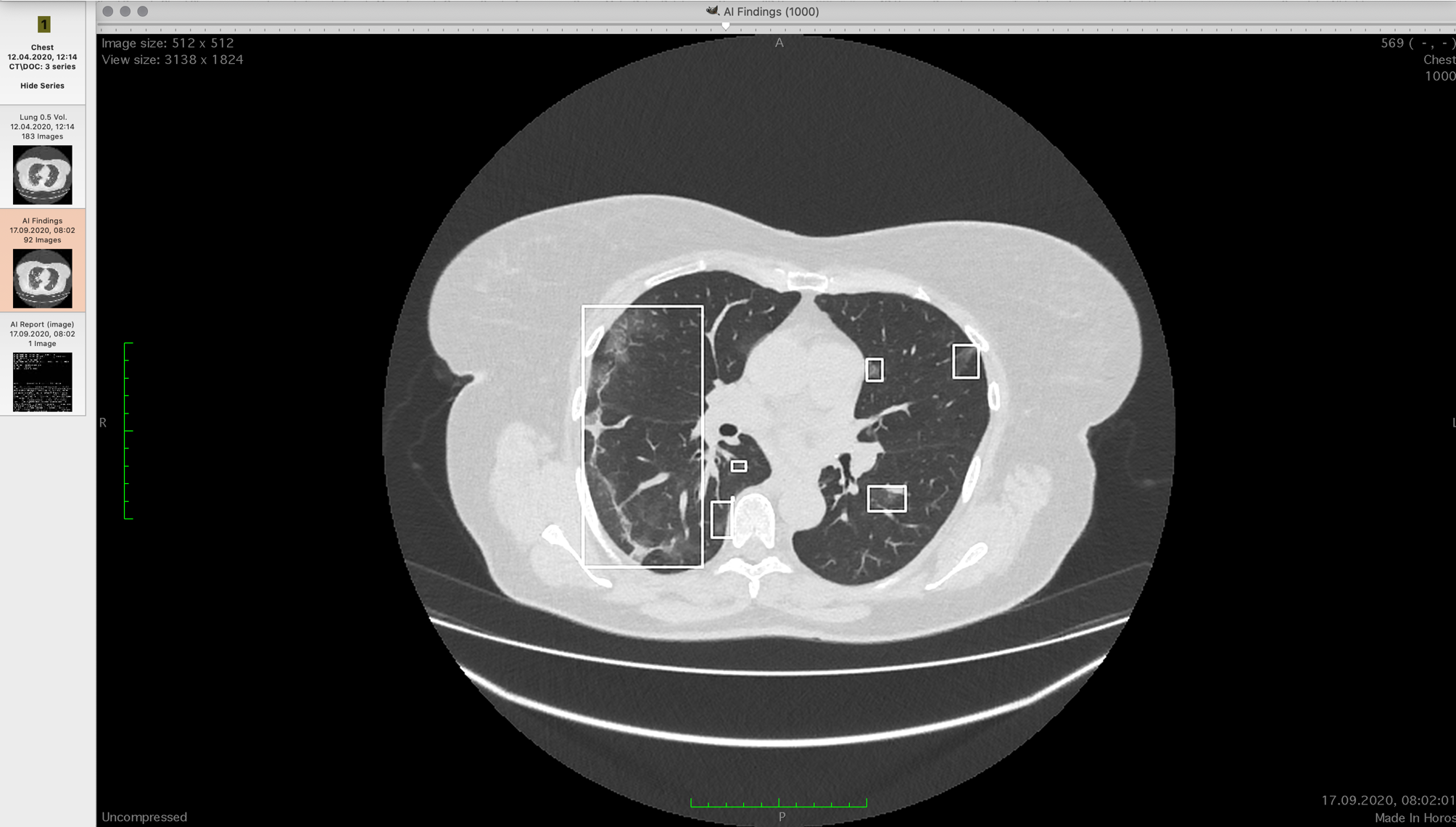
つや消しガラス領域を使用したCTスキャン
COVID-19が確認された患者は、肺のコンピューター断層撮影を受けます。運が良ければ-一度、そうでなければ-数回。初めて、ダメージのレベルをパーセンテージで見積もる必要があります。損傷の程度の四分位に応じて、さらなる治療計画が決定され、それらは著しく異なります。2020年4月、私たちは2つの困難があることを学びました。
- CTは3次元画像であり、このような画像の各レイヤーはスライスと呼ばれます。CTで300〜800の肺スライスを使用する場合、医師は1〜15分かけて特徴的な領域を探し、病変の範囲を判断します。1分は「目で」、30分は損傷した組織の領域を手動で選択してカウントするための平均です。難しい場合、結果は最大1時間処理できます。
- 専門家によるコロナウイルス感染のレベルを「目で」診断する精度は、0〜30%と70〜100%の境界で高いです。30〜70の範囲では、誤差が非常に大きく、放射線技師の中には、原則として、眼への損傷の割合を体系的に過大評価している人もいれば、過小評価している人もいることに気づきました。
タスクは、肺の損傷した組織を特定し、肺全体に対するそれらの体積の割合を計算することになります。
4月末に、クリニックと協力して、COVID-19のPCR分析が確認された患者の匿名化研究のデータセットを作成し、10人の優秀な専門放射線技師の委員会を提供し、教師とのトレーニング用のサンプルを作成しました。
5月末にベータ版がありました。7月には、ロシアで使用されているさまざまなタイプのCT機器の既製モデルがありました。私たちはSberbankの人工知能研究所のチームです。一般的に、私たちは科学文献(MICCAI、AIME、BIOSIGNALS)で開発を公開しており、AIジャーニーでもこれについて話します。
どうしてそれが重要ですか
放射線技師はすでに4月末に列を作っています。それは重要でした:
- CT検査でポイントのスループットを向上させます。
- 第二に、研究の精度を高めます。
- 1人の患者の画像間の病変レベルの変化を正確に確認できるようにします(これは数パーセントになる可能性があるため、多かれ少なかれ悪化したかどうかを理解することが重要です)。
さらに、最初の波では、経験豊富な放射線技師が病気になり、プロセスを離れたため、状況はさらに悪化しました。精度と速度が低下しました。
人工知能は医療データの分類に優れています。正しい患者の優先順位付けは命を救います。なぜなら、傷害の程度を正確に判断すればするほど、重病の人が必要な薬と(すべてが悪化した場合)時間通りに機械的換気を受ける可能性が高くなるからです。そして、肺がそれほどひどく影響を受けていない人は、病院で彼の代わりになりません。
病変の割合の評価は、多くのセクションに分割された大量の不規則な病巣を評価する必要があるため、診断を行う人にとって最も困難でリソースを大量に消費するタスクの1つです。
タスク自体
入り口で-特定の厚さの軸方向のスライス。通常、設定は0.5mmから2.5mmの範囲で設定されます。リブケージは300から800の2D画像です。それらは互いにほぼ対応しています。つまり、特定の厚さの半透明のフィルム上に条件付きで画像を作成できるようにすでに変換されており、胸のモデルが取得されます。しかし、もちろん、すべてが長い間デジタル形式でした。
ビューアは、CTスキャンをレイヤーで表示したり、3Dモデルを構築したりできます。このタイプの病変の病巣の局在をモデルから理解することは困難であるため、モデルは医師にとってあまり有益ではありません。専門家はしばしば多平面再構成を使用します-彼らは画面上に3つの直交する投影を表示します-水平、正面、矢状。次に、セクションに沿って各軸をスキャンし、必要なものを探します。これは実際にはすぐに起こります。これらの写真のうち500枚を3回見る必要があります。

医師が異なれば、そのような観察後の損傷の割合に関して異なる結果が得られます。
胸部の肺の体積を測定し、そこですべての圧密を見つけてから、それらの体積を推定する必要があります。最初のサンプルでは、60,000個の再構築されたCTスライスを取得しました(デバイスは1つの軸で撮影しますが、必要な投影は変換を使用して取得できます)。
私たちの10人の医師は目で評価しませんでしたが、各セクションを注意深く調べて、すべての統合を手動で選択しました。既存のセットのストレッチ、スクイーズ、ローテーション、シフトの組み合わせである拡張機能を使用して、トレーニングセットをわずかに強化しました。
アルゴリズムは、各ポイントの統合の存在を決定します。使用されるニューラルネットワークモデルは、2016年に公開されたU-Netアーキテクチャに基づいています..。U-Netアーキテクチャの利点は、ニューラルネットワークが元の画像をさまざまなスケールで分析することです。これにより、畳み込みレイヤーが画像の領域を「見る」ことができ、ニューラルネットワークの深さが増すにつれてサイズが指数関数的に大きくなります。言い換えれば、各折り目は3×3ピクセルの小さな領域を「見ています」。次に、スケールが2倍、次にさらに2倍に縮小されます。次の各畳み込みは3×3ピクセルの領域を調べますが、これらのピクセルの後ろには、画像の一部が数倍縮小されています(6×6、12×12、...)。最終的なアンサンブルには、U-Netに基づく同様のアーキテクチャの2つの畳み込みニューラルネットワークが含まれ、元の記事よりも「圧縮」部分が重くなります。
ネットワークがうまくいかないが、医者は間違っていない
写真には、呼吸や体の動きの結果である、いわゆるアーティファクトが含まれていることがあります。この場合、特性の変化に類似した領域が画像に表示されますが、これは病状ではありません。モデルがこれらの領域を特定したとしても、結果に対するそれらの合計の影響は10分の数パーセントであり、決定は四分位によって行われます。つまり、患者は損傷の程度に関して4つのカテゴリのいずれかに割り当てられる必要があります。したがって、タスクのこの部分は無視しました。その国で使用されている機器の種類ごとにネットワークを構成することがはるかに重要でした。
正規化
トモグラフはDICOM標準でファイルを書き込みますが、標準と記録形式の解釈は大きく異なる可能性があるため、すべてのCTマシンが書き込むファイルを維持するのに多くの時間と労力を要しました。その結果、すべてのDICOMファイルを単一の標準と単一の形式に縮小するためのツールもあります。これは、診断の問題を解決するのにさらに役立ちます。そして、COVID-19だけではありません。
私たちのソフトウェアは医者に干渉しませんが、並行してインストールされます。彼はいつものツールと私たちのソリューションを持っています。これは、分析レポートと見つかった統合のローカリゼーションを含む追加のシリーズを示しています。分析レポートは次のようになります。

このソフトウェアはオンプレミスによって提供され、クリニックのワークフローに含まれ、DICOMプロトコルを使用してCTマシンと医師のワークステーションで動作し、保護された回路内のクリニックのサーバーにインストールされます。ニューラルネットワークが機能するには強力なGPUが必要です。すべての地域の診療所がそれを買う余裕があるわけではないので、クラウドソリューションもあります。医療データの転送には機能があり、匿名化されることが保証されている必要があります。
なぜトモグラフのメーカーは何もしなかったのですか?
その仕事を引き受けたのは私たちだけのヒーローのように思えるかもしれません。いいえ、他のアプローチがありました。ほとんどの場合、断層撮影装置のメーカーは、ハウンズフィールドスケール(組織密度)に従って分類を終了し、既製の、ええと...個別にライセンスされたプラグイン、または特定の種類の組織のみが表示されるように設定を設定する方法に関するガイドラインをリリースしました。これにより、圧密をよりよく見ることができましたが(理想的には、放射フラックスの密度に関してそれらに特徴的な組織のみがフレームに残っていました)、それでも自動的にカウントすることはできませんでした。さらに、このような機能のロックを解除することは、多くの場合、いくつかの実装やGPUサーバーよりもコストがかかりました。
詳細はどこで見るか
ここです。
詳細。