情報セキュリティのトピックを継続し、CoussementBrunoによる記事の翻訳を公開します。
既存のデータにノイズを追加しますか、データ操作結果にのみノイズを追加しますか、それとも合成データを生成しますか?私たちの直感を信頼しましょう。

企業は成長し、サイバーセキュリティ規制は厳しくなり、上級アーキテクトはトレンドを受け入れています...これらすべてが、プライバシーと情報漏えいに関連するリスクを軽減する必要性(または義務)がデータ主体に対してのみ強まっているという事実につながります。
この場合、データを匿名化またはトークン化する方法が広く使用されていますが、個人情報を開示する可能性もあります(これが発生する理由については、この記事を参照してください)。
合成データの生成
合成データには根本的な違いがあります。目標は、元のデータと同じグローバル統計を表示するデータジェネレーターを作成することです。モデルや人にとって、オリジナルと結果を区別するのは難しいはずです。TGANモデルを使用
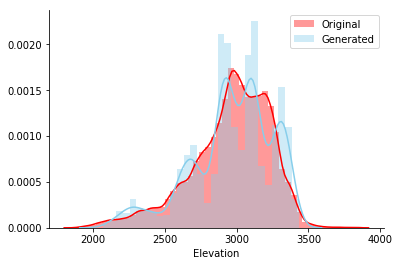
してCovertypeデータセットに合成データを生成することにより、上記を説明しましょう。 このテーブルでモデルをトレーニングした後、5000行を生成し、元のセットと生成されたセットのElevation列のヒストグラムをプロットしました。両方の線が視覚的に一致しているようです。

バーのペア間の関係を確認するために、すべての連続バーのペアグラフが表示されます。青緑色のドットが形成する(生成される)形状は、赤いドットの形状(元の)と視覚的に一致する必要があります。そして、それは起こった、かっこいい!

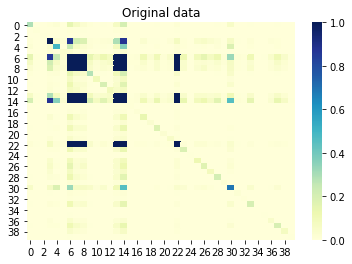
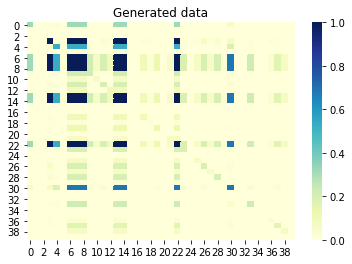
ここで、列間の相互情報(符号なし相関とも呼ばれます)を見ると、相互に相関している列も、生成されたセットで相関している必要があります。逆に、元のセットの相関のない列は、生成されたセットで相関しないようにする必要があります。 0に近い値は相関がないことを意味し、1に近い値は完全な相関を意味します。素晴らしいです!
列間の相互情報元のセット:
生成された列間の相互情報セット:
最後のテストとして、元のセットで非線形次元削減(UMAP)メソッドをトレーニングし、原点を2D空間に投影したいと思いました。生成したセットを同じプロジェクターに入力します。オレンジ色の十字(生成された)は、元のデータセットの青い点の雲にあるはずです。そこには!優秀な!
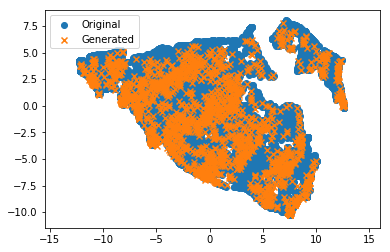
OK、データを試すのは楽しいです!
より深刻なケースの場合、2つの主要なアプローチがあります。
- 深い生成モデル:実際のデータが取得されたと思われる統計的分布を調査するために使用できます。この分布の近似値がある場合は、そこから任意のサイズの合成データセットをランダムにサンプリングできます。これは、すべてのクールな人が今していることです。
Synthetic data vault、Gretel.AI、Mostly.ai、MDClone、Hazy などのイニシアチブに注意を払う価値があります。
現在、IT組織が直面する次の一般的な問題のいずれかを解決するために、合成データを使用して概念の証明を作成できます。
- 開発環境にペイロードがありません
関心のあるデータが非常に厳格なアクセスポリシーのある実稼働環境にあるデータ製品(何でもかまいません)で作業しているとしましょう。残念ながら、興味深いデータがない開発環境にしかアクセスできません。
- 神モード-エンジニアとデータサイエンティストのアクセス権
あなたがデータサイエンティストであり、突然、情報セキュリティ担当者が本番データにアクセスするために必要な特権を制限したとします。このような厳しい限られた環境で、どうすればうまく機能し続けることができますか?
- 信頼できない外部パートナーへの機密データの転送
あなたはX社の一員です。組織Yは、最新のクールなデータ製品を紹介したいと考えています(何でもかまいません)。
彼らはあなたに製品を見せるためにデータを抽出するように頼みます。
合成データは、プライバシーの違いと何の関係がありますか?
合成データ生成の主な特性は、後処理やサードパーティの情報の追加に関係なく、オブジェクトが元のセットに含まれているかどうかを誰も知ることができず、このオブジェクトのプロパティを取得できないことです。このプロパティは、「差分プライバシー」(DP)と呼ばれるより広い概念の一部です。
グローバルおよびローカルの異なるプライバシー
DPは2種類に分けられます。
多くの場合、特定のタスクの結果のみに関心があります(たとえば、さまざまな病院の患者の非公開データに基づいてモデルをトレーニングしたり、犯罪を犯したことのある平均人数を計算したりするなど)。
この場合、信頼できないユーザーに機密データが表示されることはありません。代わりに、彼または彼女は、機密データにアクセスできる信頼できるキュレーター(グローバルな差分プライバシーメカニズムを使用)に、実行する操作を指示します。
結果のみが信頼できないユーザーに報告されます。PysyftとOpenDPをお勧めします同様のツールに関する詳細情報が必要な場合。
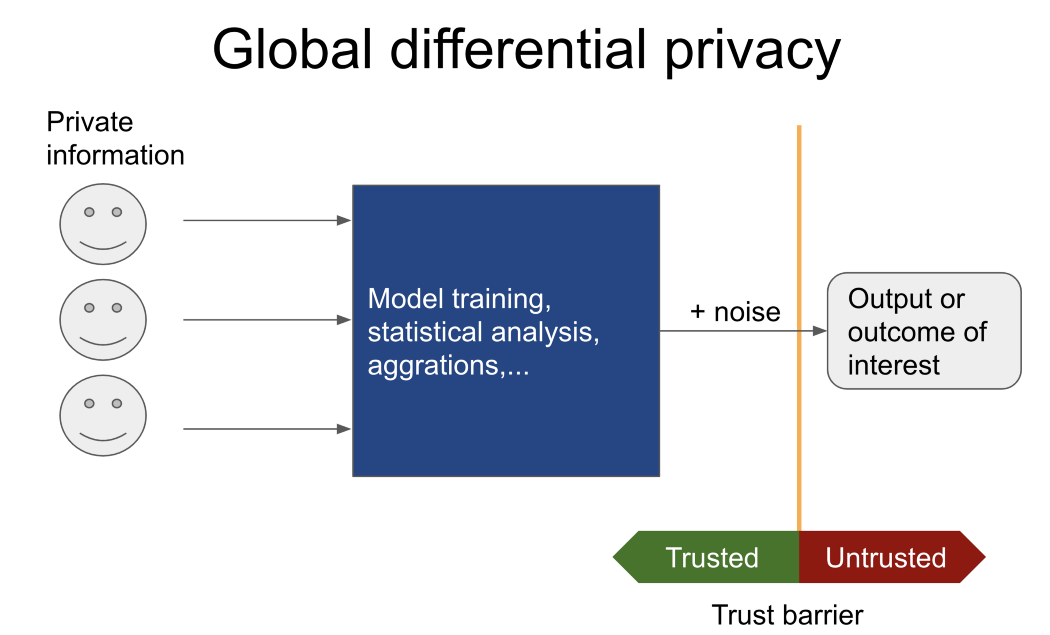
対照的に、データが信頼できない当事者に転送される場合は、ローカルの差分機密性の原則が機能します。従来、これは、テーブルまたはデータベースのすべての行にノイズを追加することによって実現されていました。追加されるノイズの量は、以下によって異なります。
- 必要なレベルの機密性(DPの文献で有名なイプシロン)、
- データセットのサイズ(データセットが大きいほど、同じレベルの機密性を実現するために必要なノイズが少なくなります)、
- 列のデータタイプ(定量的、カテゴリ的、順序的)。

理論的には、同じレベルの機密性の場合、グローバルDPメカニズム(結果にノイズを追加)は、ローカルメカニズム(ラインレベルのノイズ)よりも正確な結果を提供します。
したがって、合成データ生成方法は、ローカルDPの形式と考えることができます。
これらのトピックの詳細については、次のソースを参照することをお勧めします。
- www.udacity.com/course/secure-and-private-ai--ud185
- medium.com/@arbidha1412 / local-and-global-differential-privacy-249aaa3571
- www.openmined.org
勧告
より具体的な例を見てみましょう。個人情報を含むスプレッドシートを信頼できない当事者と共有したい。
現在、既存のデータラインにノイズを追加するか(ローカルDP)、堅牢なシステムをセットアップして使用するか(グローバルDP)、または元のデータに基づいて合成データを生成することができます。
次の場合、既存のデータラインにノイズを追加する必要があります
- 公開後にデータに対してどのような操作が実行されるかわからない、
- 元のデータの更新を定期的に共有する必要があります(=このワークフローを安定したバッチプロセスの一部として使用します)。
- あなたとデータ所有者は、元のデータにノイズを追加するために個人/チーム/組織を信頼します。
ここでは、OpenDPツールから始めることをお勧めします。
プライバシーの違いの最も有名なケースは、米国の国勢調査です(databricks.com/session_na20/using-apache-spark-and-differential-privacy-for-protecting-the-privacy-of-the-2020-census-respondentsを参照)。
このデータは3年ごとに再計算および更新されます。これは主に、複数のレベル(郡、州、国レベル)で集計および公開される数値データです。
信頼できるシステムをインストールして使用する場合
- 指定したシステムは、そのシステムで実行されるタスクと操作をサポートします。
- 基本データはさまざまな場所に保存されており、離れることはできません(たとえば、さまざまな病院に)。
- あなたとデータ所有者は、実際に現在のシステムとそれを設定している人/チーム/組織を信頼しています。
機密データのユーザーは、最初のアプローチよりも正確な結果を得ることができます。
多くのフレームワークは現在、この獣を安全でスケーラブルで監査可能な方法で展開するために必要なすべての機能を備えていません。ここにはまだ多くのエンジニアリング作業が必要です。
しかし、採用が進むにつれ、DPは大規模な組織や企業にとって優れた代替手段になる可能性があります。
ここからOpenMinedから始めることをお勧めします。
次の場合、合成データを生成することが可能です。
- 元のテーブルは比較的小さい(<100万行、<100列)、
- ad-hoc ( ),
- / / , .
上記の小さな実験と同様に、結果は有望です。また、DPシステムに関する優れた知識も必要ありません。必要に応じて、今日から始めて、一晩中トレーニングし、いわば、明日の朝に備えて分割合成セットを用意することができます。
最大の欠点は、データ量が増えると、これらの複雑なモデルのトレーニングと保守に費用がかかる可能性があることです。各テーブルには、モデルの独自の完全なトレーニングも必要です(ポータブルトレーニングはここでは機能しません)。かなりの計算予算があっても、数百のテーブルに拡張することはできません。
そうでなければ、あなたは運が悪いです。
結論
データのプライバシーがこれまで以上に重要になっているため、合成データを生成したり、既存のデータにノイズを追加したりするための優れた方法があります。ただし、それらすべてにはまだ制限があります。いくつかのニッチなケースを除いて、個人情報を含むデータを信頼できない当事者に転送できるようにする、スケーラブルで柔軟なエンタープライズグレードのツールはまだ作成されていません。
データ所有者は、確立された方法やシステムを信頼する必要があり、それは彼らからの多くの信頼を必要とします。これが最大の問題です!
それまでの間、試してみたい場合は(概念の証明、テストしてみてください)、上記のリンクのいずれかを開いてください。