強迫観念的なメロディー(英語のイヤワーム)-よく知られていて、時には刺激的な現象。これらのいずれかが頭に詰まると、それを取り除くのは難しい場合があります。研究によると、元の曲とのいわゆる相互作用は、それを聞いているか歌っているかにかかわらず、邪魔なメロディーを追い払うのに役立ちます。しかし、曲の名前を思い出せず、曲をハミングすることしかできない場合はどうでしょうか。
歌われたメロディーを元のポリフォニックスタジオレコーディングと比較する既存の方法を使用する場合、いくつかの困難が生じます。歌詞、バッキングボーカル、楽器を使ったライブまたはスタジオレコーディングのサウンドは、人が口ずさむものとは大きく異なる場合があります。さらに、誤って、または設計上、当社のバージョンのピッチ、キー、テンポ、またはリズムがまったく同じでない場合があります。これが、ハミングシステムによるクエリへの現在の多くのアプローチが、歌われたメロディーを直接識別するのではなく、既存のメロディーまたはその歌の他の歌われたバージョンのデータベースにマッピングする理由です。ただし、このタイプのアプローチは、多くの場合、手動更新を必要とする限られたデータベースに基づいています。 10月に発売されたHumto Search
は、完全に機械学習型の新しいGoogle検索システムで、歌ったり急いだりして曲を見つけることができます。既存の方法とは異なり、このアプローチでは、中間表現をバイパスして、曲のスペクトログラムから埋め込みを作成します。これにより、モデルは、トラックごとに異なるメロディやMIDIバージョンを使用しなくても、メロディを元の(ポリフォニック)録音と直接比較できます。メロディーを抽出するために複雑な手作りのロジックを使用する必要もありません。このアプローチにより、Hum to Searchのデータベースが大幅に簡素化され、最新のリリースであっても、世界中のオリジナルトラックの埋め込みを常に追加できるようになります。
使い方
多くの既存の音楽認識システムは、オーディオサンプルを処理する前に、オーディオサンプルをスペクトログラムに変換して、より正確な一致を見つけます。ただし、歌われたメロディーの認識には1つの問題があります。この曲「ベラチャオ」の例のように、情報が比較的少ないことがよくあります。歌われたバージョンと対応するスタジオレコーディングの同じセグメントの違いは、以下に示すスペクトログラムを使用して視覚化できます。

歌われたスニペットとそのスタジオレコーディングの視覚化
左側の画像を考えると、モデルは、5,000万を超える同様の画像(他の曲のスタジオレコーディングのセグメントに対応)のコレクションから、右側の画像と一致するオーディオを見つける必要があります。これを行うには、モデルは支配的なメロディーに焦点を合わせ、バックボーカル、楽器、声の音色、およびバックグラウンドノイズや残響による違いを無視することを学ぶ必要があります。 2つのスペクトログラムを比較するために使用できる主要なメロディーを目で判断するには、上の画像の下部にある線の類似点を探すことができます。
音楽の認識、特にカフェやクラブでのサウンドの認識を実装する以前の試みは、この問題に機械学習をどのように適用できるかを示しています。現在のプレイピクセル電話の2017年にリリースされ、サーバー接続を必要とせずに曲を認識するために、深いニューラルネットワークを内蔵しており、使用するサウンド検索後に技術を開発し、迅速かつ正確億曲を検索するサーバーベースの認識を使用しています。また、これらのリリースで学んだことを適用して、同様に大きなライブラリから、しかしすでに歌われているパッセージからの音楽を認識する必要がありました。
機械学習の設定
Hum to Searchの進化の最初のステップは、NowPlayingとSoundSearchで使用される音楽認識モデルをメロディーの録音で機能するように変更することでした。基本的に、多くの同様の検索エンジン(画像認識など)は同様の方法で機能します。トレーニングの過程で、ニューラルネットワークは入力としてペア(メロディーと元の録音)を受け取り、それらの埋め込みを作成します。これは後で歌われたメロディーと一致させるために使用されます。

ニューラルネットワークトレーニングの設定
私たちが歌っているものを確実に認識するには、同じメロディーのオーディオペアの埋め込みを、楽器の伴奏や歌声が異なっていても、隣り合わせに配置する必要があります。異なるメロディーを含むオーディオペアは、遠く離れている必要があります。トレーニングの過程で、ネットワークは、このプロパティを使用して埋め込みを作成する方法を学習するまで、そのようなオーディオペアを受信します。
最終的に、トレーニングされたモデルは、曲のマスターレコーディングの埋め込みと同様に、曲の埋め込みを生成できるようになります。この場合、目的の曲を見つけるには、人気のある音楽のオーディオ録音に基づいて計算された同様の埋め込みをデータベースで検索するだけです。
トレーニングデータ
モデルのトレーニングには曲のペア(録音と歌)が必要だったため、最初の課題は十分なデータを取得することでした。私たちの元のデータセットは、ほとんどが歌われたスニペットで構成されていました(それらのほとんどは、言葉のないモチーフのハムだけを含んでいました)。モデルの信頼性を高めるために、トレーニング中にこれらのフラグメントに拡張を適用しました。ピッチとテンポをランダムな順序で変更しました。結果として得られたモデルは、ハミングやホイッスルではなく歌が歌われた例では十分に機能しました。
言葉のないメロディーでのモデルのパフォーマンスを向上させるために、既存のオーディオデータのセットから人工的な「ハム」を使用して追加のトレーニングデータを生成しました。このために、プロジェクトの一環として拡張チームによって開発されたピッチ抽出モデルであるSPICEを使用しました。FreddieMeter。 SPICEは、指定されたオーディオからピッチ値を抽出します。これを使用して、個別のオーディオトーンで構成されるメロディを生成します。このシステムの最初のバージョンは、ここの元のパッセージを変換しました。
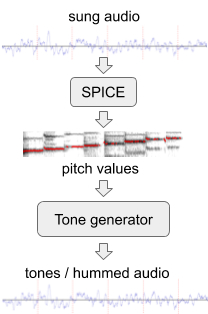
歌われたオーディオフラグメントから「ハム」を生成します。
その後、単純なトーンジェネレータを、言葉のないモチーフの実際のハムに似たサウンドを生成するニューラルネットワークに置き換えることで、アプローチを改善しました。たとえば、上記のスニペットは、そのようなハムやホイッスルに変換できます。
最後のステップでは、オーディオスニペットをミキシングして一致させることにより、トレーニングデータを比較しました。たとえば、2人の異なるアーティストからの同様のスニペットに出くわしたとき、それらを予備モデルと整列させたため、同じメロディのオーディオスニペットの追加ペアをモデルに提供しました。
モデルの改善
モデルを検索するためにハムを訓練では、我々は、使用を開始トリプレット損失関数いる、好調な画像や分類など、さまざまな分類作業に録音された音楽を。同じメロディーに一致するオーディオのペアが与えられた場合(以下に示す埋め込みスペースのRポイントとPポイント)、トリプレットロス関数は他のメロディーから取得されたトレーニングデータの特定の部分を無視します。これは、モデルが単純すぎてRとPからすでに遠い別のメロディーを見つけた場合の学習行動を改善するのに役立ちます(ポイントEを参照)。また、モデルトレーニングの現在の段階では複雑すぎて、Rに近すぎることが判明した場合も同様です(ポイントHを参照)。

空間内のポイントとしてレンダリングされたオーディオセグメントの例
追加のトレーニングデータ(ポイントHおよびE)を考慮に入れることによって、つまり一連の例でモデルの信頼性の一般的な概念を定式化することによって、モデルの精度を向上できることがわかりました。彼女が一緒に働いたのは正しく分類できますか?それとも、彼女は現在の理解に対応していない例に出くわしましたか?これに基づいて、埋め込みスペースのすべての領域でモデルの信頼度を100%に近づける損失関数を追加しました。これにより、モデルのメモリ品質と精度が向上します。
前述の変更、特に拡張とトレーニングデータの組み合わせにより、Google検索で使用されるニューラルネットワークモデルが歌われた曲を認識できるようになりました。現在のシステムは、私たちが絶えず更新している50万曲以上のデータベースに基づいて、高レベルの精度を実現しています。このトラックのコレクションには成長の余地があり、世界中からより多くの音楽が登場します。
この機能をテストするには、Googleアプリの最新バージョンを開き、マイクアイコンをクリックして「この曲は何ですか」と言うか、「曲を検索」をクリックします。今、あなたはメロディーを口ずさむか口笛を吹くことができます!Hum to Searchが邪魔なメロディーを取り除くのに役立つか、名前を入力せずにトラックを見つけて聞くのに役立つことを願っています。