は、以前の投稿[こちら]で詳細をご覧ください。
GANパッチベースの復元(GLCICバリエーション、2018)

図: 5.生成ResNetおよびPGGANディスクリミネーターの提案されたアーキテクチャ。
GANを使用したパッチベースの復元[5]は、GLCIC [4]の変形と見なすことができます。簡単に言うと、パフォーマンスをさらに向上させるために、残差学習[6]とPatchGAN [7]という2つの高度な概念がGLCICに組み込まれています。この記事の著者は、残差結合と拡張畳み込みを組み合わせて、拡張残差ブロックを形成しました。従来のGANディスクリミネーターがPatchGANディスクリミネーターに置き換えられ、ローカルテクスチャの詳細とグローバル構造の一貫性が向上しました。
従来のGANディスクリミネーターとPatchGANディスクリミネーターの主な違いは、従来のGANディスクリミネーターは入力信号のリアリズムを示す1つの予測ラベル(0から1)のみを提供するのに対し、PatchGANディスクリミネーターはラベルのマトリックス(これも0から1)を提供することです。 )入力信号の各ローカルエリアのリアリズムを示します。各マトリックス要素は、入力のローカル領域を表すことに注意してください。[私のこの投稿にアクセスして]残差学習とPatchGANの概要を確認することもできます。
Shift-Net(Deep Learning Copy and Paste、2018)

図: 6.Shift-Netネットワークアーキテクチャ。スリップジョインレイヤーは32x32の解像度で追加されます。
Shift-Net [8]は、最新のデータ駆動型CNNと、提案されたシフト結合レイヤーを使用して要素を深く再パーティション化する従来の「コピーアンドペースト」方式の両方を利用しています。この記事には2つの主要なアイデアがあります。
最初に、著者は、欠落部分のデコードされた要素(画像の隠された部分が与えられた)を欠落部分のコード化された要素(画像の良好な状態が与えられた)に近づけるランドマークの喪失を提案しました。その結果、デコードプロセスでは、欠落している部分を、画像内の妥当な推定値で良好な状態で埋めることができます(つまり、欠落している部分の真実のソース)。
第2に、提案された結合シフトレイヤーにより、ネットワークは、欠落しているパーツの外側で最も近いネイバーから提供された情報を効率的に借用して、生成されたパーツのグローバルセマンティック構造とローカルテクスチャの詳細の両方を洗練できます。簡単に言えば、評価を改善するための適切なリンクを提供します。画像の復元に興味のある読者は、この記事で提案されたアイデアを統合することが役立つと思います。詳細については、前回の投稿[こちら]をお読みになることを強くお勧めします。
DeepFill v1(Breakthrough Image Restoration、2018)

図: 7.提案されたフレームワークのネットワークアーキテクチャ。 DeepFillv1またはCA [9]とも呼ばれる、
状況に応じた注意を払った生成的復元(CA、2018)は、Shift-Net [8]の拡張バージョンまたはバリアントと見なすことができます。著者は、コピーアンドペーストのアイデアを開発し、差別化可能で完全に畳み込みのある文脈上の注意の層を提供します。
[8]の結合シフト層と同様に、欠落しているピクセルの内側で生成された要素と欠落しているピクセルの外側の特性を照合することにより、欠落しているピクセル内の各位置に対する欠落しているピクセルの外側のすべての要素の寄与を見つけることができます。したがって、外側のすべての要素の組み合わせを使用して、欠落しているピクセルの内側で生成された要素を絞り込むことができます。最も類似した機能(つまり、ハードで区別できない割り当て)のみを検索する結合せん断レイヤーと比較して、この記事のCAレイヤーは、ソフトで区別可能な割り当てを使用します。この割り当てでは、すべての機能に独自の重みがあり、欠落しているピクセル内のすべての場所。コンテキストアテンションの詳細については、以前の投稿をお読みください[こちら]、そこにはより具体的な例があります。
GMCNN(画像復元用のマルチカラムCNN、2018)

図: 8.提案されたネットワークのアーキテクチャ。
Generative Multicolumn Convolutional Neural Networks(GMCNN、2018)[10]は、画像の復元に十分な受容フィールドの重要性を拡張し、生成されたコンテンツのローカルテクスチャの詳細をさらに改善する新しい損失関数を提供します。図9に示すように、3つのブランチ/列があり、各ブランチは3つの異なるフィルターサイズを使用します。いくつかの受容フィールド(フィルターサイズ)の使用は、受容フィールドのサイズが画像復元のタスクにとって重要であるという事実によるものです。局所的に隣接するピクセルがないため、空間的に離れた場所から情報を借りて、局所的に欠落しているピクセルを埋める必要があります。
提案された損失関数の場合、暗黙の多様化マルコフランダムフィールド(ID-MRF)損失の背後にある主なアイデアは、生成された要素パッチに、スキップされた領域の外側にある最も近い隣接ノードを参照として見つけるように指示することです。よりローカルなテクスチャの詳細をモデル化できるように、十分に多様化する必要があります。実際、この損失は、MSNPSで使用されるテクスチャ損失の拡張バージョンです[3]。この損失の詳細な説明については、私の投稿[ここ]を読むことを強くお勧めします。
PartialConv(不規則なボイドの詳細な学習を通じて復元の限界を押し上げる、2018年)

. 9. , .
(PartialConvまたはPConv)[11]は、複数の不規則な穴のある潜在的な画像を処理する方法を提供することにより、画像復元における深層学習の限界を押し広げます。明らかに、この記事の主なアイデアは部分的な折りたたみです。 PConvを使用する場合、コンボリューションの結果は許可されたピクセルのみに依存するため、ネットワーク内で送信される情報を制御できます。これは、不規則なボイドに対処する最初の画像復元作業です。以前の復元モデルは、損傷した正しい画像でトレーニングされているため、これらのモデルは、ボイドが正しくない復元画像には適していません。
以前の投稿で部分的な折りたたみがどのように実行されるかを明確に説明する簡単な例を提供しました[ここに]。詳細については、リンクにアクセスしてください。楽しんでいただければ幸いです。
EdgeConnect-最初にアウトライン、次にカラー、2019

図:10.ネットワークアーキテクチャEdgeConnect。ご覧のとおり、2つのジェネレーターと2つのディスクリミネーターがあります。
EdgeConnect[12]:敵対的エッジ学習(EdgeConnect)を使用した生成的画像復元[12]は、画像復元の問題を解決するための興味深い方法を示しています。この記事の主なアイデアは、復元タスクを2つの単純化されたステップに分割することです。つまり、エッジを予測し、予測されたエッジマップに基づいて画像を完成させます。欠落している領域のエッジが最初に予測され、次にエッジ予測に従って画像が完成します。この記事で使用されている方法のほとんどは、以前の投稿で取り上げられています。さまざまな手法を組み合わせて、深層学習の画像復元への新しいアプローチを形成する方法をよく見てください。おそらく、独自の復元モデルを開発するでしょう。私の以前の投稿をご覧ください[こちら]この記事についての詳細を学ぶために。
DeepFill v2(ジェネレーティブイメージ復元への実用的なアプローチ、2019年)

図:11.無料復元のためのモデルのネットワークアーキテクチャの概要。
ゲートコンボリューションによる自由形式の復元(DeepFill v2またはGConv、2019)[13]。これはおそらく、アプリケーションで直接使用できる最も実用的な画像復元アルゴリズムです。これは、DeepFill v1 [9]、部分コンボリューション[11]、およびEdgeConnect [12]の拡張バージョンと考えることができます。作品の主なアイデアは、部分的なコンボリューションのトレーニング可能なバージョンであるゲートコンボリューションです。標準の畳み込みレイヤーを追加し、その後にシグモイド関数を追加することで、各ピクセル/オブジェクトの位置の有効性を知ることができるため、追加のカスタムスケッチ入力も可能になります。ゲートコンボリューションに加えて、SN-PatchGANは、GANモデルのトレーニングをさらに安定させるために使用されます。部分コンボリューションとゲートコンボリューションの違いとその方法について詳しく知る追加のユーザースケッチ入力が復元結果にどのように影響するかについては、私の最後の投稿を参照してください[ここ]。
結論
これで、画像復元の基本を理解できたと思います。ディープラーニングの画像復元で使用される一般的な手法のほとんどは、以前の投稿で取り上げられていると思います。あなたが私の古くからの友人であるならば、あなたは今、深い学習を使って他の修復作業を理解する立場にあると思います。初心者の方、大歓迎です。この投稿がお役に立てば幸いです。実際、この投稿はあなたに私たちに参加して一緒に学ぶ機会を与えてくれます。
私の意見では、複雑なシーン構造と多数の欠落したピクセルを含む画像を復元することは依然として困難です(たとえば、ピクセルの50%が欠落している場合)。もちろん、別の課題は高解像度の画像の復元です。これらのタスクはすべて極端と呼ぶことができます。最新の修復の進歩に基づくアプローチは、これらの問題のいくつかを解決できると思います。
記事へのリンク
[1] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, “Context Encoders: Feature Learning by Inpainting,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.
[2] Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio, “Generative Adversarial Nets,” in Advances in Neural Information Processing Systems (NeurIPS), 2014.
[3] Chao Yang, Xin Lu, Zhe Lin, Eli Shechtman, Oliver Wang, and Hao Li, “High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis,” Proc. International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[4] Satoshi Iizuka, Edgar Simo-Serra, and Hiroshi Ishikawa, “Globally and Locally Consistent Image Completion,” ACM Trans. on Graphics, Vol. 36, №4, Article 107, Publication date: July 2017.
[5] Ugur Demir, and Gozde Unal, “Patch-Based Image Inpainting with Generative Adversarial Networks,” arxiv.org/pdf/1803.07422.pdf.
[6] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep Residual Learning for Image Recognition,” Proc. Computer Vision and Pattern Recognition (CVPR), 27–30 Jun. 2016.
[7] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros, “Image-to-Image Translation with Conditional Adversarial Networks,” Proc. Computer Vision and Pattern Recognition (CVPR), 21–26 Jul. 2017.
[8] Zhaoyi Yan, Xiaoming Li, Mu Li, Wangmeng Zuo, and Shiguang Shan, “Shift-Net: Image Inpainting via Deep Feature Rearrangement,” Proc. European Conference on Computer Vision (ECCV), 2018.
[9] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas S. Huang, “Generative Image Inpainting with Contextual Attention,” Proc. Computer Vision and Pattern Recognition (CVPR), 2018.
[10] Yi Wang, Xin Tao, Xiaojuan Qi, Xiaoyong Shen, and Jiaya Jia, “Image Inpainting via Generative Multi-column Convolutional Neural Networks,” Proc. Neural Information Processing Systems, 2018.
[11] Guilin Liu, Fitsum A. Reda, Kevin J. Shih, Ting-Chun Wang, Andrew Tao, and Bryan Catanzaro, “Image Inpainting for Irregular Holes Using Partial Convolution,” Proc. European Conference on Computer Vision (ECCV), 2018.
[12] Kamyar Nazeri, Eric Ng, Tony Joseph, Faisal Z. Qureshi, Mehran Ebrahimi, “EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning,” Proc. International Conference on Computer Vision (ICCV), 2019.
[13] Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu, and Thomas Huang, “Free-Form Image Inpainting with Gated Convolution,” Proc. International Conference on Computer Vision (ICCV), 2019.
