Javaでの複雑なデータ処理のために検討しているフレームワークの中には、ApacheFlinkがあります。読者の関心を評価するために、MediumポータルのAnalyticsVidhyaブログからの優れた記事の翻訳を提供したいと思います。お気軽に投票してください!

この記事では、Flinkを使用して合理化する方法をボトムアップで見ていきます。クラウドサービスやその他のプラットフォームでは、ストリーミングソリューションが提供されます(一部のプラットフォームにはFlinkが内部で統合されています)。このトピックを最初から理解したい場合は、探していたものを正確に見つけました。
私たちのモノリシックソリューションは、増加する受信データに対処できませんでした。したがって、それを開発する必要がありました。私たちの製品の進化において、新しい世代に移行する時が来ました。ストリーミング処理を使用することが決定されました。これは、従来のバッチ処理よりも優れたデータ吸収の新しいパラダイムです。
Apache Flink:簡単な説明
Apache Flinkは、データの連続ストリームでの操作用に設計されたスケーラブルな分散スレッドフレームワークです。このフレームワーク内では、ソース、ストリーム変換、並列処理、スケジューリング、リソース割り当てなどの概念が使用されます。さまざまなデータ宛先がサポートされています。具体的には、Apache FlinkはHDFS、Kafka、Amazon Kinesis、RabbitMQ、およびCassandraに接続できます。
Flinkは、高スループットと低遅延で知られており、一貫性のある厳密に1回限りの処理(すべてのデータは1回処理され、重複はありません)、および高可用性をサポートします。他の成功したオープンソース製品と同様に、Flinkには、このフレームワークの機能を育成および拡張する大規模なコミュニティがあります。
Flinkは、データストリーム(ストリームサイズは未定義)またはデータセット(データセットサイズは特定)を処理できます。この記事では、特にスレッド処理(オブジェクトの処理)について説明します
DataStream
。
ストリーミングとその固有の課題
今日、IoTデバイスやその他のセンサーが普及しているため、データは常に多くのソースから取得されています。この無限のデータストリームには、従来のバッチコンピューティングを新しい条件に適応させる必要があります。
- 無制限のストリーミングデータ。彼らには始まりも終わりもありません。
- 新しいデータは、不規則な間隔で、予測できない方法で到着します。
- データは、タイムスタンプが異なると、無秩序に到着する可能性があります。
これらの独自の特性により、データ処理とクエリのタスクを実行するのは簡単ではありません。結果は急速に変化する可能性があり、明確な結論を出すことはほとんど不可能です。有効な結果を取得しようとすると、計算がブロックされることがあります。さらに、計算中にデータが変化し続けるため、結果は再現できません。最後に、遅延は結果の精度に影響を与えるもう1つの要因です。
Apache Flinkは、ソースで受信データに提供されるタイムスタンプに焦点を合わせているため、このような処理の問題に対処できます。Flinkには、イベントに付けられたタイムスタンプに基づいてイベントを蓄積するメカニズムがあります。イベントを蓄積した後でのみ、システムは処理に進みます。この場合、マイクロパッケージを使用せずに実行することが可能であり、この場合、結果の精度が向上します。
Flinkは、一貫性のある厳密なワンショット処理を実装しており、計算の精度を保証します。開発者は、このために特別なことをプログラムする必要はありません。
Flinkパッケージの構成
通常、Flinkはさまざまなソースからのデータストリームを吸収します。基本オブジェクトは
DataStream<T>
、同じタイプの要素のストリームです。このようなストリームの要素タイプは、コンパイル時に汎用タイプを設定することによって決定されます
T
(これについて詳しくは、こちらを参照してください)。
このオブジェクトに
DataStream
は、データを変換、分割、およびフィルタリングするための多くの便利なメソッドが含まれています。スタートのために、彼らが何をしているかのアイデアを持っていることが有用であろう
map
、
reduce
と
filter
。これらは主な変換方法です。
Map
:オブジェクトT
を取得し、その結果、タイプR
;のオブジェクトを返します。MapFunction
オブジェクトの各要素に厳密に一度適用されますDataStream
。
SingleOutputStreamOperator<R> map(MapFunction<T,R> mapper)
Reduce
:2つの連続した値を取得し、1つのオブジェクトを返し、それらを同じタイプのオブジェクトに結合します。このメソッドは、グループ内のすべての値に対して、そのうちの1つだけが残るまで実行されます。
T reduce(T value1, T value2)
Filter
:オブジェクトT
を取得し、オブジェクトのストリームを返しますT
; このメソッドはすべての要素を繰り返し処理しDataStream
ますが、関数が返す要素のみを返しますtrue
。
SingleOutputStreamOperator<T> filter(FilterFunction<T> filter)
データドレイン
Flinkの主な目標の1つは、データ変換とともに、フローを制御し、特定の宛先に転送することです。これらの場所は「排水路」と呼ばれます。FLINKは、組み込まれている文字列(テキスト、CSV、ソケット)、ならびにアウトオブボックス機構、例えば、他のシステムに接続するためのApacheカフカを。
フリンクイベントタグ
データストリームを処理する場合、時間的要因は非常に重要です。タイムスタンプを決定する方法は3つあります。
- ( ): , ; , . - . , .
, , . , , , ; , .
// Processing Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
- : , , , Flink. , , Flink .
Flink , , , ; « » (watermark). ; Flink.
// Event Time streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);DataStream<String> dataStream = streamEnv.readFile(auditFormat, dataDir, FileProcessingMode.PROCESS_CONTINUOUSLY, 1000). assignTimestampsAndWatermarks( new TimestampExtractor());// ... ... // public class TimestampExtractor implements AssignerWithPeriodicWatermarks<String>{ @Override public Watermark getCurrentWatermark() { return new Watermark(System.currentTimeMillis()-maxTimeFrame); } @Override public long extractTimestamp(String str, long l) { return InputData.getDataObject(str).timestamp; } }
- 吸収時間:これは、イベントがFlinkに入る時点です。イベントがソースにあるときに割り当てられるため、プロセスの実行開始時に割り当てられる処理時間よりも安定していると見なされます。
タイムスタンプは吸収が開始される時間であるため、吸収時間は、異常なイベントや遅延データの処理には適していません。これは、ウォーターマークメカニズムに依存して、保留中のイベントを検出して処理する機能を提供するイベント時間とは異なります。
// Ingestion Time StreamExecutionEnvironment objectstreamEnv.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime);
タイムスタンプとそれらがストリーミングに与える影響について詳しくは、次のリンクをご覧ください。
ウィンドウの内訳
ストリームは定義上無限です。したがって、処理メカニズムはフラグメントの定義(たとえば、ウィンドウ期間)に関連付けられています。したがって、ストリームは、集約と分析に便利なバッチに分割されます。ウィンドウ定義は、DataStreamオブジェクトまたはそれを継承するその他のオブジェクトに対する操作です。
時間依存ウィンドウにはいくつかのタイプがあります。
タンブリングウィンドウ(デフォルト構成):
ストリームは、互いにオーバーラップしない同等のサイズのウィンドウに分割されます。ストリームが流れている間、Flinkはこの固定されたストーリーボードに基づいてデータを継続的に計算します。 コードでの

タンブリングウィンドウの
実装:
// ,
public AllWindowedStream<T,TimeWindow> timeWindowAll(Time size)
// ,
public WindowedStream<T,KEY,TimeWindow> timeWindow(Time size)
スライディングウィンドウ
このようなウィンドウは互いに重なり合う可能性があり、スライディングウィンドウのプロパティは、このウィンドウのサイズとマージン(次のウィンドウをいつ開始するか)によって決まります。この場合、複数のウィンドウに関連するイベントを一度に処理できます。

スライドウィンドウ
そして、これはコードでどのように見えるかです:
// 1 30
dataStreamObject.timeWindow(Time.minutes(1), Time.seconds(30))
セッションウィンドウ
1つのセッションのスコープによって制限されたすべてのイベントが含まれます。アクティビティがない場合、または特定の期間後にイベントが検出されない場合、セッションは終了します。この期間は、処理中のイベントに応じて、固定または動的にすることができます。理論的には、セッション間の間隔がウィンドウサイズよりも小さい場合、セッションが終了することはありません。
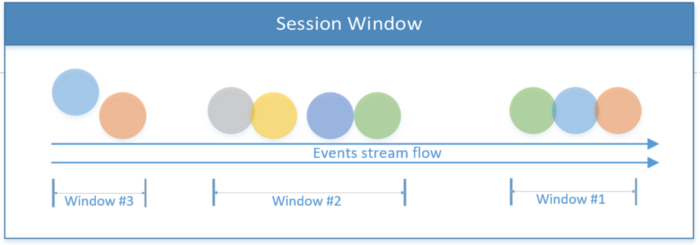
セッションウィンドウ
以下の最初のコードスニペットは、固定時間値(2秒)のセッションを示しています。 2番目の例では、スレッドイベントに基づいて動的セッションウィンドウを実装します。
// 2
dataStreamObject.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// ,
dataStreamObject.window(EventTimeSessionWindows.withDynamicGap((elem) -> {
// ,
}))
グローバルウィンドウ
システム全体が単一のウィンドウとして扱われます。 Flink

グローバルウィンドウで
は、独自のウィンドウを実装することもできます。そのロジックはユーザーが定義します。
時間依存のウィンドウに加えて、たとえば、着信イベントの数の制限が設定されているアカウントウィンドウなどがあります。しきい値Xに達すると、FlinkはXイベントを処理します。

3つのイベントのカウントウィンドウ
理論的な紹介の後、実用的な観点からデータフローとは何かを詳しく見てみましょう。Apache Flinkとスレッドの詳細については、公式Webサイトを参照してください。
ストリームの説明
理論的な部分の要約として、次のブロック図は、この記事のコードスニペットに実装されている主なデータフローを示しています。以下のストリームは、ソースから始まり(ファイルはディレクトリに書き込まれます)、オブジェクトに変換されたイベントを処理している間継続します。
以下に示す実装には、2つの処理パスがあります。上部に示されているものは、1つのストリームを2つのサイドストリームに分割し、それらを結合して、3番目のタイプのストリームを取得します。図の下部に示されているスクリプトは、ストリームの処理を説明し、その後、作業の結果がシンクに転送されます。

次に、上記の理論の実際的な実装を手で感じてみます。以下で説明するすべてのソースコードはGitHubに掲載されています。
基本的なストリーム処理(例1)
最も単純なアプリケーションから始めると、Flinkの概念を理解しやすくなります。このアプリケーションでは、プロデューサーがファイルをディレクトリに書き込むため、情報の流れをシミュレートします。Flinkはこのディレクトリからファイルを読み取り、それらに関する要約情報を宛先ディレクトリに書き込みます。これが在庫です。
次に、処理中に何が起こるかを詳しく見てみましょう。
生データをオブジェクトに変換します。
// InputData;
DataStream<InputData> inputDataObjectStream
= dataStream
.map((MapFunction<String, InputData>) inputStr -> {
System.out.println("--- Received Record : " + inputStr);
return InputData.getDataObject(inputStr);
});
以下のコードスニペットは
InputData
、ストリームオブジェクト()を文字列と整数のタプルに変換します。オブジェクトのストリームから特定のフィールドのみを抽出し、2秒の量子で1つのフィールドごとにグループ化します。
//
DataStream<Tuple2<String, Integer>> userCounts
= inputDataObjectStream
.map(new MapFunction<InputData,Tuple2<String,Integer>>() {
@Override
public Tuple2<String,Integer> map(InputData item) {
return new Tuple2<String,Integer>(item.getName() ,item.getScore() );
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0) // KeyedStream<T, Tuple> ( 'name')
//.timeWindowAll(Time.seconds(windowInterval)) // timeWindowAll
.timeWindow(Time.seconds(2)) // WindowedStream<T, KEY, TimeWindow>
.reduce((x,y) -> new Tuple2<String,Integer>( x.f0+"-"+y.f0, x.f1+y.f1));
ストリームの宛先の作成(データシンクの実装):
//
DataStream<Tuple2<String,Integer>> inputCountSummary
= inputDataObjectStream
.map( item
-> new Tuple2<String,Integer>
(String.valueOf(System.currentTimeMillis()),1))
// (1)
.returns(Types.TUPLE(Types.STRING ,Types.INT))
.timeWindowAll(Time.seconds(windowInterval)) //
.reduce((x,y) -> // ,
(new Tuple2<String, Integer>(x.f0, x.f1 + y.f1)));
//
final StreamingFileSink<Tuple2<String,Integer>> countSink
= StreamingFileSink
.forRowFormat(new Path(outputDir),
new SimpleStringEncoder<Tuple2<String,Integer>>
("UTF-8"))
.build();
// DataStream; inputCountSummary countSink
inputCountSummary.addSink(countSink);
データシンクを作成するためのサンプルコード。
ストリームの分割(例#2)
この例は、サイド出力ストリームを使用してメインストリームを分割する方法を示しています。 Flinkは、メインストリームから複数のサイドストリームを提供します
DataStream
。ストリームの両側にあるデータのタイプは、メインストリームのデータタイプ、および各サイドストリームのデータタイプとは異なる場合があります。
したがって、サイド出力ストリームを使用すると、1つの石で2羽の鳥を殺すことができます。ストリームを分割し、ストリームのデータタイプを多くのデータタイプに変換します(サイド出力ストリームごとに一意にすることができます)。
以下のコードスニペットは
ProcessFunction
、入力プロパティに応じて、ストリームを2つのサイドストリームに分割することと呼ばれます。同じ結果を得るには、関数を繰り返し使用する必要があります
filter
。
関数
ProcessFunction
(基準に基づいて)特定のオブジェクトを収集し、それらをメインのアウトレットマニホールド(にある
SingleOutputStreamOperator
)に送信し、残りのイベントはサイド出力に送信されます。ストリームは
DataStream
垂直方向に分割され、サイドストリームごとに異なる形式を公開します。
サイドストリーム出力の定義は、一意の出力タグ(オブジェクト
OutputTag
)に基づいていることに注意してください。
//
final OutputTag<Tuple2<String,String>> playerTag
= new OutputTag<Tuple2<String,String>>("player"){};
//
final OutputTag<Tuple2<String,Integer>> singerTag
= new OutputTag<Tuple2<String,Integer>>("singer"){};
// InputData .
SingleOutputStreamOperator<InputData> inputDataMain
= inputStream
.process(new ProcessFunction<String, InputData>() {
@Override
public void processElement(
String inputStr,
Context ctx,
Collector<InputData> collInputData) {
Utils.print(Utils.COLOR_CYAN, "Received record : " + inputStr);
// InputData
InputData inputData = InputData.getDataObject(inputStr);
switch (inputData.getType())
{
case "Singer":
//
ctx.output(singerTag,
new Tuple2<String,Integer>
(inputData.getName(), inputData.getScore()));
break;
case "Player":
// ;
// playerTag, (" ")
ctx.output(playerTag,
new Tuple2<String, String>
(inputData.getName(), inputData.getType()));
break;
default:
// InputData
collInputData.collect(inputData);
break;
}
}
});
ストリームを分割する方法を示すサンプルコード
ストリームの結合(例#3)
この記事で取り上げる最後の操作は、スレッドの連結です。アイデアは、データ形式が異なる可能性のある2つの異なるストリームを組み合わせて、統一されたデータ構造で1つのストリームを収集することです。データが水平方向にマージされるSQLの結合操作とは異なり、イベントのフローは継続し、時間に制限がないため、ストリームは垂直方向にマージされます。
ストリームの連結は、connectメソッドを呼び出してから、個々のストリームの各アイテムのマッピング操作を定義することによって行われます。結果はマージされたストリームです。
//
ConnectedStreams<Tuple2<String, Integer>, Tuple2<String, String>> mergedStream
= singerStream
.connect(playerStream);
DataStream<Tuple4<String, String, String, Integer>> combinedStream
= mergedStream.map(new CoMapFunction<
Tuple2<String, Integer>, // 1
Tuple2<String, String>, // 2
Tuple4<String, String, String, Integer> //
>() {
@Override
public Tuple4<String, String, String, Integer> // 1
map1(Tuple2<String, Integer> singer) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: singer stream", singer.f0, "", singer.f1);
}
@Override
public Tuple4<String, String, String, Integer>
// 2
map2(Tuple2<String, String> player) throws Exception {
return new Tuple4<String, String, String, Integer>
("Source: player stream", player.f0, player.f1, 0);
}
});
マージされたストリームを取得する方法を示すリスト
作業プロジェクトの作成
つまり、要約すると、デモプロジェクトはGitHubにアップロードされます。それを構築してコンパイルする方法について説明します。これは、Flinkで練習するための良い出発点です。
結論
この記事では、動作するFlinkベースのスレッドアプリケーションを作成するための基本的な操作について説明します。このアプリケーションの目的は、ストリーミングに固有の重要な呼び出しの概要を提供し、完全に機能するFlinkアプリケーションを後で作成するための基礎を築くことです。
ストリーミングには多くの側面と複雑さがあるため、この記事の問題の多くは未解決のままです。特に、Flinkの実行とタスクの管理、ストリーミングイベントの時間を設定するときのウォーターマーク、ストリームイベントへの状態の挿入、ストリームの反復の実行、ストリームに対するSQLのようなクエリの実行などがあります。
この記事がFlinkを試してみたいと思わせるのに十分だったことを願っています。